Rong Kit Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -
Problems with Unicode for Languages Unsupported by Computers
Problems with Unicode for Languages Unsupported by Computers Pat Hall, Language Technology Kendra, Patan, Nepal [email protected] Abstract If a language is to be used on the Internet it needs to be written and that writing encoded for the computer. The problems of achieving this for small languages is illustrated with respect to Nepal. Nepal has over 120 languages, with only the national language Nepali having any modern computer support. Nepali is relatively easy, since it is written in Devanagari which is also used for Hindi and other Indian languages, though with some local differences. I focus on the language of the Newar people, a language which has a mature written tradition spanning more than one thousand years, with several different styles of writing, and yet has no encoding of its writing within Unicode. Why has this happened? I explore this question, looking for answers in the view of technology of the people involved, in their different and possibly competing interests, and in the incentives for working on standards. I also explore what should be done about the many other unwritten and uncomputerised languages of Nepal. We are left with serious concerns about the standardisation process, but appreciate that encoding is critically important and we must work with the standardisation process as we find it.. Introduction If we are going to make knowledge written in our language available to everybody in their own languages, those languages must be written and that writing must be encoded in the computer. Those of us privileged to be native speakers of a world language such as English or Spanish may think this is straightforward, but it is not, as will be explained here. -

International Language Environments Guide for Oracle® Solaris 11.4
International Language Environments ® Guide for Oracle Solaris 11.4 Part No: E61001 November 2020 International Language Environments Guide for Oracle Solaris 11.4 Part No: E61001 Copyright © 2011, 2020, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are -

Rtorrent-Ps Documentation Release 1.2-Dev
rtorrent-ps Documentation Release 1.2-dev PyroScope Project Aug 05, 2021 Getting Started 1 Overview 3 1.1 Feature Overview............................................4 1.2 Supported Platforms...........................................4 1.3 Launching a Demo in Docker......................................4 2 Installation Guide 7 2.1 General Installation Options.......................................7 2.2 OS-Specific Installation Options.....................................8 2.3 Manual Turn-Key System Setup.....................................9 3 Setup & Configuration 17 3.1 Setting up Your Terminal Emulator................................... 17 3.2 Trouble-Shooting Guide......................................... 19 4 User’s Manual 25 4.1 Additional Features........................................... 25 4.2 Extended Canvas Explained....................................... 27 4.3 Command Extensions.......................................... 29 5 Tips & How-Tos 33 5.1 Checking Details of the Standard Configuration............................. 33 5.2 Validate Self-Signed Certs........................................ 33 6 Advanced Customization 35 6.1 Color Scheme Configuration....................................... 35 6.2 Customizing the Display Layout..................................... 37 7 Development Guide 43 7.1 Running Integration Tests........................................ 43 7.2 The Build Script............................................. 44 7.3 Creating a Release............................................ 45 7.4 Building the Debian Package..................................... -
Unifoundry.Com GNU Unifont Glyphs
Unifoundry.com GNU Unifont Glyphs Home GNU Unifont Archive Unicode Utilities Unicode Tutorial Hangul Fonts Unifont 9.0 Chart Fontforge Poll Downloads GNU Unifont is part of the GNU Project. This page contains the latest release of GNU Unifont, with glyphs for every printable code point in the Unicode 9.0 Basic Multilingual Plane (BMP). The BMP occupies the first 65,536 code points of the Unicode space, denoted as U+0000..U+FFFF. There is also growing coverage of the Supplemental Multilingual Plane (SMP), in the range U+010000..U+01FFFF, and of Michael Everson's ConScript Unicode Registry (CSUR). These font files are licensed under the GNU General Public License, either Version 2 or (at your option) a later version, with the exception that embedding the font in a document does not in itself constitute a violation of the GNU GPL. The full terms of the license are in LICENSE.txt. The standard font build — with and without Michael Everson's ConScript Unicode Registry (CSUR) Private Use Area (PUA) glyphs. Download in your favorite format: TrueType: The Standard Unifont TTF Download: unifont-9.0.01.ttf (12 Mbytes) Glyphs above the Unicode Basic Multilingual Plane: unifont_upper-9.0.01.ttf (1 Mbyte) Unicode Basic Multilingual Plane with CSUR PUA Glyphs: unifont_csur-9.0.01.ttf (12 Mbytes) Glyphs above the Unicode Basic Multilingual Plane with CSUR PUA Glyphs: unifont_upper_csur-9.0.01.ttf (1 Mbyte) PCF: unifont-9.0.01.pcf.gz (1 Mbyte) BDF: unifont-9.0.01.bdf.gz (1 Mbyte) Specialized versions — built by request: SBIT: Special version at the request -

Juhtolv-Fontsamples
juhtolv-fontsamples Juhapekka Tolvanen Contents 1 Copyright and contact information 3 2 Introduction 5 3 How to use these PDFs 6 3.1 Decompressing ............................... 6 3.1.1 bzip2 and tar ............................. 8 3.1.2 7zip .................................. 11 3.2 Finding right PDFs ............................. 12 4 How to edit these PDFs 16 4.1 What each script do ............................ 16 4.2 About shell environment .......................... 19 4.3 How to ensure each PDF take just one page .............. 20 4.4 Programs used ................................ 20 4.5 Fonts used .................................. 23 4.5.1 Proportional Gothic ......................... 24 4.5.2 Proportional Mincho ........................ 26 4.5.3 Monospace (Gothic and Mincho) ................. 27 4.5.4 Handwriting ............................. 28 4.5.5 Fonts that can not be used .................... 29 5 Thanks 30 2 1 Copyright and contact information Author of all these files is Juhapekka Tolvanen. Author’s E-Mail address is: juhtolv (at) iki (dot) fi This publication has included material from these dictionary files in ac- cordance with the licence provisions of the Electronic Dictionaries Research Group: • kanjd212 • kanjidic • kanjidic2.xml • kradfile • kradfile2 See these WWW-pages: • http://www.edrdg.org/ • http://www.edrdg.org/edrdg/licence.html • http://www.csse.monash.edu.au/~jwb/edict.html • http://www.csse.monash.edu.au/~jwb/kanjidic_doc.html • http://www.csse.monash.edu.au/~jwb/kanjd212_doc.html • http://www.csse.monash.edu.au/~jwb/kanjidic2/ • http://www.csse.monash.edu.au/~jwb/kradinf.html 3 All generated PDF- and TEX-files of each kanji-character use exactly the same license as kanjidic2.xml uses; Name of that license is Creative Commons Attribution-ShareAlike Licence (V3.0). -

Third Party Software Licensing Agreements RL6 6.8
Third Party Software Licensing Agreements RL6 6.8 Updated: April 16, 2019 www.rlsolutions.com m THIRD PARTY SOFTWARE LICENSING AGREEMENTS CONTENTS OPEN SOURCE LICENSES ................................................................................................................. 10 Apache v2 License ...................................................................................................................... 10 Apache License ................................................................................................................. 11 BSD License ................................................................................................................................ 14 .Net API for HL7 FHIR (fhir-net-api) .................................................................................. 15 ANTLR 3 C# Target ........................................................................................................... 16 JQuery Sparkline ............................................................................................................... 17 Microsoft Ajax Control Toolkit ............................................................................................ 18 Mvp.Xml ............................................................................................................................. 19 NSubstitute ........................................................................................................................ 20 Remap-istanbul ................................................................................................................ -
Lepcha Script Was Devised in the Early 18Th Century by Prince Chakdor Namgyal of Tibet
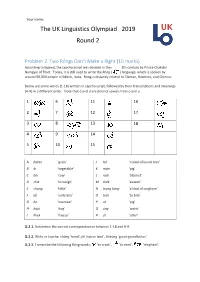
Your name: The UK Linguistics Olympiad 2019 Round 2 Problem 2. Two Róngs Don’t Make a Right (10 marks) According to legend, the Lepcha script was devised in the early 18th century by Prince Chakdor Namgyal of Tibet. Today, it is still used to write the Róng ( ) language, which is spoken by around 50,000 people in Sikkim, India. Róng is distantly related to Tibetan, Burmese, and Chinese. Below are some words (1-18) written in Lepcha script, followed by their transcriptions and meanings (A-R) in a different order. Note that ó and ú are distinct vowels from o and u. 1 6 11 16 2 7 12 17 3 8 13 18 4 9 14 5 10 15 A bakto 'grain' J lali 'a kind of laurel tree' B bi 'vegetable' K món 'pig' C bik 'cow' L radi 'blanket' D chik 'to weigh' M thúk 'season' E chung 'little' N tsung kóng 'a kind of sorghum' F dú 'umbrella' O tsúk 'to bite' G ka 'overseer' P ut 'pig' H kajú 'dog' Q úng 'water' I khek 'freeze' R út 'otter' Q.2.1. Determine the correct correspondences between 1-18 and A-R. Q.2.2. Write in Lepcha: chóng ‘hand’, jik ‘native land’, thikúng ‘great-grandfather’. Q.2.3. Transcribe the following Róng words: ‘to crack’, ‘to read’, ’elephant’. Your name: The UK Linguistics Olympiad 2019 Round 2 Solution and marking. Scoring (max 30) • Q.2.1: 1 point for each correct letter (max 18) • Q.2.2: 2 points for each correct Lepcha word; 1 point with one error (max 6) • Q.2.3: 2 points for each correct transliteration; 1 with one error (max 6) Q.2.1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 J F A Q C R D N H M G I B O K L E P Q.2.2 chóng ‘hand’ jik ‘native land’ thikúng ‘great-grandfather’ (thi-kung) or (thik-ung) Q.2.3 dan ‘to crack’ rok ‘to read’ ’elephant’ ranmo Your name: The UK Linguistics Olympiad 2019 Round 2 Commentary 1. -

Publishing Text in Indigenous African Languages
Publishing text in indigenous African languages A workshop paper prepared by Conrad Taylor for the BarCamp Africa UK conference in London on 7 Nov 2009. Copies downloadable from http://barcampafrica-uk.wikispaces.com/Publishing+technology, and http://www.conradiator.com – most markedly in the Americas and in Africa, where most 1: Background; how the problem arose cultures did not have a preiexisting writing system. In each European country’s imperial sphere of influence, its own UBLISHING, if we take it to mean the written word made language first became a lingua franca for trade; then as the Pinto many copies by the scribe or the printing press, has great late-19th century colonial landgrab of Africa got going, held a privileged position for hundreds of years as a vehicle colonial languages became the languages of administration, for transmitting stories & ideas, information & knowledge education and Christian religious proselytisation. over long distances, free from limitations of time & space. Written mass communication is so commonplace today that African indigenous-language literacy: perhaps we forget some of its demanding preconditions: the old non-latins a shared language – for which there must be a shared set of written characters; plus the skill of literacy. How did indigenous African languages take written form? Will text remain as privileged a mode of communication The first point to note is that literacy in Africa is very ancient. in the future? Text is a powerful medium, and the Internet Kemetic (ancient Egyptian) scripts were probably not the has empowered it further with email, the Web and Google. first writing system in the world – Mesopotamians most But remote person-to-person communi cation today is more likely achieved that first – but writing developed in Egypt likely to be done by phone than email; radio and television very early, about five thousand years ago. -

Iso/Iec Jtc1/Sc2/Wg2 N2947r L2/05-158R
ISO/IEC JTC1/SC2/WG2 N2947R L2/05-158R 2005-07-04 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Lepcha script in the BMP of the UCS Source: Michael Everson Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2005-07-04 Lepcha is a Sino-Tibetan language. The Lepchas call themselves Róngkup (‘children of the Róng’), and their language Róngríng (‘language of the Róng’), but the name Lepcha is very widespread now, and the Lepchas themselves also use it frequently. The Lepcha script is in current use by many people in Sikkim and West Bengal, especially in the Darjeeling district. The weekly government newspaper The Sikkim Herald is also published in Lepcha and Lepcha is taught in schools in Sikkim. In West Bengal, there are many evening classes in which the script is taught, as well as books and magazines which are published privately or through one of several Lepcha associations. The SIL Ethnologue indicates that there are 41,300 Lepchas. Structure The Lepcha script is of the Brahmic type, but indirectly, being derived directly from Tibetan; some of those innovations are reflected in the structure of Lepcha. If one turns a Lepcha syllable clockwise, the similarities to Tibetan syllables is often quite striking. Lepcha has also introduced some innovations of its own, such as the diacritical marks used for final consonants. Lepcha is thought to have been devised around 1720 CE by the Sikkim king Phyag-rdor rNam-rgyal (“Chakdor Namgyal”, born 1686), according to Jensen 1969. -

Papers in Southeast Asian Linguistics No. 14: Tibeto-Bvrman Languages of the Himalayas
PACIFIC LINGUISTICS Series A-86 PAPERS IN SOUTHEAST ASIAN LINGUISTICS NO. 14: TIBETO-BVRMAN LANGUAGES OF THE HIMALAYAS edited by David Bradley Department of Linguistics Research School of Pacific and Asian Studies THE AUSTRALIAN NATIONAL UNIVERSITY Bradley, D. editor. Papers in Southeast Asian Linguistics No. 14:. A-86, vi + 232 (incl. 4 maps) pages. Pacific Linguistics, The Australian National University, 1997. DOI:10.15144/PL-A86.cover ©1997 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. Pacific Linguistics specialises in publishing linguistic material relating to languages of East Asia, Southeast Asia and the Pacific. Linguistic and anthropological manuscripts related to other areas, and to general theoretical issues, are also considered on a case by case basis. Manuscripts are published in one of four series: SERIES A: Occasional Papers SERIES C: Books SERIES B: Monographs SERIES D: Special Publications FOUNDING EDITOR: S.A. Wurm EDITORIAL BOARD: M.D. Ross and D.T. Tryon (Managing Editors), T.E. Dutton, N.P. Himmelmann, A.K. Pawley EDITORIAL ADVISERS: B.W. Bender KA. McElhanon University of Hawaii Summer Institute of Linguistics David Bradley H.P. McKaughan La Trobe University University of Hawaii Michael G. Clyne P. Miihlhausler Monash University Universityof Adelaide S.H. Elbert G.N. O'Grady University of Hawaii University of Victoria, B.C. K.J. Franklin KL. Pike Summer Institute of Linguistics Summer Institute of Linguistics W.W.Glover E.C. Polome Summer Institute of Linguistics University of Texas G.W.Grace Gillian Sankoff University of Hawaii University of Pennsylvania M.A.K. -

Amendment for .Mls
Amendment No. 1 to Registry Agreement The Internet Corporation for Assigned Names and Numbers and The Canadian Real Estate Association agree, effective as of _______________________________ (“Amendment No. 1 Effective Date”), that the modification set forth in this amendment No. 1 (the “Amendment”) is made to the 23 April 2015 .MLS Registry Agreement between the parties, as amended (the “Agreement”). The parties hereby agree to amend Exhibit A of the Agreement by deleting section 4 in its entirety: [OLD TEXT] “4. Internationalized Domain Names (IDNs) Registry Operator may offer registration of IDNs at the second and lower levels provided that Registry Operator complies with the following requirements: 4.1. Registry Operator must offer Registrars support for handling IDN registrations in EPP. 4.2. Registry Operator must handle variant IDNs as follows: 4.2.1. Variant IDNs (as defined in the Registry Operator’s IDN tables and IDN Registration Rules) will be blocked from registration. 4.3. Registry Operator may offer registration of IDNs in the following languages/scripts (IDN Tables and IDN Registration Rules will be published by the Registry Operator as specified in the ICANN IDN Implementation Guidelines): 4.3.1. Arabic script 4.3.2. Armenian script 4.3.3. Avestan script 4.3.4. Azerbaijani language 4.3.5. Balinese script 4.3.6. Bamum script 4.3.7. Batak script 4.3.8. Belarusian language 4.3.9. Bengali script 4.3.10. Bopomofo script 4.311. Brahmi script 4.3.12. Buginese script 4.3.13. Buhid script 4.3.14. Bulgarian language 4.3.15.