Eth-8342-02.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Detection of Aneuploidies by Paralogous Sequence Quantification S Deutsch, U Choudhury, G Merla, C Howald, a Sylvan, S E Antonarakis
908 J Med Genet: first published as 10.1136/jmg.2004.023184 on 9 December 2004. Downloaded from ORIGINAL ARTICLE Detection of aneuploidies by paralogous sequence quantification S Deutsch, U Choudhury, G Merla, C Howald, A Sylvan, S E Antonarakis ............................................................................................................................... J Med Genet 2004;41:908–915. doi: 10.1136/jmg.2004.023184 Background: Chromosomal aneuploidies are a common cause of congenital disorders associated with cognitive impairment and multiple dysmorphic features. Pre-natal diagnosis of aneuploidies is most See end of article for commonly performed by the karyotyping of fetal cells obtained by amniocentesis or chorionic villus authors’ affiliations sampling, but this method is labour intensive and requires about 14 days to complete. ....................... Methods: We have developed a PCR based method for the detection of targeted chromosome number Correspondence to: abnormalities termed paralogous sequence quantification (PSQ), based on the use of paralogous genes. Professor Stylianos E Paralogous sequences have a high degree of sequence identity, but accumulate nucleotide substitutions in Antonarakis, Department a locus specific manner. These sequence differences, which we term paralogous sequence mismatches of Genetic Medicine and Development, University of (PSMs), can be quantified using pyrosequencing technology, to estimate the relative dosage between Geneva Medical School, different chromosomes. We designed 10 assays for the detection of trisomies of chromosomes 13, 18, and GE 1211, Geneva, 21 and sex chromosome aneuploidies. Switzerland; Stylianos. antonarakis@medecine. Results: We evaluated the performance of this method on 175 DNAs, highly enriched for abnormal unige.ch samples. A correct and unambiguous diagnosis was given for 119 out of 120 aneuploid samples as well as for all the controls. -

Novel Mutation and Three Other Sequence Variants Segregating with Phenotype at Keratoconus 13Q32 Susceptibility Locus
European Journal of Human Genetics (2012) 20, 389–397 & 2012 Macmillan Publishers Limited All rights reserved 1018-4813/12 www.nature.com/ejhg ARTICLE Novel mutation and three other sequence variants segregating with phenotype at keratoconus 13q32 susceptibility locus Marta Czugala1,6, Justyna A Karolak1,6, Dorota M Nowak1, Piotr Polakowski2, Jose Pitarque3, Andrea Molinari3, Malgorzata Rydzanicz1, Bassem A Bejjani4, Beatrice YJT Yue5, Jacek P Szaflik2 and Marzena Gajecka*,1 Keratoconus (KTCN), a non-inflammatory corneal disorder characterized by stromal thinning, represents a major cause of corneal transplantations. Genetic and environmental factors have a role in the etiology of this complex disease. Previously reported linkage analysis revealed that chromosomal region 13q32 is likely to contain causative gene(s) for familial KTCN. Consequently, we have chosen eight positional candidate genes in this region: MBNL1, IPO5, FARP1, RNF113B, STK24, DOCK9, ZIC5 and ZIC2, and sequenced all of them in 51 individuals from Ecuadorian KTCN families and 105 matching controls. The mutation screening identified one mutation and three sequence variants showing 100% segregation under a dominant model with KTCN phenotype in one large Ecuadorian family. These substitutions were found in three different genes: c.2262A4C (p.Gln754His) and c.720+43A4GinDOCK9; c.2377-132A4CinIPO5 and c.1053+29G4CinSTK24. PolyPhen analyses predicted that c.2262A4C (Gln754His) is possibly damaging for the protein function and structure. Our results suggest that c.2262A4C (p.Gln754His) -
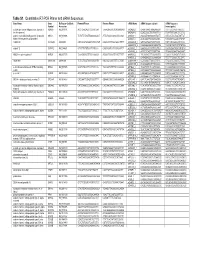
Table S1. Quantitative RT-PCR Primer and Sirna Sequences Gene Name
Table S1. Quantitative RT-PCR Primer and siRNA Sequences Gene Name Gene RefSeq or GenBank Forward Primer Reverse Primer siRNA Name siRNA Sequence (plus) siRNA Sequence Symbol Accession (minus/guide) a disintegrin and metalloproteinase domain 9 ADAM9 NM_003816 ACCTCAGCAGTTCCCATCAA TAAAGGAGGTGCAGGAGCAG siADAM9_1 GAGATTAACTAGAGAAAGA TCTTTCTCTAGTTAATCTC (meltrin gamma) siADAM9_2 GGAGGGAGTTCATAATTCA TGAATTATGAACTCCCTCC guanine nucleotide binding protein (G protein), GNAI3 NM_006496 TCTGTTATAGTTGGCGGCAGT ATTCTGCAAAGGCAAAAGGA siGNAI3_1 AGAACTAGCAGGAGTGATT AATCACTCCTGCTAGTTCT alpha inhibiting activity polypeptide 3 siGNAI3_2 ACACAGGTTCCAATACATA TATGTATTGGAACCTGTGT AA099748 AA099748 AA099748 CTACCACTGAGGTGTCCCTGT CAGCCATCTAACAGCATTTTT siAA099748_1 GTTAGATGGCTGATTAATA TATTAATCAGCCATCTAAC siAA099748_2 CGACAGAGGAGCAGCATTA TAATGCTGCTCCTCTGTCG calpain 12 CAPN12 NM_144691 GTCCTTCTGTCCCTCATCCA CAGCAGCTCCTCTGGAATCT siCAPN12_1 GGACACGCGTATTCCATCA TGATGGAATACGCGTGTCC siCAPN12_2 AATCCTCAGTTCCGTTTAA TTAAACGGAACTGAGGATT NMDA receptor regulated 1 NARG1 NM_057175 TAAAGGGAATTTGCCGAAGA AGCACTGGAGTTCGGTTTGT siNARG1_1 TGCGAGATCTTGAGGGTTA TAACCCTCAAGATCTCGCA siNARG1_2 GATAGGAGGTCCAAAAGAA TTCTTTTGGACCTCCTATC AK091308 AK091308 AK091308 TCTCCTGAATGGGAGGAATG GGCAACAGATGTTTCCTGTG siAK091308_1 CCAAAGACTTAGACTGTAA TTACAGTCTAAGTCTTTGG siAK091308_2 GCACAAAGCATTTACAACA TGTTGTAAATGCTTTGTGC serine/threonine kinase 24 (STE20 homolog, STK24 NM_003576 GCATCTGCCTTCCTTATCCA TGACAGTGTTTTGCCAGAGG siSTK24_1 TCGATTATCTCCATTCGGA TCCGAATGGAGATAATCGA yeast) siSTK24_2 CATCGGACTTGGACAGAAA -

STK24 Antibody - C-Terminal Region Rabbit Polyclonal Antibody Catalog # AI16132
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 STK24 Antibody - C-terminal region Rabbit Polyclonal Antibody Catalog # AI16132 Specification STK24 Antibody - C-terminal region - Product Information Application WB Primary Accession Q9Y6E0 Other Accession NP_003567 Reactivity Human Host Rabbit Clonality Polyclonal Calculated MW 48kDa KDa STK24 Antibody - C-terminal region - Additional Information Host: Rabbit Target Name: STK24 Gene ID 8428 Sample Tissue: 293T Whole Cell lysates Antibody Dilution: 1.0μg/ml Alias Symbol STK24, MST3, STK3, Other Names STK24 Antibody - C-terminal region - Serine/threonine-protein kinase 24, Background 2.7.11.1, Mammalian STE20-like protein kinase 3, MST-3, STE20-like kinase MST3, Serine/threonine-protein kinase that acts on Serine/threonine-protein kinase 24 36 kDa both serine and threonine residues and subunit, Mammalian STE20-like protein promotes apoptosis in response to stress kinase 3 N-terminal, MST3/N, stimuli and caspase activation. Mediates Serine/threonine-protein kinase 24 12 kDa oxidative-stress- induced cell death by subunit, Mammalian STE20-like protein modulating phosphorylation of JNK1-JNK2 kinase 3 C-terminal, MST3/C, STK24, MST3, (MAPK8 and MAPK9), p38 (MAPK11, MAPK12, STK3 MAPK13 and MAPK14) during oxidative stress. Plays a role in a staurosporine-induced Format caspase- independent apoptotic pathway by Liquid. Purified antibody supplied in 1x PBS buffer with 0.09% (w/v) sodium azide and regulating the nuclear translocation of AIFM1 2% sucrose. and ENDOG and the DNase activity associated with ENDOG. Phosphorylates STK38L on Reconstitution & Storage 'Thr-442' and stimulates its kinase activity. Add 50 &mu, l of distilled water. -

MST3 (STK24) (NM 001032296) Human Tagged ORF Clone Lentiviral Particle Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC209117L4V MST3 (STK24) (NM_001032296) Human Tagged ORF Clone Lentiviral Particle Product data: Product Type: Lentiviral Particles Product Name: MST3 (STK24) (NM_001032296) Human Tagged ORF Clone Lentiviral Particle Symbol: STK24 Synonyms: HEL-S-95; MST3; MST3B; STE20; STK3 Vector: pLenti-C-mGFP-P2A-Puro (PS100093) ACCN: NM_001032296 ORF Size: 1293 bp ORF Nucleotide The ORF insert of this clone is exactly the same as(RC209117). Sequence: OTI Disclaimer: The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info OTI Annotation: This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. RefSeq: NM_001032296.2 RefSeq Size: 4624 bp RefSeq ORF: 1296 bp Locus ID: 8428 UniProt ID: Q9Y6E0, Q5U0E6, Q6P0Y1 Protein Families: Druggable Genome, Protein Kinase MW: 47.7 kDa Gene Summary: This gene encodes a serine/threonine protein kinase that functions upstream of mitogen- activated protein kinase (MAPK) signaling. The encoded protein is cleaved into two chains by caspases; the N-terminal fragment (MST3/N) translocates to the nucleus and promotes programmed cells death. -

STRIPAK Complexes in Cell Signaling and Cancer
Oncogene (2016), 1–9 © 2016 Macmillan Publishers Limited All rights reserved 0950-9232/16 www.nature.com/onc REVIEW STRIPAK complexes in cell signaling and cancer Z Shi1,2, S Jiao1 and Z Zhou1,3 Striatin-interacting phosphatase and kinase (STRIPAK) complexes are striatin-centered multicomponent supramolecular structures containing both kinases and phosphatases. STRIPAK complexes are evolutionarily conserved and have critical roles in protein (de) phosphorylation. Recent studies indicate that STRIPAK complexes are emerging mediators and regulators of multiple vital signaling pathways including Hippo, MAPK (mitogen-activated protein kinase), nuclear receptor and cytoskeleton remodeling. Different types of STRIPAK complexes are extensively involved in a variety of fundamental biological processes ranging from cell growth, differentiation, proliferation and apoptosis to metabolism, immune regulation and tumorigenesis. Growing evidence correlates dysregulation of STRIPAK complexes with human diseases including cancer. In this review, we summarize the current understanding of the assembly and functions of STRIPAK complexes, with a special focus on cell signaling and cancer. Oncogene advance online publication, 15 February 2016; doi:10.1038/onc.2016.9 INTRODUCTION in the central nervous system and STRN4 is mostly abundant in Recent proteomic studies identified a group of novel multi- the brain and lung, whereas STRN3 is ubiquitously expressed in 5–9 component complexes named striatin (STRN)-interacting phos- almost all tissues. STRNs share a -

STRIPAK Directs PP2A Activity Toward MAP4K4 to Promote Oncogenic Transformation
bioRxiv preprint doi: https://doi.org/10.1101/823096; this version posted October 29, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. STRIPAK directs PP2A activity toward MAP4K4 to promote oncogenic transformation Jong Wook Kim1,2,7,8*, Christian Berrios2,4*, Miju Kim1,2*, Amy E. Schade2,4*, Guillaume Adelmant5, Huwate Yeerna7, Emily Damato1, Amanda Balboni Iniguez1,6, Selene K. Swanson9, Laurence Florens9, Michael P. Washburn9.10, Kim Stegmaier1,6, Nathaniel S. Gray5, Pablo Tamayo7,8, Ole Gjoerup2, Jarrod A. Marto5, James A. DeCaprio2,3,4,†, William C. Hahn1, 2, 3,† 1Broad Institute of Harvard and MIT, Cambridge MA. 2Department of Medical Oncology, Dana-Farber Cancer Institute, Boston MA. 3Department of Medicine, Brigham and Women's Hospital and Harvard Medical School, Boston MA. 4Program in Virology, Graduate School of Arts and Sciences, Harvard University, Cambridge, MA. 5Department of Cancer Biology and Blais Proteomics Center, Dana-Farber Cancer Institute, Boston MA. 6Department of Pediatric Oncology, Dana-Farber Cancer Institute, Boston MA. 7Division of Medical Genetics, School of Medicine, UC San Diego, CA. 8Moores Cancer Center, University of California, San Diego, CA. 9Stowers Institute for Medical Research, Kansas City, MO 64110 10Department of Pathology and Laboratory Medicine, University of Kansas Medical Center, Kansas City, KS 66160 * These authors contributed equally to the work. †Co-senior authors 1 bioRxiv preprint doi: https://doi.org/10.1101/823096; this version posted October 29, 2019. -

Cerebral Cavernous Malformation Proteins in Barrier Maintenance and Regulation
International Journal of Molecular Sciences Review Cerebral Cavernous Malformation Proteins in Barrier Maintenance and Regulation 1,2, 2, 3 2 3 Shu Wei y, Ye Li y, Sean P. Polster , Christopher R. Weber , Issam A. Awad and Le Shen 2,3,* 1 Graduate Program in Public Health and Preventive Medicine, Wuhan University of Science and Technology, Wuhan 430081, China; [email protected] 2 Department of Pathology, The University of Chicago, Chicago, IL 60615, USA; [email protected] (Y.L.); [email protected] (C.R.W.) 3 Section of Neurosurgery, Department of Surgery, The University of Chicago, Chicago, IL 60615, USA; [email protected] (S.P.P.); [email protected] (I.A.A.) * Correspondence: [email protected] These authors contributed equally. y Received: 10 December 2019; Accepted: 15 January 2020; Published: 20 January 2020 Abstract: Cerebral cavernous malformation (CCM) is a disease characterized by mulberry shaped clusters of dilated microvessels, primarily in the central nervous system. Such lesions can cause seizures, headaches, and stroke from brain bleeding. Loss-of-function germline and somatic mutations of a group of genes, called CCM genes, have been attributed to disease pathogenesis. In this review, we discuss the impact of CCM gene encoded proteins on cellular signaling, barrier function of endothelium and epithelium, and their contribution to CCM and potentially other diseases. Keywords: cerebral cavernous malformation; endothelial barrier; epithelial barrier; Rho; ROCK; MEKK3 1. Introduction One of the key functions of endothelial and epithelial cells is to create a barrier that separates different tissue compartments, and in the case of skin, epithelial cells separate body and outer environment. -

Global Proteomic Detection of Native, Stable, Soluble Human Protein Complexes
GLOBAL PROTEOMIC DETECTION OF NATIVE, STABLE, SOLUBLE HUMAN PROTEIN COMPLEXES by Pierre Claver Havugimana A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Graduate Department of Molecular Genetics University of Toronto © Copyright by Pierre Claver Havugimana 2012 Global Proteomic Detection of Native, Stable, Soluble Human Protein Complexes Pierre Claver Havugimana Doctor of Philosophy Graduate Department of Molecular Genetics University of Toronto 2012 Abstract Protein complexes are critical to virtually every biological process performed by living organisms. The cellular “interactome”, or set of physical protein-protein interactions, is of particular interest, but no comprehensive study of human multi-protein complexes has yet been reported. In this Thesis, I describe the development of a novel high-throughput profiling method, which I term Fractionomic Profiling-Mass Spectrometry (or FP-MS), in which biochemical fractionation using non-denaturing high performance liquid chromatography (HPLC), as an alternative to affinity purification (e.g. TAP tagging) or immuno-precipitation, is coupled with tandem mass spectrometry-based protein identification for the global detection of stably- associated protein complexes in mammalian cells or tissues. Using a cell culture model system, I document proof-of-principle experiments confirming the suitability of this method for monitoring large numbers of soluble, stable protein complexes from either crude protein extracts or enriched sub-cellular compartments. Next, I document how, using orthogonal functional genomics information generated in collaboration with computational biology groups as filters, we applied FP-MS co-fractionation profiling to construct a high-quality map of 622 predicted unique soluble human protein complexes that could be biochemically enriched from HeLa and HEK293 nuclear and cytoplasmic extracts. -

Protein Expression and Purification
Protein Expression and Purification 81 (2012) 136–143 Contents lists available at SciVerse ScienceDirect Protein Expression and Purification journal homepage: www.elsevier.com/locate/yprep Analysis of conditions affecting auto-phosphorylation of human kinases during expression in bacteria ⇑ Amit Shrestha a, Garth Hamilton b, Eric O’Neill b, Stefan Knapp a, Jonathan M. Elkins a, a Structural Genomics Consortium, Oxford University, Old Road Campus Research Building, Old Road Campus, Roosevelt Drive, Oxford OX3 7DQ, UK b Gray Institute for Radiation Oncology and Biology, Old Road Campus Research Building, Old Road Campus, Roosevelt Drive, Oxford OX3 7DQ, UK article info abstract Article history: Bacterial over-expression of kinases is often associated with high levels of auto-phosphorylation result- Received 6 October 2010 ing in heterogeneous recombinant protein preparations or sometimes in insoluble protein. Here we pres- and in revised form 22 September 2011 ent expression systems for nine kinases in Escherichia coli and, for the most heavily phosphorylated, the Available online 1 October 2011 characterisation of factors affecting auto-phosphorylation. Experiments showed that the level of auto- phosphorylation was proportional to the rate of expression. Comparison of phosphorylation states fol- Keywords: lowing in vitro phosphorylation with phosphorylation states following expression in E. coli showed that Kinase the non-physiological ‘hyper-phosphorylation’ was occurring at sites that would require local unfolding Expression to be accessible to a kinase active site. In contrast, auto-phosphorylation on unphosphorylated kinases Purification Auto-phosphorylation that had been expressed in bacteria overexpressing k-phosphatase was only observed on distinct exposed sites. Remarkably, the Ser/Thr kinase PLK4 auto-phosphorylated on a tyrosine residue (Tyr177) located in the activation segment. -

MOB (Mps One Binder) Proteins in the Hippo Pathway and Cancer
Review MOB (Mps one Binder) Proteins in the Hippo Pathway and Cancer Ramazan Gundogdu 1 and Alexander Hergovich 2,* 1 Vocational School of Health Services, Bingol University, 12000 Bingol, Turkey; [email protected] 2 UCL Cancer Institute, University College London, WC1E 6BT, London, United Kingdom * Correspondence: [email protected]; Tel.: +44 20 7679 2000; Fax: +44 20 7679 6817 Received: 1 May 2019; Accepted: 4 June 2019; Published: 10 June 2019 Abstract: The family of MOBs (monopolar spindle-one-binder proteins) is highly conserved in the eukaryotic kingdom. MOBs represent globular scaffold proteins without any known enzymatic activities. They can act as signal transducers in essential intracellular pathways. MOBs have diverse cancer-associated cellular functions through regulatory interactions with members of the NDR/LATS kinase family. By forming additional complexes with serine/threonine protein kinases of the germinal centre kinase families, other enzymes and scaffolding factors, MOBs appear to be linked to an even broader disease spectrum. Here, we review our current understanding of this emerging protein family, with emphases on post-translational modifications, protein-protein interactions, and cellular processes that are possibly linked to cancer and other diseases. In particular, we summarise the roles of MOBs as core components of the Hippo tissue growth and regeneration pathway. Keywords: Mps one binder; Hippo pathway; protein kinase; signal transduction; phosphorylation; protein-protein interactions; structure biology; STK38; NDR; LATS; MST; STRIPAK 1. Introduction The family of MOBs (monopolar spindle-one-binder proteins) is highly conserved in eukaryotes [1–4]. To our knowledge, at least two different MOBs have been found in every eukaryote analysed so far. -

A High-Throughput Study in Melanoma Identifies Epithelial- Mesenchymal Transition As a Major Determinant of Metastasis
Research Article A High-Throughput Study in Melanoma Identifies Epithelial- Mesenchymal Transition as a Major Determinant of Metastasis Soledad R. Alonso,1 Lorraine Tracey,1 Pablo Ortiz,4 Beatriz Pe´rez-Go´mez,5 Jose´ Palacios,1 Marina Polla´n,5 Juan Linares,6 Salvio Serrano,7 Ana I. Sa´ez-Castillo,6 Lydia Sa´nchez,2 Raquel Pajares,2 Abel Sa´nchez-Aguilera,1 Maria J. Artiga,1 Miguel A. Piris,1 and Jose´ L. Rodrı´guez-Peralto3 1Molecular Pathology Programme and 2Histology and Immunohistochemistry Unit, Centro Nacional de Investigaciones Oncolo´gicas; Departments of 3Pathology and 4Dermatology, Hospital Universitario 12 de Octubre; 5Centro Nacional de Epidemiologı´a, Instituto de Salud Carlos III, Madrid, Spain; and Departments of 6Pathology and 7Dermatology, Hospital Universitario San Cecilio, Granada, Spain Abstract with a less favorable prognosis as potential candidates for adjuvant Metastatic disease is the primary cause of death in cutaneous or novel therapies. malignant melanoma (CMM) patients. To understand the Currently, the prognosis of primary CMM is mainly based mechanisms of CMM metastasis and identify potential on histopathologic criteria. The most important of these is the predictive markers, we analyzed gene-expression profiles of Breslow index, although it is merely a measure of tumor depth. 34 vertical growth phase melanoma cases using cDNA micro- New molecular markers that correlate with melanoma genesis and/or progression are continuously being identified but, to date, arrays. All patients had a minimum follow-up of 36 months. Twenty-one cases developed nodal metastatic disease and 13 most of them have been obtained in experimental models and did not.