Introduction Jia Zeng* Mehmet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kūnqǔ in Practice: a Case Study
KŪNQǓ IN PRACTICE: A CASE STUDY A DISSERTATION SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI‘I AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN THEATRE OCTOBER 2019 By Ju-Hua Wei Dissertation Committee: Elizabeth A. Wichmann-Walczak, Chairperson Lurana Donnels O’Malley Kirstin A. Pauka Cathryn H. Clayton Shana J. Brown Keywords: kunqu, kunju, opera, performance, text, music, creation, practice, Wei Liangfu © 2019, Ju-Hua Wei ii ACKNOWLEDGEMENTS I wish to express my gratitude to the individuals who helped me in completion of my dissertation and on my journey of exploring the world of theatre and music: Shén Fúqìng 沈福庆 (1933-2013), for being a thoughtful teacher and a father figure. He taught me the spirit of jīngjù and demonstrated the ultimate fine art of jīngjù music and singing. He was an inspiration to all of us who learned from him. And to his spouse, Zhāng Qìnglán 张庆兰, for her motherly love during my jīngjù research in Nánjīng 南京. Sūn Jiàn’ān 孙建安, for being a great mentor to me, bringing me along on all occasions, introducing me to the production team which initiated the project for my dissertation, attending the kūnqǔ performances in which he was involved, meeting his kūnqǔ expert friends, listening to his music lessons, and more; anything which he thought might benefit my understanding of all aspects of kūnqǔ. I am grateful for all his support and his profound knowledge of kūnqǔ music composition. Wichmann-Walczak, Elizabeth, for her years of endeavor producing jīngjù productions in the US. -

Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation
Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation A/L Krishnan Thiinash Bachelor of Information Technology March 2015 A/L Selvaraju Theeban Raju Bachelor of Commerce January 2015 A/P Balan Durgarani Bachelor of Commerce with Distinction March 2015 A/P Rajaram Koushalya Priya Bachelor of Commerce March 2015 Hiba Mohsin Mohammed Master of Health Leadership and Aal-Yaseen Hussein Management July 2015 Aamer Muhammad Master of Quality Management September 2015 Abbas Hanaa Safy Seyam Master of Business Administration with Distinction March 2015 Abbasi Muhammad Hamza Master of International Business March 2015 Abdallah AlMustafa Hussein Saad Elsayed Bachelor of Commerce March 2015 Abdallah Asma Samir Lutfi Master of Strategic Marketing September 2015 Abdallah Moh'd Jawdat Abdel Rahman Master of International Business July 2015 AbdelAaty Mosa Amany Abdelkader Saad Master of Media and Communications with Distinction March 2015 Abdel-Karim Mervat Graduate Diploma in TESOL July 2015 Abdelmalik Mark Maher Abdelmesseh Bachelor of Commerce March 2015 Master of Strategic Human Resource Abdelrahman Abdo Mohammed Talat Abdelziz Management September 2015 Graduate Certificate in Health and Abdel-Sayed Mario Physical Education July 2015 Sherif Ahmed Fathy AbdRabou Abdelmohsen Master of Strategic Marketing September 2015 Abdul Hakeem Siti Fatimah Binte Bachelor of Science January 2015 Abdul Haq Shaddad Yousef Ibrahim Master of Strategic Marketing March 2015 Abdul Rahman Al Jabier Bachelor of Engineering Honours Class II, Division 1 -
![UNIT 1 味道怎么样? [Wèi-Dào Zěn-Me Yàng?] How Is the Taste?](https://docslib.b-cdn.net/cover/4270/unit-1-w%C3%A8i-d%C3%A0o-z%C4%9Bn-me-y%C3%A0ng-how-is-the-taste-554270.webp)
UNIT 1 味道怎么样? [Wèi-Dào Zěn-Me Yàng?] How Is the Taste?
1 UNIT 1 味道怎么样? [wèi-dào zěn-me yàng?] How is the taste? The following is a conversation between the waitress at 好好茶餐廳 and a customer whom just arrived at the restaurant. : 你好,请问⼏位?(nǐ*-hǎo, qǐng-wèn jǐ wèi?) 你好,请问⼏位?(nei5-hou2, cing2-man6 gei2-wai2?) Hi, How many people please? : 两位,谢谢。(liǎng-wèi, xiè-xie) 两位,唔该。 (loeng5-wai2, m4-goi1) Two people, please. 我们已经订位了。(wǒ-men yǐ-jīng dìng-wèi le) 我哋已经订咗位。(ngo5-dei6 ji5-ging1 deng6 zo2 wai2) We already made a reservation. : 好的。请问你叫什么名字?(hǎo-de. qǐng-wèn nǐ jiào shén-me míng-zì?) 好。请问你叫咩名呀?(hou2. cing2-man6 nei5 giu3 me1 meng2 aa3?) Okay. What is your name, please? : 我姓叶。(wǒ xìng yè) 我姓叶。(ngo5 sing3 jip6) My last name is Yip. : 我找到了,两位请跟我来。(wǒ* zhǎo dào le, liǎng wèi qǐng gēn wǒ lái) 我搵到喇。两位请跟我嚟。(ngo5 wan2 dou2 laa3. loeng5-wai2 cing2 gan1 ngo5 lei4) Original material under copyright, 2020 Jade Jia Ying Wu 2 I found it, please come follow me. : 请问两位想喝什么? (qǐng-wèn liǎng-wèi xiǎng hē shén-me?) 请问两位想饮咩呀?(cing2-man6 loeng5-wai2 soeng2 jam2 me1 aa3?) What would you two like to drink? : 我想要⼀杯港式奶茶。(wǒ* xiǎng yào yì-bēi gǎng shì nǎi-chá) 我想要⼀杯港式奶茶。(ngo5 soeng2 jiu3 jat1-bui1 gong2-sik1 naai5-caa4) I would like a Hong Kong-style milk tea. : 我要⽔就⾏了。(wǒ yào shuǐ jiù xíng le) 我要⽔就得喇。(ngo5 jiu3 seoi2 zau6 dak1 laa3) Water is fine for me. : 你们想吃什么?(nǐ-men xiǎng chī shén-me?) 你哋想⾷咩呀?(nei5-dei6 soeng2 sik6 me1 aa3?) What would you like to eat? : 我想要⼀个鲜虾馄饨⾯。(wǒ xiǎng* yào yí-gè xiān xiā hún-tūn miàn) 我想要⼀個鲜虾馄饨⾯。(ngo5 soeng2 jiu3 jat1-go3 sin1 haa1 wan4-tan1 min6) I would like a shrimp wonton noodle soup. -

中国人的姓名 王海敏 Wang Hai Min
中国人的姓名 王海敏 Wang Hai min last name first name Haimin Wang 王海敏 Chinese People’s Names Two parts Last name First name 姚明 Yao Ming Last First name name Jackie Chan 成龙 cheng long Last First name name Bruce Lee 李小龙 li xiao long Last First name name The surname has roughly several origins as follows: 1. the creatures worshipped in remote antiquity . 龙long, 马ma, 牛niu, 羊yang, 2. ancient states’ names 赵zhao, 宋song, 秦qin, 吴wu, 周zhou 韩han,郑zheng, 陈chen 3. an ancient official titles 司马sima, 司徒situ 4. the profession. 陶tao,钱qian, 张zhang 5. the location and scene in residential places 江jiang,柳 liu 6.the rank or title of nobility 王wang,李li • Most are one-character surnames, but some are compound surname made up of two of more characters. • 3500Chinese surnames • 100 commonly used surnames • The three most common are 张zhang, 王wang and 李li What does my name mean? first name strong beautiful lively courageous pure gentle intelligent 1.A person has an infant name and an official one. 2.In the past,the given names were arranged in the order of the seniority in the family hierarchy. 3.It’s the Chinese people’s wish to give their children a name which sounds good and meaningful. Project:Search on-Line www.Mandarinintools.com/chinesename.html Find Chinese Names for yourself, your brother, sisters, mom and dad, or even your grandparents. Find meanings of these names. ----What is your name? 你叫什么名字? ni jiao shen me ming zi? ------ 我叫王海敏 wo jiao Wang Hai min ------ What is your last name? 你姓什么? ni xing shen me? (你贵姓?)ni gui xing? ------ 我姓 王,王海敏。 wo xing wang, Wang Hai min ----- What is your nationality? 你是哪国人? ni shi na guo ren? ----- I am chinese/American 我是中国人/美国人 Wo shi zhong guo ren/mei guo ren 百家 姓 bai jia xing 赵(zhào) 钱(qián) 孙(sūn) 李(lǐ) 周(zhōu) 吴(wú) 郑(zhèng) 王(wán 冯(féng) 陈(chén) 褚(chǔ) 卫(wèi) 蒋(jiǎng) 沈(shěn) 韩(hán) 杨(yáng) 朱(zhū) 秦(qín) 尤(yóu) 许(xǔ) 何(hé) 吕(lǚ) 施(shī) 张(zhāng). -

The Case of Wang Wei (Ca
_full_journalsubtitle: International Journal of Chinese Studies/Revue Internationale de Sinologie _full_abbrevjournaltitle: TPAO _full_ppubnumber: ISSN 0082-5433 (print version) _full_epubnumber: ISSN 1568-5322 (online version) _full_issue: 5-6_full_issuetitle: 0 _full_alt_author_running_head (neem stramien J2 voor dit article en vul alleen 0 in hierna): Sufeng Xu _full_alt_articletitle_deel (kopregel rechts, hier invullen): The Courtesan as Famous Scholar _full_is_advance_article: 0 _full_article_language: en indien anders: engelse articletitle: 0 _full_alt_articletitle_toc: 0 T’OUNG PAO The Courtesan as Famous Scholar T’oung Pao 105 (2019) 587-630 www.brill.com/tpao 587 The Courtesan as Famous Scholar: The Case of Wang Wei (ca. 1598-ca. 1647) Sufeng Xu University of Ottawa Recent scholarship has paid special attention to late Ming courtesans as a social and cultural phenomenon. Scholars have rediscovered the many roles that courtesans played and recognized their significance in the creation of a unique cultural atmosphere in the late Ming literati world.1 However, there has been a tendency to situate the flourishing of late Ming courtesan culture within the mainstream Confucian tradition, assuming that “the late Ming courtesan” continued to be “integral to the operation of the civil-service examination, the process that re- produced the empire’s political and cultural elites,” as was the case in earlier dynasties, such as the Tang.2 This assumption has suggested a division between the world of the Chinese courtesan whose primary clientele continued to be constituted by scholar-officials until the eight- eenth century and that of her Japanese counterpart whose rise in the mid- seventeenth century was due to the decline of elitist samurai- 1) For important studies on late Ming high courtesan culture, see Kang-i Sun Chang, The Late Ming Poet Ch’en Tzu-lung: Crises of Love and Loyalism (New Haven: Yale Univ. -

Jia Guo A, Hui Li A, Di Wang A, Liugen Zhang A, Yuhua Maa, Naeem Akram A, Yi Zhang B, Jide Wang A,*
Electronic Supplementary Material (ESI) for Catalysis Science & Technology. This journal is © The Royal Society of Chemistry 2018 Electrical Supporting information An efficient difunctional photocatalyst prepared in situ from Prussian blue analogues for catalytic water oxidation and visible light absorption Jia Guo a, Hui Li a, Di Wang a, Liugen Zhang a, Yuhua Maa, Naeem Akram a, Yi Zhang b, Jide Wang a,* a Key Laboratory of Oil and Gas Fine Chemicals,Ministry of Education & Xinjiang Uygur Autonomous Region,College of Chemistry and Chemical Engineering of Xinjiang University, Urumqi, 830046, China b Hunan Provincial Key Laboratory of Efficient and Clean Utilization of Manganese Resources, College of Chemistry and Chemical Engineering, Central South University, Changsha 410083, Hunan, China ∗ Corresponding author. E-mail: [email protected] Synthesis of CuO and Co(OH)2 The synthesis of CuO was according to the reported literature.[34] 1.20 g of Cu(CH3COO)2·H2O was dissolved in 300 mL of distilled water in a round-bottomed flask equipped with a refluxing device. 1.00 mL glacial acetic acid was added by providing continuous magnetic stirring; a blue solution was appeared. This blue solution was then heated to 40 oC, 0.80 g of NaOH (s) was quickly added into the solution and then again heated to 100 oC for 30 min, where a large amount of brownish black precipitate was produced. After cooling it to the room temperature, the precipitate was centrifuged, washed once with distilled water and dried in a o vacuum oven at 80 C during whole night. The method of synthesis Co(OH)2 was similar to CuO expect that the reaction time was 1 h. -

Ideophones in Middle Chinese
KU LEUVEN FACULTY OF ARTS BLIJDE INKOMSTSTRAAT 21 BOX 3301 3000 LEUVEN, BELGIË ! Ideophones in Middle Chinese: A Typological Study of a Tang Dynasty Poetic Corpus Thomas'Van'Hoey' ' Presented(in(fulfilment(of(the(requirements(for(the(degree(of(( Master(of(Arts(in(Linguistics( ( Supervisor:(prof.(dr.(Jean=Christophe(Verstraete((promotor)( ( ( Academic(year(2014=2015 149(431(characters Abstract (English) Ideophones in Middle Chinese: A Typological Study of a Tang Dynasty Poetic Corpus Thomas Van Hoey This M.A. thesis investigates ideophones in Tang dynasty (618-907 AD) Middle Chinese (Sinitic, Sino- Tibetan) from a typological perspective. Ideophones are defined as a set of words that are phonologically and morphologically marked and depict some form of sensory image (Dingemanse 2011b). Middle Chinese has a large body of ideophones, whose domains range from the depiction of sound, movement, visual and other external senses to the depiction of internal senses (cf. Dingemanse 2012a). There is some work on modern variants of Sinitic languages (cf. Mok 2001; Bodomo 2006; de Sousa 2008; de Sousa 2011; Meng 2012; Wu 2014), but so far, there is no encompassing study of ideophones of a stage in the historical development of Sinitic languages. The purpose of this study is to develop a descriptive model for ideophones in Middle Chinese, which is compatible with what we know about them cross-linguistically. The main research question of this study is “what are the phonological, morphological, semantic and syntactic features of ideophones in Middle Chinese?” This question is studied in terms of three parameters, viz. the parameters of form, of meaning and of use. -

Huaqiang ZENG Team Leader and Principal Research Scientist
Huaqiang ZENG Team Leader and Principal Research Scientist +65 6824 7115 [email protected] Team Leader and Principal Research Scientist, NanoBio Lab, Singapore, 2019-present Team Leader and Principal Research Scientist, Institute of Bioengineering and Nanotechnology, Singapore, 2014-2019 Assistant Professor, National University of Singapore, 2006-2013 Postdoctoral Research Fellow, The Scripps Research Institute, USA, 2002-2006 Ph.D. in Organic Chemistry, The State University of New York at Buffalo, USA, 2002 B.S. in Chemical Physics, The University of Science and Technology of China, 1996 Publications 1. A. Roy, H. Joshi, R. Ye, J. Shen, F. Chen, A. Aksimentiev and H. Zeng, “Polyhydrazide‐Based Organic Nanotubes as Efficient and Selective Artificial Iodide Channels,” Angewandte Chemie International Edition, 132 (2020) 4836-4843. IF 12.102 2. J. Shen, J. Fan, R. Ye, N. Li, Y. Mu and H. Zeng, “Polypyridine-Based Helical Amide Foldamer Channels for Rapid Transport of Water and Proton with High Ion Rejection,” Angewandte Chemie International Edition, (2020) DOI: 10.1002/anie.202003512. IF 12.257 3. J. Shen, R. Ye, A. Romanies, A. Roy, F. Chen, C. Ren, Z. Liu and H. Zeng, “An Aquafoldmer-Based Aquaporin-Like Synthetic Water Channel,” Journal of the American Chemical Society, 142 (2020) 10050-10058. IF 14.695 4. H. Zeng, A. Roy, H. Joshi, R. Ye, J. Shen, F. Chen and A. Aksimentiev, “Polyhydrazide-Based Organic Nanotubes as Extremely Efficient and Highly Selective Artificial Iodide Channels,” Angew. Chem. Int. Ed., (2020) DOI: 10.1002/anie.201916287 5. H. Zeng, F. Chen, J. Shen, N. Li, A. -

JIA LIU LSK4051, Hong Kong University of Science & Technology Clear Water Bay, Hong Kong [email protected] +852 2358-7709 (Updated September 2020)
JIA LIU LSK4051, Hong Kong University of Science & Technology Clear Water Bay, Hong Kong [email protected] +852 2358-7709 (Updated September 2020) EDUCATION Columbia University, New York, NY Ph.D. in Marketing, 2017 M.S. in Marketing, 2011 Michigan State University, East Lansing, MI M.S. in Statistics, 2010 Tianjin University, Tianjin, China B.S. in Mathematics, 2008 ACADEMIC POSITIONS Hong Kong University of Science & Technology, HK Assistant Professor in Marketing, Aug. 2018 - present PROFESSIONAL EXPERIENCE Microsoft Research, New York, NY Postdoctoral Researcher, mentored by Duncan Watts, Aug. 2017 - June 2018 Research Intern, mentored by Shawndra Hill, May - July, 2016 Consulting Researcher, Computational Social Science Group, February - April, 2016 Advertising Research Foundation, New York, NY Research Intern, under the supervision of Dr. William Cook, May-Aug. 2011 RESEARCH INTERESTS Substantive: Consumer Online Search, Search Engine Marketing, TV Advertising, Cross- Channel Advertising, Loyalty Programs, Behavioral Economics, Recommendation Sys- tem, User Generated Content, Social Media Methodological: Topic Modeling, Natural Language Processing, Machine Learning, Deep Neural Network, Bayesian Methods, Causal Inference, Lab/Field Experiments Jia Liu j 1 PUBLICATIONS(∗INDICATES EQUAL AUTHORSHIP) Liu, Jia, Olivier Toubia, and Shawndra Hill (2020), “Content-based Model of Web Search Behavior: An Application to TV Show Search.” forthcoming at Management Science. - Best paper award at the 2018 China Marketing International Conference Liu, Jia, and Asim Ansari (2020), “Understanding Consumer Dynamic Decision Making Un- der Competing Loyalty Programs.” Journal of Marketing Research, 57(3), 422-444. [Link] Liu, Jia∗, and Olivier Toubia∗ (2020), “Search Query Formation by Strategic Consumers.” Quantitative Marketing and Economics, 18, 155-194. [Link] Liu, Jia, and Olivier Toubia (2018), “A Semantic Approach for Estimating Consumer Content Preferences from Online Search Queries.” Marketing Science, 37 (6), 930-952. -

Origin Narratives: Reading and Reverence in Late-Ming China
Origin Narratives: Reading and Reverence in Late-Ming China Noga Ganany Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2018 © 2018 Noga Ganany All rights reserved ABSTRACT Origin Narratives: Reading and Reverence in Late Ming China Noga Ganany In this dissertation, I examine a genre of commercially-published, illustrated hagiographical books. Recounting the life stories of some of China’s most beloved cultural icons, from Confucius to Guanyin, I term these hagiographical books “origin narratives” (chushen zhuan 出身傳). Weaving a plethora of legends and ritual traditions into the new “vernacular” xiaoshuo format, origin narratives offered comprehensive portrayals of gods, sages, and immortals in narrative form, and were marketed to a general, lay readership. Their narratives were often accompanied by additional materials (or “paratexts”), such as worship manuals, advertisements for temples, and messages from the gods themselves, that reveal the intimate connection of these books to contemporaneous cultic reverence of their protagonists. The content and composition of origin narratives reflect the extensive range of possibilities of late-Ming xiaoshuo narrative writing, challenging our understanding of reading. I argue that origin narratives functioned as entertaining and informative encyclopedic sourcebooks that consolidated all knowledge about their protagonists, from their hagiographies to their ritual traditions. Origin narratives also alert us to the hagiographical substrate in late-imperial literature and religious practice, wherein widely-revered figures played multiple roles in the culture. The reverence of these cultural icons was constructed through the relationship between what I call the Three Ps: their personas (and life stories), the practices surrounding their lore, and the places associated with them (or “sacred geographies”). -

Using Online Applications to Improve Tone Perception Among L2 Learners of Chinese (网络应用对中文二语学习者声调辨识的有效性研究)
Journal of Technology and Chinese Language Teaching Volume 10 Number 1, June 2019 http://www.tclt.us/journal/2019v10n1/xulili.pdf pp. 26-56 Using Online Applications to Improve Tone Perception among L2 Learners of Chinese (网络应用对中文二语学习者声调辨识的有效性研究) Xu, Hongying Li, Yan Li, Yingjie (徐红英) (李艳) (李颖颉) University of University of University of Colorado- Wisconsin-La Crosse Kansas Boulder (威斯康星大学拉克 (堪萨斯大学) (科罗拉多大学博尔得分 罗校区) [email protected] 校) [email protected] [email protected] Abstract: This study investigated the effectiveness of an online application in helping beginning-level Chinese learners improve their perception of the tones in Mandarin Chinese. Two groups—one experimental and one traditional—of beginning Chinese learners from two universities in the Midwest participated in this study. The experimental group (n=20) used the online application to practice tones for four 15-minute sessions in class. The traditional group (n=11) participated in traditional instructor-led practice in class in lieu of the online practice. Both groups completed a pre-test, an immediately administered post-test, and a delayed post-test designed to assess their perception of the tones of monosyllabic and disyllabic words. No statistically significant difference has been found between the two groups in their tone perception performance in the post-test and in the delayed post-test. However, the experimental group showed a positive trend in improving their perception on those tones which posed more difficulty than others. Their experience with this online application and the pronunciation learning strategies of participants in the experimental group were also examined through a survey. Based on the findings, it is proposed that the use of online tone practice is worthwhile in a Chinese language class, but might fit better into the curriculum as external assignments. -
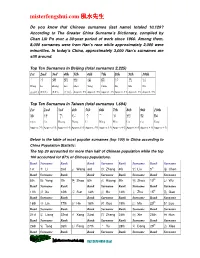
Misterfengshui.Com 風水先生
misterfengshui.com 風水先生 Do you know that Chinese surnames (last name) totaled 10,129? According to The Greater China Surname’s Dictionary, compiled by Chan Lik Pu over a 30-year period of work since 1960. Among them, 8,000 surnames were from Han’s race while approximately 2,000 were minorities. In today’s China, approximately 3,000 Han’s surnames are still around. Top Ten Surnames In Beijing (total surnames 2,225) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 王 李 張 劉 趙 楊 陳 徐 馬 吳 Wang Li Zhang Liu Zhao Yang Chen Xu Ma Wu (10.6% ) (9.6%) (9.6%) (7.7% ) Approx. 5% Approx. 5% Approx. 4% Approx. 4% Approx. 4% Approx. 3% Top Ten Surnames In Taiwan (total surnames 1,694) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 陳 林 黃 張 李 王 吳 劉 蔡 楊 Chen Lin Huang Zhang Li Wang Wux. Liu Cai Yang Approx .7% Approx 6 % Approx 6 % Approx 6 % Approx. 5% Approx 5 % Approx 4 % Approx 4 % Approx 4 % Approx 4 % Below is the table of most popular surnames (top 100) in China according to China Population Statistic: The top 20 accounted for more than half of Chinese population while the top 100 accounted for 87% of Chinese populations. Rank Surname Rank Rank Surname Rank Surname Rank Surname 1st 李 Li 2nd 王 Wang 3rd 張 Zhang 4th 劉 Liu 5th 陳 Chen Rank Surname Rank Rank Surname Rank Surname Rank Surname 6th 楊 Yang 7th 趙 Zhao 8th 黃 Huang 9th 周 Zhou 10 th 吳 Wu Rank Surname Rank Rank Surname Rank Surname Rank Surname 11th 徐 Xu 12th 孫 Sun 13th 胡 Hu 14th 朱 Zhu 15 th 高 Gao Rank Surname Rank Rank Surname Rank Surname Rank Surname 16th 林 Lin 17th 何 He 18th 郭 Guo 19th 馬 Ma 20 th 羅 Luo Rank