VLSI Design of Configurable Low-Power Coarse-Grained Array
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Prostep Ivip CPO Statement Template
CPO Statement of Mentor Graphics For Questa SIM Date: 17 June, 2015 CPO Statement of Mentor Graphics Following the prerequisites of ProSTEP iViP’s Code of PLM Openness (CPO) IT vendors shall determine and provide a list of their relevant products and the degree of fulfillment as a “CPO Statement” (cf. CPO Chapter 2.8). This CPO Statement refers to: Product Name Questa SIM Product Version Version 10 Contact Ellie Burns [email protected] This CPO Statement was created and published by Mentor Graphics in form of a self-assessment with regard to the CPO. Publication Date of this CPO Statement: 17 June 2015 Content 1 Executive Summary ______________________________________________________________________________ 2 2 Details of Self-Assessment ________________________________________________________________________ 3 2.1 CPO Chapter 2.1: Interoperability ________________________________________________________________ 3 2.2 CPO Chapter 2.2: Infrastructure _________________________________________________________________ 4 2.3 CPO Chapter 2.5: Standards ____________________________________________________________________ 4 2.4 CPO Chapter 2.6: Architecture __________________________________________________________________ 5 2.5 CPO Chapter 2.7: Partnership ___________________________________________________________________ 6 2.5.1 Data Generated by Users ___________________________________________________________________ 6 2.5.2 Partnership Models _______________________________________________________________________ 6 2.5.3 Support of -

Power Reduction of a CMOS High-Speed Interface Using Power Gating
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO Power reduction of a CMOS high-speed interface using power gating Luís Miguel Granja Gomes FOR JURY EVALUATION Mestrado Integrado em Engenharia Eletrotécnica e de Computadores FEUP Supervisor: Prof. João Canas Ferreira Synopsys Supervisor: Engineer Hélder Araújo June 25, 2013 c Luís Gomes, 2013 Resumo A indústria de circuitos VLSI sofreu uma série de revoluções na forma como os chips eletrónicos são projetados. Começou com o uso de linguagens de descrição de hardware e de avançadas ferramentas de trabalho, com o objetivo de diminuir os tempos de projeto e de produção, ao mesmo tempo que circuitos mais rápidos e pequenos eram construídos. A produção de dispos- itivos eletrónicos aumentou significativamente, de tal modo que, hoje, são usados biliões todos os dias. Atualmente, o maior desafio não é só projetar circuitos integrados mais pequenos e rápidos, mas manter esses acréscimos de velocidade e diminuição de tamanho, reduzindo simultaneamente o consumo de potência. Com a diminuição do tamanho da tecnologia e o uso de transístores com tensões de threshold cada vez mais reduzidas, o consumo de potência dinâmica e estática atingiu níveis insuportáveis. Chegou-se a um ponto em que, tanto económica como ambientalmente fa- lando, é obrigatório projetar para reduzir a potência. Synopsys, uma das maiores empresas desta indústria, apresentou um projeto com o objetivo de implementar Power Gating numa das suas interfaces de alta velocidade, como técnica mais eficaz na redução da potência estática. Esta dissertação apresenta as adaptações necessárias para a implementação de Power Gating us- ando ferramentas Synopsys, aplicando-as a um caso de estudo complexo. -

Powerpoint Template
Accellera Overview February 27, 2017 Lu Dai | Accellera Chairman Welcome Agenda . About Accellera . Current news . Technical activities . IEEE collaboration 2 © 2017 Accellera Systems Initiative, Inc. February 2017 Accellera Systems Initiative Our Mission To provide a platform in which the electronics industry can collaborate to innovate and deliver global standards that improve design and verification productivity for electronics products. 3 © 2017 Accellera Systems Initiative, Inc. February 2017 Broad Industry Support Corporate Members 4 © 2017 Accellera Systems Initiative, Inc. February 2017 Broad Industry Support Associate Members 5 © 2017 Accellera Systems Initiative, Inc. February 2017 Global Presence SystemC Evolution Day DVCon Europe DVCon U.S. SystemC Japan Design Automation Conference DVCon China Verification & ESL Forum DVCon India 6 © 2017 Accellera Systems Initiative, Inc. February 2017 Agenda . About Accellera . Current news . Technical activities . IEEE collaboration 7 © 2017 Accellera Systems Initiative, Inc. February 2017 Accellera News . Standards - IEEE Approves UVM 1.2 as IEEE 1800.2-2017 - Accellera relicenses SystemC reference implementation under Apache 2.0 . Outreach - First DVCon China to be held April 19, 2017 - Get IEEE free standards program extended 10 years/10 standards . Awards - Thomas Alsop receives 2017 Technical Excellence Award for his leadership of the UVM Working Group - Shrenik Mehta receives 2016 Accellera Leadership Award for his role as Accellera chair from 2005-2010 8 © 2017 Accellera Systems Initiative, Inc. February 2017 DVCon – Global Presence 29th Annual DVCon U.S. 4th Annual DVCon Europe www.dvcon-us.org 4th Annual DVCon India www.dvcon-europe.org 1st DVCon China www.dvcon-india.org www.dvcon-china.org 9 © 2017 Accellera Systems Initiative, Inc. -

Powerplay Power Analysis 8 2013.11.04
PowerPlay Power Analysis 8 2013.11.04 QII53013 Subscribe Send Feedback The PowerPlay Power Analysis tools allow you to estimate device power consumption accurately. As designs grow larger and process technology continues to shrink, power becomes an increasingly important design consideration. When designing a PCB, you must estimate the power consumption of a device accurately to develop an appropriate power budget, and to design the power supplies, voltage regulators, heat sink, and cooling system. The following figure shows the PowerPlay Power Analysis tools ability to estimate power consumption from early design concept through design implementation. Figure 8-1: PowerPlay Power Analysis From Design Concept Through Design Implementation PowerPlay Early Power Estimator Quartus II PowerPlay Power Analyzer Higher Placement and Simulation Routing Results Results Accuracy Quartus II Design Profile User Input Estimation Design Concept Design Implementation Lower PowerPlay Power Analysis Input For the majority of the designs, the PowerPlay Power Analyzer and the PowerPlay EPE spreadsheet have the following accuracy after the power models are final: • PowerPlay Power Analyzer—±20% from silicon, assuming that the PowerPlay Power Analyzer uses the Value Change Dump File (.vcd) generated toggle rates. • PowerPlay EPE spreadsheet— ±20% from the PowerPlay Power Analyzer results using .vcd generated toggle rates. 90% of EPE designs (using .vcd generated toggle rates exported from PPPA) are within ±30% silicon. The toggle rates are derived using the PowerPlay Power Analyzer with a .vcd file generated from a gate level simulation representative of the system operation. © 2013 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. -

IEEE-SA and How Standardization Can Enhance Your Business and Career Case Study in Electronic Design Automation
IEEE-SA and How Standardization Can Enhance Your Business and Career Case Study in Electronic Design Automation Yatin Trivedi Member, Board of Governors, IEEE-SA Member, Standards Board, IEEE-SA Member, Education Activities Board, IEEE Director of Standards and Interoperability, Synopsys Vienna, March 2015 Contents Standards and EDA Impact of EDA standards Case Study: Successful Standards Standards as Innovation Platform Standards, Business and Career © 2015 IEEE Standards Association Vienna, March 2015 2 1 IEEE Technical Societies/Councils Top-class technical expert base . Aerospace & Electronic Systems . Instrumentation & Measurement . Antennas & Propagation . Lasers & Electro-Optics . Broadcast Technology . Magnetics . Circuits & Systems . Microwave Theory & Techniques . Communications . Nanotechnology Council . Components, Packaging, & Manufacturing . Nuclear & Plasma Sciences Technology . Oceanic Engineering Computer . Power Electronics Computational Intelligence . Power & Energy Consumer Electronics . Product Safety Engineering Control Systems . Professional Communication Council on Electronic Design Automation . Reliability Council on Superconductivity . Robotics & Automation Dielectrics & Electrical Insulation . Sensors Council Education . Signal Processing Electromagnetic Compatibility . Social Implications of Technology Electron Devices . Solid-State Circuits . Engineering in Medicine & Biology . Systems Council . Geosciences & Remote Sensing . Systems, Man, & Cybernetics . Industrial Electronics . Technology Management Council -

Volume 10, Issue 1 — March 2014
A PUBLICATION OF MENTOR GRAPHICS — VOLUME 10, ISSUE 1 — MARCH 2014 WHAT’S ON Whether It’s Fixing a Boiler, or Getting THE HORIZON? to Tapeout, It’s Productivity that Matters. By Tom Fitzpatrick, Editor and Verification Technologist The Little Things that Can Make Verification Easier Make verification more As I write this, we’re experiencing yet another winter storm here in New England. It started this productive by keeping your focus on verifying your design’s functionality...page 4 morning, and the timing was fortuitous since my wife had scheduled a maintenance visit by the oil company to fix a minor problem with the pipes before it really started snowing heavily. While the kids were sleeping in due to school being cancelled, the plumber worked in our basement to make The advantages of using the Unified Power Format (UPF) sure everything was working well. It turned out that he had to replace the water feeder valve on the standard with Questa See how Questa was able to model the behaviors boiler, which was preventing enough water from circulating in the heating pipes. Aside from being from their UPF specification...page 8 inefficient, this also caused the pipes to make a gurgling sound, which was the key symptom that led to the service call in the first place. As I see the snow piling Pre-silicon validation of IEEE 1149.1-2013 based Silicon up outside my window (6-8 inches and counting), it’s easy to Instruments Verify the functionality picture the disaster that this could have become had we not of the actual chip through what Intellitech calls “silicon instruments.”...page 13 identified the problem early and gotten it fixed. -

Validation of Low Power Format Using Standard Cell Library Santosh K
Validation of Low Power Format using Standard Cell Library Santosh K. Anchatgeri1, Padmanaban K.2, Sachin Bapat3 1- M.Sc. [Engg.] Student, 2-Assistant Professor, Department of Electronics and Electrical Engineering, M. S. Ramaiah School of Advanced Studies, Bangalore- 560 058 3- Staff Manager, VLSI System Design Centre, QUALCOMM, Bangalore. Abstract Increased system complexity has led to the substitution of the traditional bottom-up design flow by systematic hierarchical design flow. With decreasing channel lengths, few key problems such as timing closure, design sign-off, routing complexity, and power dissipation arise in the design flows. Specifically, minimizing power dissipation is critical in several high-end processors. This research aims at optimizing the design flow for power using the unified power format (UPF). The low power reduction techniques enforced in this research are multivoltage, multi-threshold voltage (Vth), and power gating with state retention. A top-down digital design flow for a flash based mixed signal microcontroller has been implemented with and without UPF synthesis flow for 45nm technology. The UPF synthesis is implemented with two voltages, 1.2V and 0.9V (Multi- VDD). Area, power and timing metrics are analyzed for the flows developed. Power savings of about 20 % are achieved in the design flow with 'multi-threshold' power technique compared to that of the design flow with no low power techniques employed. Similarly, 31 % power savings are achieved in the design flow with the UPF implemented when compared to that of the design flow with 'multi-threshold' power technique employed. Thus, a cumulative power savings of 51% has been achieved in a complete power efficient design flow (UPF) compared to that of the generic top-down standard flow with no power saving techniques employed. -

An Effective and Efficient Methodology for Soc Power Management Through UPF
An effective and efficient methodology for SoC power management through UPF By Renduchinthala Anusha Under the Supervision of Dr. Sujay Deb Mr. Akhilesh Chandra Mishra Mr. Rangarajan Ramanujam Indraprastha Institute of Information Technology Delhi June, 2016 ©Indraprastha Institute of Information Technology (IIITD), New Delhi 2016 An effective and efficient methodology for SoC power management through UPF By Renduchinthala Anusha Submitted in partial fulfilment of the requirements for the degree of Master of Technology in Electronics & Communication Engineering with specialization in VLSI & Embedded Systems To Indraprastha Institute of Information Technology Delhi June, 2016 Abstract With technology scaling and increase of chip complexity, power consumption of chip has been rising and its power architecture is getting complicated. Many power management techniques like power gating, multi-voltage, multi-threshold are applied to reduce power dissipation of devices. UPF is an IEEE 1801 standard format to describe the power architecture, also called as power intent, including power network connectivity and power reduction methods. It enables verification of power intent at early phases of the design cycle. The UPF developed should be consistent with the design at all stages of the design cycle and it should be updated according to the modifications made in the design. In conventional UPF flow through design cycle, few practical challenges are faced. Many bugs are not detected at earlier phases which might lead to the wrong implementation of power intent. In addition, parallel development of power intent for complex designs, limitations of UPF standard to describe few power intent components effectively and time- consuming conventional UPF flow hinder efficient UPF development and management. -

Phd and Mphil Thesis Classes
A novel approach to Reusable Time-economized STIL based pattern development by Rahul Malhotra Under the Supervision of Dr. Sujay Deb Fabio Carlucci Indraprastha Institute of Information Technology Delhi June, 2015 ©Indraprastha Institute of Information Technology (IIITD), New Delhi 2015 A novel approach to Reusable Time-economized STIL based pattern development by Rahul Malhotra Submitted in partial fulfillment of the requirements for the degree of Master of Technology in Electronics & Communication Engineering with specialization in VLSI & Embedded Systems to Indraprastha Institute of Information Technology Delhi June, 2015 Certificate This is to certify that the thesis titled A novel approach to Reusable Time- economized STIL based pattern development being submitted by Rahul Malho- tra to the Indraprastha Institute of Information Technology Delhi, for the award of the Master of Technology, is an original research work carried out by him under my super- vision. In my opinion, the thesis has reached the standards fulfilling the requirements of the regulations relating to the degree. The results contained in this thesis have not been submitted in part or full to any other university or institute for the award of any degree/diploma. June, 2015 Dr. Sujay Deb Department of Indraprastha Institute of Information Technology Delhi New Delhi 110 020 Abstract State of the art automotive micro-controllers (MCUs) implementing com- plex system-on-chip (SoC) architectures requires often additional functional patterns to achieve high degree of reliability. Functional pattern family in- cludes test patterns checking internal device functionality under nominal condition. The development of these patterns is required to augment struc- tural tests to achieve high test coverage. -

AN 307: Intel® FPGA Design Flow for Xilinx* Users
AN 307: Intel® FPGA Design Flow for Xilinx* Users Updated for Intel® Quartus® Prime Design Suite: 17.1 Subscribe AN-307 | 2020.08.24 Send Feedback Latest document on the web: PDF | HTML Contents Contents 1. Introduction to Intel® FPGA Design Flow for Xilinx* Users............................................. 4 2. Technology Comparison.................................................................................................. 5 2.1. Intel FPGAs ..........................................................................................................5 2.2. Xilinx FPGAs......................................................................................................... 6 2.3. Comparison Table.................................................................................................. 6 2.4. Intel FPGA Device Features..................................................................................... 7 3. FPGA Tools Comparison.................................................................................................. 9 3.1. Hardware and Software Tools for FPGA Design...........................................................9 3.2. FPGA Design Flow Using Command Line Scripting.....................................................10 3.2.1. Command-Line Executable Equivalents....................................................... 12 3.2.2. Programming and Configuration File Support in the Intel Quartus Prime Pro Edition Software.................................................................................17 3.3. FPGA Design -
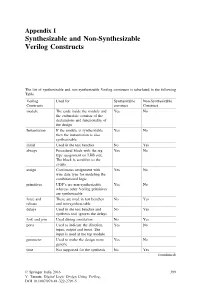
Non-Synthesizable Verilog Constructs
Appendix I Synthesizable and Non-Synthesizable Verilog Constructs The list of synthesizable and non-synthesizable Verilog constructs is tabu-lated in the following Table Verilog Used for Synthesizable Non-Synthesizable Constructs construct Construct module The code inside the module and Yes No the endmodule consists of the declarations and functionality of the design Instantiation If the module is synthesizable Yes No then the instantiation is also synthesizable initial Used in the test benches No Yes always Procedural block with the reg Yes No type assignment on LHS side. The block is sensitive to the events assign Continuous assignment with Yes No wire data type for modeling the combinational logic primitives UDP’s are non-synthesizable Yes No whereas other Verilog primitives are synthesizable force and These are used in test benches No Yes release and non-synthesizable delays Used in the test benches and No Yes synthesis tool ignores the delays fork and join Used during simulation No Yes ports Used to indicate the direction, Yes No input, output and inout. The input is used at the top module parameter Used to make the design more Yes No generic time Not supported for the synthesis No Yes (continued) © Springer India 2016 399 V. Taraate, Digital Logic Design Using Verilog, DOI 10.1007/978-81-322-2791-5 400 Appendix I: Synthesizable and Non-Synthesizable Verilog Constructs (continued) real Not supported for synthesis No Yes functions and Both are synthesizable. Provided Yes No task that the task does not have the timing constructs loop The for loop is synthesizable and Yes No used for the multiple iterations. -

Design and Implementation of an On-Chip Logic Analyzer
Design and implementation of an On-chip Logic Analyzer KRISTOFFER CARLSSON Master’s thesis Electrical Engineering Program CHALMERS UNIVERSITY OF TECHNOLOGY Department of Computer Science and Engineering Division of Computer Engineering Göteborg 2005 Design and implementation of an On-chip Logic Analyzer All rights reserved. This publication is protected by law in accordance with “Lagen om Upphovsrätt”, 1960:729. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, pho- tocopying, recording, or otherwise, without the prior permission of the authors. Copyright, Kristoffer Carlsson, Göteborg 2005. 2 Design and implementation of an On-chip Logic Analyzer Abstract The design and implementation of an On-chip Logic Analyzer for Field Programmable Gate Arrays (FPGA) is described in this report. FPGA devices have grown larger and larger and can contain very complex System on Chip (SoC) designs in a package with lim- ited I/O resources. The On-chip Logic Analyzer IP core has been developed in VHDL dur- ing this Master’s thesis to be able to debug such designs running in target hardware. It enables the designer to trace arbitrary signals inside the FPGA fabric and to trig on com- plex events. Samples are stored in a circular trace buffer implemented with synchronous on-chip RAM. Trigger engine control and trace buffer readout is done over an AMBA APB interface. The Logic Analyzer IP core will become a part of Gaisler Research’s GRLIB IP library and integrated into their GRMON debug monitor software. The work can be divided into three main parts: hardware design of the IP core, developing a debug driver for GRMON and programming a GUI front end for easier configuration.