Analysis of Intronic and Exonic Reads in RNA-Seq Data Characterizes Transcriptional and Post-Transcriptional Regulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
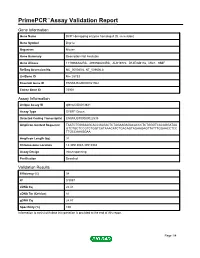
Primepcr™Assay Validation Report
PrimePCR™Assay Validation Report Gene Information Gene Name DCP1 decapping enzyme homolog A (S. cerevisiae) Gene Symbol Dcp1a Organism Mouse Gene Summary Description Not Available Gene Aliases 1110066A22Rik, 4930568L04Rik, AU019772, D14Ertd817e, Mitc1, SMIF RefSeq Accession No. NC_000080.6, NT_039606.8 UniGene ID Mm.28733 Ensembl Gene ID ENSMUSG00000021962 Entrez Gene ID 75901 Assay Information Unique Assay ID qMmuCID0013841 Assay Type SYBR® Green Detected Coding Transcript(s) ENSMUST00000022535 Amplicon Context Sequence TAATCTGGGAAGCACCGAGACTCTAGAAGAGACACCCTCTGGGTCACAGGATAA GTCTGCTCCGTCTGGTCATAAACATCTGACAGTAGAAGAGTTATTTGGAACCTCC TTGCCAAAGGAA Amplicon Length (bp) 91 Chromosome Location 14:30513043-30518984 Assay Design Intron-spanning Purification Desalted Validation Results Efficiency (%) 98 R2 0.9997 cDNA Cq 22.41 cDNA Tm (Celsius) 81 gDNA Cq 24.87 Specificity (%) 100 Information to assist with data interpretation is provided at the end of this report. Page 1/4 PrimePCR™Assay Validation Report Dcp1a, Mouse Amplification Plot Amplification of cDNA generated from 25 ng of universal reference RNA Melt Peak Melt curve analysis of above amplification Standard Curve Standard curve generated using 20 million copies of template diluted 10-fold to 20 copies Page 2/4 PrimePCR™Assay Validation Report Products used to generate validation data Real-Time PCR Instrument CFX384 Real-Time PCR Detection System Reverse Transcription Reagent iScript™ Advanced cDNA Synthesis Kit for RT-qPCR Real-Time PCR Supermix SsoAdvanced™ SYBR® Green Supermix Experimental Sample qPCR Mouse Reference Total RNA Data Interpretation Unique Assay ID This is a unique identifier that can be used to identify the assay in the literature and online. Detected Coding Transcript(s) This is a list of the Ensembl transcript ID(s) that this assay will detect. -

Exon Amplification: a Strategy to Isolate Mammalian Genes Based on RNA Splicing (Gene Cloning/Polymerase Chain Reaction) ALAN J
Proc. Natl. Acad. Sci. USA Vol. 88, pp. 4005-4009, May 1991 Genetics Exon amplification: A strategy to isolate mammalian genes based on RNA splicing (gene cloning/polymerase chain reaction) ALAN J. BUCKLER*, DAVID D. CHANG, SHARON L. GRAw, J. DAVID BROOK, DANIEL A. HABER, PHILLIP A. SHARP, AND DAVID E. HOUSMAN Center for Cancer Research, Department of Biology, Massachusetts Institute of Technology, Cambridge, MA 02139 Contributed by Phillip A. Sharp, January 25, 1991 ABSTRACT We have developed a method, exon amplifi- (7, 8). Thus, this method may be generally applicable for the cation, for fast and efficient isolation of coding sequences from selection of exon sequences from any gene. The method is complex mammalian genomic DNA. This method is based on also both rapid and easily adapted to large scale experiments. the selection of RNA sequences, exons, which are flanked by A series of cloned genomic DNA fragments can be screened functional 5' and 3' splice sites. Fragments of cloned genomic within 1-2 weeks. The sensitivity of this method is high. DNA are inserted into an intron, which is flanked by 5' and 3' Genomic DNA segments of 20 kilobases (kb) or more can be splice sites of the human immunodeficiency virus 1 tat gene successfully screened in a single transfection by using a set contained within the plasmid pSPL1. COS-7 cells are trans- of pooled subclones. This method thus allows the rapid fected with these constructs, and the resulting RNA transcripts identification of exons in mammalian genomic DNA and are processed in vivo. Splice sites of exons contained within the should facilitate the isolation of a wide spectrum of genes of inserted genomic fragment are paired with splice sites of the significance in physiology and development. -

Mrna Turnover Philip Mitchell* and David Tollervey†
320 mRNA turnover Philip Mitchell* and David Tollervey† Nuclear RNA-binding proteins can record pre-mRNA are cotransported to the cytoplasm with the mRNP. These processing events in the structure of messenger proteins may preserve a record of the nuclear history of the ribonucleoprotein particles (mRNPs). During initial rounds of pre-mRNA in the cytoplasmic mRNP structure. This infor- translation, the mature mRNP structure is established and is mation can strongly influence the cytoplasmic fate of the monitored by mRNA surveillance systems. Competition for the mRNA and is used by mRNA surveillance systems that act cap structure links translation and subsequent mRNA as a checkpoint of mRNP integrity, particularly in the identi- degradation, which may also involve multiple deadenylases. fication of premature translation termination codons (PTCs). Addresses Cotransport of nuclear mRNA-binding proteins with mRNA Wellcome Trust Centre for Cell Biology, ICMB, University of Edinburgh, from the nucleus to the cytoplasm (nucleocytoplasmic shut- Kings’ Buildings, Edinburgh EH9 3JR, UK tling) was first observed for the heterogeneous nuclear *e-mail: [email protected] ribonucleoprotein (hnRNP) proteins. Some hnRNP proteins †e-mail: [email protected] are stripped from the mRNA at export [1], but hnRNP A1, Current Opinion in Cell Biology 2001, 13:320–325 A2, E, I and K are all exported (see [2]). Although roles for 0955-0674/01/$ — see front matter these hnRNP proteins in transport and translation have been © 2001 Elsevier Science Ltd. All rights reserved. reported [3•,4•], their affects on mRNA stability have been little studied. More is known about hnRNP D/AUF1 and Abbreviations AREs AU-rich sequence elements another nuclear RNA-binding protein, HuR, which act CBC cap-binding complex antagonistically to modulate the stability of a range of DAN deadenylating nuclease mRNAs containing AU-rich sequence elements (AREs) DSEs downstream sequence elements (reviewed in [2]). -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig. -

Sequences at the Exon-Intron Boundaries* (Split Gene/Mrna Splicing/Eukaryotic Gene Structure) R
Proc. Nati. Acad. Sci. USA Vol. 75, No. 10, pp. 4853-4857, October 1978 Biochemistry Ovalbumin gene: Evidence for a leader sequence in mRNA and DNA sequences at the exon-intron boundaries* (split gene/mRNA splicing/eukaryotic gene structure) R. BREATHNACH, C. BENOIST, K. O'HARE, F. GANNON, AND P. CHAMBON Laboratoire de Genetique Mol6culaire des Eucaryotes du Centre National de la Recherche Scientifique, Unite 44 de l'Institut National de la Sant6 et de la Recherche MWdicale, Institut de Chimie Biologique, Facult6 de Melecine, Strasbourg 67085, France Communicated by A. Frey-Wyssling, July 31, 1978 ABSTRACT Selected regions of cloned EcoRI fragments the 5' end of ov-mRNA and have revealed some interesting of the chicken ovalbumin gene have been sequenced. The po- features in the DNA sequences at exon-intron boundaries. sitions where the sequences coding for ovalbumin mRNA (ov- mRNA) are interrupted in the genome have been determined, and a previously unreported interruption in the DNA sequences MATERIALS AND METHODS coding for the 5' nontranslated region of the messenger has been discovered. Because directly repeated sequences are found at Plasmid pCR1 ov 2.1 containing the ov-ds-cDNA insert was exon-intron boundaries, the nucleotide sequence alone cannot prepared as described (9). EcoRI fragments "b," "c," and "d" define unique excision-ligation points for the processing of a previously cloned in X vectors (3) were transferred to the plas- possible ov-mRNA precursor. However, the sequences in these mid pBR 322. An EcoRI/HindIII of the EcoRI boundary regions share common features; this leads to the fragment proposal that there are, in fact, unique excision-ligation points fragment "a" containing the entirety of exon 7 (Fig. -

Nuclear PTEN Safeguards Pre-Mrna Splicing to Link Golgi Apparatus for Its Tumor Suppressive Role
ARTICLE DOI: 10.1038/s41467-018-04760-1 OPEN Nuclear PTEN safeguards pre-mRNA splicing to link Golgi apparatus for its tumor suppressive role Shao-Ming Shen1, Yan Ji2, Cheng Zhang1, Shuang-Shu Dong2, Shuo Yang1, Zhong Xiong1, Meng-Kai Ge1, Yun Yu1, Li Xia1, Meng Guo1, Jin-Ke Cheng3, Jun-Ling Liu1,3, Jian-Xiu Yu1,3 & Guo-Qiang Chen1 Dysregulation of pre-mRNA alternative splicing (AS) is closely associated with cancers. However, the relationships between the AS and classic oncogenes/tumor suppressors are 1234567890():,; largely unknown. Here we show that the deletion of tumor suppressor PTEN alters pre-mRNA splicing in a phosphatase-independent manner, and identify 262 PTEN-regulated AS events in 293T cells by RNA sequencing, which are associated with significant worse outcome of cancer patients. Based on these findings, we report that nuclear PTEN interacts with the splicing machinery, spliceosome, to regulate its assembly and pre-mRNA splicing. We also identify a new exon 2b in GOLGA2 transcript and the exon exclusion contributes to PTEN knockdown-induced tumorigenesis by promoting dramatic Golgi extension and secretion, and PTEN depletion significantly sensitizes cancer cells to secretion inhibitors brefeldin A and golgicide A. Our results suggest that Golgi secretion inhibitors alone or in combination with PI3K/Akt kinase inhibitors may be therapeutically useful for PTEN-deficient cancers. 1 Department of Pathophysiology, Key Laboratory of Cell Differentiation and Apoptosis of Chinese Ministry of Education, Shanghai Jiao Tong University School of Medicine (SJTU-SM), Shanghai 200025, China. 2 Institute of Health Sciences, Shanghai Institutes for Biological Sciences of Chinese Academy of Sciences and SJTU-SM, Shanghai 200025, China. -

Deep Sequencing of Subcellular RNA Fractions Shows Splicing to Be Predominantly Co-Transcriptional in the Human Genome but Inefficient for Lncrnas
Research Deep sequencing of subcellular RNA fractions shows splicing to be predominantly co-transcriptional in the human genome but inefficient for lncRNAs Hagen Tilgner,1,3 David G. Knowles,1 Rory Johnson,1 Carrie A. Davis,2 Sudipto Chakrabortty,2 Sarah Djebali,1 Joao~ Curado,1 Michael Snyder,3 Thomas R. Gingeras,2 and Roderic Guigo´ 1,4 1Centre for Genomic Regulation (CRG) and UPF, E-08003, Barcelona, Catalonia, Spain; 2Cold Spring Harbor Laboratory, Cold Spring Harbor, New York 11724, USA; 3Department of Genetics, Stanford University School of Medicine, Stanford, California 94305, USA Splicing remains an incompletely understood process. Recent findings suggest that chromatin structure participates in its regulation. Here, we analyze the RNA from subcellular fractions obtained through RNA-seq in the cell line K562. We show that in the human genome, splicing occurs predominantly during transcription. We introduce the coSI measure, based on RNA-seq reads mapping to exon junctions and borders, to assess the degree of splicing completion around internal exons. We show that, as expected, splicing is almost fully completed in cytosolic polyA+ RNA. In chromatin- associated RNA (which includes the RNA that is being transcribed), for 5.6% of exons, the removal of the surrounding introns is fully completed, compared with 0.3% of exons for which no intron-removal has occurred. The remaining exons exist as a mixture of spliced and fewer unspliced molecules, with a median coSI of 0.75. Thus, most RNAs undergo splicing while being transcribed: ‘‘co-transcriptional splicing.’’ Consistent with co-transcriptional spliceosome assembly and splicing, we have found significant enrichment of spliceosomal snRNAs in chromatin-associated RNA compared with other cellular RNA fractions and other nonspliceosomal snRNAs. -

Unraveling Regulation and New Components of Human P-Bodies Through a Protein Interaction Framework and Experimental Validation
Downloaded from rnajournal.cshlp.org on September 25, 2021 - Published by Cold Spring Harbor Laboratory Press PERSPECTIVE Unraveling regulation and new components of human P-bodies through a protein interaction framework and experimental validation DINGHAI ZHENG,1,2 CHYI-YING A. CHEN,1 and ANN-BIN SHYU3 Department of Biochemistry and Molecular Biology, The University of Texas Medical School, Houston, Texas 77021, USA ABSTRACT The cellular factors involved in mRNA degradation and translation repression can aggregate into cytoplasmic domains known as GW bodies or mRNA processing bodies (P-bodies). However, current understanding of P-bodies, especially the regulatory aspect, remains relatively fragmentary. To provide a framework for studying the mechanisms and regulation of P-body formation, maintenance, and disassembly, we compiled a list of P-body proteins found in various species and further grouped both reported and predicted human P-body proteins according to their functions. By analyzing protein–protein interactions of human P-body components, we found that many P-body proteins form complex interaction networks with each other and with other cellular proteins that are not recognized as P-body components. The observation suggests that these other cellular proteins may play important roles in regulating P-body dynamics and functions. We further used siRNA-mediated gene knockdown and immunofluorescence microscopy to demonstrate the validity of our in silico analyses. Our combined approach identifies new P-body components and suggests that protein ubiquitination and protein phosphorylation involving 14-3-3 proteins may play critical roles for post-translational modifications of P-body components in regulating P-body dynamics. Our analyses provide not only a global view of human P-body components and their physical interactions but also a wealth of hypotheses to help guide future research on the regulation and function of human P-bodies. -

Mouse Prpf19 Conditional Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Prpf19 Conditional Knockout Project (CRISPR/Cas9) Objective: To create a Prpf19 conditional knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Prpf19 gene (NCBI Reference Sequence: NM_001253843 ; Ensembl: ENSMUSG00000024735 ) is located on Mouse chromosome 19. 16 exons are identified, with the ATG start codon in exon 1 and the TAG stop codon in exon 16 (Transcript: ENSMUST00000179297). Exon 2~3 will be selected as conditional knockout region (cKO region). Deletion of this region should result in the loss of function of the Mouse Prpf19 gene. To engineer the targeting vector, homologous arms and cKO region will be generated by PCR using BAC clone RP23-404I24 as template. Cas9, gRNA and targeting vector will be co-injected into fertilized eggs for cKO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Mice homozygous for a null allele die prior to implantation and have defective cell proliferation. Exon 2 starts from about 1.27% of the coding region. The knockout of Exon 2~3 will result in frameshift of the gene. The size of intron 1 for 5'-loxP site insertion: 2034 bp, and the size of intron 3 for 3'-loxP site insertion: 1032 bp. The size of effective cKO region: ~891 bp. The cKO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele gRNA region 5' gRNA region 3' 1 2 3 4 5 6 16 Targeting vector Targeted allele Constitutive KO allele (After Cre recombination) Legends Homology arm Exon of mouse Prpf19 cKO region loxP site Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot Window size: 10 bp Forward Reverse Complement Sequence 12 Note: The sequence of homologous arms and cKO region is aligned with itself to determine if there are tandem repeats. -

Chem 465 Biochemistry II Test 3
Name: 1 point Chem 465 Biochemistry II Test 3 Multiple choice 4 points each 1. RNA polymerase: A) binds tightly to a region of DNA thousands of base pairs away from the DNA to be transcribed. B) can synthesize RNA chains de novo (without a primer). C) has a subunit called ë (lambda), which acts as a proofreading ribonuclease. D) separates DNA strands throughout a long region of DNA (up to thousands of base pairs), then copies one of them. E) synthesizes RNA chains in the 3'65' direction. 2. Splicing of introns in nuclear mRNA primary transcripts requires: A) a guanine nucleoside or nucleotide. B) endoribonucleases. C) polynucleotide phosphorylase. D) RNA polymerase II. E) small nuclear ribonucleoproteins (snurps). 3. Which one of the following statements about mRNA stability is true? A) Degradation always proceeds in the 5' to 3' direction. B) Degradation of mRNA by polynucleotide phosphorylase yields 5'-nucleoside monophosphates. C) In general, bacterial mRNAs have longer half-lives than do eukaryotic mRNAs. D) Rates of mRNA degradation ared always at least 10-fold slower than rates of mRNA synthesis. E) Secondary structure in mRNA (hairpins, for example) slows the rate of degradation. 4. Which of the following statements about the tRNA that normally accepts phenylalanine is false? (mRNA codons for phenylalanine are UUU and UUC.) A) It interacts specificially with the Phe synthetase. B) It will accept only the amino acid phenylalanine. C) Its molecular weight is about 25,000. D) Phenylalanine can be specifically attached to an -OH group at the 3' end. E) The tRNA must contain the sequence UUU. -

Messenger-Rna-Binding Proteins and the Messages They Carry
REVIEWS MESSENGER-RNA-BINDING PROTEINS AND THE MESSAGES THEY CARRY Gideon Dreyfuss*, V.Narry Kim‡ and Naoyuki Kataoka* From sites of transcription in the nucleus to the outreaches of the cytoplasm, messenger RNAs are associated with RNA-binding proteins. These proteins influence pre-mRNA processing as well as the transport, localization, translation and stability of mRNAs. Recent discoveries have shown that one group of these proteins marks exon–exon junctions and has a role in mRNA export. These proteins communicate crucial information to the translation machinery for the surveillance of nonsense mutations and for mRNA localization and translation. PRE-mRNA To function properly, eukaryotic messenger RNAs must Recent discoveries showed that this mature mRNP The primary transcript of the contain, in addition to a string of codons, information contains proteins that it acquired strictly in the wake of genomic DNA, which contains that specifies their nuclear export, subcellular localiza- the splicing reaction. These proteins, which are exons, introns and other tion, translation and stability. An important theme to arranged in the form of a complex called the exon–exon sequences. emerge over the past few years is that much of this infor- junction complex (EJC), mark the position of SPLICING mation is provided by specific RNA-binding proteins. exon–exon junctions. EJC proteins have a role in the The removal of introns from the These proteins — collectively referred to as heteroge- nuclear export of mRNAs that are produced by splicing, pre-mRNA. neous nuclear ribonucleoproteins (hnRNP proteins) and several of the mRNP’s components persist in the or mRNA–protein complex proteins (mRNP pro- same position after export of the mRNP to the cyto- TERMINATION CODONS The stop signals for translation: teins) — are PRE-mRNA/mRNA-binding proteins that plasm. -

Alternatively Spliced Genes
1 Alternatively Spliced Genes Jane Y. Wu1,2,LiyaYuan1 and Necat Havlioglu1 1Washington University School of Medicine, St. Louis, MO, USA 2John F. Kennedy Center for Research on Human Development, Vanderbilt University Medical Center, Nashville, TN, USA 1 Pre-mRNA Splicing and Splicing Machinery 3 1.1 Splicing Machinery: Spliceosome 3 1.2 Splicing Signals 4 1.3 Spliceosomal UsnRNP Biogenesis 12 1.4 Spliceosome Assembly 13 1.5 Biochemical Mechanisms of pre-mRNA Splicing 17 2 Alternative pre-mRNA Splicing 17 2.1 Alternative Splicing and its Role in Regulating Gene Activities and Generating Genetic Diversity 17 2.1.1 Different Patterns of Alternative Splicing 17 2.1.2 Alternative Splicing and Genetic Diversity 18 2.2 Mechanisms Underlying Alternative Splicing Regulation 19 2.2.1 Splicing Signals and Splicing Regulatory Elements 20 2.2.2 Trans-acting Splicing Regulators 23 2.3 Tissue-specific and Developmentally Regulated Alternative Splicing 26 2.4 Regulation of Alternative Splicing in Response to Extracellular Stimuli 27 3 Pre-mRNA Splicing and Human Diseases 28 3.1 Splicing Defects in Human Diseases 28 3.2 Molecular Mechanisms Underlying Splicing Defects Associated with Disease 33 4 Perspectives on Diagnosis and Treatment of Diseases Caused by pre-mRNA Splicing Defects 36 4.1 Diagnosis of Human Diseases Caused by Splicing Defects 36 2 Alternatively Spliced Genes 4.2 Potential Therapeutic Approaches 37 4.2.1 Oligonucleotide-based Approaches: Antisense, RNAi, and Chimeric Molecules 37 4.2.2 Ribozymes 37 4.2.3 SMaRT 38 4.2.4 Chemical Compounds 38 5 Concluding Remarks 38 Acknowledgment 39 Bibliography 39 Books and Reviews 39 Keywords Pre-mRNA Nascent transcripts that are precursors of mature messenger RNAs.