Phd Musoll.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Digital Semiconductor Alpha 21064 and Alpha 21064A Microprocessors Hardware Reference Manual
Digital Semiconductor Alpha 21064 and Alpha 21064A Microprocessors Hardware Reference Manual Order Number: EC–Q9ZUC–TE Abstract: This document contains information about the following Alpha microprocessors: 21064-150, 21064-166, 21064-200, 21064A-200, 21064A-233, 21064A-275, 21064A-275-PC, and 21064A-300. Revision/Update Information: This manual supersedes the Alpha 21064 and Alpha 21064A Microprocessors Hard- ware Reference Manual (EC–Q9ZUB–TE). Digital Equipment Corporation Maynard, Massachusetts June 1996 While Digital believes the information included in this publication is correct as of the date of publication, it is subject to change without notice. Digital Equipment Corporation makes no representations that the use of its products in the manner described in this publication will not infringe on existing or future patent rights, nor do the descriptions contained in this publication imply the granting of licenses to make, use, or sell equipment or software in accordance with the description. © Digital Equipment Corporation 1996. All rights reserved. Printed in U.S.A. AlphaGeneration, Digital, Digital Semiconductor, OpenVMS, VAX, VAX DOCUMENT, the AlphaGeneration design mark, and the DIGITAL logo are trademarks of Digital Equipment Corporation. Digital Semiconductor is a Digital Equipment Corporation business. GRAFOIL is a registered trademark of Union Carbide Corporation. Windows NT is a trademark of Microsoft Corporation. All other trademarks and registered trademarks are the property of their respective owners. This document was prepared using VAX DOCUMENT Version 2.1. Contents Preface ..................................................... xix 1 Introduction to the 21064/21064A 1.1 Introduction ......................................... 1–1 1.2 The Architecture . ................................... 1–1 1.3 Chip Features ....................................... 1–2 1.4 Backward Compatibility ............................... -

Alpha 21064A Microprocessors Data Sheet
Alpha 21064A Microprocessors Data Sheet Order Number: EC–QFGKC–TE This document contains information about the following Alpha micro- processors: 21064A–200, 21064A–233, 21064A–275, 21064A–275–PC, and 21064A–300. Revision/Update Information: This document supersedes the Alpha 21064A–233, –275 Microprocessor Data Sheet, EC–QFGKB–TE. Digital Equipment Corporation Maynard, Massachusetts January 1996 While Digital believes the information included in this publication is correct as of the date of publication, it is subject to change without notice. Digital Equipment Corporation makes no representations that the use of its products in the manner described in this publication will not infringe on existing or future patent rights, nor do the descriptions contained in this publication imply the granting of licenses to make, use, or sell equipment or software in accordance with the description. © Digital Equipment Corporation 1995, 1996. All rights reserved. Printed in U.S.A. AlphaGeneration, Digital, Digital Semiconductor, OpenVMS, VAX, VAX DOCUMENT, the AlphaGeneration design mark, and the DIGITAL logo are trademarks of Digital Equipment Corporation. Digital Semiconductor is a Digital Equipment Corporation business. GRAFOIL is a registered trademark of Union Carbide Corporation. Windows NT is a trademark of Microsoft Corporation. All other trademarks and registered trademarks are the property of their respective owners. This document was prepared using VAX DOCUMENT Version 2.1. Contents 1 Overview ........................................... 1 2 Signal Names and Functions . ........................... 6 3 Instruction Set ....................................... 17 3.1 Instruction Summary ............................... 17 3.2 IEEE Floating-Point Instructions . ................... 23 3.3 21064A IEEE Floating-Point Conformance .............. 25 3.4 VAX Floating-Point Instructions . ................... 28 3.5 Required PALcode Function Codes . -

Computer Architectures an Overview
Computer Architectures An Overview PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 25 Feb 2012 22:35:32 UTC Contents Articles Microarchitecture 1 x86 7 PowerPC 23 IBM POWER 33 MIPS architecture 39 SPARC 57 ARM architecture 65 DEC Alpha 80 AlphaStation 92 AlphaServer 95 Very long instruction word 103 Instruction-level parallelism 107 Explicitly parallel instruction computing 108 References Article Sources and Contributors 111 Image Sources, Licenses and Contributors 113 Article Licenses License 114 Microarchitecture 1 Microarchitecture In computer engineering, microarchitecture (sometimes abbreviated to µarch or uarch), also called computer organization, is the way a given instruction set architecture (ISA) is implemented on a processor. A given ISA may be implemented with different microarchitectures.[1] Implementations might vary due to different goals of a given design or due to shifts in technology.[2] Computer architecture is the combination of microarchitecture and instruction set design. Relation to instruction set architecture The ISA is roughly the same as the programming model of a processor as seen by an assembly language programmer or compiler writer. The ISA includes the execution model, processor registers, address and data formats among other things. The Intel Core microarchitecture microarchitecture includes the constituent parts of the processor and how these interconnect and interoperate to implement the ISA. The microarchitecture of a machine is usually represented as (more or less detailed) diagrams that describe the interconnections of the various microarchitectural elements of the machine, which may be everything from single gates and registers, to complete arithmetic logic units (ALU)s and even larger elements. -

Virtual Memory CS740 October 13, 1998
Virtual Memory CS740 October 13, 1998 Topics • page tables • TLBs • Alpha 21X64 memory system Levels in a Typical Memory Hierarchy cache virtual memory C 4 Ba 8 B 4 KB CPU c Memory CPU Memory diskdisk regs h regs e register cache memory disk memory reference reference reference reference size: 200 B 32 KB / 4MB 128 MB 20 GB speed: 3 ns 6 ns 100 ns 10 ms $/Mbyte: $256/MB $2/MB $0.10/MB block size: 4 B 8 B 4 KB larger, slower, cheaper – 2 – CS 740 F’98 Virtual Memory Main memory acts as a cache for the secondary storage (disk) Virtual addresses Physical addresses Address translation Disk addresses Increases Program-Accessible Memory • address space of each job larger than physical memory • sum of the memory of many jobs greater than physical memory – 3 – CS 740 F’98 Address Spaces • Virtual and physical address spaces divided into equal-sized blocks – “Pages” (both virtual and physical) • Virtual address space typically larger than physical • Each process has separate virtual address space Physical addresses (PA) Virtual addresses (VA) 0 0 address translation VP 1 PP2 Process 1: VP 2 2n-1 PP7 (Read-only library code) 0 Process 2: VP 1 VP 2 PP10 2n-1 2m-1 – 4 – CS 740 F’98 Other Motivations Simplifies memory management • main reason today • Can have multiple processes resident in physical memory • Their program addresses mapped dynamically – Address 0x100 for process P1 doesn’t collide with address 0x100 for process P2 • Allocate more memory to process as its needs grow Provides Protection • One process can’t interfere with another – Since -

Address Translation & Caches Outline
Operating Systems & Memory Systems: Address Translation & Caches CPS 220 Professor Alvin R. Lebeck Fall 2001 Outline • Review • TLBs • Page Table Designs • Interaction of VM and Caches Admin • HW #4 Due today • Project Status report due Thursday © Alvin R. Lebeck 2001 CPS 220 2 Page 1 Virtual Memory: Motivation Virtual • Process = Address Space + thread(s) of Physical control • Address space = PA – programmer controls movement from disk – protection? – relocation? • Linear Address space – larger than physical address space » 32, 64 bits v.s. 28-bit physical (256MB) • Automatic management © Alvin R. Lebeck 2001 CPS 220 3 Virtual Memory • Process = virtual address space + thread(s) of control • Translation – VA -> PA – What physical address does virtual address A map to – Is VA in physical memory? • Protection (access control) – Do you have permission to access it? © Alvin R. Lebeck 2001 CPS 220 4 Page 2 Segmented Virtual Memory • Virtual address (232, 264) to Physical Address mapping (230) • Variable size, base + offset, contiguous in both VA and PA Virtual Physical 0x1000 0x0000 0x1000 0x6000 0x2000 0x9000 0x11000 © Alvin R. Lebeck 2001 CPS 220 5 Paged Virtual Memory • Virtual address (232, 264) to Physical Address mapping (228) – virtual page to physical page frame Virtual page number Offset • Fixed Size units for access control & translation Virtual Physical 0x1000 0x0000 0x1000 0x6000 0x2000 0x9000 0x11000 © Alvin R. Lebeck 2001 CPS 220 6 Page 3 Page Table • Kernel data structure (per process) • Page Table Entry (PTE) – VA -> PA translations (if none page fault) – access rights (Read, Write, Execute, User/Kernel, cached/uncached) – reference, dirty bits • Many designs – Linear, Forward mapped, Inverted, Hashed, Clustered • Design Issues – support for aliasing (multiple VA to single PA) – large virtual address space – time to obtain translation © Alvin R. -

Database Integration
I DATABASE INTEGRATION ALPHA SERVERS & WORKSTATIONS Digital ALPHA 21164 CPU Technical Journal Editorial The Digital TechnicalJournal is a refereed Cyrix is a trademark of Cyrix Corporation. Jane C. Blake, Managing Editor journal published quarterly by Digital dBASE is a trademark and Paradox is Helen L. Patterson, Editor Equipment Corporation, 30 Porter Road a registered trademark of Borland Kathleen M. Stetson, Editor LJ02/D10, Littleton, Massachusetts 01460. International, Inc. Subscriptionsto the Journal are $40.00 Circulation (non-U.S. $60) for four issues and $75.00 EDA/SQL is a trademark of Information Catherine M. Phillips, Administrator (non-U.S. $115) for eight issues and must Builders, Inc. Dorothea B. Cassady, Secretary be prepaid in U.S. funds. University and Encina is a registered trademark of Transarc college professors and Ph.D. students in Corporation. Production the electrical engineering and computer Excel and Microsoft are registered pde- Terri Autieri, Production Editor science fields receive complimentary sub- marks and Windows and Windows NT are Anne S. Katzeff, Typographer scriptions upon request. Orders, inquiries, trademarks of Microsoft Corporation. Joanne Murphy, Typographer and address changes should be sent to the Peter R Woodbury, Illustrator Digital TechnicalJournal at the published- Hewlett-Packard and HP-UX are registered by address. Inquiries can also be sent elec- trademarks of Hewlett-Packard Company. Advisory Board tronically to [email protected]. Single copies INGRES is a registered trademark of Ingres Samuel H. Fuller, Chairman and back issues are available for $16.00 each Corporation. Richard W. Beane by calling DECdirect at 1-800-DIGITAL Donald Z. Harbert (1-800-344-4825). -

Thesis May Never Have Been Completed
UvA-DARE (Digital Academic Repository) Digital Equipment Corporation (DEC): A case study of indecision, innovation and company failure Goodwin, D.T. Publication date 2016 Document Version Final published version Link to publication Citation for published version (APA): Goodwin, D. T. (2016). Digital Equipment Corporation (DEC): A case study of indecision, innovation and company failure. General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:26 Sep 2021 Digital Equipment Corporation (DEC) (DEC) Corporation Digital Equipment David Thomas David Goodwin Digital Equipment Corporation (DEC): A Case Study of Indecision, Innovation and Company Failure David Thomas Goodwin Digital Equipment Corporation (DEC): A Case Study of Indecision, Innovation and Company Failure David Thomas Goodwin 1 Digital Equipment Corporation (DEC): A Case Study of Indecision, Innovation and Company Failure ACADEMISCH PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit van Amsterdam op gezag van de Rector Magnificus prof. -

Virtual Memory
EEC 581 Computer Architecture Memory Hierarchy Design (II) Department of Electrical Engineering and Computer Science Cleveland State University Topics to be covered Cache Penalty Reduction Techniques Victim cache Assist cache Non-blocking cache Data Prefetch mechanism Virtual Memory 2 1 3Cs Absolute Miss Rate (SPEC92) •Compulsory misses are a tiny fraction of the overall misses •Capacity misses reduce with increasing sizes •Conflict misses reduce with increasing associativity 0.14 1-way Conflict 0.12 2-way 0.1 4-way 0.08 8-way 0.06 Capacity 0.04 Miss Rate per Type 0.02 0 1 2 4 8 16 32 64 128 Cache Size (KB) Compulsory 3 2:1 Cache Rule Miss rate DM cache size X ~= Miss rate 2-way SA cache size X/2 Conflict 4 2 3Cs Relative Miss Rate 100% 1-way 80% 2-way Conflict 4-way 60% 8-way 40% Capacity 20% Miss Rate per Type 0% 1 2 4 8 16 32 64 128 Caveat: fixed block size Compulsory Cache Size (KB) 5 Victim Caching [Jouppi’90] Victim cache (VC) Processor A small, fully associative structure Effective in direct-mapped caches L1 VC Whenever a line is displaced from L1 cache, it is loaded into VC Memory Processor checks both L1 and VC Victim Cache Organization simultaneously Swap data between VC and L1 if L1 misses and VC hits When data has to be evicted from VC, it is written back to memory 6 3 % of Conflict Misses Removed Dcache Icache 7 Assist Cache [Chan et al. ‘96] Assist Cache (on-chip) avoids thrashing in main (off-chip) L1 Processor cache (both run at full speed) 64 x 32-byte fully associative CAM L1 AC Data enters Assist Cache -

Iilihfflf WWETWIU HI Ull ISTITUTO NAZIONALE DI FISICA NUCLEARE - ISTITUTO NAZIONALE DI FISICA NUCLEARE - \ST, ^3 Laboratori Nazionali Di Frascati
MICROCOPY RESOIUTION TEST CHART NBS • 1010a (ANSI and 150 TEST CHART No 2 PHOTOGRAPHIC SCIENCES CORPORATION 770 BASKFT ROAD P O BOX 13B IILIHfflF WWETWIU HI Ull ISTITUTO NAZIONALE DI FISICA NUCLEARE - ISTITUTO NAZIONALE DI FISICA NUCLEARE - \ST, ^3 Laboratori Nazionali di Frascati LWF - \ft-- Vr-o^ LNF-9S/Q14 (IR) 29 Marzo 1995 The KLOE Collaboration THE KLOE DATA ACQUISITION SYSTEM ADDENDUM TO THE KLOE TECHNICAL PROPOSAL PACS.: 11.30.Er, 13.20.Eb; 13.20.Jf; 29.40.Gx; 29.40.Vj tu. 26 A 2^ Servizio Documentazione dei Laboratori Nazionali di Frascati P.O. Box, 13 - 00044 Frascati (Italy) LNF-yg/014 (IR) 29 Marzo 1995 The KLOE Collaboration THE KLOE DATA ACQUISITION SYSTEM ADDENDUM TO THE KLOE TECHNICAL PROPOSAL PACS.: 11.30.Er, 13.20.Eb; 13.20.Jf; 29.40.Gx; 29.40.Vj IOTN - Laboratori Nazionali di Frascati SIS - Pubblicazioni LNF-fflOH (IR) 29 M?rzo 1995 The KLOE Collaboration THE KLOE DATA ACQUISITION SYSTEM ADDENDUM TO THE KLOE TECHNICAL PROPOSAL ABSTRACT We present in the following the design of the KLOE Data Acquisition System. Included are the philosophy and pxtensive discussions on all parts of the system. The KLOE Collaboration A. Aloisio? A. Andryokov* A. Antonella M. Antonella F. Anulli* C. Avanzini* D. Babusci* C. Baccio R. Baldini-Ferroli* G. BarbielliniT" M. Barone? K. Barth? V. Baturin? H. Beker* G. Bencivenni* S. Bertolucci? C. Bini!* C. Bloise* V. Bocci! V. Bolognesi? F. Bossi?. P. Branching L. Bucci* A. Calcaterra? R. Caloi* P. Campana? G. Capon. M. Carboni? G. Cataldo S. Cavaliere* F. CeradinW L. -

Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation
micromachines Review Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation Fatima Hameed Khan, Muhammad Adeel Pasha * and Shahid Masud * Department of Electrical Engineering, Lahore University of Management Sciences (LUMS), Lahore, Punjab 54792, Pakistan; [email protected] * Correspondence: [email protected] (M.A.P.); [email protected] (S.M.) Abstract: Artificial intelligence (AI) has successfully made its way into contemporary industrial sectors such as automobiles, defense, industrial automation 4.0, healthcare technologies, agriculture, and many other domains because of its ability to act autonomously without continuous human interventions. However, this capability requires processing huge amounts of learning data to extract useful information in real time. The buzz around AI is not new, as this term has been widely known for the past half century. In the 1960s, scientists began to think about machines acting more like humans, which resulted in the development of the first natural language processing computers. It laid the foundation of AI, but there were only a handful of applications until the 1990s due to limitations in processing speed, memory, and computational power available. Since the 1990s, advancements in computer architecture and memory organization have enabled microprocessors to deliver much higher performance. Simultaneously, improvements in the understanding and mathematical representation of AI gave birth to its subset, referred to as machine learning (ML). ML Citation: Khan, F.H.; Pasha, M.A.; includes different algorithms for independent learning, and the most promising ones are based on Masud, S. Advancements in brain-inspired techniques classified as artificial neural networks (ANNs). -

A 160Mhz 32B 0.5W CMOS ARM Processor, Sribalan
Digital Semiconductor StrongARM 3TRONG!2-3! !-HZB7#-/3!2-0ROCESSOR 3RIBALAN3ANTHANAM $IGITAL%QUIPMENT#ORPORATION (OT#HIPS Digital Semiconductor StrongARM /VERVIEW/VERVIEW u Highlights u Design choices u µArchitecture details u Powerdown Modes u Measured Results u Performance Comparisons u Summary Digital Semiconductor StrongARM 0ROCESSOR(IGHLIGHTS0ROCESSOR(IGHLIGHTS u Target Market Segments – Embedded consumer applications – PDA’s, set-top boxes, Internet browsers u Function – Implements ARM V4 Instruction set – Bus compatible with ARM 610,710 and 810 u Performance – Record breaking perfomance/watt and price/performance – 160Mhz @ 1.65V delivers 185 Dhrystone MIPS at < 0.45W – 215Mhz @ 2.0V delivers 245 Dhrystone MIPS at < 0.9W Digital Semiconductor StrongARM 0ROCESSOR(IGHLIGHTS0ROCESSOR(IGHLIGHTS u Process – 2.5 Million transistors (2.2 Million in caches) – 3 Metal CMOS –tOX of 60 Å, LEFF of 0.25 micron, and VT of 0.35v u Packaging – 7.8mm X 6.4mm -> 50mm2 – 144 pin plastic TQFP Digital Semiconductor StrongARM 3TRONG!2-$ESIGN#HOICES3TRONG!2-$ESIGN#HOICES u Chose a simple design with low latency functional units to fit portable power budgets – Simple single issue 5 stage pipeline – Long tick model, low latency – Could have pipelined deeper for faster cycle time but would have exceeded the power budget – Could have gone superscalar but that would have increased control logic cost and power and increased per cycle memory interface needs – Would have increased design time Digital Semiconductor StrongARM 3TRONG!2-$ESIGN#HOICES3TRONG!2-$ESIGN#HOICES -
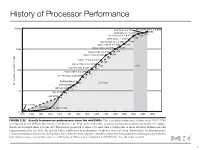
History of Processor Performance
History of Processor Performance )NTELª8EON ªª'(Z BITª)NTELª8EON ªª'(Z !-$ª/PTERON ªª'(Z )NTELª0ENTIUMª ª'(Z !-$ª!THLON ªª'(Z )NTELª0ENTIUMª))) ªª'(Z !LPHAª! ªª'(Z !LPHAª ªª'(Z !LPHAª ªª'(Z !LPHAª ªª'(Z !LPHAª ªª'(Z !LPHAª! ªª'(Z 0OWER0#ª ª'(Z !LPHAª ªª'(Z (0ª0! 2)3# ªª'(Z )"-ª23 YEAR 0ERFORMANCEªVS6!8 -)03ª-ª -)03ª- 3UN 6!8ª 6!8 YEAR 6!8 &)'52%ää 'ROWTHäINäPROCESSORäPERFORMANCEäSINCEäTHEäMID S 4HISäCHARTäPLOTSäPERFORMANCEäRELATIVEäTOäTHEä6!8ää ASäMEASUREDäBYäTHEä30%#INTäBENCHMARKSäSEEä3ECTIONä ä0RIORäTOäTHEäMID S äPROCESSORäPERFORMANCEäGROWTHäWASäLARGELYäTECHNOLOGY DRIVENäANDäAVERAGEDäABOUTääPERäYEARä4HEäINCREASEäINäGROWTHäTOäABOUTääSINCEäTHENäISäATTRIBUTABLEäTOäMOREäADVANCEDäARCHITECTURALäANDä ORGANIZATIONALäIDEASä"Yä äTHISäGROWTHäLEDäTOä AäDIFFERENCEäINäPERFORMANCEäOFäABOUTäAäFACTORäOFäSEVENä0ERFORMANCEäFORämäOATING POINT ORIENTEDäCALCULATIONSäHASäINCREASEDäEVENäFASTERä3INCEä äTHEäLIMITSäOFäPOWER äAVAILABLEäINSTRUCTION LEVELäPARALLELISM äANDäLONGäMEMORYäLATENCYä HAVEäSLOWEDäUNIPROCESSORäPERFORMANCEäRECENTLY äTOäABOUTääPERäYEARä#OPYRIGHTäÚää%LSEVIER ä)NCä!LLäRIGHTSäRESERVED 1 History of Processor Performance )NTELª8EON ªª'(Z BITª)NTELª8EON ªª'(Z !-$ª/PTERON ªª'(Z )NTELª0ENTIUMª ª'(Z CSEE 3827 !-$ª!THLON ªª'(Z )NTELª0ENTIUMª))) ªª'(Z !LPHAª! ªª'(Z !LPHAª ªª'(Z !LPHAª ªª'(Z !LPHAª ªª'(Z !LPHAª ªª'(Z !LPHAª! ªª'(Z 0OWER0#ª ª'(Z !LPHAª ªª'(Z (0ª0! 2)3# ªª'(Z )"-ª23 YEAR 0ERFORMANCEªVS6!8 -)03ª-ª -)03ª- 3UN 6!8ª 6!8 YEAR 6!8 &)'52%ää 'ROWTHäINäPROCESSORäPERFORMANCEäSINCEäTHEäMID