Itanium® Processor 9500 Series Mission Critical Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Micro-Circuits for High Energy Physics*
MICRO-CIRCUITS FOR HIGH ENERGY PHYSICS* Paul F. Kunz Stanford Linear Accelerator Center Stanford University, Stanford, California, U.S.A. ABSTRACT Microprogramming is an inherently elegant method for implementing many digital systems. It is a mixture of hardware and software techniques with the logic subsystems controlled by "instructions" stored Figure 1: Basic TTL Gate in a memory. In the past, designing microprogrammed systems was difficult, tedious, and expensive because the available components were capable of only limited number of functions. Today, however, large blocks of microprogrammed systems have been incorporated into a A input B input C output single I.e., thus microprogramming has become a simple, practical method. false false true false true true true false true true true false 1. INTRODUCTION 1.1 BRIEF HISTORY OF MICROCIRCUITS Figure 2: Truth Table for NAND Gate. The first question which arises when one talks about microcircuits is: What is a microcircuit? The answer is simple: a complete circuit within a single integrated-circuit (I.e.) package or chip. The next question one might ask is: What circuits are available? The answer to this question is also simple: it depends. It depends on the economics of the circuit for the semiconductor manufacturer, which depends on the technology he uses, which in turn changes as a function of time. Thus to understand Figure 3: Logical NOT Circuit. what microcircuits are available today and what makes them different from those of yesterday it is interesting to look into the economics of producing microcircuits. The basic element in a logic circuit is a gate, which is a circuit with a number of inputs and one output and it performs a basic logical function such as AND, OR, or NOT. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Parallel Computing
Lecture 1: Computer Organization 1 Outline • Overview of parallel computing • Overview of computer organization – Intel 8086 architecture • Implicit parallelism • von Neumann bottleneck • Cache memory – Writing cache-friendly code 2 Why parallel computing • Solving an × linear system Ax=b by using Gaussian elimination takes ≈ flops. 1 • On Core i7 975 @ 4.0 GHz,3 which is capable of about 3 60-70 Gigaflops flops time 1000 3.3×108 0.006 seconds 1000000 3.3×1017 57.9 days 3 What is parallel computing? • Serial computing • Parallel computing https://computing.llnl.gov/tutorials/parallel_comp 4 Milestones in Computer Architecture • Analytic engine (mechanical device), 1833 – Forerunner of modern digital computer, Charles Babbage (1792-1871) at University of Cambridge • Electronic Numerical Integrator and Computer (ENIAC), 1946 – Presper Eckert and John Mauchly at the University of Pennsylvania – The first, completely electronic, operational, general-purpose analytical calculator. 30 tons, 72 square meters, 200KW. – Read in 120 cards per minute, Addition took 200µs, Division took 6 ms. • IAS machine, 1952 – John von Neumann at Princeton’s Institute of Advanced Studies (IAS) – Program could be represented in digit form in the computer memory, along with data. Arithmetic could be implemented using binary numbers – Most current machines use this design • Transistors was invented at Bell Labs in 1948 by J. Bardeen, W. Brattain and W. Shockley. • PDP-1, 1960, DEC – First minicomputer (transistorized computer) • PDP-8, 1965, DEC – A single bus -

Programmable Digital Microcircuits - a Survey with Examples of Use
- 237 - PROGRAMMABLE DIGITAL MICROCIRCUITS - A SURVEY WITH EXAMPLES OF USE C. Verkerk CERN, Geneva, Switzerland 1. Introduction For most readers the title of these lecture notes will evoke microprocessors. The fixed instruction set microprocessors are however not the only programmable digital mi• crocircuits and, although a number of pages will be dedicated to them, the aim of these notes is also to draw attention to other useful microcircuits. A complete survey of programmable circuits would fill several books and a selection had therefore to be made. The choice has rather been to treat a variety of devices than to give an in- depth treatment of a particular circuit. The selected devices have all found useful ap• plications in high-energy physics, or hold promise for future use. The microprocessor is very young : just over eleven years. An advertisement, an• nouncing a new era of integrated electronics, and which appeared in the November 15, 1971 issue of Electronics News, is generally considered its birth-certificate. The adver• tisement was for the Intel 4004 and its three support chips. The history leading to this announcement merits to be recalled. Intel, then a very young company, was working on the design of a chip-set for a high-performance calculator, for and in collaboration with a Japanese firm, Busicom. One of the Intel engineers found the Busicom design of 9 different chips too complicated and tried to find a more general and programmable solu• tion. His design, the 4004 microprocessor, was finally adapted by Busicom, and after further négociation, Intel acquired marketing rights for its new invention. -

5 Microprocessors
Color profile: Disabled Composite Default screen BaseTech / Mike Meyers’ CompTIA A+ Guide to Managing and Troubleshooting PCs / Mike Meyers / 380-8 / Chapter 5 5 Microprocessors “MEGAHERTZ: This is a really, really big hertz.” —DAVE BARRY In this chapter, you will learn or all practical purposes, the terms microprocessor and central processing how to Funit (CPU) mean the same thing: it’s that big chip inside your computer ■ Identify the core components of a that many people often describe as the brain of the system. You know that CPU CPU makers name their microprocessors in a fashion similar to the automobile ■ Describe the relationship of CPUs and memory industry: CPU names get a make and a model, such as Intel Core i7 or AMD ■ Explain the varieties of modern Phenom II X4. But what’s happening inside the CPU to make it able to do the CPUs amazing things asked of it every time you step up to the keyboard? ■ Install and upgrade CPUs 124 P:\010Comp\BaseTech\380-8\ch05.vp Friday, December 18, 2009 4:59:24 PM Color profile: Disabled Composite Default screen BaseTech / Mike Meyers’ CompTIA A+ Guide to Managing and Troubleshooting PCs / Mike Meyers / 380-8 / Chapter 5 Historical/Conceptual ■ CPU Core Components Although the computer might seem to act quite intelligently, comparing the CPU to a human brain hugely overstates its capabilities. A CPU functions more like a very powerful calculator than like a brain—but, oh, what a cal- culator! Today’s CPUs add, subtract, multiply, divide, and move billions of numbers per second. -

Opinion Ten Reasons Why HP’S Itanium-Based Servers Have Reached the Point-Of-No-Return
Opinion Ten Reasons Why HP’s Itanium-based Servers Have Reached the Point-of-No-Return Executive Summary Hewlett-Packard (HP) refers to its HP Integrity and Integrity NonStop Itanium-based servers as “business critical systems”. In Q4, 2007, HP sold over $1 billion of these business critical systems. But, since then, due to a number of factors, Itanium-based server sales have declined significantly. Over the past year, business critical systems sales have hovered in the $400 million range per quarter, an almost 60% decline as compared with the 2007 high-mark. From our perspective, HP’s Itanium-based servers have now achieved a form of stasis (a medical term that refers to an inactive state). We expect a rise in Itanium business this quarter (due to pent-up demand for the new Itanium 9500), but we also expect that – within in a few quarters – underlying, dogging problems will again drive Itanium business downward. These problems include HP’s financial woes; increased competition (particularly from Intel x86-based servers); market factors (such as the market move toward Linux and a market preference for x86 architecture); a broken ecosystem (where HP has actually had to take legal action to get a business partner to keep supporting its independent software on Itanium-based platforms); an ill-founded Itanium recovery plan known as “converged infrastructure”; and more (in fact, we list a total of ten reasons why we believe HP’s Itanium-based servers have reached the point-of-no- return on page 2 of this Opinion)… In this Opinion , Clabby Analytics describes why we believe that HP’s business critical Integrity servers have now reached the point-of-no-return. -
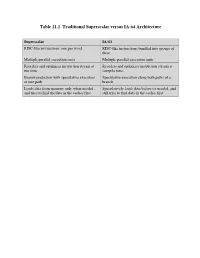
Table 21.1 Traditional Superscalar Versus IA-64 Architecture
Table 21.1 Traditional Superscalar versus IA-64 Architecture Superscalar IA-64 RISC-like instructions, one per word RISC-like instructions bundled into groups of three Multiple parallel execution units Multiple parallel execution units Reorders and optimizes instruction stream at Reorders and optimizes instruction stream at run time compile time Branch prediction with speculative execution Speculative execution along both paths of a of one path branch Loads data from memory only when needed, Speculatively loads data before its needed, and and tries to find the data in the caches first still tries to find data in the caches first Table 21.2 Relationship Between Instruction Type and Execution Unit Type Instruction Type Description Execution Unit Type A Integer ALU I-unit or M-unit I Non-ALU integer I-unit M Memory M-unit F Floating-point F-unit B Branch B-unit X Extended I-unit/B-unit Table 21.3 Template Field Encoding and Instruction Set Mapping Template Slot 0 Slot 1 Slot 2 00 M-unit I-unit I-unit 01 M-unit I-unit I-unit 02 M-unit I-unit I-unit 03 M-unit I-unit I-unit 04 M-unit L-unit X-unit 05 M-unit L-unit X-unit 08 M-unit M-unit I-unit 09 M-unit M-unit I-unit 0A M-unit M-unit I-unit 0B M-unit M-unit I-unit 0C M-unit F-unit I-unit 0D M-unit F-unit I-unit 0E M-unit M-unit F-unit 0F M-unit M-unit F-unit 10 M-unit I-unit B-unit 11 M-unit I-unit B-unit 12 M-unit B-unit B-unit 13 M-unit B-unit B-unit 16 B-unit B-unit B-unit 17 B-unit B-unit B-unit 18 M-unit M-unit B-unit 19 M-unit M-unit B-unit 1C M-unit F-unit B-unit 1D M-unit F-unit B-unit Table 21.5 IA-64 Application Registers Kernel registers (KR0-7) Convey information from the operating system to the application. -

The IA-32 Processor Architecture
The IA-32 processor architecture Nicholas FitzRoy-Dale Document Revision: 1 Date: 2006/05/30 22:31:24 [email protected] http://www.cse.unsw.edu.au/∼disy/ Operating Systems and Distributed Systems Group School of Computer Science and Engineering The University of New South Wales UNSW Sydney 2052, Australia 1 Introduction This report discusses the most common instruction set architecture for desktop microprocessors: IA- 32. From a programmer’s perspective, IA-32 has not changed changed significantly since its introduc- tion with the Intel 80386 processor in 1985. IA-32 implementations, however, have undergone dra- matic changes in order to stay competitive with more modern architectures, particularly in the area of instruction-level parallelism. This report discusses the history of IA-32, and then the architectural features of recent IA-32 im- plementations, with particular regard to caching, multiprocessing, and instruction-level parallelism. An archtectural description is not particularly useful in isolation. Therefore, to provide context, each as- pect is compared with analogous features of other architectures, with particular attention paid to the RISC-style ARM processor and the VLIW-inspired Itanium. 2 A brief history of IA-32 IA-32 first appeared with the 80386 processor, but the architecture was by no means completely new. IA-32’s 8-bit predecessor first appeared in the Datapoint 2200 programmable terminal, released in 1971. Under contract to produce a single-chip version of the terminal’s multiple-chip TTL design, Intel’s im- plementation, the 8008, was not included in the terminal. Intel released the chip in 1972. -

Intel Itanium 2 Processors Get Faster Bus Architecture 18 July 2005
Intel Itanium 2 Processors Get Faster Bus Architecture 18 July 2005 Intel Corporation today introduced two Intel Itanium based servers. 2 processors which deliver better performance over the current generation for database, business The improved front side bus bandwidth allows for intelligence, enterprise resource planning and 10.6 gigabits of data per second to pass from the technical computing applications. processor to other system components. In contrast, the current generation 400 MHz FSB transfers 6.4 For the first time, Itanium 2 processors have a 667 gigabits of data per second. The ability to move megahertz (MHz) front side bus (FSB), which more data in a very short period of time is critical to connects and transfers data between the compute intensive applications in the scientific, oil microprocessor, chipset and system's main and gas and government industries. memory. Servers designed to utilize the new bus are expected to deliver more than 65 percent Hitachi, which will adopt the new Itanium 2 greater system bandwidth over servers designed processors with the 667 FSB into new Hitachi with current Itanium 2 processors with a 400 MHz BladeSymphony* servers coming in the next 30 FSB. This new capability will help set the stage for days, has also designed a chipset (the the forthcoming dual core Itanium processor, communications controller between the processor codenamed "Montecito," which will feature the and the rest of the computer system) to take same bus architecture. advantage of the new bus architecture. "Intel continues to bring new capabilities to the Platforms using Montecito are expected to deliver Itanium architecture, evolving the platform to up to twice the performance, up to three times the further improve performance for data intensive system bandwidth, and more than 2 1/2 times as tasks," said Kirk Skaugen, general manager of much on-die cache as the current generation of Intel's Server Platforms Group. -

V850E2S User's Manual: Architecture
User’s Manual User’s V850E2S 32 User’s Manual: Architecture RENESAS MCU V850E2S Microprocessor Core All information contained in these materials, including products and product specifications, represents information on the product at the time of publication and is subject to change by Renesas Electronics Corp. without notice. Please review the latest information published by Renesas Electronics Corp. through various means, including the Renesas Electronics Corp. website (http://www.renesas.com). www.renesas.com Rev.1.00 May, 2014 Notice 1. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. You are fully responsible for the incorporation of these circuits, software, and information in the design of your equipment. Renesas Electronics assumes no responsibility for any losses incurred by you or third parties arising from the use of these circuits, software, or information. 2. Renesas Electronics has used reasonable care in preparing the information included in this document, but Renesas Electronics does not warrant that such information is error free. Renesas Electronics assumes no liability whatsoever for any damages incurred by you resulting from errors in or omissions from the information included herein. 3. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 4. -

(12) Patent Application Publication (10) Pub. No.: US 2015/0067389 A1 Galloway (43) Pub
US 2015 OO67389A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2015/0067389 A1 Galloway (43) Pub. Date: Mar. 5, 2015 (54) PROGRAMMABLE SUBSTITUTIONS FOR (52) U.S. Cl. MCROCODE CPC .......... G06F 1 1/1405 (2013.01); G06F 9/3016 (2013.01) (71) Applicant: ADVANCED MICRO DEVICES, USPC ............................................................ 71.4/10 INC., Sunnyvale, CA (US) (72) Inventor: Frank C. Galloway, Dripping Springs, TX (US) (57) ABSTRACT (73) Assignee: ADVANCED MICRO DEVICES, INC., Sunnyvale, CA (US) The apparatuses, systems, and methods in accordance with the embodiments disclosed herein may facilitate modifying (21) Appl. No.: 14/014,220 post silicon instruction behavior. Embodiments herein may provide registers in predetermined locations in an integrated (22) Filed: Aug. 29, 2013 circuit. These registers may be mapped to generic instruc Publication Classification tions, which can modify an operation of the integrated circuit. In some embodiments, these registers may be used to imple (51) Int. C. ment a patch routine to change the behavior of at least a G06F II/4 (2006.01) portion of the integrated circuit. In this manner, the original G06F 9/30 (2006.01) design of the integrated circuit may be altered. Peera Revices Processor Central Processing init (CPU) agrarirrate Comute act Output. {-n}init(s) Dynamic Randon evices) 165 Access Merroy 142 (DRAM) i 2 t South Eridge pi (evices) f Graphics Processing Unit (GP or Floating Point (Graphics Processor) B (EPU) 8 as 8 : Programmate -: agrariate Scrage Storage Paic nit as it 1 65 Patent Application Publication Mar. 5, 2015 Sheet 1 of 7 US 2015/0067389 A1 §6% Patent Application Publication Mar. -

Database Integration
I DATABASE INTEGRATION ALPHA SERVERS & WORKSTATIONS Digital ALPHA 21164 CPU Technical Journal Editorial The Digital TechnicalJournal is a refereed Cyrix is a trademark of Cyrix Corporation. Jane C. Blake, Managing Editor journal published quarterly by Digital dBASE is a trademark and Paradox is Helen L. Patterson, Editor Equipment Corporation, 30 Porter Road a registered trademark of Borland Kathleen M. Stetson, Editor LJ02/D10, Littleton, Massachusetts 01460. International, Inc. Subscriptionsto the Journal are $40.00 Circulation (non-U.S. $60) for four issues and $75.00 EDA/SQL is a trademark of Information Catherine M. Phillips, Administrator (non-U.S. $115) for eight issues and must Builders, Inc. Dorothea B. Cassady, Secretary be prepaid in U.S. funds. University and Encina is a registered trademark of Transarc college professors and Ph.D. students in Corporation. Production the electrical engineering and computer Excel and Microsoft are registered pde- Terri Autieri, Production Editor science fields receive complimentary sub- marks and Windows and Windows NT are Anne S. Katzeff, Typographer scriptions upon request. Orders, inquiries, trademarks of Microsoft Corporation. Joanne Murphy, Typographer and address changes should be sent to the Peter R Woodbury, Illustrator Digital TechnicalJournal at the published- Hewlett-Packard and HP-UX are registered by address. Inquiries can also be sent elec- trademarks of Hewlett-Packard Company. Advisory Board tronically to [email protected]. Single copies INGRES is a registered trademark of Ingres Samuel H. Fuller, Chairman and back issues are available for $16.00 each Corporation. Richard W. Beane by calling DECdirect at 1-800-DIGITAL Donald Z. Harbert (1-800-344-4825).