Parallel Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fill Your Boots: Enhanced Embedded Bootloader Exploits Via Fault Injection and Binary Analysis
IACR Transactions on Cryptographic Hardware and Embedded Systems ISSN 2569-2925, Vol. 2021, No. 1, pp. 56–81. DOI:10.46586/tches.v2021.i1.56-81 Fill your Boots: Enhanced Embedded Bootloader Exploits via Fault Injection and Binary Analysis Jan Van den Herrewegen1, David Oswald1, Flavio D. Garcia1 and Qais Temeiza2 1 School of Computer Science, University of Birmingham, UK, {jxv572,d.f.oswald,f.garcia}@cs.bham.ac.uk 2 Independent Researcher, [email protected] Abstract. The bootloader of an embedded microcontroller is responsible for guarding the device’s internal (flash) memory, enforcing read/write protection mechanisms. Fault injection techniques such as voltage or clock glitching have been proven successful in bypassing such protection for specific microcontrollers, but this often requires expensive equipment and/or exhaustive search of the fault parameters. When multiple glitches are required (e.g., when countermeasures are in place) this search becomes of exponential complexity and thus infeasible. Another challenge which makes embedded bootloaders notoriously hard to analyse is their lack of debugging capabilities. This paper proposes a grey-box approach that leverages binary analysis and advanced software exploitation techniques combined with voltage glitching to develop a powerful attack methodology against embedded bootloaders. We showcase our techniques with three real-world microcontrollers as case studies: 1) we combine static and on-chip dynamic analysis to enable a Return-Oriented Programming exploit on the bootloader of the NXP LPC microcontrollers; 2) we leverage on-chip dynamic analysis on the bootloader of the popular STM8 microcontrollers to constrain the glitch parameter search, achieving the first fully-documented multi-glitch attack on a real-world target; 3) we apply symbolic execution to precisely aim voltage glitches at target instructions based on the execution path in the bootloader of the Renesas 78K0 automotive microcontroller. -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

3.2 the CORDIC Algorithm
UC San Diego UC San Diego Electronic Theses and Dissertations Title Improved VLSI architecture for attitude determination computations Permalink https://escholarship.org/uc/item/5jf926fv Author Arrigo, Jeanette Fay Freauf Publication Date 2006 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California 1 UNIVERSITY OF CALIFORNIA, SAN DIEGO Improved VLSI Architecture for Attitude Determination Computations A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical and Computer Engineering (Electronic Circuits and Systems) by Jeanette Fay Freauf Arrigo Committee in charge: Professor Paul M. Chau, Chair Professor C.K. Cheng Professor Sujit Dey Professor Lawrence Larson Professor Alan Schneider 2006 2 Copyright Jeanette Fay Freauf Arrigo, 2006 All rights reserved. iv DEDICATION This thesis is dedicated to my husband Dale Arrigo for his encouragement, support and model of perseverance, and to my father Eugene Freauf for his patience during my pursuit. In memory of my mother Fay Freauf and grandmother Fay Linton Thoreson, incredible mentors and great advocates of the quest for knowledge. iv v TABLE OF CONTENTS Signature Page...............................................................................................................iii Dedication … ................................................................................................................iv Table of Contents ...........................................................................................................v -

Micro-Circuits for High Energy Physics*
MICRO-CIRCUITS FOR HIGH ENERGY PHYSICS* Paul F. Kunz Stanford Linear Accelerator Center Stanford University, Stanford, California, U.S.A. ABSTRACT Microprogramming is an inherently elegant method for implementing many digital systems. It is a mixture of hardware and software techniques with the logic subsystems controlled by "instructions" stored Figure 1: Basic TTL Gate in a memory. In the past, designing microprogrammed systems was difficult, tedious, and expensive because the available components were capable of only limited number of functions. Today, however, large blocks of microprogrammed systems have been incorporated into a A input B input C output single I.e., thus microprogramming has become a simple, practical method. false false true false true true true false true true true false 1. INTRODUCTION 1.1 BRIEF HISTORY OF MICROCIRCUITS Figure 2: Truth Table for NAND Gate. The first question which arises when one talks about microcircuits is: What is a microcircuit? The answer is simple: a complete circuit within a single integrated-circuit (I.e.) package or chip. The next question one might ask is: What circuits are available? The answer to this question is also simple: it depends. It depends on the economics of the circuit for the semiconductor manufacturer, which depends on the technology he uses, which in turn changes as a function of time. Thus to understand Figure 3: Logical NOT Circuit. what microcircuits are available today and what makes them different from those of yesterday it is interesting to look into the economics of producing microcircuits. The basic element in a logic circuit is a gate, which is a circuit with a number of inputs and one output and it performs a basic logical function such as AND, OR, or NOT. -

Id Question Microprocessor Is the Example of ___Architecture. A
Id Question Microprocessor is the example of _______ architecture. A Princeton B Von Neumann C Rockwell D Harvard Answer A Marks 1 Unit 1 Id Question _______ bus is unidirectional. A Data B Address C Control D None of these Answer B Marks 1 Unit 1 Id Question Use of _______isolates CPU form frequent accesses to main memory. A Local I/O controller B Expansion bus interface C Cache structure D System bus Answer C Marks 1 Unit 1 Id Question _______ buffers data transfer between system bus and I/O controllers on expansion bus. A Local I/O controller B Expansion bus interface C Cache structure D None of these Answer B Marks 1 Unit 1 Id Question ______ Timing involves a clock line. A Synchronous B Asynchronous C Asymmetric D None of these Answer A Marks 1 Unit 1 Id Question -----timing takes advantage of mixture of slow and fast devices, sharing the same bus A Synchronous B asynchronous C Asymmetric D None of these Answer B Marks 1 Unit 1 Id st Question In 1 generation _____language was used to prepare programs. A Machine B Assembly C High level programming D Pseudo code Answer B Marks 1 Unit 1 Id Question The transistor was invented at ________ laboratories. A AT &T B AT &Y C AM &T D AT &M Answer A Marks 1 Unit 1 Id Question ______is used to control various modules in the system A Control Bus B Data Bus C Address Bus D All of these Answer A Marks 1 Unit 1 Id Question The disadvantage of single bus structure over multi bus structure is _____ A Propagation delay B Bottle neck because of bus capacity C Both A and B D Neither A nor B Answer C Marks 1 Unit 1 Id Question _____ provide path for moving data among system modules A Control Bus B Data Bus C Address Bus D All of these Answer B Marks 1 Unit 1 Id Question Microcontroller is the example of _____ architecture. -

Consider an Instruction Cycle Consisting of Fetch, Operators Fetch (Immediate/Direct/Indirect), Execute and Interrupt Cycles
Module-2, Unit-3 Instruction Execution Question 1: Consider an instruction cycle consisting of fetch, operators fetch (immediate/direct/indirect), execute and interrupt cycles. Explain the purpose of these four cycles. Solution 1: The life of an instruction passes through four phases—(i) Fetch, (ii) Decode and operators fetch, (iii) execute and (iv) interrupt. The purposes of these phases are as follows 1. Fetch We know that in the stored program concept, all instructions are also present in the memory along with data. So the first phase is the “fetch”, which begins with retrieving the address stored in the Program Counter (PC). The address stored in the PC refers to the memory location holding the instruction to be executed next. Following that, the address present in the PC is given to the address bus and the memory is set to read mode. The contents of the corresponding memory location (i.e., the instruction) are transferred to a special register called the Instruction Register (IR) via the data bus. IR holds the instruction to be executed. The PC is incremented to point to the next address from which the next instruction is to be fetched So basically the fetch phase consists of four steps: a) MAR <= PC (Address of next instruction from Program counter is placed into the MAR) b) MBR<=(MEMORY) (the contents of Data bus is copied into the MBR) c) PC<=PC+1 (PC gets incremented by instruction length) d) IR<=MBR (Data i.e., instruction is transferred from MBR to IR and MBR then gets freed for future data fetches) 2. -

Akukwe Michael Lotachukwu 18/Sci01/014 Computer Science
AKUKWE MICHAEL LOTACHUKWU 18/SCI01/014 COMPUTER SCIENCE The purpose of every computer is some form of data processing. The CPU supports data processing by performing the functions of fetch, decode and execute on programmed instructions. Taken together, these functions are frequently referred to as the instruction cycle. In addition to the instruction cycle functions, the CPU performs fetch and writes functions on data. When a program runs on a computer, instructions are stored in computer memory until they're executed. The CPU uses a program counter to fetch the next instruction from memory, where it's stored in a format known as assembly code. The CPU decodes the instruction into binary code that can be executed. Once this is done, the CPU does what the instruction tells it to, performing an operation, fetching or storing data or adjusting the program counter to jump to a different instruction. The types of operations that typically can be performed by the CPU include simple math functions like addition, subtraction, multiplication and division. The CPU can also perform comparisons between data objects to determine if they're equal. All the amazing things that computers can do are performed with these and a few other basic operations. After an instruction is executed, the next instruction is fetched and the cycle continues. While performing the execute function of the instruction cycle, the CPU may be asked to execute an instruction that requires data. For example, executing an arithmetic function requires the numbers that will be used for the calculation. To deliver the necessary data, there are instructions to fetch data from memory and write data that has been processed back to memory. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Programmable Digital Microcircuits - a Survey with Examples of Use
- 237 - PROGRAMMABLE DIGITAL MICROCIRCUITS - A SURVEY WITH EXAMPLES OF USE C. Verkerk CERN, Geneva, Switzerland 1. Introduction For most readers the title of these lecture notes will evoke microprocessors. The fixed instruction set microprocessors are however not the only programmable digital mi• crocircuits and, although a number of pages will be dedicated to them, the aim of these notes is also to draw attention to other useful microcircuits. A complete survey of programmable circuits would fill several books and a selection had therefore to be made. The choice has rather been to treat a variety of devices than to give an in- depth treatment of a particular circuit. The selected devices have all found useful ap• plications in high-energy physics, or hold promise for future use. The microprocessor is very young : just over eleven years. An advertisement, an• nouncing a new era of integrated electronics, and which appeared in the November 15, 1971 issue of Electronics News, is generally considered its birth-certificate. The adver• tisement was for the Intel 4004 and its three support chips. The history leading to this announcement merits to be recalled. Intel, then a very young company, was working on the design of a chip-set for a high-performance calculator, for and in collaboration with a Japanese firm, Busicom. One of the Intel engineers found the Busicom design of 9 different chips too complicated and tried to find a more general and programmable solu• tion. His design, the 4004 microprocessor, was finally adapted by Busicom, and after further négociation, Intel acquired marketing rights for its new invention. -

P the Pioneers and Their Computers
The Videotape Sources: The Pioneers and their Computers • Lectures at The Compp,uter Museum, Marlboro, MA, September 1979-1983 • Goal: Capture data at the source • The first 4: Atanasoff (ABC), Zuse, Hopper (IBM/Harvard), Grosch (IBM), Stibitz (BTL) • Flowers (Colossus) • ENIAC: Eckert, Mauchley, Burks • Wilkes (EDSAC … LEO), Edwards (Manchester), Wilkinson (NPL ACE), Huskey (SWAC), Rajchman (IAS), Forrester (MIT) What did it feel like then? • What were th e comput ers? • Why did their inventors build them? • What materials (technology) did they build from? • What were their speed and memory size specs? • How did they work? • How were they used or programmed? • What were they used for? • What did each contribute to future computing? • What were the by-products? and alumni/ae? The “classic” five boxes of a stored ppgrogram dig ital comp uter Memory M Central Input Output Control I O CC Central Arithmetic CA How was programming done before programming languages and O/Ss? • ENIAC was programmed by routing control pulse cables f ormi ng th e “ program count er” • Clippinger and von Neumann made “function codes” for the tables of ENIAC • Kilburn at Manchester ran the first 17 word program • Wilkes, Wheeler, and Gill wrote the first book on programmiidbBbbIiSiing, reprinted by Babbage Institute Series • Parallel versus Serial • Pre-programming languages and operating systems • Big idea: compatibility for program investment – EDSAC was transferred to Leo – The IAS Computers built at Universities Time Line of First Computers Year 1935 1940 1945 1950 1955 ••••• BTL ---------o o o o Zuse ----------------o Atanasoff ------------------o IBM ASCC,SSEC ------------o-----------o >CPC ENIAC ?--------------o EDVAC s------------------o UNIVAC I IAS --?s------------o Colossus -------?---?----o Manchester ?--------o ?>Ferranti EDSAC ?-----------o ?>Leo ACE ?--------------o ?>DEUCE Whirl wi nd SEAC & SWAC ENIAC Project Time Line & Descendants IBM 701, Philco S2000, ERA.. -
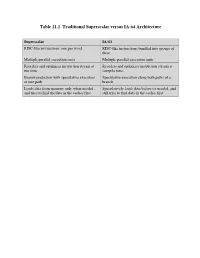
Table 21.1 Traditional Superscalar Versus IA-64 Architecture
Table 21.1 Traditional Superscalar versus IA-64 Architecture Superscalar IA-64 RISC-like instructions, one per word RISC-like instructions bundled into groups of three Multiple parallel execution units Multiple parallel execution units Reorders and optimizes instruction stream at Reorders and optimizes instruction stream at run time compile time Branch prediction with speculative execution Speculative execution along both paths of a of one path branch Loads data from memory only when needed, Speculatively loads data before its needed, and and tries to find the data in the caches first still tries to find data in the caches first Table 21.2 Relationship Between Instruction Type and Execution Unit Type Instruction Type Description Execution Unit Type A Integer ALU I-unit or M-unit I Non-ALU integer I-unit M Memory M-unit F Floating-point F-unit B Branch B-unit X Extended I-unit/B-unit Table 21.3 Template Field Encoding and Instruction Set Mapping Template Slot 0 Slot 1 Slot 2 00 M-unit I-unit I-unit 01 M-unit I-unit I-unit 02 M-unit I-unit I-unit 03 M-unit I-unit I-unit 04 M-unit L-unit X-unit 05 M-unit L-unit X-unit 08 M-unit M-unit I-unit 09 M-unit M-unit I-unit 0A M-unit M-unit I-unit 0B M-unit M-unit I-unit 0C M-unit F-unit I-unit 0D M-unit F-unit I-unit 0E M-unit M-unit F-unit 0F M-unit M-unit F-unit 10 M-unit I-unit B-unit 11 M-unit I-unit B-unit 12 M-unit B-unit B-unit 13 M-unit B-unit B-unit 16 B-unit B-unit B-unit 17 B-unit B-unit B-unit 18 M-unit M-unit B-unit 19 M-unit M-unit B-unit 1C M-unit F-unit B-unit 1D M-unit F-unit B-unit Table 21.5 IA-64 Application Registers Kernel registers (KR0-7) Convey information from the operating system to the application.