Computer Organization and Architecture Designing for Performance Ninth Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Floating-Point Package for Intel 8008 and 8080 Microprocessors
UCRL-51940 FLOATING-POINT PACKAGE FOR INTEL 8008 AND 8080 MICROPROCESSORS Michael D. Maples October 24, 1975 Prepared for U.S. Energy Research& Development Administration under contract No. W-7405-Eng-48 I_AV~=IENCE I_IVEFIMORE I.ABOFIATOFIY University ol Calilomia ~ Livermore ~ NOTICE .sponsored by tht: United $~ates G~ven~menl.Neilhe~ the United States nor the United ~tates I’:n,~rgy of their employees,IIOr lilly of their eorltl’ilctclrs~ warranty~ express t~r implied, or asstltlleS ~t]y legld liability or responsihilit y fnr the accuracy, apparatus, product or ])rc)eess disclosed, represents that its rise would IIt~l illl’r liege privlttely-owned rights." Printed in the United States of America Avai.] able from National Technical. information Service U.S. Department of Commerce 5285 Port Royal Road Springfield, Virginia 22151 Price: Printed Copy $ *; Microfiche $2.25 NTIS ""Pages _Sellin_.g Price 1-50 $4.00 51-150 $5.45 151-325 $7.60 326-500 $10.60 501.-1000 $13.60 DISCI.AlMBR This documeut was prepared as an account of work sponsored by an agency of the United States Gnvernment.Neither the United States Governmentnor the University of California nor any of their employees,makes any warranty, express or implied, or assumesany legal liability or responsibility for the accuracy, complete.aess, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use wouldnot infrioge privately ownedrights. Refarenceherein to any specific commercialproduct, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation,or favoring by the United States Govermnentor the University of California. -

Fill Your Boots: Enhanced Embedded Bootloader Exploits Via Fault Injection and Binary Analysis
IACR Transactions on Cryptographic Hardware and Embedded Systems ISSN 2569-2925, Vol. 2021, No. 1, pp. 56–81. DOI:10.46586/tches.v2021.i1.56-81 Fill your Boots: Enhanced Embedded Bootloader Exploits via Fault Injection and Binary Analysis Jan Van den Herrewegen1, David Oswald1, Flavio D. Garcia1 and Qais Temeiza2 1 School of Computer Science, University of Birmingham, UK, {jxv572,d.f.oswald,f.garcia}@cs.bham.ac.uk 2 Independent Researcher, [email protected] Abstract. The bootloader of an embedded microcontroller is responsible for guarding the device’s internal (flash) memory, enforcing read/write protection mechanisms. Fault injection techniques such as voltage or clock glitching have been proven successful in bypassing such protection for specific microcontrollers, but this often requires expensive equipment and/or exhaustive search of the fault parameters. When multiple glitches are required (e.g., when countermeasures are in place) this search becomes of exponential complexity and thus infeasible. Another challenge which makes embedded bootloaders notoriously hard to analyse is their lack of debugging capabilities. This paper proposes a grey-box approach that leverages binary analysis and advanced software exploitation techniques combined with voltage glitching to develop a powerful attack methodology against embedded bootloaders. We showcase our techniques with three real-world microcontrollers as case studies: 1) we combine static and on-chip dynamic analysis to enable a Return-Oriented Programming exploit on the bootloader of the NXP LPC microcontrollers; 2) we leverage on-chip dynamic analysis on the bootloader of the popular STM8 microcontrollers to constrain the glitch parameter search, achieving the first fully-documented multi-glitch attack on a real-world target; 3) we apply symbolic execution to precisely aim voltage glitches at target instructions based on the execution path in the bootloader of the Renesas 78K0 automotive microcontroller. -

8088 8-Bit Hmos Microprocessor 8088 8088-2
8088 8-BIT HMOS MICROPROCESSOR 8088/8088-2 Y 8-Bit Data Bus Interface Y Byte, Word, and Block Operations Y 16-Bit Internal Architecture Y 8-Bit and 16-Bit Signed and Unsigned Arithmetic in Binary or Decimal, Y Direct Addressing Capability to 1 Mbyte of Memory Including Multiply and Divide Y Two Clock Rates: Y Direct Software Compatibility with 8086 CPU Ð 5 MHz for 8088 Ð 8 MHz for 8088-2 Y 14-Word by 16-Bit Register Set with Symmetrical Operations Y Available in EXPRESS Ð Standard Temperature Range Y 24 Operand Addressing Modes Ð Extended Temperature Range The Intel 8088 is a high performance microprocessor implemented in N-channel, depletion load, silicon gate technology (HMOS-II), and packaged in a 40-pin CERDIP package. The processor has attributes of both 8- and 16-bit microprocessors. It is directly compatible with 8086 software and 8080/8085 hardware and periph- erals. 231456±2 Figure 2. 8088 Pin Configuration 231456±1 Figure 1. 8088 CPU Functional Block Diagram August 1990 Order Number: 231456-006 8088 Table 1. Pin Description The following pin function descriptions are for 8088 systems in either minimum or maximum mode. The ``local bus'' in these descriptions is the direct multiplexed bus interface connection to the 8088 (without regard to additional bus buffers). Symbol Pin No. Type Name and Function AD7±AD0 9±16 I/O ADDRESS DATA BUS: These lines constitute the time multiplexed memory/IO address (T1) and data (T2, T3, Tw, T4) bus. These lines are active HIGH and float to 3-state OFF during interrupt acknowledge and local bus ``hold acknowledge''. -

Secondary Memory
Secondary Memory This type of memory is also known as external memory or non-volatile. It is slower than main memory. These are used for storing data/Information permanently. CPU directly does not access these memories instead they are accessed via input-output routines. Contents of secondary memories are first transferred to main memory, and then CPU can access it. For example : Hard disk, CD-ROM, DVD etc. Electronic data is a sequence of bits. This data can either reside in : • Primary storage - main memory (RAM), relatively small, fast access, expensive (cost per MB), volatile (go away when power goes off) • Secondary storage - disks, tape, large amounts of data, slower access, cheap (cost per MB), persistent (remain even when power is off) Data storage has expanded from text and numeric files to include digital music files, photographic files, video files, and much more. These new types of files require secondary storage devices with much greater capacity than floppy disks. 1 Primary storage ( or main memory or internal memory) , often referred to simply as memory , is the only directly accessible to the CPU. Primary memory can be divided into volatile and nonvolatile memories. Primary storage (Main Memory ) has three main functions: 1-It stored all or part of the program that being executed. 2-It also holds data that are being used by the program. 3-It also stored the operating system programs that manage the operation of the computer. Limitation of Primary storage 1. Limited capacity- because the cost per bit of storage is high. 2. Volatile – data stored in it is lost when the electric power is turned off Or interrupted. -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

Lecture 1: Course Introduction G Course Organization G Historical Overview G Computer Organization G Why the MC68000? G Why Assembly Language?
Lecture 1: Course introduction g Course organization g Historical overview g Computer organization g Why the MC68000? g Why assembly language? Microprocessor-based System Design 1 Ricardo Gutierrez-Osuna Wright State University Course organization g Grading Instructor n Exams Ricardo Gutierrez-Osuna g 1 midterm and 1 final Office: 401 Russ n Homework Tel:775-5120 g 4 problem sets (not graded) [email protected] n Quizzes http://www.cs.wright.edu/~rgutier g Biweekly Office hours: TBA n Laboratories g 5 Labs Teaching Assistant g Grading scheme Mohammed Tabrez Office: 339 Russ [email protected] Weight (%) Office hours: TBA Quizes 20 Laboratory 40 Midterm 20 Final Exam 20 Microprocessor-based System Design 2 Ricardo Gutierrez-Osuna Wright State University Course outline g Module I: Programming (8 lectures) g MC68000 architecture (2) g Assembly language (5) n Instruction and addressing modes (2) n Program control (1) n Subroutines (2) g C language (1) g Module II: Peripherals (9) g Exception processing (1) g Devices (6) n PI/T timer (2) n PI/T parallel port (2) n DUART serial port (1) g Memory and I/O interface (1) g Address decoding (2) Microprocessor-based System Design 3 Ricardo Gutierrez-Osuna Wright State University Brief history of computers GENERATION FEATURES MILESTONES YEAR NOTES Asia Minor, Abacus 3000BC Only replaced by paper and pencil Mech., Blaise Pascal, Pascaline 1642 Decimal addition (8 decimal figs) Early machines Electro- Charles Babbage Differential Engine 1823 Steam powered (3000BC-1945) mech. Herman Hollerith, -

Trends in Electrical Efficiency in Computer Performance
ASSESSING TRENDS IN THE ELECTRICAL EFFICIENCY OF COMPUTATION OVER TIME Jonathan G. Koomey*, Stephen Berard†, Marla Sanchez††, Henry Wong** * Lawrence Berkeley National Laboratory and Stanford University †Microsoft Corporation ††Lawrence Berkeley National Laboratory **Intel Corporation Contact: [email protected], http://www.koomey.com Final report to Microsoft Corporation and Intel Corporation Submitted to IEEE Annals of the History of Computing: August 5, 2009 Released on the web: August 17, 2009 EXECUTIVE SUMMARY Information technology (IT) has captured the popular imagination, in part because of the tangible benefits IT brings, but also because the underlying technological trends proceed at easily measurable, remarkably predictable, and unusually rapid rates. The number of transistors on a chip has doubled more or less every two years for decades, a trend that is popularly (but often imprecisely) encapsulated as “Moore’s law”. This article explores the relationship between the performance of computers and the electricity needed to deliver that performance. As shown in Figure ES-1, computations per kWh grew about as fast as performance for desktop computers starting in 1981, doubling every 1.5 years, a pace of change in computational efficiency comparable to that from 1946 to the present. Computations per kWh grew even more rapidly during the vacuum tube computing era and during the transition from tubes to transistors but more slowly during the era of discrete transistors. As expected, the transition from tubes to transistors shows a large jump in computations per kWh. In 1985, the physicist Richard Feynman identified a factor of one hundred billion (1011) possible theoretical improvement in the electricity used per computation. -

Computer Performance Evaluation and Benchmarking
Computer Performance Evaluation and Benchmarking EE 382M Dr. Lizy Kurian John Evolution of Single-Chip Microprocessors 1970’s 1980’s 1990’s 2010s Transistor Count 10K- 100K-1M 1M-100M 100M- 100K 10 B Clock Frequency 0.2- 2-20MHz 20M- 0.1- 2MHz 1GHz 4GHz Instruction/Cycle < 0.1 0.1-0.9 0.9- 2.0 1-100 MIPS/MFLOPS < 0.2 0.2-20 20-2,000 100- 10,000 Hot Chips 2014 (August 2014) AMD KAVERI HOT CHIPS 2014 AMD KAVERI HOTCHIPS 2014 Hotchips 2014 Hotchips 2014 - NVIDIA Power Density in Microprocessors 10000 Sun’s Surface 1000 Rocket Nozzle ) 2 Nuclear Reactor 100 Core 2 8086 10 Hot Plate 8008 Pentium® Power Density (W/cm 8085 4004 386 Processors 286 486 8080 1 1970 1980 1990 2000 2010 Source: Intel Why Performance Evaluation? • For better Processor Designs • For better Code on Existing Designs • For better Compilers • For better OS and Runtimes Design Analysis Lord Kelvin “To measure is to know.” "If you can not measure it, you can not improve it.“ "I often say that when you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind; it may be the beginning of knowledge, but you have scarcely in your thoughts advanced to the state of Science, whatever the matter may be." [PLA, vol. 1, "Electrical Units of Measurement", 1883-05-03] Designs evolve based on Analysis • Good designs are impossible without good analysis • Workload Analysis • Processor Analysis Design Analysis Performance Evaluation -

CSCI 120 Introduction to Computation Bits... and Pieces (Draft)
CSCI 120 Introduction to Computation Bits... and pieces (draft) Saad Mneimneh Visiting Professor Hunter College of CUNY 1 Yes No Yes No... I am a Bit You may recall from the previous lecture that the use of electro mechanical relays, and in subsequent years, diodes and transistor, made it possible to con- struct more advanced computers, e.g. ENIAC. This is accredited to the fact that these devices could function as on/off switches. On one hand, they create the ability to encode logic into the circuits of the computer. This means that the computer can perform different tasks under different conditions, i.e. the notion of a program. For instance, one could encode the logic if A OR B then C. On the other hand, these devices allow the engineers to worry less about the values that could possibly arise in the system: the switch is either on or off. It cannot be anything in between. Therefore, this means that any errors due to fluctuation in voltage levels are greatly reduced. It would be enough to simply distinguish between high voltage and low voltage. This brings us to the question of Analog versus Digital. In simple terms, a digital system encodes information using a number of de- vices that have discrete states (e.g. on/off switches). An analog system encodes information using a device that have continuous states (e.g. measurement in an electric circuit). To build an intuition for digital versus analog, consider the problem of en- coding a number using buckets of water. One possibility is to use two kinds of buckets, full and empty. -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

Id Question Microprocessor Is the Example of ___Architecture. A
Id Question Microprocessor is the example of _______ architecture. A Princeton B Von Neumann C Rockwell D Harvard Answer A Marks 1 Unit 1 Id Question _______ bus is unidirectional. A Data B Address C Control D None of these Answer B Marks 1 Unit 1 Id Question Use of _______isolates CPU form frequent accesses to main memory. A Local I/O controller B Expansion bus interface C Cache structure D System bus Answer C Marks 1 Unit 1 Id Question _______ buffers data transfer between system bus and I/O controllers on expansion bus. A Local I/O controller B Expansion bus interface C Cache structure D None of these Answer B Marks 1 Unit 1 Id Question ______ Timing involves a clock line. A Synchronous B Asynchronous C Asymmetric D None of these Answer A Marks 1 Unit 1 Id Question -----timing takes advantage of mixture of slow and fast devices, sharing the same bus A Synchronous B asynchronous C Asymmetric D None of these Answer B Marks 1 Unit 1 Id st Question In 1 generation _____language was used to prepare programs. A Machine B Assembly C High level programming D Pseudo code Answer B Marks 1 Unit 1 Id Question The transistor was invented at ________ laboratories. A AT &T B AT &Y C AM &T D AT &M Answer A Marks 1 Unit 1 Id Question ______is used to control various modules in the system A Control Bus B Data Bus C Address Bus D All of these Answer A Marks 1 Unit 1 Id Question The disadvantage of single bus structure over multi bus structure is _____ A Propagation delay B Bottle neck because of bus capacity C Both A and B D Neither A nor B Answer C Marks 1 Unit 1 Id Question _____ provide path for moving data among system modules A Control Bus B Data Bus C Address Bus D All of these Answer B Marks 1 Unit 1 Id Question Microcontroller is the example of _____ architecture. -
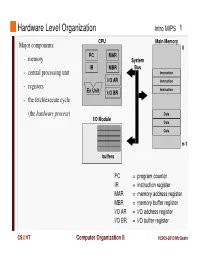
Instruction Register MAR = Memory Address Register MBR = Memory Buffer Register I/O AR = I/O Address Register I/O BR = I/O Buffer Register
Hardware Level Organization Intro MIPS 1 CPU Main Memory Major components: 0 PC MAR - memory System IR MBR Bus - central processing unit Instruction I/O AR Instruction - registers Instruction Ex Unit I/O BR - the fetch/execute cycle (the hardware process ) Data I/O Module Data Data n-1 buffers PC = program counter IR = instruction register MAR = memory address register MBR = memory buffer register I/O AR = I/O address register I/O BR = I/O buffer register CS @VT Computer Organization II ©2005-2013 McQuain Central Processing Unit Intro MIPS 2 Control - decodes instructions and manages CPU’s internal resources Registers - general-purpose registers available to user processes - special-purpose registers directly managed in fetch/execute cycle - other registers may be reserved for use of operating system - very fast and expensive (relative to memory) - hold all operands and results of arithmetic instructions (on RISC systems) - save bits in instruction representation Data path or arithmetic/logic unit (ALU) - operates on data CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 3 Instructions are collections of bits Programs are stored in memory, to be read or written just like data Main Memory CPU 0 memory for data, programs, PC MAR compilers, editors, etc. Instruction IR MBR Instruction I/O AR Instruction Ex Unit I/O BR Data Data Data n-1 Fetch & Execute Cycle Instructions are fetched and put into a special register Bits in the register "control" the subsequent actions Fetch the “next” instruction and continue CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 4 Of course, on most systems several programs will be stored in memory at any given time.