Finding the Beat: Using Respondent-Driven Sampling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
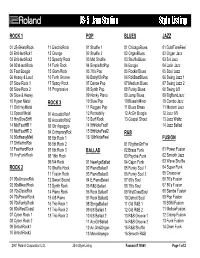
PTSVNWU JS-5 Jam Station Style Listing
PTSVNWU JS-5 Jam Station Style Listing ROCK 1 POP BLUES JAZZ 01 JS-5HardRock 11 ElectricRock 01 Shuffle 1 01 ChicagoBlues 01 DublTimeFeel 02 BritHardRck1 12 Grunge 02 Shuffle 2 02 OrganBlues 02 Organ Jazz 03 BritHardRck2 13 Speedy Rock 03 Mid Shuffle 03 ShuffleBlues 03 5/4 Jazz 04 80'sHardRock 14 Funk Rock 04 Simple8btPop 04 Boogie 04 Latin Jazz 05 Fast Boogie 15 Glam Rock 05 70's Pop 05 Rockin'Blues 05 Soul Jazz 06 Heavy & Loud 16 Funk Groove 06 Early80'sPop 06 RckBeatBlues 06 Swing Jazz 1 07 Slow Rock 1 17 Spacy Rock 07 Dance Pop 07 Medium Blues 07 Swing Jazz 2 08 Slow Rock 2 18 Progressive 08 Synth Pop 08 Funky Blues 08 Swing 6/8 09 Slow & Heavy 09 Honky Piano 09 Jump Blues 09 BigBandJazz 10 Hyper Metal ROCK 3 10 Slow Pop 10 BluesInMinor 10 Combo Jazz 11 Old HvyMetal 11 Reggae Pop 11 Blues Brass 11 Modern Jazz 12 Speed Metal 01 AcousticRck1 12 Rockabilly 12 AcGtr Boogie 12 Jazz 6/8 13 HvySlowShffl 02 AcousticRck2 13 Surf Rock 13 Gospel Shout 13 Jazz Waltz 14 MidFastHR 1 03 Gtr Arpeggio 14 8thNoteFeel1 14 Jazz Ballad 15 MidFastHR 2 04 CntmpraryRck 15 8thNoteFeel2 R&B 16 80sHeavyMetl 05 8bt Rock 1 16 16thNoteFeel FUSION 17 ShffleHrdRck 06 8bt Rock 2 01 RhythmGtrFnk 18 FastHardRock 07 8bt Rock 3 BALLAD 02 Brass Funk 01 Power Fusion 19 HvyFunkRock 08 16bt Rock 03 Psyche-Funk 02 Smooth Jazz 09 5/4 Rock 01 NewAgeBallad 04 Cajun Funk 03 Wave Shuffle ROCK 2 10 Shuffle Rock 02 PianoBallad1 05 Funky Soul 1 04 Super Funk 11 Fusion Rock 03 PianoBallad2 06 Funky Soul 2 05 Crossover 01 90sGrooveRck 12 Sweet Sound 04 E.PianoBalad 07 60's Soul 06 -

“Rapper's Delight”
1 “Rapper’s Delight” From Genre-less to New Genre I was approached in ’77. A gentleman walked up to me and said, “We can put what you’re doing on a record.” I would have to admit that I was blind. I didn’t think that somebody else would want to hear a record re-recorded onto another record with talking on it. I didn’t think it would reach the masses like that. I didn’t see it. I knew of all the crews that had any sort of juice and power, or that was drawing crowds. So here it is two years later and I hear, “To the hip-hop, to the bang to the boogie,” and it’s not Bam, Herc, Breakout, AJ. Who is this?1 DJ Grandmaster Flash I did not think it was conceivable that there would be such thing as a hip-hop record. I could not see it. I’m like, record? Fuck, how you gon’ put hip-hop onto a record? ’Cause it was a whole gig, you know? How you gon’ put three hours on a record? Bam! They made “Rapper’s Delight.” And the ironic twist is not how long that record was, but how short it was. I’m thinking, “Man, they cut that shit down to fifteen minutes?” It was a miracle.2 MC Chuck D [“Rapper’s Delight”] is a disco record with rapping on it. So we could do that. We were trying to make a buck.3 Richard Taninbaum (percussion) As early as May of 1979, Billboard magazine noted the growing popularity of “rapping DJs” performing live for clubgoers at New York City’s black discos.4 But it was not until September of the same year that the trend gar- nered widespread attention, with the release of the Sugarhill Gang’s “Rapper’s Delight,” a fifteen-minute track powered by humorous party rhymes and a relentlessly funky bass line that took the country by storm and introduced a national audience to rap. -

Music 3500: American Music This Final Exam Is Comprehensive —It Covers the Entire Course (Monday December Starting at 5PM In
FINAL EXAM STUDY GUIDE Music 3500: American Music This final exam is comprehensive —it covers the entire course (Monday December starting at 5PM in Knauss Hall 2452) Exam Format: 70 questions (each question is worth 4 points), plus a 40-point "fill-in-the-chart" (described below) (these two things total a maximum of 320 possible points toward your final course grade total). The format of the 70-question computer-graded section of the final exam will be: ...Matching ...Multiple Choice ...True/False (from text readings, class lectures, YouTube video links) General study recommendations: - Do the online quiz assignments for Chapters 1-9 (these must be completed by Monday April 24) ---------- For the Computer-Graded part of the final exam: 1. Know the definitions of Important Terms at the ends of Chapters 2-8 - Chapter 1 (textbook, page 5) -- know "popular music," "roots music," "Classical art- music" - Chapter 2 (textbook, page 19) -- know "old-time music," "hot jazz," "race music" - Chapter 3 (textbook, page 31) -- know "bebop," "big-band," "boogie-woogie" - Chapter 4 (textbook, page 42) -- know "backbeat," "chance music," "cool jazz," "multi- serialism," "rhythm & blues," "soul" - Chapter 5 (textbook, page 52) -- know "soundtrack," "free jazz" - Chapter 6 (textbook, pages 58-59) -- know "fusion," minimalism," - Chapter 7 (textbook, pages 69-70) -- know "techno," "smooth jazz," "hip-hop" - Chapter 8 (textbook, page 81) -- know "sound art" 2. Know which decade the following music technologies came from: (Review the chronological order of -

The DIY Careers of Techno and Drum 'N' Bass Djs in Vienna
Cross-Dressing to Backbeats: The Status of the Electroclash Producer and the Politics of Electronic Music Feature Article David Madden Concordia University (Canada) Abstract Addressing the international emergence of electroclash at the turn of the millenium, this article investigates the distinct character of the genre and its related production practices, both in and out of the studio. Electroclash combines the extended pulsing sections of techno, house and other dance musics with the trashier energy of rock and new wave. The genre signals an attempt to reinvigorate dance music with a sense of sexuality, personality and irony. Electroclash also emphasizes, rather than hides, the European, trashy elements of electronic dance music. The coming together of rock and electro is examined vis-à-vis the ongoing changing sociality of music production/ distribution and the changing role of the producer. Numerous women, whether as solo producers, or in the context of collaborative groups, significantly contributed to shaping the aesthetics and production practices of electroclash, an anomaly in the history of popular music and electronic music, where the role of the producer has typically been associated with men. These changes are discussed in relation to the way electroclash producers Peaches, Le Tigre, Chicks on Speed, and Miss Kittin and the Hacker often used a hybrid approach to production that involves the integration of new(er) technologies, such as laptops containing various audio production softwares with older, inexpensive keyboards, microphones, samplers and drum machines to achieve the ironic backbeat laden hybrid electro-rock sound. Keywords: electroclash; music producers; studio production; gender; electro; electronic dance music Dancecult: Journal of Electronic Dance Music Culture 4(2): 27–47 ISSN 1947-5403 ©2011 Dancecult http://dj.dancecult.net DOI: 10.12801/1947-5403.2012.04.02.02 28 Dancecult 4(2) David Madden is a PhD Candidate (A.B.D.) in Communications at Concordia University (Montreal, QC). -

MUSIC, Dvds, PROGRAMS, PE CLASSES & SOUND SYSTEMS
MUSIC, DVDs, PROGRAMS, PE CLASSES & SOUND SYSTEMS ® and “Hi! I’m Christy Lane, creator of Dare to Dance owner of Christy Lane Enterprises. How can we help you? As you browse through this catalog, you will notice we expanded our line of products and services. When our company was established 20 years ago our philosophy was simple. To educate children that dance can benefit them physically, mentally, That's me on my first video shoot. socially, and emotionally. We did this by producing quality educational products for the physical Catalog Listings: education teachers and dance studio instructors. LINE DANCING Our customer base has expanded tremendously over PARTY DANCING the years and so has the popularity of dance. Now, DECADE DANCING moms, dads, single adults, seniors, and kids who HIP HOP have never danced before are dancing! So join the PARTNER/BALLROOM fun!” LATIN DANCING SQUARE DANCING AMERICA SPORTS & NOVELTY MULTICULTURAL FOLK Christy Lane is one of America’s most well-known and respected dance instructors. Her DANCING extensive dance training has led her to become an acknowledged dance educator, producer, choreographer, and writer. Her work has been recognized by U.S. News and World Report, AFRICAN-CARIBBEAN American Fitness, USA Today and Shape Magazine. Her credits include Disney, Pepsi and DANCING Capezio to name a few. A former private dance studio owner, she tours nationally and her PHYSICAL FITNESS conventions and workshops have delighted thousands of all ages. MUSIC EDITING JAZZ DANCING TAP DANCING DANCE CONVENTIONS HOLIDAY DANCE SHIRTS DANCE FLOORS SOUND SYSTEMS & MICROPHONES TEACHER WORKSHOPS “Christy Lane has the magic to motivate the non-dancer and insight to move DANCE SCHOOL ASSEMBLIES accomplished dancers to the next level.”-Bud Turner, P.E. -

Is Rock Music in Decline? a Business Perspective
Jose Dailos Cabrera Laasanen Is Rock Music in Decline? A Business Perspective Helsinki Metropolia University of Applied Sciences Bachelor of Business Administration International Business and Logistics 1405484 22nd March 2018 Abstract Author(s) Jose Dailos Cabrera Laasanen Title Is Rock Music in Decline? A Business Perspective Number of Pages 45 Date 22.03.2018 Degree Bachelor of Business Administration Degree Programme International Business and Logistics Instructor(s) Michael Keaney, Senior Lecturer Rock music has great importance in the recent history of human kind, and it is interesting to understand the reasons of its de- cline, if it actually exists. Its legacy will never disappear, and it will always be a great influence for new artists but is important to find out the reasons why it has become what it is in now, and what is the expected future for the genre. This project is going to be focused on the analysis of some im- portant business aspects related with rock music and its de- cline, if exists. The collapse of Gibson guitars will be analyzed, because if rock music is in decline, then the collapse of Gibson is a good evidence of this. Also, the performance of independ- ent and major record labels through history will be analyzed to understand better the health state of the genre. The same with music festivals that today seem to be increasing their popularity at the expense of smaller types of live-music events. Keywords Rock, music, legacy, influence, artists, reasons, expected, fu- ture, genre, analysis, business, collapse, -

Glam Rock by Barney Hoskyns 1
Glam Rock By Barney Hoskyns There's a new sensation A fabulous creation, A danceable solution To teenage revolution Roxy Music, 1973 1: All the Young Dudes: Dawn of the Teenage Rampage Glamour – a word first used in the 18th Century as a Scottish term connoting "magic" or "enchantment" – has always been a part of pop music. With his mascara and gold suits, Elvis Presley was pure glam. So was Little Richard, with his pencil moustache and towering pompadour hairstyle. The Rolling Stones of the mid-to- late Sixties, swathed in scarves and furs, were unquestionably glam; the group even dressed in drag to push their 1966 single "Have You Seen Your Mother, Baby, Standing in the Shadow?" But it wasn't until 1971 that "glam" as a term became the buzzword for a new teenage subculture that was reacting to the messianic, we-can-change-the-world rhetoric of late Sixties rock. When T. Rex's Marc Bolan sprinkled glitter under his eyes for a TV taping of the group’s "Hot Love," it signaled a revolt into provocative style, an implicit rejection of the music to which stoned older siblings had swayed during the previous decade. "My brother’s back at home with his Beatles and his Stones," Mott the Hoople's Ian Hunter drawled on the anthemic David Bowie song "All the Young Dudes," "we never got it off on that revolution stuff..." As such, glam was a manifestation of pop's cyclical nature, its hedonism and surface show-business fizz offering a pointed contrast to the sometimes po-faced earnestness of the Woodstock era. -

The History of Rock Music: 1976-1989
The History of Rock Music: 1976-1989 New Wave, Punk-rock, Hardcore History of Rock Music | 1955-66 | 1967-69 | 1970-75 | 1976-89 | The early 1990s | The late 1990s | The 2000s | Alpha index Musicians of 1955-66 | 1967-69 | 1970-76 | 1977-89 | 1990s in the US | 1990s outside the US | 2000s Back to the main Music page (Copyright © 2009 Piero Scaruffi) Punk-rock (These are excerpts from my book "A History of Rock and Dance Music") London's burning TM, ®, Copyright © 2005 Piero Scaruffi All rights reserved. The effervescence of New York's underground scene was contagious and spread to England with a 1976 tour of the Ramones that was artfully manipulated to start a fad (after the "100 Club Festival" of september 1976 that turned British punk-rock into a national phenomenon). In the USA the punk subculture was a combination of subterranean record industry and of teenage angst. In Britain it became a combination of fashion and of unemployment. Music in London had been a component of fashion since the times of the Swinging London (read: Rolling Stones). Punk-rock was first and foremost a fad that took over the Kingdom by storm. However, the social component was even stronger than in the USA: it was not only a generic malaise, it was a specific catastrophe. The iron rule of prime minister Margaret Thatcher had salvaged Britain from sliding into the Third World, but had caused devastation in the social fabric of the industrial cities, where unemployment and poverty reached unprecedented levels and racial tensions were brooding. -

CP3 Responsible Party Name : Kawai America Corporation Nameplate Address : 2055 East University Drive Rancho Dominguez, CA 90220 Telephone : 310-631-1771
Owner’s Manual Owner’s Using USB Virtual Playing the Piano Listening to Part Names Appendices Settings Menu Music Menu Using a Style Recording a Song Memory Technician (Basic Controls) the Piano & Functions 10 9 8 7 6 5 4 3 2 1 All descriptions and specifications in this manual are subject to change without notice. Page 3 Thank you for purchasing this KAWAI Concert Performer (CP) Series Ensemble Digital Piano. The CP Series piano has been designed to provide you with the ultimate musical experience, no matter your skill level. Featuring superbly realistic instrument tones and the most finely crafted keyboard in its class, the CP is a unique musical instrument resulting from the combination of KAWAI’s eighty-five-plus years experience in making acoustic pianos, along with cutting-edge digital music technologies. With over 1000 different instrument and drum sounds at your disposal, you will have the flexibility to perform any kind of music ranging from traditional to contemporary. The Auto-Accompaniment Styles provide the enjoyment of playing rich, fully orchestrated music in hundreds of musical genres. Thanks to the Song Stylist feature, you will never have to worry about finding the best sounds and style to perform a particular song. The Concert Performer incorporates many professional features, such as a 16-track Recorder, Microphone Input, USB to Device functionality and MP3 recording/playback. For the non-player, KAWAI’s unique Concert Magic feature creates the thrill of being a performing musician simply by tapping any key on the keyboard. The Concert Performer offers tremendous opportunities for anyone who is interested in learning, playing, and listening to music. -

VA Dance Action the Final Eurodance Remixes Vol 18 2000
VA - Dance Action - The Final Eurodance Remixes Vol. 1-8 (2000) 1 / 4 VA - Dance Action - The Final Eurodance Remixes Vol. 1-8 (2000) 2 / 4 3 / 4 com, DJ Remix Album Video, DJ Album Songs Mp3 Free ... Type Title Size; Audio DANCE - VA - May Dance Club Vol. ... Sheher Ki Ladki (Remix) ABK Production) [Indian Dj Remix] Author | Your Source for All TY Boogie and DJ Action Pac ... 2 by NA DJ, released 03 May 2019 1. 8 [ 松田聖子 PUMA .... Various - Valencia Mix (2 CD, Compilation) Discoshop Productions (DS-001-CD) Spain ... Out-Da-Way - Movin' Up (Maxi-CD) ZYX Music (2000) Germany - flac ... Mr. Manila - Action (12'') Make You Dance (MYD_95-02) 1995 Italy - wav ... VA - Cantaditas De Siempre Vol. ... Bandido - End Of The Road (Original Mix) 5:38. Artist: Various Artists Album: VA - Muzyczna Petarda Vol.78 (2020) [Norman] Genre: Retro/Dance/Club Mix ... Europe - The Final Countdown (Dj KaktuZ Remix) [03:59] 9. FLGTT ... VA Year: 2020. Genre: Eurodance, Euro-House, Electronic, Dance ... 1-8 You're Much Better Off Loving Me 3:20 ... Year Of Release: 2000-2015. VA - Dance Action - The Final Eurodance Remixes Vol. 1-8 (2000) Artist: VA Title: Dance Action - The Final Eurodance Remixes. Various Artists - Dance Action - The Final Eurodance Remixes Vol. 1-8 скачать торрент ... Год выпуска диска: 2000 ... Various Artists - Planet Hits Vol. ... VA - Лучшая танцевальная музыка,Выпуск:(2007апрель, май, июнь, июль) скачать .... (Eurodance ) VA - Old Dance Remix Vol. 1 - 60 (2006 - 2013), MP3, 128 - 320kbps скачать торрент Международный торрент-трекер .... Pop / Eurodance / Disco / Synthpop / Сборники (общие - 50х50) » Скачать торрент VA - Old Dance Remix Vol.1-57 + Bonus. -

THE BOOGIE! a NIGHTCLUB THAT DEFIED TRADITIONAL PROBLEM SOLVING EFFORTS Or When Jack Met SARA
THE BOOGIE! A NIGHTCLUB THAT DEFIED TRADITIONAL PROBLEM SOLVING EFFORTS or when Jack met SARA Anaheim Police Department South District Community Policing Team Tourist Oriented Policing Team District Commander, Lieutenant David Vangsness Summary The Boogie, a nightclub that operated in Anaheim for over 25 years, maintained a reputation as one of the most popular clubs in Southern California. It operated under various banners including: The Crescendo, The Cowboy, The Bandstand, The Cowboy- Boogie and finally The Boogie. Each change in name represented a change in both the music format and the clientele who patronized the club. What remained constant were the challenges the club created for the community. As is often the case, the police department would be the driving force in addressing these challenges. The Boogie brought all of the common problems expected of a large nightclub. As with any concentration of alcohol, high-energy music and young adults, the club’s problems included: fights, intoxicated patrons and parking and traffic congestion. Beyond these “traditional” problems, in later years The Boogie severely impacted surrounding businesses, forcing them to hire security, close their doors during peak hours, and endure ongoing customer complaints. As the club evolved into a Hip-Hop and Rap format, stabbings, shootings and firearms seizures became routine. Two homicides were committed by patrons leaving the club in its last year of operation, 2006. The Anaheim Police Department became stuck in a recurring loop while trying to solve the challenges in and around The Boogie. Scanning revealed a problem; analysis suggested a fix; responses were usually effective; but assessment often turned into a new round of response and assessment, as a problem recurred, or a new problem arose. -

Boo-Hooray Catalog #8: Music Boo-Hooray Catalog #8
Boo-Hooray Catalog #8: Music Boo-Hooray Catalog #8 Music Boo-Hooray is proud to present our eighth antiquarian catalog, dedicated to music artifacts and ephemera. Included in the catalog is unique artwork by Tomata Du Plenty of The Screamers, several incredible items documenting music fan culture including handmade sleeves for jazz 45s, and rare paste-ups from reggae’s entrance into North America. Readers will also find the handmade press kit for the early Björk band, KUKL, several incredible hip-hop posters, and much more. For over a decade, we have been committed to the organization, stabilization, and preservation of cultural narratives through archival placement. Today, we continue and expand our mission through the sale of individual items and smaller collections. We encourage visitors to browse our extensive inventory of rare books, ephemera, archives and collections and look forward to inviting you back to our gallery in Manhattan’s Chinatown. Catalog prepared by Evan Neuhausen, Archivist & Rare Book Cataloger and Daylon Orr, Executive Director & Rare Book Specialist; with Beth Rudig, Director of Archives. Photography by Ben Papaleo, Evan, and Daylon. Layout by Evan. Please direct all inquiries to Daylon ([email protected]). Terms: Usual. Not onerous. All items subject to prior sale. Payment may be made via check, credit card, wire transfer or PayPal. Institutions may be billed accordingly. Shipping is additional and will be billed at cost. Returns will be accepted for any reason within a week of receipt. Please provide advance notice of the return. Table of Contents 31. [Patti Smith] Hey Joe (Version) b/w Piss Factory ..................