Reinforcement Learning and Video Games Arxiv:1909.04751V1 [Cs.LG]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Location-Based Mobile Games
LOCATION-BASED MOBILE GAMES Creating a location-based game with Unity game engine LAB-UNIVERSITY OF APPLIED SCIENCES Engineer (AMK) Information and Communications Technology, Media technology Spring 2020 Samuli Korhola Tiivistelmä Tekijä(t) Julkaisun laji Valmistumisaika Korhola, Samuli Opinnäytetyö, AMK Kevät 2020 Sivumäärä 28 Työn nimi Sijaintipohjaisuus mobiilipeleissä Sijaintipohjaisen pelin kehitys Unity pelimoottorissa Tutkinto Tieto- ja viestintätekniikan insinööri. Tiivistelmä Tämän opinnäytetyön aiheena oli sijaintipohjaiset mobiilipelit. Sijaintipohjaiset mobiili- pelit ovat pelien tapa yhdistää oikea maailma virtuaalisen maailman kanssa ja täten ne luovat yhdessä aivan uuden pelikokemuksen. Tämä tutkimus syventyi teknologiaan ja työkaluihin, joilla kehitetään sijaintipohjaisia pelejä. Näihin sisältyy esimerkiksi GPS ja Bluetooth. Samalla työssä myös tutustuttiin yleisesti sijaintipohjaisten pelien ominaisuuksiin. Melkein kaikki tekniset ratkaisut, jotka oli esitetty opinnäytetyössä, olivat Moomin Move peliprojektin teknisiä ratkaisuja. Opinnäytetyön tuloksena tuli lisää mahdolli- suuksia kehittää Moomin Move pelin sijaintipohjaisia ominaisuuksia, kuten tuomalla kamerapohjaisia sijaintitekniikoita. Asiasanat Unity, sijaintipohjainen, mobiilipelit, GPS, Bluetooth Abstract Author(s) Type of publication Published Korhola, Samuli Bachelor’s thesis Spring 2020 Number of pages 28 Title of publication Location-based mobile games Creating a location-based game with the Unity game engine Name of Degree Bachelor of Information and Communications -

The Discovery of Chinese Logic Modern Chinese Philosophy
The Discovery of Chinese Logic Modern Chinese Philosophy Edited by John Makeham, Australian National University VOLUME 1 The titles published in this series are listed at brill.nl/mcp. The Discovery of Chinese Logic By Joachim Kurtz LEIDEN • BOSTON 2011 This book is printed on acid-free paper. Library of Congress Cataloging-in-Publication Data Kurtz, Joachim. The discovery of Chinese logic / by Joachim Kurtz. p. cm. — (Modern Chinese philosophy, ISSN 1875-9386 ; v. 1) Includes bibliographical references and index. ISBN 978-90-04-17338-5 (hardback : alk. paper) 1. Logic—China—History. I. Title. II. Series. BC39.5.C47K87 2011 160.951—dc23 2011018902 ISSN 1875-9386 ISBN 978 90 04 17338 5 Copyright 2011 by Koninklijke Brill NV, Leiden, The Netherlands. Koninklijke Brill NV incorporates the imprints Brill, Global Oriental, Hotei Publishing, IDC Publishers, Martinus Nijhoff Publishers and VSP. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Authorization to photocopy items for internal or personal use is granted by Koninklijke Brill NV provided that the appropriate fees are paid directly to The Copyright Clearance Center, 222 Rosewood Drive, Suite 910, Danvers, MA 01923, USA. Fees are subject to change. CONTENTS List of Illustrations ...................................................................... vii List of Tables ............................................................................. -

Iaj 10-3 (2019)
Vol. 10 No. 3 2019 Arthur D. Simons Center for Interagency Cooperation, Fort Leavenworth, Kansas FEATURES | 1 About The Simons Center The Arthur D. Simons Center for Interagency Cooperation is a major program of the Command and General Staff College Foundation, Inc. The Simons Center is committed to the development of military leaders with interagency operational skills and an interagency body of knowledge that facilitates broader and more effective cooperation and policy implementation. About the CGSC Foundation The Command and General Staff College Foundation, Inc., was established on December 28, 2005 as a tax-exempt, non-profit educational foundation that provides resources and support to the U.S. Army Command and General Staff College in the development of tomorrow’s military leaders. The CGSC Foundation helps to advance the profession of military art and science by promoting the welfare and enhancing the prestigious educational programs of the CGSC. The CGSC Foundation supports the College’s many areas of focus by providing financial and research support for major programs such as the Simons Center, symposia, conferences, and lectures, as well as funding and organizing community outreach activities that help connect the American public to their Army. All Simons Center works are published by the “CGSC Foundation Press.” The CGSC Foundation is an equal opportunity provider. InterAgency Journal FEATURES Vol. 10, No. 3 (2019) 4 In the beginning... Special Report by Robert Ulin Arthur D. Simons Center for Interagency Cooperation 7 Military Neuro-Interventions: The Lewis and Clark Center Solving the Right Problems for Ethical Outcomes 100 Stimson Ave., Suite 1149 Shannon E. -

Machine Learning Explained
Learning Deep or not Deep… De MENACE à AlphaGo JM Alliot Le Deep Learning en Version Simple Qu’est-ce que c’est ? Croisement entre deux univers • L’apprentissage • Par renforcement: on est capable d’évaluer le résultat et de l’utiliser pour améliorer le programme • Supervisé: une base de données d’apprentissage est disponible cas par cas • Non supervisé: algorithmes de classification (k- means,…),… • Les neurosciences DLVS L’apprentissage par renforcement • Turing: • « Instead of trying to produce a program to simulate the adult mind, why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain. Presumably the child brain is something like a notebook as one buys it from the stationers. Rather little mechanism, and lots of blank sheets.” • “The use of punishments and rewards can at best be a part of the teaching process. Roughly speaking, if the teacher has no other means of communicating to the pupil, the amount of information which can reach him does not exceed the total number of rewards and punishments applied. By the time a child has learnt to repeat “Casabianca” he would probably feel very sore indeed, if the text could only be discovered by a “Twenty Questions” technique, every “NO” taking the form of a blow.” DLVS L’apprentissage par renforcement • Arthur Samuel (1959): « Some Studies in Machine Learning Using the Game of Checkers » • Memoization • Ajustement automatique de paramètres par régression. • Donald Michie (1962): MENACE -

Hearing on China's Military Reforms and Modernization: Implications for the United States Hearing Before the U.S.-China Economic
HEARING ON CHINA'S MILITARY REFORMS AND MODERNIZATION: IMPLICATIONS FOR THE UNITED STATES HEARING BEFORE THE U.S.-CHINA ECONOMIC AND SECURITY REVIEW COMMISSION ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION THURSDAY, FEBRUARY 15, 2018 Printed for use of the United States-China Economic and Security Review Commission Available via the World Wide Web: www.uscc.gov UNITED STATES-CHINA ECONOMIC AND SECURITY REVIEW COMMISSION WASHINGTON: 2018 U.S.-CHINA ECONOMIC AND SECURITY REVIEW COMMISSION ROBIN CLEVELAND, CHAIRMAN CAROLYN BARTHOLOMEW, VICE CHAIRMAN Commissioners: HON. CARTE P. GOODWIN HON. JAMES TALENT DR. GLENN HUBBARD DR. KATHERINE C. TOBIN HON. DENNIS C. SHEA MICHAEL R. WESSEL HON. JONATHAN N. STIVERS DR. LARRY M. WORTZEL The Commission was created on October 30, 2000 by the Floyd D. Spence National Defense Authorization Act for 2001 § 1238, Public Law No. 106-398, 114 STAT. 1654A-334 (2000) (codified at 22 U.S.C. § 7002 (2001), as amended by the Treasury and General Government Appropriations Act for 2002 § 645 (regarding employment status of staff) & § 648 (regarding changing annual report due date from March to June), Public Law No. 107-67, 115 STAT. 514 (Nov. 12, 2001); as amended by Division P of the “Consolidated Appropriations Resolution, 2003,” Pub L. No. 108-7 (Feb. 20, 2003) (regarding Commission name change, terms of Commissioners, and responsibilities of the Commission); as amended by Public Law No. 109- 108 (H.R. 2862) (Nov. 22, 2005) (regarding responsibilities of Commission and applicability of FACA); as amended by Division J of the “Consolidated Appropriations Act, 2008,” Public Law Nol. 110-161 (December 26, 2007) (regarding responsibilities of the Commission, and changing the Annual Report due date from June to December); as amended by the Carl Levin and Howard P. -

Autonomous Aircraft Sequencing and Separation with Hierarchical Deep Reinforcement Learning
ICRAT 2018 Autonomous Aircraft Sequencing and Separation with Hierarchical Deep Reinforcement Learning Marc Brittain Peng Wei Aerospace Engineering Department Aerospace Engineering Department Iowa State University Iowa State University Ames, IA, USA Ames, IA, USA [email protected] [email protected] Abstract—With the increasing air traffic density and complexity autonomy or human operator decisions, and cope with in traditional controlled airspace, and the envisioned large envisioned high-density and on-demand air traffic by providing volume vertical takeoff and landing (VTOL) operations in low- automated sequencing and separation advisories. altitude airspace for personal air mobility or on-demand air taxi, an autonomous air traffic control system (a fully automated The inspiration of this paper is twofold. First, the authors airspace) is needed as the ultimate solution to handle dense, were amazed by the fact that an artificial intelligence agent complex and dynamic air traffic in the future. In this work, we called AlphaGo built by DeepMind defeated the world design and build an artificial intelligence (AI) agent to perform champion Ke Jie in three matches of Go in May 2017 [11]. air traffic control sequencing and separation. The approach is to This notable advance in AI field demonstrated the theoretical formulate this problem as a reinforcement learning model and foundation and computational capability to potentially augment solve it using the hierarchical deep reinforcement learning and facilitate human tasks with intelligent agents and AI algorithms. For demonstration, the NASA Sector 33 app has technologies. Therefore, the authors want to apply the most been used as our simulator and learning environment for the recent AI frameworks and algorithms to re-visit the agent. -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

NTT Technical Review, Vol. 15, No. 11, Nov. 2017
NTT Technical Review November 2017 Vol. 15 No. 11 Front-line Researchers Naonori Ueda, NTT Fellow, Head of Ueda Research Laboratory and Director of Machine Learning and Data Science Center, NTT Communication Science Laboratories Feature Articles: Communication Science that Enables corevo®—Artificial Intelligence that Gets Closer to People Basic Research in the Era of Artificial Intelligence, Internet of Things, and Big Data—New Research Design through the Convergence of Science and Engineering Generative Personal Assistance with Audio and Visual Examples Efficient Algorithm for Enumerating All Solutions to an Exact Cover Problem Memory-efficient Word Embedding Vectors Synthesizing Ghost-free Stereoscopic Images for Viewers without 3D Glasses Personalizing Your Speech Interface with Context Adaptive Deep Neural Networks Regular Articles Optimization of Harvest Time in Microalgae Cultivation Using an Image Processing Algorithm for Color Restoration Global Standardization Activities Report on First Meeting of ITU-T TSAG (Telecommunication Standardization Advisory Group) for the Study Period 2017 to 2020 Information Event Report: NTT Communication Science Laboratories Open House 2017 Short Reports Arkadin Brings Businesses into the Future with New Cloud Unified Communications Services and Digital Operations Strategies World’s Largest Transmission Capacity with Standard Diameter Multi-core Optical Fiber—Accelerated Multi-core Fiber Application Using Current Standard Technology External Awards/Papers Published in Technical Journals -
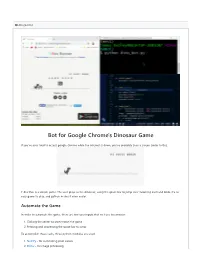
Bot for Google Chrome's Dinosaur Game
dino_bot.md Bot for Google Chrome's Dinosaur Game If you've ever tried to access google chrome while the internet is down, you've probably seen a screen simlar to this: T-Rex Run is a simple game. The user plays as the dinosaur, using the space bar to jump over incoming cacti and birds. It's an easy game to play, and python makes it even easier. Automate the Game In order to automate the game, there are two user inputs that we have to consider: 1. Clicking the center to start/restart the game 2. Pressing and unpressing the space bar to jump To accomplish these tasks, three python modules are used: 1. NumPy - for summating pixel values 2. Pillow - for image processing 3. PyAutoGUI - for controlling mouse and keyboard input Conceptual Overview The goal is to make the program able to analyze the area in front of the dinosaur and jump when something is in his way. The following image shows the two places that the program is using to do this: The blue rectangle is a reference to the area of the screen in front of the dinosaur that the bot is constantly running calculations on. As the game runs, the area in front of the dinosaur changes as obstacles approach. With Pillow, we're able to calculate the sum of the different pixel values specifically in the blue area in front of the dinosaur. When nothing is in front of the dinosaur, the value of the sum of these pixels represented by the blue rectangle is 1,447. -

Foundation Stage Medium Term Planning Summer Term 2018 Title: All Creatures Great and Small Memorable Experience: Dinosaur Egg and Bones to Be Found
Foundation Stage Medium Term Planning Summer Term 2018 Title: All Creatures Great and Small Memorable experience: dinosaur egg and bones to be found. Please note that EYFS Medium Term Planning is updated weekly to accommodate for children’s interests. Week C/L & Literacy Mathematics ,Topic Session 1 Topic Session 2 Topic session 3 Topic focus task Music/ICT session Week 1 Text: How to look after your Shape space and measure: Where have dinosaurs been Why are they extinct? How are dinosaurs similar and EAD: dinosaur craft Musci/PSHE/RE see scheme of 16/04/18 dinosaur by Jason Cockcroft weight and capacity found? Discuss what the word extinct different to animals we know Make dinosaur skeletons work. M- find a dinosaur egg and M- how much does the Look at a palaeontology dig means. Why did dinosaurs today? using pipe cleaners or pasta dinosaur bones. Who might dinosaur egg weigh compare online and how this is how we become extinct discuss Share pictures of alligators shapes. ICT: Use google Earth to they belong to? Read the with other objects and order. know that dinosaurs existed. theories. and crocodiles what features locate the places around the story. T- use balance scale to Look at a map of the world What other animals do we do these have that link them world that dinosaurs have T- Re-read the story and measure the weight of the and mark the places around know that are extinct? to dinosaurs? Look at a range been found compare to our discuss the things we need to egg. -

(CMPUT) 455 Search, Knowledge, and Simulations
Computing Science (CMPUT) 455 Search, Knowledge, and Simulations James Wright Department of Computing Science University of Alberta [email protected] Winter 2021 1 455 Today - Lecture 22 • AlphaGo - overview and early versions • Coursework • Work on Assignment 4 • Reading: AlphaGo Zero paper 2 AlphaGo Introduction • High-level overview • History of DeepMind and AlphaGo • AlphaGo components and versions • Performance measurements • Games against humans • Impact, limitations, other applications, future 3 About DeepMind • Founded 2010 as a startup company • Bought by Google in 2014 • Based in London, UK, Edmonton (from 2017), Montreal, Paris • Expertise in Reinforcement Learning, deep learning and search 4 DeepMind and AlphaGo • A DeepMind team developed AlphaGo 2014-17 • Result: Massive advance in playing strength of Go programs • Before AlphaGo: programs about 3 levels below best humans • AlphaGo/Alpha Zero: far surpassed human skill in Go • Now: AlphaGo is retired • Now: Many other super-strong programs, including open source Image source: • https://www.nature.com All are based on AlphaGo, Alpha Zero ideas 5 DeepMind and UAlberta • UAlberta has deep connections • Faculty who work part-time or on leave at DeepMind • Rich Sutton, Michael Bowling, Patrick Pilarski, Csaba Szepesvari (all part time) • Many of our former students and postdocs work at DeepMind • David Silver - UofA PhD, designer of AlphaGo, lead of the DeepMind RL and AlphaGo teams • Aja Huang - UofA postdoc, main AlphaGo programmer • Many from the computer Poker group -

Computer Wins Second GAME Against Chinese GO Champion
TECHNOLOGY SATURDAY, MAY 27, 2017 Samsung investigating Galaxy S8 ‘iris hack’ SEOUL: Samsung Electronics is investigating claims by a German hacking group that it fooled the iris recognition system of the new flagship Galaxy S8 device, the firm said yesterday. The launch of the Galaxy S8 was a key step for the world’s largest smartphone maker as it sought to move on from last year’s humiliating withdrawal of the fire-prone Galaxy Note 7s, which hammered the firm’s once-stellar reputation. But a video posted by the Chaos Computer Club (CCC), a German hacking group founded in 1981, shows the Galaxy S8 being unlocked using a printed photo of the owner’s eye covered with a contact lens to replicate the curvature of a real eyeball. “A high- resolution picture from the internet is sufficient to cap- ture an iris,” CCC spokesman Dirk Engling said, adding: “Ironically, we got the best results with laser printers made by Samsung.” A Samsung spokeswoman said it was aware of the report and was investigating. The iris scanning technolo- gy was “developed through rigorous testing”, the firm said in a statement as it sought to reassure customers. “If there is a potential vulnerability or the advent of a new method that challenges our efforts to ensure security at WUZHEN: Chinese Go player Ke Jie, left, looks at the board as a person makes a move on behalf of Google’s artificial any time, we will respond as quickly as possible to resolve intelligence program, AlphaGo, during a game of Go at the Future of Go Summit in Wuzhen in eastern China’s Zhejiang the issue.” Samsung’s hopes of competing against archri- Province.