Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Residual Networks for Computer Go
IEEE TCIAIG 1 Residual Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, 75016 PARIS, FRANCE Deep Learning for the game of Go recently had a tremendous success with the victory of AlphaGo against Lee Sedol in March 2016. We propose to use residual networks so as to improve the training of a policy network for computer Go. Training is faster than with usual convolutional networks and residual networks achieve high accuracy on our test set and a 4 dan level. Index Terms—Deep Learning, Computer Go, Residual Networks. I. INTRODUCTION Input EEP Learning for the game of Go with convolutional D neural networks has been addressed by Clark and Storkey [1]. It has been further improved by using larger networks [2]. Learning multiple moves in a row instead of only one Convolution move has also been shown to improve the playing strength of Go playing programs that choose moves according to a deep neural network [3]. Then came AlphaGo [4] that combines ReLU Monte Carlo Tree Search (MCTS) with a policy and a value network. Deep neural networks are good at recognizing shapes in the game of Go. However they have weaknesses at tactical search Output such as ladders and life and death. The way it is handled in AlphaGo is to give as input to the network the results of Fig. 1. The usual layer for computer Go. ladders. Reading ladders is not enough to understand more complex problems that require search. So AlphaGo combines deep networks with MCTS [5]. It learns a value network the last section concludes. -
![Arxiv:1701.07274V3 [Cs.LG] 15 Jul 2017](https://docslib.b-cdn.net/cover/8220/arxiv-1701-07274v3-cs-lg-15-jul-2017-78220.webp)
Arxiv:1701.07274V3 [Cs.LG] 15 Jul 2017
DEEP REINFORCEMENT LEARNING:AN OVERVIEW Yuxi Li ([email protected]) ABSTRACT We give an overview of recent exciting achievements of deep reinforcement learn- ing (RL). We discuss six core elements, six important mechanisms, and twelve applications. We start with background of machine learning, deep learning and reinforcement learning. Next we discuss core RL elements, including value func- tion, in particular, Deep Q-Network (DQN), policy, reward, model, planning, and exploration. After that, we discuss important mechanisms for RL, including atten- tion and memory, in particular, differentiable neural computer (DNC), unsuper- vised learning, transfer learning, semi-supervised learning, hierarchical RL, and learning to learn. Then we discuss various applications of RL, including games, in particular, AlphaGo, robotics, natural language processing, including dialogue systems (a.k.a. chatbots), machine translation, and text generation, computer vi- sion, neural architecture design, business management, finance, healthcare, Indus- try 4.0, smart grid, intelligent transportation systems, and computer systems. We mention topics not reviewed yet. After listing a collection of RL resources, we present a brief summary, and close with discussions. arXiv:1701.07274v3 [cs.LG] 15 Jul 2017 1 CONTENTS 1 Introduction5 2 Background6 2.1 Machine Learning . .7 2.2 Deep Learning . .8 2.3 Reinforcement Learning . .9 2.3.1 Problem Setup . .9 2.3.2 Value Function . .9 2.3.3 Temporal Difference Learning . .9 2.3.4 Multi-step Bootstrapping . 10 2.3.5 Function Approximation . 11 2.3.6 Policy Optimization . 12 2.3.7 Deep Reinforcement Learning . 12 2.3.8 RL Parlance . 13 2.3.9 Brief Summary . -

ELF: an Extensive, Lightweight and Flexible Research Platform for Real-Time Strategy Games
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games Yuandong Tian1 Qucheng Gong1 Wenling Shang2 Yuxin Wu1 C. Lawrence Zitnick1 1Facebook AI Research 2Oculus 1fyuandong, qucheng, yuxinwu, [email protected] [email protected] Abstract In this paper, we propose ELF, an Extensive, Lightweight and Flexible platform for fundamental reinforcement learning research. Using ELF, we implement a highly customizable real-time strategy (RTS) engine with three game environ- ments (Mini-RTS, Capture the Flag and Tower Defense). Mini-RTS, as a minia- ture version of StarCraft, captures key game dynamics and runs at 40K frame- per-second (FPS) per core on a laptop. When coupled with modern reinforcement learning methods, the system can train a full-game bot against built-in AIs end- to-end in one day with 6 CPUs and 1 GPU. In addition, our platform is flexible in terms of environment-agent communication topologies, choices of RL methods, changes in game parameters, and can host existing C/C++-based game environ- ments like ALE [4]. Using ELF, we thoroughly explore training parameters and show that a network with Leaky ReLU [17] and Batch Normalization [11] cou- pled with long-horizon training and progressive curriculum beats the rule-based built-in AI more than 70% of the time in the full game of Mini-RTS. Strong per- formance is also achieved on the other two games. In game replays, we show our agents learn interesting strategies. ELF, along with its RL platform, is open sourced at https://github.com/facebookresearch/ELF. 1 Introduction Game environments are commonly used for research in Reinforcement Learning (RL), i.e. -

Iaj 10-3 (2019)
Vol. 10 No. 3 2019 Arthur D. Simons Center for Interagency Cooperation, Fort Leavenworth, Kansas FEATURES | 1 About The Simons Center The Arthur D. Simons Center for Interagency Cooperation is a major program of the Command and General Staff College Foundation, Inc. The Simons Center is committed to the development of military leaders with interagency operational skills and an interagency body of knowledge that facilitates broader and more effective cooperation and policy implementation. About the CGSC Foundation The Command and General Staff College Foundation, Inc., was established on December 28, 2005 as a tax-exempt, non-profit educational foundation that provides resources and support to the U.S. Army Command and General Staff College in the development of tomorrow’s military leaders. The CGSC Foundation helps to advance the profession of military art and science by promoting the welfare and enhancing the prestigious educational programs of the CGSC. The CGSC Foundation supports the College’s many areas of focus by providing financial and research support for major programs such as the Simons Center, symposia, conferences, and lectures, as well as funding and organizing community outreach activities that help connect the American public to their Army. All Simons Center works are published by the “CGSC Foundation Press.” The CGSC Foundation is an equal opportunity provider. InterAgency Journal FEATURES Vol. 10, No. 3 (2019) 4 In the beginning... Special Report by Robert Ulin Arthur D. Simons Center for Interagency Cooperation 7 Military Neuro-Interventions: The Lewis and Clark Center Solving the Right Problems for Ethical Outcomes 100 Stimson Ave., Suite 1149 Shannon E. -

Improved Policy Networks for Computer Go
Improved Policy Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, PARIS, FRANCE Abstract. Golois uses residual policy networks to play Go. Two improvements to these residual policy networks are proposed and tested. The first one is to use three output planes. The second one is to add Spatial Batch Normalization. 1 Introduction Deep Learning for the game of Go with convolutional neural networks has been ad- dressed by [2]. It has been further improved using larger networks [7, 10]. AlphaGo [9] combines Monte Carlo Tree Search with a policy and a value network. Residual Networks improve the training of very deep networks [4]. These networks can gain accuracy from considerably increased depth. On the ImageNet dataset a 152 layers networks achieves 3.57% error. It won the 1st place on the ILSVRC 2015 classifi- cation task. The principle of residual nets is to add the input of the layer to the output of each layer. With this simple modification training is faster and enables deeper networks. Residual networks were recently successfully adapted to computer Go [1]. As a follow up to this paper, we propose improvements to residual networks for computer Go. The second section details different proposed improvements to policy networks for computer Go, the third section gives experimental results, and the last section con- cludes. 2 Proposed Improvements We propose two improvements for policy networks. The first improvement is to use multiple output planes as in DarkForest. The second improvement is to use Spatial Batch Normalization. 2.1 Multiple Output Planes In DarkForest [10] training with multiple output planes containing the next three moves to play has been shown to improve the level of play of a usual policy network with 13 layers. -

Machine Learning Explained
Learning Deep or not Deep… De MENACE à AlphaGo JM Alliot Le Deep Learning en Version Simple Qu’est-ce que c’est ? Croisement entre deux univers • L’apprentissage • Par renforcement: on est capable d’évaluer le résultat et de l’utiliser pour améliorer le programme • Supervisé: une base de données d’apprentissage est disponible cas par cas • Non supervisé: algorithmes de classification (k- means,…),… • Les neurosciences DLVS L’apprentissage par renforcement • Turing: • « Instead of trying to produce a program to simulate the adult mind, why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain. Presumably the child brain is something like a notebook as one buys it from the stationers. Rather little mechanism, and lots of blank sheets.” • “The use of punishments and rewards can at best be a part of the teaching process. Roughly speaking, if the teacher has no other means of communicating to the pupil, the amount of information which can reach him does not exceed the total number of rewards and punishments applied. By the time a child has learnt to repeat “Casabianca” he would probably feel very sore indeed, if the text could only be discovered by a “Twenty Questions” technique, every “NO” taking the form of a blow.” DLVS L’apprentissage par renforcement • Arthur Samuel (1959): « Some Studies in Machine Learning Using the Game of Checkers » • Memoization • Ajustement automatique de paramètres par régression. • Donald Michie (1962): MENACE -

Hearing on China's Military Reforms and Modernization: Implications for the United States Hearing Before the U.S.-China Economic
HEARING ON CHINA'S MILITARY REFORMS AND MODERNIZATION: IMPLICATIONS FOR THE UNITED STATES HEARING BEFORE THE U.S.-CHINA ECONOMIC AND SECURITY REVIEW COMMISSION ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION THURSDAY, FEBRUARY 15, 2018 Printed for use of the United States-China Economic and Security Review Commission Available via the World Wide Web: www.uscc.gov UNITED STATES-CHINA ECONOMIC AND SECURITY REVIEW COMMISSION WASHINGTON: 2018 U.S.-CHINA ECONOMIC AND SECURITY REVIEW COMMISSION ROBIN CLEVELAND, CHAIRMAN CAROLYN BARTHOLOMEW, VICE CHAIRMAN Commissioners: HON. CARTE P. GOODWIN HON. JAMES TALENT DR. GLENN HUBBARD DR. KATHERINE C. TOBIN HON. DENNIS C. SHEA MICHAEL R. WESSEL HON. JONATHAN N. STIVERS DR. LARRY M. WORTZEL The Commission was created on October 30, 2000 by the Floyd D. Spence National Defense Authorization Act for 2001 § 1238, Public Law No. 106-398, 114 STAT. 1654A-334 (2000) (codified at 22 U.S.C. § 7002 (2001), as amended by the Treasury and General Government Appropriations Act for 2002 § 645 (regarding employment status of staff) & § 648 (regarding changing annual report due date from March to June), Public Law No. 107-67, 115 STAT. 514 (Nov. 12, 2001); as amended by Division P of the “Consolidated Appropriations Resolution, 2003,” Pub L. No. 108-7 (Feb. 20, 2003) (regarding Commission name change, terms of Commissioners, and responsibilities of the Commission); as amended by Public Law No. 109- 108 (H.R. 2862) (Nov. 22, 2005) (regarding responsibilities of Commission and applicability of FACA); as amended by Division J of the “Consolidated Appropriations Act, 2008,” Public Law Nol. 110-161 (December 26, 2007) (regarding responsibilities of the Commission, and changing the Annual Report due date from June to December); as amended by the Carl Levin and Howard P. -

Autonomous Aircraft Sequencing and Separation with Hierarchical Deep Reinforcement Learning
ICRAT 2018 Autonomous Aircraft Sequencing and Separation with Hierarchical Deep Reinforcement Learning Marc Brittain Peng Wei Aerospace Engineering Department Aerospace Engineering Department Iowa State University Iowa State University Ames, IA, USA Ames, IA, USA [email protected] [email protected] Abstract—With the increasing air traffic density and complexity autonomy or human operator decisions, and cope with in traditional controlled airspace, and the envisioned large envisioned high-density and on-demand air traffic by providing volume vertical takeoff and landing (VTOL) operations in low- automated sequencing and separation advisories. altitude airspace for personal air mobility or on-demand air taxi, an autonomous air traffic control system (a fully automated The inspiration of this paper is twofold. First, the authors airspace) is needed as the ultimate solution to handle dense, were amazed by the fact that an artificial intelligence agent complex and dynamic air traffic in the future. In this work, we called AlphaGo built by DeepMind defeated the world design and build an artificial intelligence (AI) agent to perform champion Ke Jie in three matches of Go in May 2017 [11]. air traffic control sequencing and separation. The approach is to This notable advance in AI field demonstrated the theoretical formulate this problem as a reinforcement learning model and foundation and computational capability to potentially augment solve it using the hierarchical deep reinforcement learning and facilitate human tasks with intelligent agents and AI algorithms. For demonstration, the NASA Sector 33 app has technologies. Therefore, the authors want to apply the most been used as our simulator and learning environment for the recent AI frameworks and algorithms to re-visit the agent. -
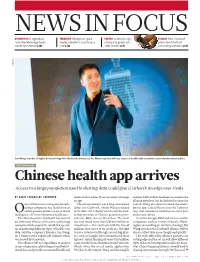
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Residual Networks for Computer Go Tristan Cazenave
Residual Networks for Computer Go Tristan Cazenave To cite this version: Tristan Cazenave. Residual Networks for Computer Go. IEEE Transactions on Games, Institute of Electrical and Electronics Engineers, 2018, 10 (1), 10.1109/TCIAIG.2017.2681042. hal-02098330 HAL Id: hal-02098330 https://hal.archives-ouvertes.fr/hal-02098330 Submitted on 12 Apr 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. IEEE TCIAIG 1 Residual Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, 75016 PARIS, FRANCE Deep Learning for the game of Go recently had a tremendous success with the victory of AlphaGo against Lee Sedol in March 2016. We propose to use residual networks so as to improve the training of a policy network for computer Go. Training is faster than with usual convolutional networks and residual networks achieve high accuracy on our test set and a 4 dan level. Index Terms—Deep Learning, Computer Go, Residual Networks. I. INTRODUCTION Input EEP Learning for the game of Go with convolutional D neural networks has been addressed by Clark and Storkey [1]. It has been further improved by using larger networks [2]. -

NTT Technical Review, Vol. 15, No. 11, Nov. 2017
NTT Technical Review November 2017 Vol. 15 No. 11 Front-line Researchers Naonori Ueda, NTT Fellow, Head of Ueda Research Laboratory and Director of Machine Learning and Data Science Center, NTT Communication Science Laboratories Feature Articles: Communication Science that Enables corevo®—Artificial Intelligence that Gets Closer to People Basic Research in the Era of Artificial Intelligence, Internet of Things, and Big Data—New Research Design through the Convergence of Science and Engineering Generative Personal Assistance with Audio and Visual Examples Efficient Algorithm for Enumerating All Solutions to an Exact Cover Problem Memory-efficient Word Embedding Vectors Synthesizing Ghost-free Stereoscopic Images for Viewers without 3D Glasses Personalizing Your Speech Interface with Context Adaptive Deep Neural Networks Regular Articles Optimization of Harvest Time in Microalgae Cultivation Using an Image Processing Algorithm for Color Restoration Global Standardization Activities Report on First Meeting of ITU-T TSAG (Telecommunication Standardization Advisory Group) for the Study Period 2017 to 2020 Information Event Report: NTT Communication Science Laboratories Open House 2017 Short Reports Arkadin Brings Businesses into the Future with New Cloud Unified Communications Services and Digital Operations Strategies World’s Largest Transmission Capacity with Standard Diameter Multi-core Optical Fiber—Accelerated Multi-core Fiber Application Using Current Standard Technology External Awards/Papers Published in Technical Journals -

Spy on Me #2 – Artistic Manoevres for the Digital Present
Spy on Me Artistic Manoeuvres for the Digital Present #2 19. –29.3.2020 Spy on Me #2 – Artistic Manoeuvres for the Digital Present 19.–29.3.2020 / HAU1, HAU2, HAU3 We have arrived in the reality of digital transformation. Life with screens, apps and algorithms influences our behaviour, our atten - tion and desires. Meanwhile the idea of the public space and of democracy is being reorganized by digital means. The festival “Spy on Me” goes into its second round after 2018, searching for manoeuvres for the digital present together with Berlin-based and international artists. Performances, interactive spatial installati - ons and discursive events examine the complex effects of the digi - tal transformation of society. In theatre, where live encounters are the focus, we come close to the intermediate spaces of digital life, searching for ways out of feeling powerless and overwhelmed, as currently experienced by many users of internet-based technolo - gies. For it is not just in some future digital utopia, but here, in the midst of this present, that we have to deal with the basic conditi - ons of living together as a society and of planetary survival. Are we at the edge of a great digital darkness or at the decisive tur - ning point of perspective? A Festival by HAU Hebbel am Ufer. Funded by: Hauptstadtkulturfonds. What is our rela - tionship with alien conscious - nesses? As we build rivals to human intelligence, James Bridle looks at our relationship with the planet’s other alien consciousnesses. 5 On 27 June 1835, two masters of the ancient DeepBlue defeated Garry Kasparov at chess, prise, strangeness and even horror that Chinese game of Go faced off in a match up to that point a game with Go-like status as AlphaGo evokes will become a feature of more which was the culmination of a years-long a bastion of human imagination and mental and more areas of our lives.