When Are We Done with Games?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Empirical Investigation on Measurement of Game Immersion Using Real World Dissociation Factor
Thesis no: MSCS-2016-13 Empirical Investigation on Measurement of Game Immersion using Real World Dissociation Factor Gadila Swarajya Haritha Reddy Faculty of Computing Blekinge Institute of Technology SE–371 79 Karlskrona, Sweden This thesis is submitted to the Faculty of Computing at Blekinge Institute of Technology in partial fulfillment of the requirements for the degree of Master of Science in Computer Science. The thesis is equivalent to 20 weeks of full time studies. Contact Information: Author(s): Gadila Swarajya Haritha Reddy E-mail: [email protected] University advisor: Prof. Sara Eriksén Department of Creative Technologies Faculty of Computing Internet : www.bth.se Blekinge Institute of Technology Phone : +46 455 38 50 00 SE–371 79 Karlskrona, Sweden Fax : +46 455 38 50 57 Abstract Context. Games involve people to a large extent where they relate them- selves with the game characters; this is commonly known as game immer- sion. Generally, some players play games for enjoyment, some for stress relaxation and so on.Game immersion is usually used to describe the degree of involvement with a game. When people play games, they don’t necessar- ily realize that they have been dissociated with the surrounding world. Real world dissociation (RWD) can be defined as the situation where a player is less aware of the surroundings outside the game than about what is happen- ing in the game itself. The RWD factor has been expected to measure the losing track of time, lack of awareness of surroundings and mental trans- portation. Objectives. In this thesis, we measure and compare the difference in game immersion between experienced and inexperienced players using RWD fac- tor. -

Artificial Intelligence in Health Care: the Hope, the Hype, the Promise, the Peril
Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril Michael Matheny, Sonoo Thadaney Israni, Mahnoor Ahmed, and Danielle Whicher, Editors WASHINGTON, DC NAM.EDU PREPUBLICATION COPY - Uncorrected Proofs NATIONAL ACADEMY OF MEDICINE • 500 Fifth Street, NW • WASHINGTON, DC 20001 NOTICE: This publication has undergone peer review according to procedures established by the National Academy of Medicine (NAM). Publication by the NAM worthy of public attention, but does not constitute endorsement of conclusions and recommendationssignifies that it is the by productthe NAM. of The a carefully views presented considered in processthis publication and is a contributionare those of individual contributors and do not represent formal consensus positions of the authors’ organizations; the NAM; or the National Academies of Sciences, Engineering, and Medicine. Library of Congress Cataloging-in-Publication Data to Come Copyright 2019 by the National Academy of Sciences. All rights reserved. Printed in the United States of America. Suggested citation: Matheny, M., S. Thadaney Israni, M. Ahmed, and D. Whicher, Editors. 2019. Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril. NAM Special Publication. Washington, DC: National Academy of Medicine. PREPUBLICATION COPY - Uncorrected Proofs “Knowing is not enough; we must apply. Willing is not enough; we must do.” --GOETHE PREPUBLICATION COPY - Uncorrected Proofs ABOUT THE NATIONAL ACADEMY OF MEDICINE The National Academy of Medicine is one of three Academies constituting the Nation- al Academies of Sciences, Engineering, and Medicine (the National Academies). The Na- tional Academies provide independent, objective analysis and advice to the nation and conduct other activities to solve complex problems and inform public policy decisions. -

Artificial Intelligence: with Great Power Comes Great Responsibility
ARTIFICIAL INTELLIGENCE: WITH GREAT POWER COMES GREAT RESPONSIBILITY JOINT HEARING BEFORE THE SUBCOMMITTEE ON RESEARCH AND TECHNOLOGY & SUBCOMMITTEE ON ENERGY COMMITTEE ON SCIENCE, SPACE, AND TECHNOLOGY HOUSE OF REPRESENTATIVES ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION JUNE 26, 2018 Serial No. 115–67 Printed for the use of the Committee on Science, Space, and Technology ( Available via the World Wide Web: http://science.house.gov U.S. GOVERNMENT PUBLISHING OFFICE 30–877PDF WASHINGTON : 2018 COMMITTEE ON SCIENCE, SPACE, AND TECHNOLOGY HON. LAMAR S. SMITH, Texas, Chair FRANK D. LUCAS, Oklahoma EDDIE BERNICE JOHNSON, Texas DANA ROHRABACHER, California ZOE LOFGREN, California MO BROOKS, Alabama DANIEL LIPINSKI, Illinois RANDY HULTGREN, Illinois SUZANNE BONAMICI, Oregon BILL POSEY, Florida AMI BERA, California THOMAS MASSIE, Kentucky ELIZABETH H. ESTY, Connecticut RANDY K. WEBER, Texas MARC A. VEASEY, Texas STEPHEN KNIGHT, California DONALD S. BEYER, JR., Virginia BRIAN BABIN, Texas JACKY ROSEN, Nevada BARBARA COMSTOCK, Virginia CONOR LAMB, Pennsylvania BARRY LOUDERMILK, Georgia JERRY MCNERNEY, California RALPH LEE ABRAHAM, Louisiana ED PERLMUTTER, Colorado GARY PALMER, Alabama PAUL TONKO, New York DANIEL WEBSTER, Florida BILL FOSTER, Illinois ANDY BIGGS, Arizona MARK TAKANO, California ROGER W. MARSHALL, Kansas COLLEEN HANABUSA, Hawaii NEAL P. DUNN, Florida CHARLIE CRIST, Florida CLAY HIGGINS, Louisiana RALPH NORMAN, South Carolina DEBBIE LESKO, Arizona SUBCOMMITTEE ON RESEARCH AND TECHNOLOGY HON. BARBARA COMSTOCK, Virginia, Chair FRANK D. LUCAS, Oklahoma DANIEL LIPINSKI, Illinois RANDY HULTGREN, Illinois ELIZABETH H. ESTY, Connecticut STEPHEN KNIGHT, California JACKY ROSEN, Nevada BARRY LOUDERMILK, Georgia SUZANNE BONAMICI, Oregon DANIEL WEBSTER, Florida AMI BERA, California ROGER W. MARSHALL, Kansas DONALD S. BEYER, JR., Virginia DEBBIE LESKO, Arizona EDDIE BERNICE JOHNSON, Texas LAMAR S. -

Lecture Note on Deep Learning and Quantum Many-Body Computation
Lecture Note on Deep Learning and Quantum Many-Body Computation Jin-Guo Liu, Shuo-Hui Li, and Lei Wang∗ Institute of Physics, Chinese Academy of Sciences Beijing 100190, China November 23, 2018 Abstract This note introduces deep learning from a computa- tional quantum physicist’s perspective. The focus is on deep learning’s impacts to quantum many-body compu- tation, and vice versa. The latest version of the note is at http://wangleiphy.github.io/. Please send comments, suggestions and corrections to the email address in below. ∗ [email protected] CONTENTS 1 introduction2 2 discriminative learning4 2.1 Data Representation 4 2.2 Model: Artificial Neural Networks 6 2.3 Cost Function 9 2.4 Optimization 11 2.4.1 Back Propagation 11 2.4.2 Gradient Descend 13 2.5 Understanding, Visualization and Applications Beyond Classification 15 3 generative modeling 17 3.1 Unsupervised Probabilistic Modeling 17 3.2 Generative Model Zoo 18 3.2.1 Boltzmann Machines 19 3.2.2 Autoregressive Models 22 3.2.3 Normalizing Flow 23 3.2.4 Variational Autoencoders 25 3.2.5 Tensor Networks 28 3.2.6 Generative Adversarial Networks 29 3.3 Summary 32 4 applications to quantum many-body physics and more 33 4.1 Material and Chemistry Discoveries 33 4.2 Density Functional Theory 34 4.3 “Phase” Recognition 34 4.4 Variational Ansatz 34 4.5 Renormalization Group 35 4.6 Monte Carlo Update Proposals 36 4.7 Tensor Networks 37 4.8 Quantum Machine Leanring 38 4.9 Miscellaneous 38 5 hands on session 39 5.1 Computation Graph and Back Propagation 39 5.2 Deep Learning Libraries 41 5.3 Generative Modeling using Normalizing Flows 42 5.4 Restricted Boltzmann Machine for Image Restoration 43 5.5 Neural Network as a Quantum Wave Function Ansatz 43 6 challenges ahead 45 7 resources 46 BIBLIOGRAPHY 47 1 1 INTRODUCTION Deep Learning (DL) ⊂ Machine Learning (ML) ⊂ Artificial Intelli- gence (AI). -

AI Computer Wraps up 4-1 Victory Against Human Champion Nature Reports from Alphago's Victory in Seoul
The Go Files: AI computer wraps up 4-1 victory against human champion Nature reports from AlphaGo's victory in Seoul. Tanguy Chouard 15 March 2016 SEOUL, SOUTH KOREA Google DeepMind Lee Sedol, who has lost 4-1 to AlphaGo. Tanguy Chouard, an editor with Nature, saw Google-DeepMind’s AI system AlphaGo defeat a human professional for the first time last year at the ancient board game Go. This week, he is watching top professional Lee Sedol take on AlphaGo, in Seoul, for a $1 million prize. It’s all over at the Four Seasons Hotel in Seoul, where this morning AlphaGo wrapped up a 4-1 victory over Lee Sedol — incidentally, earning itself and its creators an honorary '9-dan professional' degree from the Korean Baduk Association. After winning the first three games, Google-DeepMind's computer looked impregnable. But the last two games may have revealed some weaknesses in its makeup. Game four totally changed the Go world’s view on AlphaGo’s dominance because it made it clear that the computer can 'bug' — or at least play very poor moves when on the losing side. It was obvious that Lee felt under much less pressure than in game three. And he adopted a different style, one based on taking large amounts of territory early on rather than immediately going for ‘street fighting’ such as making threats to capture stones. This style – called ‘amashi’ – seems to have paid off, because on move 78, Lee produced a play that somehow slipped under AlphaGo’s radar. David Silver, a scientist at DeepMind who's been leading the development of AlphaGo, said the program estimated its probability as 1 in 10,000. -

Accelerators and Obstacles to Emerging ML-Enabled Research Fields
Life at the edge: accelerators and obstacles to emerging ML-enabled research fields Soukayna Mouatadid Steve Easterbrook Department of Computer Science Department of Computer Science University of Toronto University of Toronto [email protected] [email protected] Abstract Machine learning is transforming several scientific disciplines, and has resulted in the emergence of new interdisciplinary data-driven research fields. Surveys of such emerging fields often highlight how machine learning can accelerate scientific discovery. However, a less discussed question is how connections between the parent fields develop and how the emerging interdisciplinary research evolves. This study attempts to answer this question by exploring the interactions between ma- chine learning research and traditional scientific disciplines. We examine different examples of such emerging fields, to identify the obstacles and accelerators that influence interdisciplinary collaborations between the parent fields. 1 Introduction In recent decades, several scientific research fields have experienced a deluge of data, which is impacting the way science is conducted. Fields such as neuroscience, psychology or social sciences are being reshaped by the advances in machine learning (ML) and the data processing technologies it provides. In some cases, new research fields have emerged at the intersection of machine learning and more traditional research disciplines. This is the case for example, for bioinformatics, born from collaborations between biologists and computer scientists in the mid-80s [1], which is now considered a well-established field with an active community, specialized conferences, university departments and research groups. How do these transformations take place? Do they follow similar paths? If yes, how can the advances in such interdisciplinary fields be accelerated? Researchers in the philosophy of science have long been interested in these questions. -

Valve Corporation Tournament License
VALVE CORPORATION DOTA 2 TOURNAMENT LICENSE AND PAID SPECTATOR SERVICE AGREEMENT By pressing “Submit” you and/or the party you represent in submitting this web form (“Licensee”) agree to be bound be the terms of this Dota 2 Tournament License and Paid Spectator Service Agreement (the “Agreement”). It is entered into and effective by and between Valve Corporation, a Washington, U.S.A. corporation (“Valve”), and the Licensee as of the day that Valve accepts and confirms the submission by making it accessible through the Paid Spectator Service. 1. Definitions 1.1 “Adjusted Gross Revenue” mean the gross revenue actually received by Valve from Valve’s sale of the Tournaments via the Paid Spectator Service, less (a) actual costs resulting directly from returns, discounts, refunds, fraud or chargebacks; (b) taxes that are imposed on a customer of the Paid Spectator Service on the distribution, sale or license of the Tournaments (such as sales, use, excise, value-added and other similar taxes) that are received from such customer by Valve for payment to governmental authorities. 1.2 “Confidential Information” means (i) any trade secrets relating to Valve’s product plans, designs, costs, prices and names, finances, marketing plans, business opportunities, personnel, research development or know-how; (ii) any unreleased Valve products; and (iii) any other information that Valve designates to Licensee as being confidential or which, based on the nature of such information and the circumstances surrounding its disclosure, ought in good faith to be treated as confidential. 1.3 “Game” means the game Dota 2. 1.4 “Game-Related Intellectual Property,” means the Dota™ trademark and Dota 2 logo. -

Transfer Learning Between RTS Combat Scenarios Using Component-Action Deep Reinforcement Learning
Transfer Learning Between RTS Combat Scenarios Using Component-Action Deep Reinforcement Learning Richard Kelly and David Churchill Department of Computer Science Memorial University of Newfoundland St. John’s, NL, Canada [email protected], [email protected] Abstract an enormous financial investment in hardware for training, using over 80000 CPU cores to run simultaneous instances Real-time Strategy (RTS) games provide a challenging en- of StarCraft II, 1200 Tensor Processor Units (TPUs) to train vironment for AI research, due to their large state and ac- the networks, as well as a large amount of infrastructure and tion spaces, hidden information, and real-time gameplay. Star- Craft II has become a new test-bed for deep reinforcement electricity to drive this large-scale computation. While Al- learning systems using the StarCraft II Learning Environment phaStar is estimated to be the strongest existing RTS AI agent (SC2LE). Recently the full game of StarCraft II has been ap- and was capable of beating many players at the Grandmas- proached with a complex multi-agent reinforcement learning ter rank on the StarCraft II ladder, it does not yet play at the (RL) system, however this is currently only possible with ex- level of the world’s best human players (e.g. in a tournament tremely large financial investments out of the reach of most setting). The creation of AlphaStar demonstrated that using researchers. In this paper we show progress on using varia- deep learning to tackle RTS AI is a powerful solution, how- tions of easier to use RL techniques, modified to accommo- ever applying it to the entire game as a whole is not an eco- date actions with multiple components used in the SC2LE. -

Iaj 10-3 (2019)
Vol. 10 No. 3 2019 Arthur D. Simons Center for Interagency Cooperation, Fort Leavenworth, Kansas FEATURES | 1 About The Simons Center The Arthur D. Simons Center for Interagency Cooperation is a major program of the Command and General Staff College Foundation, Inc. The Simons Center is committed to the development of military leaders with interagency operational skills and an interagency body of knowledge that facilitates broader and more effective cooperation and policy implementation. About the CGSC Foundation The Command and General Staff College Foundation, Inc., was established on December 28, 2005 as a tax-exempt, non-profit educational foundation that provides resources and support to the U.S. Army Command and General Staff College in the development of tomorrow’s military leaders. The CGSC Foundation helps to advance the profession of military art and science by promoting the welfare and enhancing the prestigious educational programs of the CGSC. The CGSC Foundation supports the College’s many areas of focus by providing financial and research support for major programs such as the Simons Center, symposia, conferences, and lectures, as well as funding and organizing community outreach activities that help connect the American public to their Army. All Simons Center works are published by the “CGSC Foundation Press.” The CGSC Foundation is an equal opportunity provider. InterAgency Journal FEATURES Vol. 10, No. 3 (2019) 4 In the beginning... Special Report by Robert Ulin Arthur D. Simons Center for Interagency Cooperation 7 Military Neuro-Interventions: The Lewis and Clark Center Solving the Right Problems for Ethical Outcomes 100 Stimson Ave., Suite 1149 Shannon E. -

Machine Learning Explained
Learning Deep or not Deep… De MENACE à AlphaGo JM Alliot Le Deep Learning en Version Simple Qu’est-ce que c’est ? Croisement entre deux univers • L’apprentissage • Par renforcement: on est capable d’évaluer le résultat et de l’utiliser pour améliorer le programme • Supervisé: une base de données d’apprentissage est disponible cas par cas • Non supervisé: algorithmes de classification (k- means,…),… • Les neurosciences DLVS L’apprentissage par renforcement • Turing: • « Instead of trying to produce a program to simulate the adult mind, why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain. Presumably the child brain is something like a notebook as one buys it from the stationers. Rather little mechanism, and lots of blank sheets.” • “The use of punishments and rewards can at best be a part of the teaching process. Roughly speaking, if the teacher has no other means of communicating to the pupil, the amount of information which can reach him does not exceed the total number of rewards and punishments applied. By the time a child has learnt to repeat “Casabianca” he would probably feel very sore indeed, if the text could only be discovered by a “Twenty Questions” technique, every “NO” taking the form of a blow.” DLVS L’apprentissage par renforcement • Arthur Samuel (1959): « Some Studies in Machine Learning Using the Game of Checkers » • Memoization • Ajustement automatique de paramètres par régression. • Donald Michie (1962): MENACE -

In-Datacenter Performance Analysis of a Tensor Processing Unit
In-Datacenter Performance Analysis of a Tensor Processing Unit Presented by Josh Fried Background: Machine Learning Neural Networks: ● Multi Layer Perceptrons ● Recurrent Neural Networks (mostly LSTMs) ● Convolutional Neural Networks Synapse - each edge, has a weight Neuron - each node, sums weights and uses non-linear activation function over sum Propagating inputs through a layer of the NN is a matrix multiplication followed by an activation Background: Machine Learning Two phases: ● Training (offline) ○ relaxed deadlines ○ large batches to amortize costs of loading weights from DRAM ○ well suited to GPUs ○ Usually uses floating points ● Inference (online) ○ strict deadlines: 7-10ms at Google for some workloads ■ limited possibility for batching because of deadlines ○ Facebook uses CPUs for inference (last class) ○ Can use lower precision integers (faster/smaller/more efficient) ML Workloads @ Google 90% of ML workload time at Google spent on MLPs and LSTMs, despite broader focus on CNNs RankBrain (search) Inception (image classification), Google Translate AlphaGo (and others) Background: Hardware Trends End of Moore’s Law & Dennard Scaling ● Moore - transistor density is doubling every two years ● Dennard - power stays proportional to chip area as transistors shrink Machine Learning causing a huge growth in demand for compute ● 2006: Excess CPU capacity in datacenters is enough ● 2013: Projected 3 minutes per-day per-user of speech recognition ○ will require doubling datacenter compute capacity! Google’s Answer: Custom ASIC Goal: Build a chip that improves cost-performance for NN inference What are the main costs? Capital Costs Operational Costs (power bill!) TPU (V1) Design Goals Short design-deployment cycle: ~15 months! Plugs in to PCIe slot on existing servers Accelerates matrix multiplication operations Uses 8-bit integer operations instead of floating point How does the TPU work? CISC instructions, issued by host. -
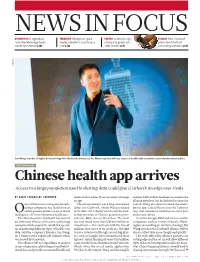
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly.