Krishnadeva, a Fresh Transliteration Scheme
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kannada Versus Sanskrit: Hegemony, Power and Subjugation Dr
================================================================== Language in India www.languageinindia.com ISSN 1930-2940 Vol. 17:8 August 2017 UGC Approved List of Journals Serial Number 49042 ================================================================ Kannada versus Sanskrit: Hegemony, Power and Subjugation Dr. Meti Mallikarjun =================================================================== Abstract This paper explores the sociolinguistic struggles and conflicts that have taken place in the context of confrontation between Kannada and Sanskrit. As a result, the dichotomy of the “enlightened” Sanskrit and “unenlightened” Kannada has emerged among Sanskrit-oriented scholars and philologists. This process of creating an asymmetrical relationship between Sanskrit and Kannada can be observed throughout the formation of the Kannada intellectual world. This constructed dichotomy impacted the Kannada world in such a way that without the intellectual resource of Sanskrit, the development of the Kannada intellectual world is considered quite impossible. This affirms that Sanskrit is inevitable for Kannada in every respect of its sociocultural and philosophical formations. This is a very simple contention, and consequently, Kannada has been suffering from “inferiority” both in the cultural and philosophical development contexts. In spite of the contributions of Prakrit and Pali languages towards Indian cultural history, the Indian cultural past is directly connected to and by and large limited to the aspects of Sanskrit culture and philosophy alone. The Sanskrit language per se could not have dominated or subjugated any of the Indian languages. But its power relations with religion and caste systems are mainly responsible for its domination over other Indian languages and cultures. Due to this sociolinguistic hegemonic structure, Sanskrit has become a language of domination, subjugation, ideology and power. This Sanskrit-centric tradition has created its own notion of poetics, grammar, language studies and cultural understandings. -

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
Note: the Font “Hindiromanized” Must Be Selected
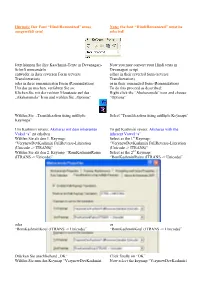
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

Social Transformation of Pakistan Under Urdu Language
Social Transformations in Contemporary Society, 2021 (9) ISSN 2345-0126 (online) SOCIAL TRANSFORMATION OF PAKISTAN UNDER URDU LANGUAGE Dr. Sohaib Mukhtar Bahria University, Pakistan [email protected] Abstract Urdu is the national language of Pakistan under article 251 of the Constitution of Pakistan 1973. Urdu language is the first brick upon which whole building of Pakistan is built. In pronunciation both Hindi in India and Urdu in Pakistan are same but in script Indian choose their religious writing style Sanskrit also called Devanagari as Muslims of Pakistan choose Arabic script for writing Urdu language. Urdu language is based on two nation theory which is the basis of the creation of Pakistan. There are two nations in Indian Sub-continent (i) Hindu, and (ii) Muslims therefore Muslims of Indian sub- continent chanted for separate Muslim Land Pakistan in Indian sub-continent thus struggled for achieving separate homeland Pakistan where Muslims can freely practice their religious duties which is not possible in a country where non-Muslims are in majority thus Urdu which is derived from Arabic, Persian, and Turkish declared the national language of Pakistan as official language is still English thus steps are required to be taken at Government level to make Urdu as official language of Pakistan. There are various local languages of Pakistan mainly: Punjabi, Sindhi, Pashto, Balochi, Kashmiri, Balti and it is fundamental right of all citizens of Pakistan under article 28 of the Constitution of Pakistan 1973 to protect, preserve, and promote their local languages and local culture but the national language of Pakistan is Urdu according to article 251 of the Constitution of Pakistan 1973. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Intelligence System for Tamil Vattezhuttuoptical
Mr R.Vinoth et al. / International Journal of Computer Science & Engineering Technology (IJCSET) INTELLIGENCE SYSTEM FOR TAMIL VATTEZHUTTUOPTICAL CHARACTER RCOGNITION Mr R.Vinoth Assistant Professor, Department of Information Technology Agni college of Technology, Chennai, India [email protected] Rajesh R. UG Student, Department of Information Technology Agni college of Technology, Chennai, India [email protected] Yoganandhan P. UG Student, Department of Information Technology Agni college of Technology, Chennai, India [email protected] Abstract--A system that involves character recognition and information retrieval of Palm Leaf Manuscript. The conversion of ancient Tamil to the present Tamil digital text format. Various algorithms were used to find the OCR for different languages, Ancient letter conversion still possess a big challenge. Because Image recognition technology has reached near-perfection when it comes to scanning Tamil text. The proposed system overcomes such a situation by converting all the palm manuscripts into Tamil digital text format. Though the Tamil scripts are difficult to understand. We are using this approach to solve the existing problems and convert it to Tamil digital text. Keyword - Vatteluttu Tamil (VT); Data set; Character recognition; Neural Network. I. INTRODUCTION Tamil language is one of the longest surviving classical languages in the world. Tamilnadu is a place, where the Palm Leaf Manuscript has been preserved. There are some difficulties to preserve the Palm Leaf Manuscript. So, we need to preserve the Palm Leaf Manuscript by converting to the form of digital text format. Computers and Smart devices are used by mostof them now a day. So, this system helps to convert and preserve in a fine manner. -

Morphological Integration of Urdu Loan Words in Pakistani English
English Language Teaching; Vol. 13, No. 5; 2020 ISSN 1916-4742 E-ISSN 1916-4750 Published by Canadian Center of Science and Education Morphological Integration of Urdu Loan Words in Pakistani English Tania Ali Khan1 1Minhaj University/Department of English Language & Literature Lahore, Pakistan Correspondence: Tania Ali Khan, Minhaj University/Department of English Language & Literature Lahore, Pakistan Received: March 19, 2020 Accepted: April 18, 2020 Online Published: April 21, 2020 doi: 10.5539/elt.v13n5p49 URL: https://doi.org/10.5539/elt.v13n5p49 Abstract Pakistani English is a variety of English language concerning Sentence structure, Morphology, Phonology, Spelling, and Vocabulary. The one semantic element, which makes the investigation of Pakistani English additionally fascinating is the Vocabulary. Pakistani English uses many loan words from Urdu language and other local dialects, which have become an integral part of Pakistani English, and the speakers don't feel odd while using these words. Numerous studies are conducted on Pakistani English Vocabulary, yet a couple manage to deal with morphology. Therefore, the purpose of this study is to explore the morphological integration of Urdu loan words in Pakistani English. Another purpose of the study is to investigate the main reasons of this morphological integration process. The Qualitative research method is used in this study. Researcher prepares a sample list of 50 loan words for the analysis. These words are randomly chosen from the newspaper “The Dawn” since it is the most dispersed English language newspaper in Pakistan. Some words are selected from the Books and Novellas of Pakistani English fiction authors, and concise Oxford English Dictionary, 11th edition. -

Exploring Language Similarities with Dimensionality Reduction Techniques
EXPLORING LANGUAGE SIMILARITIES WITH DIMENSIONALITY REDUCTION TECHNIQUES Sangarshanan Veeraraghavan Final Year Undergraduate VIT Vellore [email protected] Abstract In recent years several novel models were developed to process natural language, development of accurate language translation systems have helped us overcome geographical barriers and communicate ideas effectively. These models are developed mostly for a few languages that are widely used while other languages are ignored. Most of the languages that are spoken share lexical, syntactic and sematic similarity with several other languages and knowing this can help us leverage the existing model to build more specific and accurate models that can be used for other languages, so here I have explored the idea of representing several known popular languages in a lower dimension such that their similarities can be visualized using simple 2 dimensional plots. This can even help us understand newly discovered languages that may not share its vocabulary with any of the existing languages. 1. Introduction Language is a method of communication and ironically has long remained a communication barrier. Written representations of all languages look quite different but inherently share similarity between them. For example if we show a person with no knowledge of English alphabets a text in English and then in Spanish they might be oblivious to the similarity between them as they look like gibberish to them. There might also be several languages which may seem completely different to even experienced linguists but might share a subtle hidden similarity as they is a possibility that languages with no shared vocabulary might still have some similarity. -

Comment on L2/13-065: Grantha Characters from Other Indic Blocks Such As Devanagari, Tamil, Bengali Are NOT the Solution
Comment on L2/13-065: Grantha characters from other Indic blocks such as Devanagari, Tamil, Bengali are NOT the solution Dr. Naga Ganesan ([email protected]) Here is a brief comment on L2/13-065 which suggests Devanagari block for Grantha characters to write both Aryan and Dravidian languages. From L2/13-065, which suggests Devanagari block for writing Sanskrit and Dravidian languages, we read: “Similar dedicated characters were provided to cater different fonts as URUDU MARATHI SINDHI MARWARI KASHMERE etc for special conditions and needs within the shared DEVANAGARI range. There are provisions made to suit Dravidian specials also as short E short O LLLA RRA NNNA with new created glyptic forms in rhythm with DEVANAGARI glyphs (with suitable combining ortho-graphic features inside DEVANAGARI) for same special functions. These will help some aspirant proposers as a fall out who want to write every Indian language contents in Grantham when it is unified with DEVANAGARI because those features were already taken care of by the presence in that DEVANAGARI. Even few objections seen in some docs claim them as Tamil characters to induce a bug inside Grantham like letters from GoTN and others become tangential because it is going to use the existing Sanskrit properties inside shared DEVANAGARI and also with entirely new different glyph forms nothing connected with Tamil. In my doc I have shown rhythmic non-confusable glyphs for Grantham LLLA RRA NNNA for which I believe there cannot be any varied opinions even by GoTN etc which is very much as Grantham and not like Tamil form at all to confuse (as provided in proposals).” Grantha in Devanagari block to write Sanskrit and Dravidian languages will not work. -

An Augmented Translation Technique for Low Resource Language Pair: Sanskrit to Hindi Translation
An Augmented Translation Technique for low Resource Language pair: Sanskrit to Hindi translation RASHI KUMAR, Malaviya National Institute of Technology, India PIYUSH JHA, Malaviya National Institute of Technology, India VINEET SAHULA, Malaviya National Institute of Technology, India Neural Machine Translation (NMT) is an ongoing technique for Machine Translation (MT) using enormous artificial neural network. It has exhibited promising outcomes and has shown incredible potential in solving challenging machine translation exercises. One such exercise is the best approach to furnish great MT to language sets with a little preparing information. In this work, Zero Shot Translation (ZST) is inspected for a low resource language pair. By working on high resource language pairs for which benchmarks are available, namely Spanish to Portuguese, and training on data sets (Spanish-English and English-Portuguese) we prepare a state of proof for ZST system that gives appropriate results on the available data. Subsequently the same architecture is tested for Sanskrit to Hindi translation for which data is sparse, by training the model on English-Hindi and Sanskrit-English language pairs. In order to prepare and decipher with ZST system, we broaden the preparation and interpretation pipelines of NMT seq2seq model in tensorflow, incorporating ZST features. Dimensionality reduction ofword embedding is performed to reduce the memory usage for data storage and to achieve a faster training and translation cycles. In this work existing helpful technology has been utilized in an imaginative manner to execute our Natural Language Processing (NLP) issue of Sanskrit to Hindi translation. A Sanskrit-Hindi parallel corpus of 300 is constructed for testing. -

Power of Sanskrit
09/03/2014 WEBPAGE: http://www.translink.profkrishna.com E-mail: [email protected] rofkrishna.com p www. वागतम ् amurthy, Singapore n n Swaagatham N. Krishnamurthy 23 February 2014 www.profkrishna.com Copyright: Dr. N. Krish Consultant, Singapore 1 Acknowledgements and Scope of talk ी गुयो नमः (shri gurub’yo’ namaha) Thanks to Singapore Dakshina Bharatha Brahmana Sabha, and Sri Srinivasan and all members of the rofkrishna.com Sabha Committee for organising this event for me to p p launch my transliteration scheme KrishnaDheva. www. Thanks also to the Sanskrit scholars here, as well as those who have come to learn how to pronounce Sanskrit correctly in English. This talk will not be a religious discourse amurthy, Singapore n This talk will not be a Sanskrit tutoring class This talk will simply be my sharing with you how to: Write down in simple English (KrishnaDheva) any Sanskrit material without special rules, and, Copyright: Dr. N. Krish Read Sanskrit correctly from KrishnaDheva. 2 1 09/03/2014 Starting off The wrong things we say: Sri should be s’ri Siva or Shiva should be s’iva rofkrishna.com p Krishna should be kr+shna www. Visaka should be vis’a’k’a’ Shuklambaradharam should be s’ukla’mbaradh’aram Vrishaba raasi should be vr+shab’a ra’s’ihi amurthy, Singapore n Kowsika gothra should be kaus’ika go’thra … and so on! Copyright: Dr. N. Krish 3 http://sanskritdocuments.org/news/subnews/NASASanskrit.txt Power of Sanskrit – a In ancient India the intention to discover truth was so consuming, that in the process, they discovered perhaps the most perfect tool for fulfilling such a search that the world has ever known – the Sanskrit language.