Language Transliteration in Indian Languages – a Lexicon Parsing Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
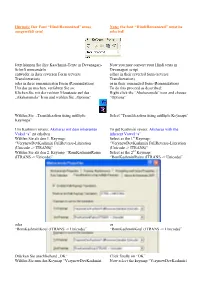
Note: the Font “Hindiromanized” Must Be Selected
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

The Journal of the Music Academy Madras Devoted to the Advancement of the Science and Art of Music
The Journal of Music Academy Madras ISSN. 0970-3101 Publication by THE MUSIC ACADEMY MADRAS Sangita Sampradaya Pradarsini of Subbarama Dikshitar (Tamil) Part I, II & III each 150.00 Part – IV 50.00 Part – V 180.00 The Journal Sangita Sampradaya Pradarsini of Subbarama Dikshitar of (English) Volume – I 750.00 Volume – II 900.00 The Music Academy Madras Volume – III 900.00 Devoted to the Advancement of the Science and Art of Music Volume – IV 650.00 Volume – V 750.00 Vol. 89 2018 Appendix (A & B) Veena Seshannavin Uruppadigal (in Tamil) 250.00 ŸÊ„¢U fl‚ÊÁ◊ flÒ∑ȧá∆U Ÿ ÿÊÁªNÔUŒÿ ⁄UflÊÒ– Ragas of Sangita Saramrta – T.V. Subba Rao & ◊jQÊ— ÿòÊ ªÊÿÁãà ÃòÊ ÁÃDÊÁ◊ ŸÊ⁄UŒH Dr. S.R. Janakiraman (in English) 50.00 “I dwell not in Vaikunta, nor in the hearts of Yogins, not in the Sun; Lakshana Gitas – Dr. S.R. Janakiraman 50.00 (but) where my Bhaktas sing, there be I, Narada !” Narada Bhakti Sutra The Chaturdandi Prakasika of Venkatamakhin 50.00 (Sanskrit Text with supplement) E Krishna Iyer Centenary Issue 25.00 Professor Sambamoorthy, the Visionary Musicologist 150.00 By Brahma EDITOR Sriram V. Raga Lakshanangal – Dr. S.R. Janakiraman (in Tamil) Volume – I, II & III each 150.00 VOL. 89 – 2018 VOL. COMPUPRINT • 2811 6768 Published by N. Murali on behalf The Music Academy Madras at New No. 168, TTK Road, Royapettah, Chennai 600 014 and Printed by N. Subramanian at Sudarsan Graphics Offset Press, 14, Neelakanta Metha Street, T. Nagar, Chennai 600 014. Editor : V. Sriram. THE MUSIC ACADEMY MADRAS ISSN. -

Power of Sanskrit
09/03/2014 WEBPAGE: http://www.translink.profkrishna.com E-mail: [email protected] rofkrishna.com p www. वागतम ् amurthy, Singapore n n Swaagatham N. Krishnamurthy 23 February 2014 www.profkrishna.com Copyright: Dr. N. Krish Consultant, Singapore 1 Acknowledgements and Scope of talk ी गुयो नमः (shri gurub’yo’ namaha) Thanks to Singapore Dakshina Bharatha Brahmana Sabha, and Sri Srinivasan and all members of the rofkrishna.com Sabha Committee for organising this event for me to p p launch my transliteration scheme KrishnaDheva. www. Thanks also to the Sanskrit scholars here, as well as those who have come to learn how to pronounce Sanskrit correctly in English. This talk will not be a religious discourse amurthy, Singapore n This talk will not be a Sanskrit tutoring class This talk will simply be my sharing with you how to: Write down in simple English (KrishnaDheva) any Sanskrit material without special rules, and, Copyright: Dr. N. Krish Read Sanskrit correctly from KrishnaDheva. 2 1 09/03/2014 Starting off The wrong things we say: Sri should be s’ri Siva or Shiva should be s’iva rofkrishna.com p Krishna should be kr+shna www. Visaka should be vis’a’k’a’ Shuklambaradharam should be s’ukla’mbaradh’aram Vrishaba raasi should be vr+shab’a ra’s’ihi amurthy, Singapore n Kowsika gothra should be kaus’ika go’thra … and so on! Copyright: Dr. N. Krish 3 http://sanskritdocuments.org/news/subnews/NASASanskrit.txt Power of Sanskrit – a In ancient India the intention to discover truth was so consuming, that in the process, they discovered perhaps the most perfect tool for fulfilling such a search that the world has ever known – the Sanskrit language. -

Library Stock.Pdf
Acc.No. Title Author Publication Samuhyashasthra Vidyarthimithram, 1 Vidhyabyasathinte saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Samuhyashasthra Vidyarthimithram, 2 Vidhyabyasathinte saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 3 saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 4 saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Adhunika Vidhyabyasathinte Vidyarthimithram, 5 Rajeshwary V.P Saithathikadisthanangal-2 Kottayam Adhunika Vidhyabyasathinte Vidyarthimithram, 6 Rajeshwary V.P Saithathikadisthanangal-2 Kottayam MalayalaBasha Bodhanathinte Vidyarthimithram, 7 Saithathikadisthanam (Pradhesika Rajapan Nair P.K Kottayam Bashabothanam-1) MalayalaBasha Bodhanathinte Vidyarthimithram, 8 Saithathikadisthanam (Pradhesika Rajapan Nair P.K Kottayam Bashabothanam-1) Samuhyashasthra Vidyarthimithram, 9 Vidhyabyasathinte saithadhika Thomas R.S Kottayam Adisthanangal-2 Samuhyashasthra Vidyarthimithram, 10 Vidhyabyasathinte saithadhika Thomas R.S Kottayam Adisthanangal-2 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 11 saithadhika Rajeshwary V.P Kottayam Adisthanangal-2 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 12 saithadhika Rajeshwary V.P Kottayam Adisthanangal-2 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 13 saithadhika Rajeshwary V.P Kottayam Adisthanangal-2 MalayalaBasha Bodhanathinte Vidyarthimithram, 14 Saithathikadisthanam (Pradhesika Rajapan Nair P.K Kottayam Bashabothanam-2) MalayalaBasha -

Python Module Index 9
indictransliterationDocumentation Release 0.0.1 sanskrit-programmers Mar 28, 2021 Contents 1 Submodules 3 1.1 indic_transliteration.sanscript......................................3 1.1.1 Submodules...........................................3 1.1.1.1 indic_transliteration.sanscript.schemes........................3 1.1.1.1.1 Submodules.................................3 1.2 indic_transliteration.xsanscript......................................3 1.3 indic_transliteration.detect........................................3 1.3.1 Supported schemes.......................................4 1.4 indic_transliteration.deduplication....................................5 2 Indices and tables 7 Python Module Index 9 Index 11 i ii indictransliterationDocumentation; Release0:0:1 sanscript is the most popular submodule here. Contents 1 indictransliterationDocumentation; Release0:0:1 2 Contents CHAPTER 1 Submodules 1.1 indic_transliteration.sanscript 1.1.1 Submodules 1.1.1.1 indic_transliteration.sanscript.schemes 1.1.1.1.1 Submodules indic_transliteration.sanscript.schemes.roman indic_transliteration.sanscript.schemes.brahmi 1.2 indic_transliteration.xsanscript 1.3 indic_transliteration.detect Example usage: from indic_transliteration import detect detect.detect('pitRRIn') == Scheme.ITRANS detect.detect('pitRRn') == Scheme.HK When handling a Sanskrit string, it’s almost always best to explicitly state its transliteration scheme. This avoids embarrassing errors with words like pitRRIn. But most of the time, it’s possible to infer the encoding from the text itself. -

Stotras in Sanskrit, Tamil, Malayalam and Krithis Addressed To
Stotras in Sanskrit, Tamil, Malayalam and Krithis addressed to Guruvayurappan This document has 10 sanskrit stotras, 5 Tamil prayers ,56 Malayalam prayers and 8 Krithis Table of Contents 1. Stotras in Sanskrit, Tamil, Malayalam and Krithis addressed to Guruvayurappan .......... 1 2. Guruvayu puresa Pancha Rathnam(sanskrit)........................................................................... 5 3. Sri Guruvatha pureesa stotram .................................................................................................. 7 4. Sampoorna roga nivarana stotra of Guryvayurappan ......................................................... 9 5. Solve all your problems by worshiping Lord Guruvayurappan ........................................ 13 6. Guruvayu puresa Bhujanga stotra ............................................................................................ 17 7. Guruvayupuresa Suprabatham ................................................................................................. 25 8. Gurvayurappan Suprabatham .................................................................................................. 31 9. Guruvayurappan Pratha Smaranam ...................................................................................... 37 10. Sri Guruvatha puresa Ashtotharam ........................................................................................ 39 11. Sampoorna roga nivarana stotra of Guryvayurappan ....................................................... 45 12. Srimad Narayaneeyamrutham(Tamil summary of Narayaneeyam) -
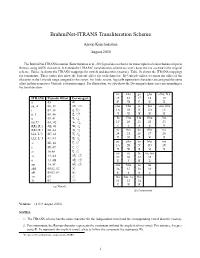
Brahminet-ITRANS Transliteration Scheme
BrahmiNet-ITRANS Transliteration Scheme Anoop Kunchukuttan August 2020 The BrahmiNet-ITRANS notation (Kunchukuttan et al., 2015) provides a scheme for transcription of major Indian scripts in Roman, using ASCII characters. It extends the ITRANS1 transliteration scheme to cover characters not covered in the original scheme. Tables 1a shows the ITRANS mappings for vowels and diacritics (matras). Table 1b shows the ITRANS mappings for consonants. These tables also show the Unicode offset for each character. By Unicode offset, we mean the offset of the character in the Unicode range assigned to the script. For Indic scripts, logically equivalent characters are assigned the same offset in their respective Unicode codepoint ranges. For illustration, we also show the Devanagari characters corresponding to the transliteration. ka kha ga gha ∼Na, N^a ITRANS Unicode Offset Devanagari 15 16 17 18 19 a 05 अ क ख ग घ ङ aa, A 06, 3E आ, ◌ा cha Cha ja jha ∼na, JNa i 07, 3F इ, ि◌ 1A 1B 1C 1D 1E ii, I 08, 40 ई, ◌ी च छ ज झ ञ u 09, 41 उ, ◌ु Ta Tha Da Dha Na uu, U 0A, 42 ऊ, ◌ू 1F 20 21 22 23 RRi, R^i 0B, 43 ऋ, ◌ृ ट ठ ड ढ ण RRI, R^I 60, 44 ॠ, ◌ॄ ta tha da dha na LLi, L^i 0C, 62 ऌ, ◌ॢ 24 25 26 27 28 LLI, L^I 61, 63 ॡ, ◌ॣ त थ द ध न pa pha ba bha ma .e 0E, 46 ऎ, ◌ॆ 2A 2B 2C 2D 2E e 0F, 47 ए, ◌े प फ ब भ म ai 10,48 ऐ, ◌ै ya ra la va, wa .o 12, 4A ऒ, ◌ॊ 2F 30 32 35 o 13, 4B ओ, ◌ो य र ल व au 14, 4C औ, ◌ौ sha Sha sa ha aM 05 02, 02 अं 36 37 38 39 aH 05 03, 03 अः श ष स ह .m 02 ◌ं Ra lda, La zha .h 03 ◌ः 31 33 34 (a) Vowels ऱ ळ ऴ (b) Consonants Version: v1.0 (9 August 2020) NOTES: 1. -

Tugboat, Volume 19 (1998), No. 2 115 an Overview of Indic Fonts For
TUGboat, Volume 19 (1998), No. 2 115 the Indo-Aryan and Dravidian language families of Fonts India. Such uniformity in phonetics is reflected in orthography, which in turn enables all scripts to be transliterated through a single scheme. This unifor- An Overview of Indic Fonts for TEX mity has subsequently been reflected in the translit- Anshuman Pandey eration schemes of the Indic language/script pack- ages. 1 Introduction Most packages have their own transliteration Many scholars and students in the humanities have scheme, but these schemes are essentially variations on a single scheme, differing merely in the coding preferred TEX over other “word processors” or doc- ument preparation systems because of the ease TEX of a few vowel, nasal, and retroflex letters. Most provides them in typesetting non-Roman scripts, the of these packages accept input in one of the two availability of TEX fonts of interest to them, and the primary 7-bit transliteration schemes— ITRANS or ability TEX has in producing well-structured docu- Velthuis—or a derivative of one of them. There ments. is also an 8-bit format called CS/CSX which a few However, this is not the case amongst Indol- of these packages support. CS/CSX is described in ogists. The lack of Indic fonts for TEXandthe further detail in Section 3. perceived difficulty of typesetting them have often 2 The Fonts and Packages turned Indologists away from using TEX. Little do they realize that TEXisthe foremost tool for de- Figure 1 shows examples of the various fonts de- veloping Indic language/script documents. -

Krishnadeva, a Fresh Transliteration Scheme
KRISHNADHEVA SCRIPT – Transliteration Scheme for Indian Languages to English N. Krishnamurthy 1. INTRODUCTION For the thousands of years that Devanagari has existed, millions have used it, mainly to chant Sanskrit (or other Devanagari-script based) prayers and scriptures. Devanagari is the script, and it is used for many languages such as Sanskrit, Hindi, and Marathi. Many do not know the Devanagari script, but have access to its transliterations into a language they know. Of these, a number of South Indian languages, such as Kannada, Malayalam and Telugu, based on Devanagari, have very similar alphabet sets with almost identical sounds. To them the transliterated versions would have been faithful reproductions of the original. However for those who did not know such Devanagari-based languages, or who did not have the transliterations available, the next recourse was to use the English language script. The author of this paper learnt Sanskrit at home from a priest as a boy, and had Sanskrit as second language in his undergraduate days. He also studied some Hindu scriptures in the Devanagari script, and formally studied a small portion of the Veda-s through a Guru. Problems with Devanagari-related languages: Many adjustments and accommodations have been made to reflect the sounds of Devanagari, such as the following (see Comparison Table at end): . The International Alphabet of Sanskrit Transliteration (IAST) includes the following conventions: "i", "u", etc. with a bar above it, to represent the long "i", "u", etc. "t", "d", and "s" with a dot underneath each, to represent the sound "t", "d", and "sh", while without the dot, they would represent, "th", "dh" and "s". -

Transcription Final Table
MAJOR ALTERNATIVE TRANSLITERATION METHODS FOR MAINLAND SOUTHEAST ASIAN OLD SCRIPTS So far, this table includes Old Khmer and Cam scripts. IAST: International Alphabet of Sanskrit Transliteration ITRANS: Indian languages TRANSliteration See http://en.wikipedia.org/wiki/Devanagari_transliteration And http://indology.info/email/members/wujastyk And http://fr.wikipedia.org/wiki/American_Standard_Code_for_Information_Interchange See also: Antelme 2007 CIK+CIC CIK+CIC Other Harvard- ITRANS ASCII Sakamoto IAST Velthuis Schreiner Remarks publications pub. Kyoto 5.3 corpora Glottal stop (as in Khmer, Mon and ’ q q, a Q other Southeast Asian scripts) VOWELS a a a A a a a a a ā aa ā AF ā A aa, A aa -a i i i I i i i i i ī ii ī IF ī I ii, I ii -i u u u U u u u u u ū uu ū UF ū U uu, U uu -u 1 e e e E e e e e e ai ai ai AI ai ai ai ai ai o o o O o o o o o au au au AU au au au au au The consonant .r r̥ .r r̥ R. r̥ R RRi, R^i .r .r (and the .rh) is not relevant for Southeast Asian scripts: r̥/r ̥̄ always represent the vowel. The dot r̥̄ .r.r r̥̄ r̥̄ RR RRI, R^I .rr, .r.r -.r underneath the r should be a small circle (here I used Lucida Grande). ḷ .l ḷ L. ḷ IR LLi, L^i .l .l ḹ .l.l ḹ ḹ IRR LLI, L^I .ll, .l.l -.l ṁ .m ṃ M.