Roman Transliteration of Indic Scripts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

Syndicatebank
E – Auction sale notice under SARFAESI Act 2002 E-Auction Sale Notice for Sale of immovable assets under the Securitization and Reconstruction of Financial Assets and Enforcement of Security Interest Act, 2002 read with proviso to Rule 8(6) of the Security Interest (Enforcement) Rules, 2002. Notice is hereby given to the public in general and in particular to the Borrower/s and Guarantor/s that the below described immovable property mortgaged / charged to the Secured Creditor, the Constructive possession of which has been taken by the Authorized Officer of Secured Creditor, will be sold on “AS IS WHERE IS, AS IS WHAT IS, and WHATEVER THERE IS” on E-auction date 15-02-2019 for recovery of dues to the Secured Creditor form the below mentioned borrowers and guarantors. The reserve price will be and earnest money deposit will be as detailed below: 1-Branch: Naka Hindola Branch, Lucknow Authorised Officer Contact No 9415550124 S No Name and Address of Borrowers and Guarantors/Co-obligant Description of the Immovable Reserved Price of Account No to Amount due with date property\ies mortgaged and Name of Property deposit EMD and Owner/Mortgager -------------------- IFS Code Earnest Money Deposit(EMD) 1 Borrower- 1. Mrs. Rashmi Srivastava Land and building situated at House No Rs 8.00 lacs A/c No. W/o Mr. Atul Srivastav, – E-6/221-A (First Floor), Sector-6, Gomti ---------------------- 94553170000010 R/o H.No.- 710, Manas Enclave, Nagar Vistar Yojna, Ward- Rafi Ahmad Rs 0.80 lacs Syndicate Bank Indira Nagar, Kidwai Nagar, Tehsil and District Naka Hindola Lucknow Lucknow and admeasuring an area of Branch, Lucknow 20.89 square meter and is bounded as IFSC Code: 2- Mr. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
Note: the Font “Hindiromanized” Must Be Selected
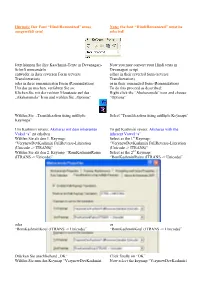
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Tugboat, Volume 15 (1994), No. 4 447 Indica, an Indic Preprocessor
TUGboat, Volume 15 (1994), No. 4 447 HPXC , an Indic preprocessor for T X script, ...inMalayalam, Indica E 1 A Sinhalese TEXSystem hpx...inSinhalese,etc. This justifies the choice of a common translit- Yannis Haralambous eration scheme for all Indic languages. But why is Abstract a preprocessor necessary, after all? A common characteristic of Indic languages is In this paper a two-fold project is described: the first the fact that the short vowel ‘a’ is inherent to con- part is a generalized preprocessor for Indic scripts (scripts of languages currently spoken in India—except Urdu—, sonants. Vowels are written by adding diacritical Sanskrit and Tibetan), with several kinds of input (LATEX marks (or smaller characters) to consonants. The commands, 7-bit ascii, CSX, ISO/IEC 10646/unicode) beauty (and complexity) of these scripts comes from and TEX output. This utility is written in standard Flex the fact that one needs a special way to denote the (the gnu version of Lex), and hence can be painlessly absence of vowel. There is a notorious diacritic, compiled on any platform. The same input methods are called “vir¯ama”, present in all Indic languages, which used for all Indic languages, so that the user does not is used for this reason. But it seems illogical to add a need to memorize different conventions and commands sign, to specify the absence of a sound. On the con- for each one of them. Moreover, the switch from one lan- trary, it seems much more logical to remove some- guage to another can be done by use of user-defineable thing, and what is done usually is that letters are preprocessor directives. -

Devan¯Agar¯I for TEX Version 2.17.1
Devanagar¯ ¯ı for TEX Version 2.17.1 Anshuman Pandey 6 March 2019 Contents 1 Introduction 2 2 Project Information 3 3 Producing Devan¯agar¯ıText with TEX 3 3.1 Macros and Font Definition Files . 3 3.2 Text Delimiters . 4 3.3 Example Input Files . 4 4 Input Encoding 4 4.1 Supplemental Notes . 4 5 The Preprocessor 5 5.1 Preprocessor Directives . 7 5.2 Protecting Text from Conversion . 9 5.3 Embedding Roman Text within Devan¯agar¯ıText . 9 5.4 Breaking Pre-Defined Conjuncts . 9 5.5 Supported LATEX Commands . 9 5.6 Using Custom LATEX Commands . 10 6 Devan¯agar¯ıFonts 10 6.1 Bombay-Style Fonts . 11 6.2 Calcutta-Style Fonts . 11 6.3 Nepali-Style Fonts . 11 6.4 Devan¯agar¯ıPen Fonts . 11 6.5 Default Devan¯agar¯ıFont (LATEX Only) . 12 6.6 PostScript Type 1 . 12 7 Special Topics 12 7.1 Delimiter Scope . 12 7.2 Line Spacing . 13 7.3 Hyphenation . 13 7.4 Captions and Date Formats (LATEX only) . 13 7.5 Customizing the date and captions (LATEX only) . 14 7.6 Using dvnAgrF in Sections and References (LATEX only) . 15 7.7 Devan¯agar¯ıand Arabic Numerals . 15 7.8 Devan¯agar¯ıPage Numbers and Other Counters (LATEX only) . 15 1 7.9 Category Codes . 16 8 Using Devan¯agar¯ıin X E LATEXand luaLATEX 16 8.1 Using Hindi with Polyglossia . 17 9 Using Hindi with babel 18 9.1 Installation . 18 9.2 Usage . 18 9.3 Language attributes . 19 9.3.1 Attribute modernhindi .