Tugboat, Volume 19 (1998), No. 2 115 an Overview of Indic Fonts For
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Section 14.4, Phags-Pa
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
Note: the Font “Hindiromanized” Must Be Selected
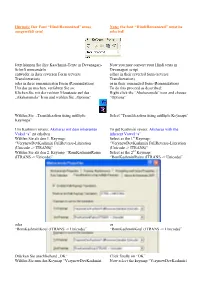
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

Tugboat, Volume 15 (1994), No. 4 447 Indica, an Indic Preprocessor
TUGboat, Volume 15 (1994), No. 4 447 HPXC , an Indic preprocessor for T X script, ...inMalayalam, Indica E 1 A Sinhalese TEXSystem hpx...inSinhalese,etc. This justifies the choice of a common translit- Yannis Haralambous eration scheme for all Indic languages. But why is Abstract a preprocessor necessary, after all? A common characteristic of Indic languages is In this paper a two-fold project is described: the first the fact that the short vowel ‘a’ is inherent to con- part is a generalized preprocessor for Indic scripts (scripts of languages currently spoken in India—except Urdu—, sonants. Vowels are written by adding diacritical Sanskrit and Tibetan), with several kinds of input (LATEX marks (or smaller characters) to consonants. The commands, 7-bit ascii, CSX, ISO/IEC 10646/unicode) beauty (and complexity) of these scripts comes from and TEX output. This utility is written in standard Flex the fact that one needs a special way to denote the (the gnu version of Lex), and hence can be painlessly absence of vowel. There is a notorious diacritic, compiled on any platform. The same input methods are called “vir¯ama”, present in all Indic languages, which used for all Indic languages, so that the user does not is used for this reason. But it seems illogical to add a need to memorize different conventions and commands sign, to specify the absence of a sound. On the con- for each one of them. Moreover, the switch from one lan- trary, it seems much more logical to remove some- guage to another can be done by use of user-defineable thing, and what is done usually is that letters are preprocessor directives. -

Exploring the Linguistic Influence of Tibet in Ladakh(La-Dwags)
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Kobe City University of Foreign Studies Institutional Repository 神戸市外国語大学 学術情報リポジトリ Exploring the linguistic influence of Tibet in Ladakh(La-dwags) 著者 Namgyal Tsetan journal or Journal of Research Institute : Historical publication title Development of the Tibetan Languages volume 49 page range 115-147 year 2013-03-01 URL http://id.nii.ac.jp/1085/00001408/ Creative Commons : 表示 - 非営利 - 改変禁止 http://creativecommons.org/licenses/by-nc-nd/3.0/deed.ja -RXUQDORI5HVHDUFK,QVWLWXWH9RO ([SORULQJ WKH /LQJXLVWLF ,QIOXHQFH RI 7LEHW LQ /DGDNK /DGZDJV 7VHWDQ1DPJ\DO -DZDKDUODO1HKUX8QLYHUVLW\ ,QWURGXFWLRQ /DQJXDJH LVWKHHVVHQFHRINQRZOHGJHDQGWKHOLIHIRUFHRIKXPDQNLQG ,W VHUYHVDVWKHPHGLXP RIFRPPXQLFDWLRQLQVRFLHW\DQGRWKHUVRFLDOGRPDLQV DQG GHWHUPLQHVRQH¶VFXOWXUHLQUHODWLRQ WRWKH ZRUOG$VWKH QRWHG7LEHWDQVFKRODU=KDQJWRQ7HQSD*\DWVR ± VWDWHG³,WLV JRRG WR OHDUQ DOO ODQJXDJHV EXW IRUJHWWLQJ DQG LJQRULQJ RQH¶V RZQ ODQJXDJH LV D VKDPH´ 5HJDUGLQJ WKH7LEHWDQODQJXDJHIRUWXQDWHO\WKHDJHROGLQGLJHQRXV7LEHWDQVFULSW LQZKLFKWKH HQWLUH %XGGKLVW VFULSWXUHV DQG RWKHU UHODWHG OLWHUDWXUH DUH ZULWWHQ KDV EHHQ SUHVHUYHG 7KLV ODQJXDJH LQWURGXFHGGXULQJWKHUHLJQRI(PSHURU6RQJWVHQ*DPSR ± $' LV EDVHG RQWKH,QGLFVFULSW ,QVSLWHRID GHFOLQHLQLWVJUDPPDWLFDOXVDJHRYHU WKHODVWVL[GHFDGHV RZLQJ WRSROLWLFDOXSKHDYDOWKH7LEHWDQODQJXDJHDOVRNQRZQDV%KRWL RU%RGKL UHPDLQV RQHRIWKH PRVWLPSRUWDQWODQJXDJHV RI&HQWUDO$VLD,QDGGLWLRQWKHODQJXDJHKDVEHFRPHZHOO NQRZQIRU LWVVLJQLILFDQWFRQWULEXWLRQWRZDUG WKHGHYHORSPHQWRIKXPDQVRFLHW\ -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

Learning to Serve and to Roam You Could Ask Almost Any Tibetan
CHAPTER FIVE LEARNING TO SERVE AND TO ROAM You could ask almost any Tibetan secondary student in Tibet or the diaspora where the writing system for Tibetan came from and they would tell you the story of King Songtsen Gampo and his seven ministers. While it is unclear if this story recounts actual events, it is the most well known account regarding the origins of the Tibetan writing system and as such is part of Tibetans’ collective memory. Through its retelling to successive generations of Tibetan children, it has helped to shape ideologies of lit- eracy by linking the writing system to Tibetan religion and the Tibetan nation-state. In this version of the origination story, King Songtsen Gampo, the sixth century ruler of Tibet, is credited with having sent seven government min- isters to India with the mission of bringing back a writing system that could be used to translate Buddhist texts into Tibetan. These ministers, however, met with many hardships while in India. Six of the ministers succumbed to illness or disease, leaving Thonmi Sambhota the sole minis- ter to return to Tibet with the writing system they had developed from the Indian Devanagari script. So famous is the story of this perilous journey and successful return that a statue of Thonmi Sambhota today stands in the main courtyard at the Tibetan Academy of Social Sciences in Lhasa. Outside the Library of Tibetan Works and Archives in McLeod Ganj, there is a mural depicting him sitting cross-legged writing the Tibetan alphasyllabary1 on parchment. The story of the Tibetan script, King Songtsen Gampo, and Thonmi Sambhota, however, is more than just a tale of adventure and adversity. -

A Script Independent Approach for Handwritten Bilingual Kannada and Telugu Digits Recognition
IJMI International Journal of Machine Intelligence ISSN: 0975–2927 & E-ISSN: 0975–9166, Volume 3, Issue 3, 2011, pp-155-159 Available online at http://www.bioinfo.in/contents.php?id=31 A SCRIPT INDEPENDENT APPROACH FOR HANDWRITTEN BILINGUAL KANNADA AND TELUGU DIGITS RECOGNITION DHANDRA B.V.1, GURURAJ MUKARAMBI1, MALLIKARJUN HANGARGE2 1Department of P.G. Studies and Research in Computer Science Gulbarga University, Gulbarga, Karnataka. 2Department of Computer Science, Karnatak Arts, Science and Commerce College Bidar, Karnataka. *Corresponding author. E-mail: [email protected],[email protected],[email protected] Received: September 29, 2011; Accepted: November 03, 2011 Abstract- In this paper, handwritten Kannada and Telugu digits recognition system is proposed based on zone features. The digit image is divided into 64 zones. For each zone, pixel density is computed. The KNN and SVM classifiers are employed to classify the Kannada and Telugu handwritten digits independently and achieved average recognition accuracy of 95.50%, 96.22% and 99.83%, 99.80% respectively. For bilingual digit recognition the KNN and SVM classifiers are used and achieved average recognition accuracy of 96.18%, 97.81% respectively. Keywords- OCR, Zone Features, KNN, SVM 1. Introduction recognition of isolated handwritten Kannada numerals Recent advances in Computer technology, made every and have reported the recognition accuracy of 90.50%. organization to implement the automatic processing Drawback of this procedure is that, it is not free from systems for its activities. For example, automatic thinning. U. Pal et al. [11] have proposed zoning and recognition of vehicle numbers, postal zip codes for directional chain code features and considered a feature sorting the mails, ID numbers, processing of bank vector of length 100 for handwritten Kannada numeral cheques etc. -

16-Sanskrit-In-JAPAN.Pdf
A rich literary treasure of Sanskrit literature consisting of dharanis, tantras, sutras and other texts has been kept in Japan for nearly 1400 years. Entry of Sanskrit Buddhist scriptures into Japan was their identification with the central axis of human advance. Buddhism opened up unfathomed spheres of thought as soon as it reached Japan officially in AD 552. Prince Shotoku Taishi himself wrote commentaries and lectured on Saddharmapundarika-sutra, Srimala- devi-simhanada-sutra and Vimala-kirt-nirdesa-sutra. They can be heard in the daily recitation of the Japanese up to the day. Palmleaf manuscripts kept at different temples since olden times comprise of texts which carry immeasurable importance from the viewpoint of Sanskrit philology although some of them are incomplete Sanskrit manuscripts crossed the boundaries of India along with the expansion of Buddhist philosophy, art and thought and reached Japan via Central Asia and China. Thousands of Sanskrit texts were translated into Khotanese, Tokharian, Uigur and Sogdian in Central Asia, on their way to China. With destruction of monastic libraries, most of the Sanskrit literature perished leaving behind a large number of fragments which are discovered by the great explorers who went from Germany, Russia, British India, Sweden and Japan. These excavations have uncovered vast quantities of manuscripts in Sanskrit. Only those manuscripts and texts have survived which were taken to Nepal and Tibet or other parts of Asia. Their translations into Tibetan, Chinese and Mongolian fill the gap, but partly. A number of ancient Sanskrit manuscripts are strewn in the monasteries nestling among high mountains and waterless deserts. -

Devan¯Agar¯I for TEX Version 2.17.1
Devanagar¯ ¯ı for TEX Version 2.17.1 Anshuman Pandey 6 March 2019 Contents 1 Introduction 2 2 Project Information 3 3 Producing Devan¯agar¯ıText with TEX 3 3.1 Macros and Font Definition Files . 3 3.2 Text Delimiters . 4 3.3 Example Input Files . 4 4 Input Encoding 4 4.1 Supplemental Notes . 4 5 The Preprocessor 5 5.1 Preprocessor Directives . 7 5.2 Protecting Text from Conversion . 9 5.3 Embedding Roman Text within Devan¯agar¯ıText . 9 5.4 Breaking Pre-Defined Conjuncts . 9 5.5 Supported LATEX Commands . 9 5.6 Using Custom LATEX Commands . 10 6 Devan¯agar¯ıFonts 10 6.1 Bombay-Style Fonts . 11 6.2 Calcutta-Style Fonts . 11 6.3 Nepali-Style Fonts . 11 6.4 Devan¯agar¯ıPen Fonts . 11 6.5 Default Devan¯agar¯ıFont (LATEX Only) . 12 6.6 PostScript Type 1 . 12 7 Special Topics 12 7.1 Delimiter Scope . 12 7.2 Line Spacing . 13 7.3 Hyphenation . 13 7.4 Captions and Date Formats (LATEX only) . 13 7.5 Customizing the date and captions (LATEX only) . 14 7.6 Using dvnAgrF in Sections and References (LATEX only) . 15 7.7 Devan¯agar¯ıand Arabic Numerals . 15 7.8 Devan¯agar¯ıPage Numbers and Other Counters (LATEX only) . 15 1 7.9 Category Codes . 16 8 Using Devan¯agar¯ıin X E LATEXand luaLATEX 16 8.1 Using Hindi with Polyglossia . 17 9 Using Hindi with babel 18 9.1 Installation . 18 9.2 Usage . 18 9.3 Language attributes . 19 9.3.1 Attribute modernhindi . -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten.