1/12 A. Supplementary Figures and Tables
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Product Sheet Info
Master Clone List for NR-19279 ® Vibrio cholerae Gateway Clone Set, Recombinant in Escherichia coli, Plates 1-46 Catalog No. NR-19279 Table 1: Vibrio cholerae Gateway® Clones, Plate 1 (NR-19679) Clone ID Well ORF Locus ID Symbol Product Accession Position Length Number 174071 A02 367 VC2271 ribD riboflavin-specific deaminase NP_231902.1 174346 A03 336 VC1877 lpxK tetraacyldisaccharide 4`-kinase NP_231511.1 174354 A04 342 VC0953 holA DNA polymerase III, delta subunit NP_230600.1 174115 A05 388 VC2085 sucC succinyl-CoA synthase, beta subunit NP_231717.1 174310 A06 506 VC2400 murC UDP-N-acetylmuramate--alanine ligase NP_232030.1 174523 A07 132 VC0644 rbfA ribosome-binding factor A NP_230293.2 174632 A08 322 VC0681 ribF riboflavin kinase-FMN adenylyltransferase NP_230330.1 174930 A09 433 VC0720 phoR histidine protein kinase PhoR NP_230369.1 174953 A10 206 VC1178 conserved hypothetical protein NP_230823.1 174976 A11 213 VC2358 hypothetical protein NP_231988.1 174898 A12 369 VC0154 trmA tRNA (uracil-5-)-methyltransferase NP_229811.1 174059 B01 73 VC2098 hypothetical protein NP_231730.1 174075 B02 82 VC0561 rpsP ribosomal protein S16 NP_230212.1 174087 B03 378 VC1843 cydB-1 cytochrome d ubiquinol oxidase, subunit II NP_231477.1 174099 B04 383 VC1798 eha eha protein NP_231433.1 174294 B05 494 VC0763 GTP-binding protein NP_230412.1 174311 B06 314 VC2183 prsA ribose-phosphate pyrophosphokinase NP_231814.1 174603 B07 108 VC0675 thyA thymidylate synthase NP_230324.1 174474 B08 466 VC1297 asnS asparaginyl-tRNA synthetase NP_230942.2 174933 B09 198 -
Q 297 Suppl USE
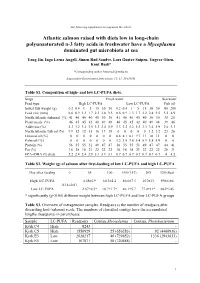
The following supplement accompanies the article Atlantic salmon raised with diets low in long-chain polyunsaturated n-3 fatty acids in freshwater have a Mycoplasma dominated gut microbiota at sea Yang Jin, Inga Leena Angell, Simen Rød Sandve, Lars Gustav Snipen, Yngvar Olsen, Knut Rudi* *Corresponding author: [email protected] Aquaculture Environment Interactions 11: 31–39 (2019) Table S1. Composition of high- and low LC-PUFA diets. Stage Fresh water Sea water Feed type High LC-PUFA Low LC-PUFA Fish oil Initial fish weight (g) 0.2 0.4 1 5 15 30 50 0.2 0.4 1 5 15 30 50 80 200 Feed size (mm) 0.6 0.9 1.3 1.7 2.2 2.8 3.5 0.6 0.9 1.3 1.7 2.2 2.8 3.5 3.5 4.9 North Atlantic fishmeal (%) 41 40 40 40 40 30 30 41 40 40 40 40 30 30 35 25 Plant meals (%) 46 45 45 42 40 49 48 46 45 45 42 40 49 48 39 46 Additives (%) 3.3 3.2 3.2 3.5 3.3 3.4 3.9 3.3 3.2 3.2 3.5 3.3 3.4 3.9 2.6 3.3 North Atlantic fish oil (%) 9.9 12 12 15 16 17 18 0 0 0 0 0 1.2 1.2 23 26 Linseed oil (%) 0 0 0 0 0 0 0 6.8 8.1 8.1 9.7 11 10 11 0 0 Palm oil (%) 0 0 0 0 0 0 0 3.2 3.8 3.8 5.4 5.9 5.8 5.9 0 0 Protein (%) 56 55 55 51 49 47 47 56 55 55 51 49 47 47 44 41 Fat (%) 16 18 18 21 22 22 22 16 18 18 21 22 22 22 28 31 EPA+DHA (% diet) 2.2 2.4 2.4 2.9 3.1 3.1 3.1 0.7 0.7 0.7 0.7 0.7 0.7 0.7 4 4.2 Table S2. -

Exploring the Data Work Organization of the Gene Ontology Shuheng Wu
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2014 Exploring the Data Work Organization of the Gene Ontology Shuheng Wu Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF COMMUNICATION AND INFORMATION EXPLORING THE DATA WORK ORGANIZATION OF THE GENE ONTOLOGY By SHUHENG WU A Dissertation submitted to the School of Information in partial fulfillment of the requirements for the degree of Doctor of Philosophy Degree Awarded: Fall Semester, 2014 Shuheng Wu defended this dissertation on October 24, 2014. The members of the supervisory committee were: Besiki Stvilia Professor Directing Dissertation Henry W. Bass University Representative Corinne L. Jörgensen Committee Member Michelle M. Kazmer Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii I dedicate this dissertation to my beloved mother Peiqiong Ou, and my father, my husband, and those who have supported and helped me. It is all of you who have helped me grow and become who I am today. iii ACKNOWLEDGMENTS My deepest appreciation is owed to my major professor Dr. Besiki Stvilia and his family. Without his advice and help, I cannot even imagine if I could finish my doctoral coursework. Thanks go to him for introducing Activity Theory to me and for developing a theoretical framework that I can use in my current and future studies. Because of working with him, I learned about the beauty of theory and the power of methodology, which will benefit my future research and career. -
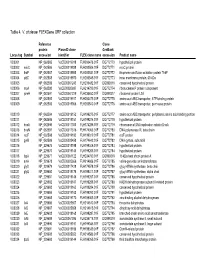
Table 4. V. Cholerae Flexgene ORF Collection
Table 4. V. cholerae FLEXGene ORF collection Reference Clone protein PlasmID clone GenBank Locus tag Symbol accession identifier FLEX clone name accession Product name VC0001 NP_062585 VcCD00019918 FLH200476.01F DQ772770 hypothetical protein VC0002 mioC NP_062586 VcCD00019938 FLH200506.01F DQ772771 mioC protein VC0003 thdF NP_062587 VcCD00019958 FLH200531.01F DQ772772 thiophene and furan oxidation protein ThdF VC0004 yidC NP_062588 VcCD00019970 FLH200545.01F DQ772773 inner membrane protein, 60 kDa VC0005 NP_062589 VcCD00061243 FLH236482.01F DQ899316 conserved hypothetical protein VC0006 rnpA NP_062590 VcCD00025697 FLH214799.01F DQ772774 ribonuclease P protein component VC0007 rpmH NP_062591 VcCD00061229 FLH236450.01F DQ899317 ribosomal protein L34 VC0008 NP_062592 VcCD00019917 FLH200475.01F DQ772775 amino acid ABC transporter, ATP-binding protein VC0009 NP_062593 VcCD00019966 FLH200540.01F DQ772776 amino acid ABC transproter, permease protein VC0010 NP_062594 VcCD00019152 FLH199275.01F DQ772777 amino acid ABC transporter, periplasmic amino acid-binding portion VC0011 NP_062595 VcCD00019151 FLH199274.01F DQ772778 hypothetical protein VC0012 dnaA NP_062596 VcCD00017363 FLH174286.01F DQ772779 chromosomal DNA replication initiator DnaA VC0013 dnaN NP_062597 VcCD00017316 FLH174063.01F DQ772780 DNA polymerase III, beta chain VC0014 recF NP_062598 VcCD00019182 FLH199319.01F DQ772781 recF protein VC0015 gyrB NP_062599 VcCD00025458 FLH174642.01F DQ772782 DNA gyrase, subunit B VC0016 NP_229675 VcCD00019198 FLH199346.01F DQ772783 hypothetical protein -

Product Information Sheet for NR-19718
Product Information Sheet for NR-19718 Vibrio cholerae Gateway® Clone Set, Growth Conditions: Media: Recombinant in Escherichia coli, Plate 40 LB broth or agar containing 50 µg/mL kanamycin Incubation: Catalog No. NR-19718 Temperature: E. coli, strain DH10B-T1 clones should be This reagent is the tangible property of the U.S. Government. grown at 37°C. Atmosphere: Aerobic For research use only. Not for human use. Propagation: 1. Scrape top of frozen well with a pipette tip and streak onto Contributor: agar plate. Pathogen Functional Genomics Resource Center at the J. 2. Incubate the plates at 37°C for 1 day. Craig Venter Institute Citation: Manufacturer: Acknowledgment for publications should read “The following BEI Resources reagent was obtained through BEI Resources, NIAID, NIH: ® Vibrio cholerae Gateway Clone Set, Recombinant in Product Description: Escherichia coli, Plate 40, NR-19718.” Production in the 96-well format has increased risk of cross- contamination between adjacent wells. Individual clones Biosafety Level: 1 should be purified (e.g. single colony isolation and purification Appropriate safety procedures should always be used with this using good microbiological practices) and sequence-verified material. Laboratory safety is discussed in the following prior to use. BEI Resources does not confirm or validate publication: U.S. Department of Health and Human Services, individual mutants provided by the contributor. Public Health Service, Centers for Disease Control and Prevention, and National Institutes of Health. Biosafety in The Vibrio cholerae (V. cholerae) Gateway® clone set consists Microbiological and Biomedical Laboratories. 5th ed. of 46 plates which contain 3813 sequence validated clones Washington, DC: U.S. -

ABSTRACT BOZDAG, AHMET. Investigation of Methanol and Formaldehyde Metabolism in Bacillus Methanolicus
ABSTRACT BOZDAG, AHMET. Investigation of Methanol and Formaldehyde Metabolism in Bacillus methanolicus.(Under the direction of Prof. Michael C. Flickinger). Bacillus methanolicus is a Gram-positive aerobic methylotroph growing optimally at 50-53 °C. Wild-type strains of B. methanolicus have been reported to secrete 58 g/l of L- glutamate in fed-batch cultures. Mutants of B. methanolicus created via classical mutangenesis can secrete 37 g/l of L-lysine, at 50 °C. The genes required for methylotrophyin B. methanolicus are encoded by an endogenous plasmid, pBM19 in strain MGA3, except for hexulose phosphate synthase (hps) and phosphohexuloisomerase (phi) which are encoded on the chromosome.It is a promising candidate for industrial production of chemical intermediates or amino acids from methanol. B. methanolicus employs the ribulose monophospate (RuMP) pathway to assimilate the carbon derived from the methanol, but enzymes that dissimilate carbon are not identified, although formaldehyde and formate were identified as intermediates by 13C NMR. It is important to understand how methanol is oxidized to formaldehyde and then, to formate and carbon dioxide. This study aims to elucidate the methanol dissimilation pathway of B. methanolicus. Growth rates of B. methanolicus MGA3 were assessed on methanol, mannitol, and glucose as a substrate. B. methanolicus achieved maximum growth rate, µmax, when growing on 25 mM methanol, 0.65±0.007 h-1, and it gradually decreased to 0.231±0.004 h-1 at 2Mmethanol concentration which demonstrates substrate inhibition. The maximum growth rates (µmax) of B. methanolicus MGA3 on mannitol and glucose are 0.532±0.002 and 0.336±0.003 h-1, respectively. -

Supplemental Table S1: Comparison of the Deleted Genes in the Genome-Reduced Strains
Supplemental Table S1: Comparison of the deleted genes in the genome-reduced strains Legend 1 Locus tag according to the reference genome sequence of B. subtilis 168 (NC_000964) Genes highlighted in blue have been deleted from the respective strains Genes highlighted in green have been inserted into the indicated strain, they are present in all following strains Regions highlighted in red could not be deleted as a unit Regions highlighted in orange were not deleted in the genome-reduced strains since their deletion resulted in severe growth defects Gene BSU_number 1 Function ∆6 IIG-Bs27-47-24 PG10 PS38 dnaA BSU00010 replication initiation protein dnaN BSU00020 DNA polymerase III (beta subunit), beta clamp yaaA BSU00030 unknown recF BSU00040 repair, recombination remB BSU00050 involved in the activation of biofilm matrix biosynthetic operons gyrB BSU00060 DNA-Gyrase (subunit B) gyrA BSU00070 DNA-Gyrase (subunit A) rrnO-16S- trnO-Ala- trnO-Ile- rrnO-23S- rrnO-5S yaaC BSU00080 unknown guaB BSU00090 IMP dehydrogenase dacA BSU00100 penicillin-binding protein 5*, D-alanyl-D-alanine carboxypeptidase pdxS BSU00110 pyridoxal-5'-phosphate synthase (synthase domain) pdxT BSU00120 pyridoxal-5'-phosphate synthase (glutaminase domain) serS BSU00130 seryl-tRNA-synthetase trnSL-Ser1 dck BSU00140 deoxyadenosin/deoxycytidine kinase dgk BSU00150 deoxyguanosine kinase yaaH BSU00160 general stress protein, survival of ethanol stress, SafA-dependent spore coat yaaI BSU00170 general stress protein, similar to isochorismatase yaaJ BSU00180 tRNA specific adenosine -

12) United States Patent (10
US007635572B2 (12) UnitedO States Patent (10) Patent No.: US 7,635,572 B2 Zhou et al. (45) Date of Patent: Dec. 22, 2009 (54) METHODS FOR CONDUCTING ASSAYS FOR 5,506,121 A 4/1996 Skerra et al. ENZYME ACTIVITY ON PROTEIN 5,510,270 A 4/1996 Fodor et al. MICROARRAYS 5,512,492 A 4/1996 Herron et al. 5,516,635 A 5/1996 Ekins et al. (75) Inventors: Fang X. Zhou, New Haven, CT (US); 5,532,128 A 7/1996 Eggers Barry Schweitzer, Cheshire, CT (US) 5,538,897 A 7/1996 Yates, III et al. s s 5,541,070 A 7/1996 Kauvar (73) Assignee: Life Technologies Corporation, .. S.E. al Carlsbad, CA (US) 5,585,069 A 12/1996 Zanzucchi et al. 5,585,639 A 12/1996 Dorsel et al. (*) Notice: Subject to any disclaimer, the term of this 5,593,838 A 1/1997 Zanzucchi et al. patent is extended or adjusted under 35 5,605,662 A 2f1997 Heller et al. U.S.C. 154(b) by 0 days. 5,620,850 A 4/1997 Bamdad et al. 5,624,711 A 4/1997 Sundberg et al. (21) Appl. No.: 10/865,431 5,627,369 A 5/1997 Vestal et al. 5,629,213 A 5/1997 Kornguth et al. (22) Filed: Jun. 9, 2004 (Continued) (65) Prior Publication Data FOREIGN PATENT DOCUMENTS US 2005/O118665 A1 Jun. 2, 2005 EP 596421 10, 1993 EP 0619321 12/1994 (51) Int. Cl. EP O664452 7, 1995 CI2O 1/50 (2006.01) EP O818467 1, 1998 (52) U.S. -

Clostridium Thermocellum
Virginia Commonwealth University VCU Scholars Compass Theses and Dissertations Graduate School 2011 Model-Guided Systems Metabolic Engineering of Clostridium thermocellum Christopher Gowen Virginia Commonwealth University Follow this and additional works at: https://scholarscompass.vcu.edu/etd Part of the Engineering Commons © The Author Downloaded from https://scholarscompass.vcu.edu/etd/2529 This Dissertation is brought to you for free and open access by the Graduate School at VCU Scholars Compass. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of VCU Scholars Compass. For more information, please contact [email protected]. ©Christopher M Gowen 2011 All rights reserved. MODEL-GUIDED SYSTEMS METABOLIC ENGINEERING OF CLOSTRIDIUM THERMOCELLUM A DISSERTATION SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY AT VIRGINIA COMMONWEALTH UNIVERSITY. BY CHRISTOPHER MARK GOWEN M.S. ENGINEERING, VIRGINIA COMMONWEALTH UNIVERSITY, 2008 B.S. BIOSYSTEMS ENGINEERING, CLEMSON UNIVERSITY, 2006 DIRECTOR: STEPHEN S. FONG, PH.D. ASSISTANT PROFESSOR, CHEMICAL & LIFE SCIENCE ENGINEERING VIRGINIA COMMONWEALTH UNIVERSITY RICHMOND, VIRGINIA MAY, 2011 ii ACKNOWLEDGEMENT For Grandy. "Can't never did do nothin'" I have many people to whom I am indebted for incredible love, support, and guidance. To begin, I would like to thank my advisor, Dr. Fong, for his guidance, instruction, and flexibility. Few educators can balance so well the sometimes competing drives for impactful research and scientific education, and I am grateful for the patience and flexibility he shows in letting his graduate students find their own independence. I would also like to thank Dr. Sherry Baldwin, Dr. Paul Brooks, Dr. Mark McHugh, Dr. -

(12) Patent Application Publication (10) Pub. No.: US 2005/0009771 A1 Levanon Et Al
US 2005OOO9771A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2005/0009771 A1 LeVanOn et al. (43) Pub. Date: Jan. 13, 2005 (54) METHODS AND SYSTEMS FOR (22) Filed: Jan. 27, 2004 IDENTIFYING NATURALLY OCCURRING ANTISENSE TRANSCRIPTS AND METHODS, Related U.S. Application Data KITS AND ARRAYS UTILIZING SAME (63) Continuation-in-part of application No. 10/441,281, (76) Inventors: Erez. Levanon, Petach Tikva (IL); filed on May 20, 2003. Jeanne Bernstein, Kfar Yona (IL); Sarah Pollock, Tel Aviv (IL); Alex Publication Classification Diber, Herzlia (IL); Zurit Levine, Herzlia (IL); Sergey Nemzer, Ramat 51)1) Int. Cl.C.7 ............................ A61K 48700 ; C12O 1/68; Gan (IL); Vladimir Grebinsky, G06F 19/00; G01N 33/48; Highland Park, NJ (US); Hanqing Xie, GO1N 33/50 Lambertville, NJ (US); Brian Meloon, (52) U.S. Cl. .................................... 514/44; 435/6; 702/20 Plainsboro, NJ (US); Andrew Olson, Westfield, NJ (US); Dvir Dahary, Tel Aviv (IL); Yossi Cohen, Woking (GB); (57) ABSTRACT Avi Shoshan, Kiryat Gat (IL); Shira Walach, Hod Hasharon (IL); Alon A method of identifying putative naturally occurring anti Wasserman, New York, NY (US); Sense transcripts is provided. The method is effected by (a) Rami Khosravi, Herzlia (IL); Galit computationally aligning a first database including Sense Rotman, Herzlia (IL) oriented polynucleotide Sequences with a Second database Correspondence Address: including expressed polynucleotide Sequences; and (b) iden G.E. EHRLICH (1995) LTD. tifying expressed polynucleotide Sequences from the Second c/o ANTHONY CASTORINA database being capable of forming a duplex with at least one 2001 JEFFERSON DAVIS HIGHWAY, SUITE Sense-oriented polynucleotide Sequence of the first database, 207 thereby identifying putative naturally occurring antisense ARLINGTON, VA 2.2202 (US) transcripts. -

The Antimicrobial Mechanism of Action of 3,4-Methylenedioxy-Βββ-Nitropropene
The antimicrobial mechanism of action of 3,4-methylenedioxy-βββ-nitropropene A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Kylie Suzanne White B. App. Sci. School of Applied Science Science Engineering and Technology Portfolio RMIT UNIVERSITY March 2008 Declaration I certify that except where due acknowledgement has been made, the work is that of the author alone; the work has not been submitted previously, in whole or in part, to qualify for any other academic award; the content of the thesis is the result of work which has been carried out since the official commencement date of the approved research program; and, any editorial work, paid or unpaid, carried out by a third party is acknowledged. __________________ Kylie Suzanne White __________________ ii Acknowledements I would firstly like to thank my supervisors Gina Nicoletti and Robert Borland for their confidence, support and invaluable guidance throughout. In regards to the chlamydia work I would like to thank Robert Alexander for his generosity with his time, for use of the lab and for providing and maintaining the C. trachomatis clinical strain and McCoy cell monolayers. Thankyou to everyone in the lab RCH for making me feel welcome during my visits. I would also like to thank those in the department who have helped me along the way, particularly Viraj Perera for use of the Campylobacter mutant and Tien Huynh for help with quantitative PCR. Thanks also to Priya, Nitin, Eddie and Stephane for their suggestions for the Microarray work. A big thankyou to Thu for her friendship, making sure I had enough media and being there to tend to cultures when I could not. -

1471-2164-6-174-S4.PDF (299.1Kb)
Sup_Table_2. Comparison of the whole genomes in Fig. 3A. Segment 1- Conserved in Bm, Bp, and Bt to Bp to Bt Gene Description % length % identity % length % identity BMA0001 chromosomal replication initiator protein DnaA 100 99 100 96 BMA0002 DNA polymerase III, beta subunit 100 100 100 99 BMA0003 DNA gyrase, B subunit 100 100 100 99 BMA0006 carboxymuconolactone decarboxylase family protein 100 98 100 99 BMA0010 hypothetical protein 100 99 100 92 BMA0011 hypothetical protein 100 100 100 91 BMA0014.1 hypothetical protein 100 99 96 94 BMA0018 hypothetical protein 100 99 100 95 BMA0019 FHA domain protein 100 100 100 94 BMA0020 protein kinase domain protein 100 99 100 90 BMA0023 conserved hypothetical protein 100 99 100 90 BMA0024 aldolase, class II 100 98 100 91 BMA0027 polysaccharide biosynthesis family protein 100 100 100 96 BMA0028 glycosyl transferase, group 1 family protein 100 99 100 94 BMA0029 mannose-1-phosphate guanylyltransferase/mannose-6-phosphate isomerase 100 99 100 92 BMA0030 ElaA family protein 100 99 100 90 BMA0032 glycosyl transferase, group 1 family protein 100 99 100 93 BMA0037 sigma-54 dependent transcriptional regulator 100 99 100 97 BMA0039 beta-mannosidase-related protein 100 99 100 91 BMA0040 conserved hypothetical protein 100 100 100 94 BMA0041 conserved hypothetical protein 100 99 100 95 BMA0042 acyl-CoA dehydrogenase domain protein 100 99 100 96 BMA0043 acyl carrier protein, putative 100 100 100 95 BMA0044 conserved hypothetical protein 100 99 100 96 BMA0045 conserved hypothetical protein 100 100 100 98 BMA0046