(12) Patent Application Publication (10) Pub. No.: US 2007/0083334 A1 Mintz Et Al
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Review Article Functional Subunits of Eukaryotic Chaperonin CCT/Tric in Protein Folding
SAGE-Hindawi Access to Research Journal of Amino Acids Volume 2011, Article ID 843206, 16 pages doi:10.4061/2011/843206 Review Article Functional Subunits of Eukaryotic Chaperonin CCT/TRiC in Protein Folding M. Anaul Kabir,1 Wasim Uddin,1 Aswathy Narayanan,1 Praveen Kumar Reddy,1 M. Aman Jairajpuri,2 Fred Sherman,3 and Zulfiqar Ahmad4 1 Molecular Genetics Laboratory, School of Biotechnology, National Institute of Technology Calicut, Kerala 673601, India 2 Department of Biosciences, Jamia Millia Islamia, Jamia Nagar, New Delhi 110025, India 3 Department of Biochemistry and Biophysics, University of Rochester Medical Center, NY 14642, USA 4 Department of Biology, Alabama A&M University, Normal, AL 35762, USA Correspondence should be addressed to M. Anaul Kabir, [email protected] Received 15 February 2011; Accepted 5 April 2011 Academic Editor: Shandar Ahmad Copyright © 2011 M. Anaul Kabir et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Molecular chaperones are a class of proteins responsible for proper folding of a large number of polypeptides in both prokaryotic and eukaryotic cells. Newly synthesized polypeptides are prone to nonspecific interactions, and many of them make toxic aggregates in absence of chaperones. The eukaryotic chaperonin CCT is a large, multisubunit, cylindrical structure having two identical rings stacked back to back. Each ring is composed of eight different but similar subunits and each subunit has three distinct domains. CCT assists folding of actin, tubulin, and numerous other cellular proteins in an ATP-dependent manner. -

Leeds Thesis Template
Determining the Link Between Genome Integrity and Seed Quality Robbie Michael Gillett Submitted in accordance with the requirements for the degree of Doctor of Philosophy The University of Leeds Faculty of Biological Sciences School of Biology January, 2017 - ii - The candidate confirms that the work submitted is his own and that appropriate credit has been given where reference has been made to the work of others. This copy has been supplied on the understanding that it is copyright material and that no quotation from the thesis may be published without proper acknowledgement. The right of Robbie M. Gillett to be identified as Author of this work has been asserted by him in accordance with the Copyright, Designs and Patents Act 1988. © 2016 The University of Leeds and Robbie Michael Gillett - iii - Acknowledgements I would like to thank my supervisor Dr Christopher West and co-supervisor Dr. Wanda Waterworth for all of their support, expertise and incredible patience and for always being available to help. I would like to thank Aaron Barrett, James Cooper, Valérie Tennant, and all my other friends at university for their help throughout my PhD. Thanks to Vince Agboh and Grace Hoysteed for their combined disjointedness and to Ashley Hines, Daniel Johnston and Darryl Ransom for being a source of entertainment for many years. I would like to thank my international Sona friends, Lindsay Hoffman and Jan Maarten ten Katen. Finally unreserved thanks to my loving parents who supported me throughout the tough times and to my Grandma and Granddad, Jean and Dennis McCarthy, who were always very vocal with their love, support and pride. -

The Microbiota-Produced N-Formyl Peptide Fmlf Promotes Obesity-Induced Glucose
Page 1 of 230 Diabetes Title: The microbiota-produced N-formyl peptide fMLF promotes obesity-induced glucose intolerance Joshua Wollam1, Matthew Riopel1, Yong-Jiang Xu1,2, Andrew M. F. Johnson1, Jachelle M. Ofrecio1, Wei Ying1, Dalila El Ouarrat1, Luisa S. Chan3, Andrew W. Han3, Nadir A. Mahmood3, Caitlin N. Ryan3, Yun Sok Lee1, Jeramie D. Watrous1,2, Mahendra D. Chordia4, Dongfeng Pan4, Mohit Jain1,2, Jerrold M. Olefsky1 * Affiliations: 1 Division of Endocrinology & Metabolism, Department of Medicine, University of California, San Diego, La Jolla, California, USA. 2 Department of Pharmacology, University of California, San Diego, La Jolla, California, USA. 3 Second Genome, Inc., South San Francisco, California, USA. 4 Department of Radiology and Medical Imaging, University of Virginia, Charlottesville, VA, USA. * Correspondence to: 858-534-2230, [email protected] Word Count: 4749 Figures: 6 Supplemental Figures: 11 Supplemental Tables: 5 1 Diabetes Publish Ahead of Print, published online April 22, 2019 Diabetes Page 2 of 230 ABSTRACT The composition of the gastrointestinal (GI) microbiota and associated metabolites changes dramatically with diet and the development of obesity. Although many correlations have been described, specific mechanistic links between these changes and glucose homeostasis remain to be defined. Here we show that blood and intestinal levels of the microbiota-produced N-formyl peptide, formyl-methionyl-leucyl-phenylalanine (fMLF), are elevated in high fat diet (HFD)- induced obese mice. Genetic or pharmacological inhibition of the N-formyl peptide receptor Fpr1 leads to increased insulin levels and improved glucose tolerance, dependent upon glucagon- like peptide-1 (GLP-1). Obese Fpr1-knockout (Fpr1-KO) mice also display an altered microbiome, exemplifying the dynamic relationship between host metabolism and microbiota. -

Style Specifications Thesis
Structural Studies of Salvage Enzymes in Nucleotide Biosynthesis Martin Welin Faculty of Natural Resources and Agricultural Sciences Department of Molecular Biology Uppsala Doctoral thesis Swedish University of Agricultural Sciences Uppsala 2007 Acta Universitatis Agriculturae Sueciae 2007:21 ISSN 1652-6880 ISBN 978-91-576-7320-6 © 2007 Martin Welin, Uppsala Tryck: SLU Service/Repro, Uppsala 2007 Abstract Welin, M., 2007. Structural Studies of Salvage Enzymes in Nucleotide Biosynthesis. Doctoral dissertation. ISSN 1652-6880, ISBN 978-91-576-7320-6 There are two routes to produce deoxyribonucleoside triphosphates (dNTPs) precursors for DNA synthesis, the de novo and the salvage pathways. Deoxyribonucleoside kinases (dNKs) perform the initial phosphorylation of deoxyribonucleosides (dNs). Furthermore, they can act as activators for several medically important nucleoside analogs (NAs) for treatment against cancer or viral infections. Several disorders are characterized by mutations in enzymes involved in the nucleotide biosynthesis, such as Lesch-Nyhan disease that is linked to hypoxanthine guanine phosphoribosyltransferase (HPRT). In this thesis, the structures of human thymidine kinase 1 (TK1), a mycoplasmic deoxyadenosine kinase (Mm-dAK), and phosphoribosyltransferase domain containing 1 (PRTFDC1) are presented. Furthermore, a structural investigation of Drosophila melanogaster dNK (Dm-dNK) N64D mutant was carried out. The obtained structural information reveals the basis for substrate specificity for TKs and the bacterial dAKs. The TK1 revealed a structure different from other known dNK structures, containing an α/β domain similar to the RecA-F1ATPase family, and a lasso-like domain stabilized by a structural zinc. The Mm-dAK structure was similar to its human counterparts, but with some alterations in the proximity of the active site. -

Product Sheet Info
Master Clone List for NR-19279 ® Vibrio cholerae Gateway Clone Set, Recombinant in Escherichia coli, Plates 1-46 Catalog No. NR-19279 Table 1: Vibrio cholerae Gateway® Clones, Plate 1 (NR-19679) Clone ID Well ORF Locus ID Symbol Product Accession Position Length Number 174071 A02 367 VC2271 ribD riboflavin-specific deaminase NP_231902.1 174346 A03 336 VC1877 lpxK tetraacyldisaccharide 4`-kinase NP_231511.1 174354 A04 342 VC0953 holA DNA polymerase III, delta subunit NP_230600.1 174115 A05 388 VC2085 sucC succinyl-CoA synthase, beta subunit NP_231717.1 174310 A06 506 VC2400 murC UDP-N-acetylmuramate--alanine ligase NP_232030.1 174523 A07 132 VC0644 rbfA ribosome-binding factor A NP_230293.2 174632 A08 322 VC0681 ribF riboflavin kinase-FMN adenylyltransferase NP_230330.1 174930 A09 433 VC0720 phoR histidine protein kinase PhoR NP_230369.1 174953 A10 206 VC1178 conserved hypothetical protein NP_230823.1 174976 A11 213 VC2358 hypothetical protein NP_231988.1 174898 A12 369 VC0154 trmA tRNA (uracil-5-)-methyltransferase NP_229811.1 174059 B01 73 VC2098 hypothetical protein NP_231730.1 174075 B02 82 VC0561 rpsP ribosomal protein S16 NP_230212.1 174087 B03 378 VC1843 cydB-1 cytochrome d ubiquinol oxidase, subunit II NP_231477.1 174099 B04 383 VC1798 eha eha protein NP_231433.1 174294 B05 494 VC0763 GTP-binding protein NP_230412.1 174311 B06 314 VC2183 prsA ribose-phosphate pyrophosphokinase NP_231814.1 174603 B07 108 VC0675 thyA thymidylate synthase NP_230324.1 174474 B08 466 VC1297 asnS asparaginyl-tRNA synthetase NP_230942.2 174933 B09 198 -

Biochemical Basis for Differential Deoxyadenosine Toxicity To
Proc. Natl. Acad. Sci. USA Vol. 76, No. 5, pp. 2434-2437, May 1979 Medical Sciences Biochemical basis for differential deoxyadenosine toxicity to T and B lymphoblasts: Role for 5'-nucleotidase (deoxyadenosine kinase/deoxyadenylate kinase/immunodeficiency) ROBERT L. WORTMANN, BEVERLY S. MITCHELL, N. LAWRENCE EDWARDS, AND IRVING H. Fox Human Purine Research Center, Departments of Internal Medicine and Biological Chemistry, Clinical Research Center, University of Michigan Medical Center, Ann Arbor, Michigan 48109 Communicated by James B. Wyngaarden, March 7, 1979 ABSTRACT Deoxyadenosine metabolism was investigated tained from Calbiochem. Erythro-9-[3-(2-hydroxynonyl)]- in cultured human cells to elucidate the biochemical basis for adenine (EHNA) was a gift from G. B. Elion of Burroughs the sensitivity of T lymphoblasts and the resistance of B lym- Wellcome (Research Triangle Park, NC). Horse serum was phoblasts to deoxyadenosine toxicity. T lymphoblasts have a 20- to 45-fold greater capacity to synthesize deoxyadenosine nu- obtained from Flow Laboratories (Rockville, MD), and Eagle's cleotides than B lymphoblasts at deoxyadenosine concentrations minimal essential medium was purchased from GIBCO. From of 50-300 ,uM. During the synthesis of dATP, T lymphoblasts Amersham/Searle, [U-14C]deoxyadenosine (505 mCi/mmol), accumulate large quantities of dADP, whereas B lymphoblasts [8-14C]hypoxanthine (52.5 mCi/mmol), and [U-14C]deoxy- do not accumu ate dADP. Enzymes affecting deoxyadenosine adenosine monophosphate (574 mCi/mmol) were purchased; nucleotide synthesis were assayed in these cells. No substantial and, from ICN, [8-14C]adenosine monophosphate (34.4 mCi/ differences were evident in activities of deoxyadenosine kinase (ATP: deoxyadenosine 5'-phosphotransferase, EC 2.7.1.76) or mmol) was purchased (1 Ci = 3.7 X 1010 becquerels). -

Structure, Hormonal Regulation and Chromosomal Location of Genes Encoding Barley (1-+A)-B-Xylan Endohydrolases
l;),, (!. s,9 47 STRUCTURE, HORMONAL RB,GULA CHROMOSOMAL LOCATION OF GENES ENCODING BARLEY (1+4)- p-XYLAI\ ENDOHYDROLASES by MITALI BANIK, B.Sc. (Hons.), M.Sc. A thesis submitted in fulfillment of the requirement for the degree of Doctor of Philosophy Department of Plant Science, Division of Agricultural and Natural Resource Sciences, TheUniversity of Adelaide, Waite Campus, Glen Osmond,5064 Australia October, 1996 1l STATEMENT OF AUTHORSHIP Except where reference is made in the text of the thesis, this thesis contains no material published elsewhere or extracted in whole or in part from a thesis presented by me for another degree or diploma. No other person's work has been used without due acknowledgment in the main text of the thesis. This thesis has not been submitted for the award of any other degree or diploma in any other tertiary institution. MITALI BANIK October, 1996 o lll ACKNOWLBDGMENTS I would like to express my deepest sense of gratitude and indebtedness to my supervisor, Professor Geoffrey B. Fincher, Head of Department, Plant Science, University of Adelaide for his constant guidance, infinite patience, encouragement and invaluable suggestions throughout my studies. I wish to express my immense gratitude to Professor Derek Bewley, Department of Botany, University of Guelph, Canada for his constructive criticism during the preparation of this thesis. I am also grateful to Drs. Frank Gubler and John V. Jacobsen, CSIRO Division of Plant Industry, Canberra for providing a cDNA library. I wish to thank Dr. Simon Robinson, Senior Scientist, CSIRO for his constructive suggestions throughout the duration of my research project. -

Supplementary Information
Supplementary information (a) (b) Figure S1. Resistant (a) and sensitive (b) gene scores plotted against subsystems involved in cell regulation. The small circles represent the individual hits and the large circles represent the mean of each subsystem. Each individual score signifies the mean of 12 trials – three biological and four technical. The p-value was calculated as a two-tailed t-test and significance was determined using the Benjamini-Hochberg procedure; false discovery rate was selected to be 0.1. Plots constructed using Pathway Tools, Omics Dashboard. Figure S2. Connectivity map displaying the predicted functional associations between the silver-resistant gene hits; disconnected gene hits not shown. The thicknesses of the lines indicate the degree of confidence prediction for the given interaction, based on fusion, co-occurrence, experimental and co-expression data. Figure produced using STRING (version 10.5) and a medium confidence score (approximate probability) of 0.4. Figure S3. Connectivity map displaying the predicted functional associations between the silver-sensitive gene hits; disconnected gene hits not shown. The thicknesses of the lines indicate the degree of confidence prediction for the given interaction, based on fusion, co-occurrence, experimental and co-expression data. Figure produced using STRING (version 10.5) and a medium confidence score (approximate probability) of 0.4. Figure S4. Metabolic overview of the pathways in Escherichia coli. The pathways involved in silver-resistance are coloured according to respective normalized score. Each individual score represents the mean of 12 trials – three biological and four technical. Amino acid – upward pointing triangle, carbohydrate – square, proteins – diamond, purines – vertical ellipse, cofactor – downward pointing triangle, tRNA – tee, and other – circle. -
The Metabolic Building Blocks of a Minimal Cell Supplementary
The metabolic building blocks of a minimal cell Mariana Reyes-Prieto, Rosario Gil, Mercè Llabrés, Pere Palmer and Andrés Moya Supplementary material. Table S1. List of enzymes and reactions modified from Gabaldon et. al. (2007). n.i.: non identified. E.C. Name Reaction Gil et. al. 2004 Glass et. al. 2006 number 2.7.1.69 phosphotransferase system glc + pep → g6p + pyr PTS MG041, 069, 429 5.3.1.9 glucose-6-phosphate isomerase g6p ↔ f6p PGI MG111 2.7.1.11 6-phosphofructokinase f6p + atp → fbp + adp PFK MG215 4.1.2.13 fructose-1,6-bisphosphate aldolase fbp ↔ gdp + dhp FBA MG023 5.3.1.1 triose-phosphate isomerase gdp ↔ dhp TPI MG431 glyceraldehyde-3-phosphate gdp + nad + p ↔ bpg + 1.2.1.12 GAP MG301 dehydrogenase nadh 2.7.2.3 phosphoglycerate kinase bpg + adp ↔ 3pg + atp PGK MG300 5.4.2.1 phosphoglycerate mutase 3pg ↔ 2pg GPM MG430 4.2.1.11 enolase 2pg ↔ pep ENO MG407 2.7.1.40 pyruvate kinase pep + adp → pyr + atp PYK MG216 1.1.1.27 lactate dehydrogenase pyr + nadh ↔ lac + nad LDH MG460 1.1.1.94 sn-glycerol-3-phosphate dehydrogenase dhp + nadh → g3p + nad GPS n.i. 2.3.1.15 sn-glycerol-3-phosphate acyltransferase g3p + pal → mag PLSb n.i. 2.3.1.51 1-acyl-sn-glycerol-3-phosphate mag + pal → dag PLSc MG212 acyltransferase 2.7.7.41 phosphatidate cytidyltransferase dag + ctp → cdp-dag + pp CDS MG437 cdp-dag + ser → pser + 2.7.8.8 phosphatidylserine synthase PSS n.i. cmp 4.1.1.65 phosphatidylserine decarboxylase pser → peta PSD n.i. -
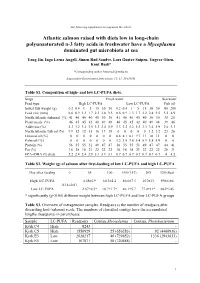
Q 297 Suppl USE
The following supplement accompanies the article Atlantic salmon raised with diets low in long-chain polyunsaturated n-3 fatty acids in freshwater have a Mycoplasma dominated gut microbiota at sea Yang Jin, Inga Leena Angell, Simen Rød Sandve, Lars Gustav Snipen, Yngvar Olsen, Knut Rudi* *Corresponding author: [email protected] Aquaculture Environment Interactions 11: 31–39 (2019) Table S1. Composition of high- and low LC-PUFA diets. Stage Fresh water Sea water Feed type High LC-PUFA Low LC-PUFA Fish oil Initial fish weight (g) 0.2 0.4 1 5 15 30 50 0.2 0.4 1 5 15 30 50 80 200 Feed size (mm) 0.6 0.9 1.3 1.7 2.2 2.8 3.5 0.6 0.9 1.3 1.7 2.2 2.8 3.5 3.5 4.9 North Atlantic fishmeal (%) 41 40 40 40 40 30 30 41 40 40 40 40 30 30 35 25 Plant meals (%) 46 45 45 42 40 49 48 46 45 45 42 40 49 48 39 46 Additives (%) 3.3 3.2 3.2 3.5 3.3 3.4 3.9 3.3 3.2 3.2 3.5 3.3 3.4 3.9 2.6 3.3 North Atlantic fish oil (%) 9.9 12 12 15 16 17 18 0 0 0 0 0 1.2 1.2 23 26 Linseed oil (%) 0 0 0 0 0 0 0 6.8 8.1 8.1 9.7 11 10 11 0 0 Palm oil (%) 0 0 0 0 0 0 0 3.2 3.8 3.8 5.4 5.9 5.8 5.9 0 0 Protein (%) 56 55 55 51 49 47 47 56 55 55 51 49 47 47 44 41 Fat (%) 16 18 18 21 22 22 22 16 18 18 21 22 22 22 28 31 EPA+DHA (% diet) 2.2 2.4 2.4 2.9 3.1 3.1 3.1 0.7 0.7 0.7 0.7 0.7 0.7 0.7 4 4.2 Table S2. -

Exploring the Data Work Organization of the Gene Ontology Shuheng Wu
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2014 Exploring the Data Work Organization of the Gene Ontology Shuheng Wu Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF COMMUNICATION AND INFORMATION EXPLORING THE DATA WORK ORGANIZATION OF THE GENE ONTOLOGY By SHUHENG WU A Dissertation submitted to the School of Information in partial fulfillment of the requirements for the degree of Doctor of Philosophy Degree Awarded: Fall Semester, 2014 Shuheng Wu defended this dissertation on October 24, 2014. The members of the supervisory committee were: Besiki Stvilia Professor Directing Dissertation Henry W. Bass University Representative Corinne L. Jörgensen Committee Member Michelle M. Kazmer Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii I dedicate this dissertation to my beloved mother Peiqiong Ou, and my father, my husband, and those who have supported and helped me. It is all of you who have helped me grow and become who I am today. iii ACKNOWLEDGMENTS My deepest appreciation is owed to my major professor Dr. Besiki Stvilia and his family. Without his advice and help, I cannot even imagine if I could finish my doctoral coursework. Thanks go to him for introducing Activity Theory to me and for developing a theoretical framework that I can use in my current and future studies. Because of working with him, I learned about the beauty of theory and the power of methodology, which will benefit my future research and career. -

The Chaperonin Folding Machine
Review TRENDS in Biochemical Sciences Vol.27 No.12 December 2002 627 32 He, B. et al. (1998) Glycogen synthase kinase 3β DNA damage-induced phosphorylation. Science regulates transcriptional activity. Mol. Cell 6, and extracellular signal-regulated kinase 292, 1910–1915 539–550 inactivate heat shock transcription factor 1 by 43 Waterman, M.J. et al. (1998) ATM-dependent 53 Beals, C.R. et al. (1997) Nuclear localization of facilitating the disappearance of transcriptionally activation of p53 involves dephosphorylation and NF-ATc by a calcineurin-dependent, active granules after heat shock. Mol. Cell. Biol. association with 14-3-3 proteins. Nat. Genet. 19, cyclosporin-sensitive intramolecular interaction. 18, 6624–6633 175–178 Genes Dev. 11, 824–834 33 Xia, W. et al. (1998) Transcriptional activation of 44 Stavridi, E.S. et al. (2001) Substitutions that 54 Porter, C.M. et al. (2000) Identification of amino heat shock factor HSF1 probed by phosphopeptide compromise the ionizing radiation-induced acid residues and protein kinases involved in the analysis of factor 32P-labeled in vivo. J. Biol. association of p53 with 14-3-3 proteins also regulation of NFATc subcellular localization. Chem. 273, 8749–8755 compromise the ability of p53 to induce cell cycle J. Biol. Chem. 275, 3543–3551 34 Dai, R. et al. (2000) c-Jun NH2-terminal kinase arrest. Cancer Res. 61, 7030–7033 55 Yang, T.T. et al. (2002) Phosphorylation of NFATc4 targeting and phosphorylation of heat shock 45 Kaeser, M.D. and Iggo, R.D. (2002) Chromatin by p38 mitogen-activated protein kinases. factor-1 suppress its transcriptional activity.