MOT Proceedings Paper-Current
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Master of Arts
SOUI\D CHAI\IGE IN OtD MOI\ITAGITAIS by Christopher W. Haryey A Thesis submitted to the Faculty of Graduate Studies ln Partial Fulfillment of the Requirements for the Degree of MASTER OF ARTS I)epartment of Linguistics Ilniversity of Manitoba \ffinnipeg, Manitoba @ Christopher'W. Harve¡ 2005 THE UNTVERSITY OF MANITOBA FACULTY OF GRADUATE STUDIES ?t*itJrrt COPYRIGHT PERMISSION SOUND CIIANGE IN OLD MONITAGNAIS BY Christopher W. Harvey A ThesislPracticum submitted to the Faculty of Graduate Studies of The University of Manitoba in partial fulfillment of the requirement of the degree Master Of Arts Christopher W. Harvey O 2005 Permission has been granted to the Library of the University of Manitoba to lend or sell copies of this thesis/practicum, to the National Library of Canada to microfilm this thesis and to lend or sell copies of the film, and to University Microfilms Inc. to publish an abstract of this thesis/practicum. This reproduction or copy of this thesis has been made available by authority of the copyright owner solely for the purpose of private study and research, and may only be reproduced and copied as permitted by copyright laws or with express written authorization from the copyright owner. SOUND CHANGE IN OLD MONTAGNAIS Chris Harvey ABSTRACT This thesis looks at the sound changes which occurred from reconstructed Proto- Algonquian to Old Montagnais. The Old Montagnais language was recorded by the Jesuits during the seventeenth century in the region of Québec City, Lac Saint-Jean and the lower Saguenay River at the Tadoussac mission. Their most important works which survive to this day are two dictionaries, Díctionnaire montagnais by Antoine Silvy and Racines montagnøises by Bonaventure Fabvre. -

Of the University of Manitoba in Partial Fulfillment of the Requirements for the Degree of Master of Àrts
PHONOTOGICÀt VÀRIÀNTS I PUKATÀI^IÀGÀN WOODS CREE by Jennifer M. Greensmith A thesis submitted to the Faculty of Graduate Studíes of the University of Manitoba in partial fulfiLlment of the requirements for the degree of Master of Àrts Winnipeg, Maniloba 1 985 (e) Jennifer M. Greensmith, 1985 PHONOLOGICAL VARIANTS IN PUKATAI.IAGAN I^IOODS CREE BY JENNIFER I"f . GREENSMITH A thesis subntitted to the Faculty of Craduate Studies of the Ulriversity of Ma¡ritoba in partial fulfill¡nent of the requirenrents of the degree of MASTER OF ARTS o teg6 Pernrission has bee¡r granted to the LIBRARY OF THE UNIVER- SITY OF MAN¡TOBA to lend or sell copies of this thesis. to the NATIOTT-AL LIBRARY OF CANADA ro microfilnr this thesis and to lend or sell copies of the film, and UNIVERSITY lvf ICROFILIvf S to publish an abstract of this thesis. Thc' author reserves other publicatiort rights, alld neithe r tire tlesis nor extensive extracts fronl it may be ¡lrinted o¡ othc'r- wise reproduced without the author's writte¡l pernrissiorr. 111 PREFACE This thesis is a first attempt at a study of the phonological contrasts and surface variants of Woods Cree, based on the dialect spoken at Pukalawagan, Manitoba. The analysis is based on direct elicitation and on narrative texts, one of whieh is included as an appendi x . Few studies of Cree phonology exist, and no phonological st.udy has been made of the Woods dialect. Traditionally, Woods Cree has been identified as t.hat dialect of Cree which has the p-reflex of Proto Àlgonquian *1. -

Aboriginal Languages in Canada
Catalogue no. 98-314-X2011003 Census in Brief Aboriginal languages in Canada Language, 2011 Census of Population Aboriginal languages in Canada Census in Brief No. 3 Over 60 Aboriginal languages reported in 2011 The 2011 Census of Population recorded over 60 Aboriginal languages grouped into 12 distinct language families – an indication of the diversity of Aboriginal languages in Canada.1 According to the 2011 Census, almost 213,500 people reported an Aboriginal mother tongue and nearly 213,400 people reported speaking an Aboriginal language most often or regularly at home.2,3 Largest Aboriginal language family is Algonquian The Aboriginal language family with the largest number of people was Algonquian. A total of 144,015 people reported a mother tongue belonging to this language family (Table 1). The Algonquian languages most often reported in 2011 as mother tongues were the Cree languages4 (83,475), Ojibway (19,275), Innu/Montagnais (10,965) and Oji-Cree (10,180). People reporting a mother tongue belonging to the Algonquian language family lived across Canada. For example, people with the Cree languages as their mother tongue lived mainly in Saskatchewan, Manitoba, Alberta or Quebec. Those with Ojibway or Oji-Cree mother tongues were mainly located in Ontario or Manitoba, while those whose mother tongue was Innu/Montagnais or Atikamekw (5,915) lived mostly in Quebec. Also included in the Algonquian language family were people who reported Mi'kmaq (8,030) who lived mainly in Nova Scotia or New Brunswick, and those who reported Blackfoot (3,250) as their mother tongue and who primarily lived in Alberta. -

Supplementary Resources 2 Connect
March 2015/Mars 2015 SUPPLEMENTARY RESOURCES 2 CONNECT • "Apihawikosisan" Law, Language, Life: A Plains Cree Speaking Metis Woman in Montreal apihtawikosisan.com This blog follows the life of a Metis teacher and has information on how to attend her "language nest" style Plains Cree language course in Montreal. The site also lists a wide variety of links to Cree language and cultural resources. • Cree Cultural Institute http://creeculture.ca/ This site is an excellent destination for learning about the culture and language of Crees living in the James Bay and Hudson Bay regions of Quebec. Among the many features of this website are an archive of historical photographs, an online exhibition of Cree artifacts from the region, and translated traditional stories. • Centre for Race and Culture http://www.cfrac.com/ This organization based in Edmonton, AB organizes programs and projects to help minority, immigrant, and refugee communities. One of these projects is on-site Cree language lessons. • The Nehiyawewin (Cree) Word/Phrase of the Day https://www.facebook.com/groups/18414147673/ This Facebook group brings together users from across the world to share their favourite Cree words and phrases as a way to promote and strengthen the language and the people it represents. 3 LEARN • A-mowin Virtual Language Classroom http://learncreeonline.blogspot.ca This blog offers free online Cree language lessons every Thursday at 9 pm EST. • Alberta Language Technology Lab http://altlab.artsrn.ualberta.ca/?page_id=150 This team at the University of Alberta has created a number of Plains Cree language tools including a Cree/English dictionary and linguistic generation tools. -
When Is a Cluster Not a Cluster?: a Northern East Cree Case Study
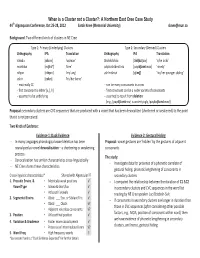
When is a Cluster not a Cluster?: A Northern East Cree Case Study 44 th Algonquian Conference, Oct 25 Ͳ28, 2012 Sarah Knee (Memorial University) [email protected] Background :Two different kinds of clusters in NE Cree Type 1: Primary (Underlying) Clusters Type 2: Secondary (Derived) Clusters Orthography IPA Translation Orthography IPA Translation iskwâu [ࡁsk ࠧw] ‘woman’ tihchikâchâu [t ࡁht ࡚kat ࡚aw] ‘s/he kicks’ mishtikw [m ࡁ࡚t࠾kॎ] ‘tree’ pâyikushtâmitiniu [pay ࡁk࡚tamt ࡁnࡁw] ‘ninety’ nihpin [n ࡁhp ࡁn] ‘my lung’ ushîmishish [ࡡ࡚ im࡚࡚ ] ‘his/her younger sibling’ uskin [ࡡsk ࡁn] ‘his/her bone’ Ͳ maximally CC Ͳcan be many consonants in arow Ͳ first consonant is either [s, ࡚ ,h] Ͳfirst consonant can be awider variety of consonants Ͳ assumed to be underlying Ͳassumed to result from deletion (e.g., [pay ࡁk࡚tamt ࡁnࡁw] is underlyingly /pay ࡁkࡡ࡚tamࡁtࡁnࡁw/) Proposal: secondary clusters are CVC sequences that are produced with avowel that has been devocalized (shortened or weakened) to the point that it is not perceived. Two Kinds of Evidence : Evidence 1: Duck Evidence Evidence 2: Gestural Hiding Ͳ In many languages phonological vowel deletion has been Proposal :vowel gestures are ‘hidden’ by the gestures of adjacent reanalyzed as vowel devocalization –ashortening or weakening consonants process The study : Ͳ Devocalization has similar characteristics cross Ͳlinguistically Ͳ Investigate data for presence of aphonetic correlate of Ͳ NE Cree shares these characteristics gestural hiding: phonetic lengthening of consonants in Cross Ͳlinguistic characteristics* Shared with Algonquian?? secondary clusters 1. Prosodic Enviro. & • Metrically weak positions я Ͳ Icompared the relationship between the duration of C1 &C2 Vowel Type • Schwa &short/lax я in secondary clusters and CVC sequences in the word list • At least hi vowels я reading by NE Cree speaker Luci Bobbish ͲSalt 2. -

Innu-Aimun) in Labrador1
A SURVEY OF RESEARCH ON MONTAGNAIS AND NASKAPI (INNU-AIMUN) IN LABRADOR1 Marguerite MacKenzie Memorial University of Newfoundland ABSTRACT The last two decades have seen increased interest in the study of the language of the Innu of Labrador. Researchers from Memorial University of Newfoundland have been prominent in producing descriptions of grammar, lexicon and linguistic variation in the community of Sheshatshit. Anthropologists have been active in the collection of texts and toponyms. This article gives an overview of work to date in these areas. 1. INTRODUCTION The language spoken by the Innu of Labrador, known to linguists as Montagnais / Naskapi, represents two dialects of the Cree-Montagnais-Naskapi language complex of the Algonquian language family. The Montagnais sub-group is spoken by about 10,000 people in eight communities in Québec and one in Labrador (see Map). In Sheshatshit, (formerly known as North West River) there are about 2,000 speakers. To the north, Naskapi is spoken by about 500 people in Davis Inlet, also known as Utshimassits. Speakers refer to both dialects as Innu- aimun, qualifying this term as necessary. Innu-aimun is still the first language of virtually all residents of the two Labrador communities, with English as the second language. In Québec, where French is the second language, a significant number of Innu, particularly in the western communities, now use French as a first language. In Labrador most speakers under the age of forty are now bilingual to some extent in Innu-aimun and English, since English is the language of schooling. The extent to which this language will join or resist the widespread decline of Aboriginal languages as first languages remains to be documented. -

Evidence from Phonological and Morphological Development in Northern East Cree
Grammar Matters: Evidence from Phonological and Morphological Development in Northern East Cree Yvan Rose and Julie Brittain Memorial University of Newfoundland 1. Introduction* Linguistic theories, all of which aim at explaining the nature and functioning of language, are generally elaborated through the systematic observation of adult languages. It is, however, the case that the empirical base of these theories is limited to a relatively small set of typological observations, often coming from a handful of languages. This problem, unavoidable given the as yet relatively limited state of empirical documentation of linguistic systems, is compounded by the sheer complexity of language typology; entire theories must be developed to account for particular linguistic sub-systems (e.g., phonological or morphological), often without much regard for other sub-systems. All current linguistic theories are thus more than likely to be incomplete and, as such, to be compromised if considered in light of new evidence. This situation, in which different types of empirical evidence may be taken into consideration or, in other cases, ignored, also gives rise to a number of competing linguistic theories, many of which offer radically different outlooks on the nature of human language. In turn, these theories have implications in the context of language development and related applications, as each theory more or less explicitly sets paths for how language should be acquired by first and/or second language learners. This situation has consequences beyond empirical adequacy. For example, two different theories of language acquisition ² one that makes predictions based on input frequency, the other on the basis of structural complexity ² may make equivalent empirical predictions in cases where structural simplicity is pervasive in frequently-occurring contexts. -

Indigenous Languages in Canada
ᐁᑯᓯ ᒫᑲ ᐁᑎᑵ ᐊᓂᒪ ᑳᐃᑘᐟ ᐊᐘ ᐅᐢᑭᓃᑭᐤ , ᒥᔼᓯᐣ, ᑮᐢᐱᐣ ᑕᑲᑵᓂᓯᑐᐦᑕᒣᐠ ᐁᑿ ᒦᓇ ᑕᑲᑵᒥᑐᓂᐑᒋᐦᐃᓱᔦᐠ ᐊᓂᒪ, ᐆᒪ ᓀᐦᐃᔭᐍᐏᐣ ᑭᐢᐱᐣ ᑭᓅᐦᑌᑭᐢᑫᔨᐦᑌᓈᐚᐤ᙮ ᐆᒪ ᐆᑌ INDIGENOUSᑳᐃᑕᐱᔮᕽ ᓵᐢᑿᑑᐣ, ᐁᑯᓯ ᐃᓯ ᐆᒪ ᓂᑲᑵᒋᒥᑲᐏᓈᐣ ᑮᑿᕀ ᐁᓅᐦᑌᑭᐢᑫᔨᐦᑕᐦᑭᐠ ᐁᑯᓯ ᐃᓯLANGUAGESᐆᒪ ᐹᐦᐯᔭᐠ ᐆᒥᓯ ᐃᓯ , ᓂᑮᑭᑐᑎᑯᓈᓇᐠ IN CANADA, “ᑮᒁᕀ ᐊᓂᒪ ᐁᐘᑯ᙮ ᑖᓂᓯ ᐊᓂᒪ ᐁᐘᑯ ᐁᐃᑘᒪᑲᕽ ᐲᑭᐢᑵᐏᐣ᙮” ᐁᑯᓯ ᐃᑘᐘᐠ, ᐁᐘᑯ ᐊᓂᒪ ᐁᑲᑵᒋᒥᑯᔮᐦᑯᐠ, ᐁᑯᓯ ᐏᔭ ᐁᑭᐢᑫᔨᐦᑕᒫᕽ ᐊᓂᒪ, ᑮᒁᕀ ᑳᓅᐦᑌ ᑭᐢᑫᔨᐦᑕᐦᑭᐠ, ᐁᑯᓯ ᓂᑕᑎ ᐑᐦᑕᒪᐚᓈᓇᐠ, ᐁᑯᓯ ᐁᐃᓰᐦᒋᑫᔮᕽ ᐆᑌ ᓵᐢᑿᑑᐣ, ᐁᑿ ᐯᔭᑿᔭᐠ ᐊᓂᒪ ᐁᑯᓯ ᐃᓯ ᐆᒪ ᐁᐊᐱᔮᕽ, ᐁᑿ ᐯᔭᑿᔭᐠ ᒦᓇ ᐃᐦᑕᑯᐣ = ᑭᐢᑫᔨᐦᑕᒼ ᐊᐘ ᐊᓂᒪ ᐃᑕ CANADIAN LANGUAGE MUSEUM ᒦᓇ ᐁᐊᐱᔮᕽMUSÉE CANADIEN= ᐁᑯᑕ DESᐱᓯᓯᐠ LANGUES ᑫᐦᑌ ᐊᔭᐠ᙮ ᐁᑯᑕ ᐁᑿ ᐁᑯᓂᐠ ᑳᓂᑕᐍᔨᐦᑕᐦᑭᐠ , ᒣᒁᐨ ᐆᒪ ᐁᐘᑯ ᐆᒪ ᐁᑿ ᑳᓅᒋᐦᑖᒋᐠ, ᐁᑯᑕ ᐊᓂᒪ ᓂᐑᒋᐦᐃᐚᐣ᙮ CANADIAN LANGUAGE MUSEUM Canadian Language Museum Glendon Gallery, Glendon College 2275 Bayview Avenue Toronto ON M4N 3M6 Printed with assistance from the Robarts Centre for Canadian Studies, York University, Toronto, Canada Copyright © 2019, Canadian Language Museum Author: Will Oxford Editor: Elaine Gold The Cree syllabic text on the cover, typeset by Chris Harvey, is an excerpt from a speech titled “Speaking Cree and Speaking English” by Sarah Whitecalf, published in kinêhiyâwiwininaw nêhiyawêwin / The Cree Language is Our Identity: The La Ronge Lec- tures of Sarah Whitecalf (University of Manitoba Press, 1993, ed. by H.C. Wolfart and Freda Ahenakew). Preface ................................................................................................................................... iii 1 Approaching the study of Indigenous languages ................................................ 1 1.1 Terms for Indigenous peoples and languages ............................................. -

Moose (L-Dialect) and Swampy (N-Dialect) Cree Conversation Manual
ililîmotâ ! / ininîmotâ ! ᐃᓕᓖᒧᑖ ! / ᐃᓂᓂᒧᑕ ! Moose (L-dialect) and Swampy (N-dialect) Cree Conversation Manual Adapted for Moose & Swampy Cree by: Elsie Chilton (L-dialect), Mary Lou Iahtail (N-dialect), and C. Douglas Ellis Originally written for East Cree by: Louise Blacksmith, Marie-Odile Junker, Marguerite MacKenzie, Luci Salt, and Annie Whiskeychan Voices of: Marguerite MacKenzie (English), Elsie Chilton (L-dialect), and Mary Lou Iahtail (N-dialect) Formatting, cover design, graphic design by: Omushkego Education – Mushkegowuk Council Edited by: Marie-Odile Junker, C. Douglas Ellis, and Claire Owen ISBN: 9780770905989 © 2016, www.atlas-ling.ca & Omushkego Education – Mushkegowuk Council Table of Contents Acknowledgements ......................................................................... iii Introduction .................................................................................. iii 1. Greetings .................................................................................. 1 2.1 Family – My Relatives ................................................................ 2 2.2 Family – Calling My Relatives (vocatives) ..................................... 2 3. Numbers ................................................................................... 3 4. Days ......................................................................................... 3 5. Weather .................................................................................... 4 6. Seasons ................................................................................... -

Towards a Dialectology of Cree-Montagnais-Naskapi
TOWARDS A DIALECTOLOGY OF CREE-MONTAGNAIS-NASKAPI by Marguerite Ellen MacKenzie Department of Anthropology A Thesis submitted in conformity with requirements for the Degree of Doctor of Philosophy in the University of Toronto MARGUERITE ELLEN MACKNZIE 1980 TOWARDS A DIALECTOLOGY of CREE - MONTAGNAIS - NASKAPI by Marguerite Ellen MacKenzie ABSTRACT This study describes linguistic variations among the dialects of the Cree language at the levels of phonology, morphology and lexicon. The dialects which undergo velar palatalization (k>c) within Quebec- Labrador are described in detail. The language spoken in these nineteen communities has been referred to as Cree, Montagnais, Naskapi or Montagnais-Naskapi by various scholars. Only the dialects where velar palatalization does not take place are unambiguously regarded as Cree. The relationship between the palatalized and non-palatalized dialects is examined and the dialects spoken between Alberta and Labrador are found to form a continuum. Within the continuum sub- groups are established but the existence of a significant break between non-palatalized (so-called Cree) and palatalized (so-called Montagnais-Naskapi) dialects is challenged. At the level of phonology it is demonstrated that the majority of sound shifts occur in both palatalized and non-palatalized dialects. Usually, however, these shifts are generalized to more phonological segments, and over a larger geographic area, in the palatalized dialects. Processes of short vowel assimilation, loss, neutralization and rounding are much more widespread. As well, the processes of velar palatalization, short vowel syncope and subsequent de-palatalized account for the majority of the differences between palatalized and non-palatalized dialects. These processes are linguistic innovations which originate in thee Quebec dialects, which have been longest in contact with European populations. -

East Cree Material Culture Together We Survive
TOGETHER WE SURVIVE: EAST CREE MATERIAL CULTURE TOGETHER WE SURVIVE: EAST CREE MATERIAL CULTURE By CriTH OBERHOLTZER, M.A. A Thesis Submitted to the School of Graduate Studies in Partial Fulfilment of the Requirements for the Degree Doctor of Philosophy McMaster University (c) Copyright by Cath Oberholtzer, September 1994 DOCTOR OF PHILOSOPHY (1994) McMASTER UNIVERSITY, (Anthropology) Hamilton, Ontario TITLE: Toge1:her We Survive: East Cree Material Culture AUTHOR: Cath Oberholtzer, B.Sc. (Trent University) M.A. (Trent University) SUPERVISOR: Professor R.J. Preston NUMBER OF PAGES: xi, 304 II ABSTRACT The main goals of this thesis are to recontextualize, to rehistoricize and to facilitate the symbolic repatriation of East Cree material culture. As a consequence of the British presence in the Hudson Bay Territory, from the seventeenth century onward a substantial number of inadequately documented material objects were collected from the Cree of the James Bay region and ultimately accessioned into European and North American museum collections. By using these objects as primary documents, we are able to gain knowledge of the native world view and to reconstruct the social history of both the artifacts and their makers. Foremost is the need to establish a definitive ethnic identification of this material. This identification, derived from bot.h external and internal evidence, allows further analysis of particular items which contribute towards a general understanding of East Cree history and world view. Evidence for embedded symbolism expressed in the decorative elements of beaded hoods reveals the dynamic and negotiated realities of native and European relations. While reworking and incorporating European aesthetics and ideals into their material culture, the Cree retained components paramount to native world view. -
Comparative Structures of East Cree and English
COMPARATIVE STRUCTURES OF EAST CREE AND ENGLISH Marie-Odile Junker, Marguerite MacKenzie & Julie Brittain © 2012 Comparative Structures of East Cree and English TABLE&OF&CONTENTS FOREWORD&.........................................................................................................................................................&4! 1.&THE&PLACE&OF&THE&CREE&LANGUAGE&.....................................................................................................&6! 1.1!THE!CREE!LANGUAGE!FAMILY!.....................................................................................................................................!6! 1.2!DIALECTS!OF!THE!EAST!CREE!LANGUAGE!..................................................................................................................!7! 1.3!WRITING!IN!EAST!CREE!.................................................................................................................................................!9! 1.4!QUESTIONS!....................................................................................................................................................................!10! 1.4.1$What$is$the$difference$between$Cree$and$Inuktitut,$spoken$further$north?$................................$10! 1.4.2$Do$other$Cree$people$in$Canada$understand$each$other?$...................................................................$10! 2.&CREE&AND&ENGLISH&PRONUNCIATION&................................................................................................&10! 3.&INTRODUCTION&TO&GRAMMATICAL&COMPARISON&........................................................................&14!