Predictable, Low-Power Arithmetic Logic Unit for the 8051 Microcontroller Using Asynchronous Logic D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R
et International Journal on Emerging Technologies 11 (2): 668-673(2020) ISSN No. (Print): 0975-8364 ISSN No. (Online): 2249-3255 Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R. Venkata Siva Reddy 2 1Research Scholar, VTU Belagavi (Karnataka), India. 2School of Electronics and Communication Engineering, REVA University Bengaluru, (Karnataka), India. (Corresponding author: Amrut Anilrao Purohit) (Received 04 January 2020, Revised 02 March 2020, Accepted 03 March 2020) (Published by Research Trend, Website: www.researchtrend.net) ABSTRACT: Arithmetic and Logic Unit (ALU) can be understood with basic knowledge of digital electronics and any engineer will go through the details only once. The advantage of knowing ALU in detail is two- folded: firstly, programming of the processing device can be efficient and secondly, can design a new ALU architecture as per the various constraints of the use cases. The miniaturization of digital circuits can be achieved by either reducing the size of transistor (Moore’s law) or by optimizing the gate count of the circuit. The first has been explored extensively while the latter has been ignored which deals with the application of Boolean rules and requires sound knowledge of logic design. The ultimate outcome is to have an area optimized architecture/approach that optimizes the circuit at gate level. The design of ALU is for various processing devices varies with the device/system requirements. The area optimization places a significant role in the chip design. Here in this work, we have attempted to design an ALU which is area efficient while being loaded with additional functionality necessary for microcontrollers. -

Unit 8 : Microprocessor Architecture
Unit 8 : Microprocessor Architecture Lesson 1 : Microcomputer Structure 1.1. Learning Objectives On completion of this lesson you will be able to : ♦ draw the block diagram of a simple computer ♦ understand the function of different units of a microcomputer ♦ learn the basic operation of microcomputer bus system. 1.2. Digital Computer A digital computer is a multipurpose, programmable machine that reads A digital computer is a binary instructions from its memory, accepts binary data as input and multipurpose, programmable processes data according to those instructions, and provides results as machine. output. 1.3. Basic Computer System Organization Every computer contains five essential parts or units. They are Basic computer system organization. i. the arithmetic logic unit (ALU) ii. the control unit iii. the memory unit iv. the input unit v. the output unit. 1.3.1. The Arithmetic and Logic Unit (ALU) The arithmetic and logic unit (ALU) is that part of the computer that The arithmetic and logic actually performs arithmetic and logical operations on data. All other unit (ALU) is that part of elements of the computer system - control unit, register, memory, I/O - the computer that actually are there mainly to bring data into the ALU to process and then to take performs arithmetic and the results back out. logical operations on data. An arithmetic and logic unit and, indeed, all electronic components in the computer are based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations. Data are presented to the ALU in registers. These registers are temporary storage locations within the CPU that are connected by signal paths of the ALU. -

Reverse Engineering X86 Processor Microcode
Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz, Ruhr-University Bochum https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/koppe This paper is included in the Proceedings of the 26th USENIX Security Symposium August 16–18, 2017 • Vancouver, BC, Canada ISBN 978-1-931971-40-9 Open access to the Proceedings of the 26th USENIX Security Symposium is sponsored by USENIX Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz Ruhr-Universitat¨ Bochum Abstract hardware modifications [48]. Dedicated hardware units to counter bugs are imperfect [36, 49] and involve non- Microcode is an abstraction layer on top of the phys- negligible hardware costs [8]. The infamous Pentium fdiv ical components of a CPU and present in most general- bug [62] illustrated a clear economic need for field up- purpose CPUs today. In addition to facilitate complex and dates after deployment in order to turn off defective parts vast instruction sets, it also provides an update mechanism and patch erroneous behavior. Note that the implementa- that allows CPUs to be patched in-place without requiring tion of a modern processor involves millions of lines of any special hardware. While it is well-known that CPUs HDL code [55] and verification of functional correctness are regularly updated with this mechanism, very little is for such processors is still an unsolved problem [4, 29]. known about its inner workings given that microcode and the update mechanism are proprietary and have not been Since the 1970s, x86 processor manufacturers have throughly analyzed yet. -

Reconfigurable Accelerators in the World of General-Purpose Computing
Reconfigurable Accelerators in the World of General-Purpose Computing Dissertation A thesis submitted to the Faculty of Electrical Engineering, Computer Science and Mathematics of Paderborn University in partial fulfillment of the requirements for the degree of Dr. rer. nat. by Tobias Kenter Paderborn, Germany August 26, 2016 Acknowledgments First and foremost, I would like to thank Prof. Dr. Christian Plessl for the advice and support during my research. As particularly helpful, I perceived his ability to communicate suggestions depending on the situation, either through open questions that give room to explore and learn, or through concrete recommendations that help to achieve results more directly. Special thanks go also to Prof. Dr. Marco Platzner for his advice and support. I profited especially from his experience and ability to systematically identify the essence of challenges and solutions. Furthermore, I would like to thank: • Prof. Dr. João M. P. Cardoso, for serving as external reviewer for my dissertation. • Prof. Dr. Friedhelm Meyer auf der Heide and Dr. Matthias Fischer for serving on my oral examination committee. • All colleagues with whom I had the pleasure to work at the PC2 and the Computer Engineering Group, researchers, technical and administrative staff. In a variation to one of our coffee kitchen puns, I’d like to state that research without colleagues is possible, but pointless. However, I’m not sure about the first part. • My long-time office mates Lars Schäfers and Alexander Boschmann for particularly extensive discussions on our research and far beyond. • Gavin Vaz, Heinrich Riebler and Achim Lösch for intensive and productive collabo- ration on joint research interests. -

The Central Processing Unit (CPU)
The Central Processing Unit (CPU) Crash Course Computer Science #7 The Central Processing Unit https://www.youtube.com/watch?v=FZGugFqdr60 Internals ● Arithmetic Logic Unit (ALU) ● Control Unit (CU) ● Registers ● Cache Memory ● The Fetch-Execute Cycle Arithmetic Logic Unit An arithmetic logic unit (ALU) is a digital circuit used to perform arithmetic and logic operations. It represents the fundamental building block of the central processing unit (CPU) of a computer. Modern CPUs contain very powerful and complex ALUs. In addition to ALUs, modern CPUs contain a control unit (CU). Most of the operations of a CPU are performed by one or more ALUs, which load data from input registers. A register is a small amount of storage available as part of a CPU. The control unit tells the ALU what operation to perform on that data and the ALU stores the result in an output register. The control unit moves the data between these registers, the ALU, and memory. Control Unit A control unit coordinates how data moves around a cpu. The control unit (CU) is a component of a computer's central processing unit (CPU) that directs operation of the processor. It tells the computer's memory, arithmetic/logic unit and input and output devices how to respond to a program's instructions. ● The control unit obtains data / instructions from memory ● Interprets / decodes the instructions into commands / signals ● Controls transfer of instructions and data in the CPU ● Coordinates the parts of the CPU Registers In computer architecture, a processor register is a quickly accessible location available to a digital processor's central processing unit (CPU). -
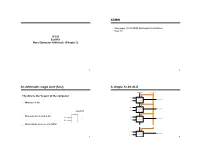
ADMIN an Arithmetic Logic Unit (ALU) a Simple 32-Bit
ADMIN • Read pages 211-215 (MIPS floating point instructions) • Read 3.9 IC220 Set #10: More Computer Arithmetic (Chapter 3) 1 2 An Arithmetic Logic Unit (ALU) A simple 32-bit ALU C arryIn O pe ratio n The ALU is the ‘brawn’ of the computer a0 C arry In R e su lt0 A LU 0 b0 • What does it do? C arry O u t a1 C arry In R e su lt1 A LU 1 b1 operation C arry O u t • How wide does it need to be? a a2 C arry In R e su lt2 A LU 2 b2 b C arry O u t • What outputs do we need for MIPS? a3 1 C arry In R e su lt31 A LU 3 1 b3 1 3 4 ALU Control and Symbol Multiplication • More complicated than addition – accomplished via shifting and addition • Example: grade-school algorithm 0010 (multiplicand) ALU Control Lines Function __x_1011 (multiplier) 0000 AND 0001 OR 0010 Add 0110 Subtract 0111 Set on less than 1100 NOR • Multiply m * n bits, How wide (in bits) should the product be? 5 6 Multiplication: Simple Implementation Multiplicand Shift left 64bits Multiplier 64-bit ALU Shift right 32bits Product Control test Write 64bits 7 Using Multiplication Floating Point • Product requires 64 bits • We need a way to represent – Use dedicated registers – numbers with fractions, e.g., 3.1416 – HI – more significant part of product – – LO – less significant part of product very small numbers, e.g., .000000001 • MIPS instructions – very large numbers, e.g., 3.15576 1023 mult $s2, $s3 • Representation: multu $s2, $s3 mfhi $t0 – sign, exponent, significand: mflo $t1 • (–1)sign significand 2exponent(some power) • Division – Significand always in normalized form: – Can perform with same hardware! (see book) div $s2, $s3 Lo = $s2 / $s3 • Yes: Hi = $s2 mod $s3 • No: divu $s2, $s3 – more bits for significand gives more – more bits for exponent increases 9 10 IEEE754 Standard IEEE 754 – Optimizations Single Precision (float): 8 bit exponent, 23 bit significand 31 30 29 28 27 26 25 24 23 22 21 20 . -

Graphical Microcode Simulator with a Reconfigurable Datapath
Rochester Institute of Technology RIT Scholar Works Theses 12-11-2006 Graphical microcode simulator with a reconfigurable datapath Brian VanBuren Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation VanBuren, Brian, "Graphical microcode simulator with a reconfigurable datapath" (2006). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Graphical Microcode Simulator with a Reconfigurable Datapath by Brian G VanBuren A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Engineering Supervised by Associate Professor Dr. Muhammad Shaaban Department of Computer Engineering Kate Gleason College of Engineering Rochester Institute of Technology Rochester, New York August 2006 Approved By: Dr. Muhammad Shaaban Associate Professor Primary Adviser Dr. Roy Czernikowski Professor, Department of Computer Engineering Dr. Roy Melton Visiting Assistant Professor, Department of Computer Engineering Thesis Release Permission Form Rochester Institute of Technology Kate Gleason College of Engineering Title: Graphical Microcode Simulator with a Reconfigurable Datapath I, Brian G VanBuren, hereby grant permission to the Wallace Memorial Library repor- duce my thesis in whole or part. Brian G VanBuren Date Dedication To my son. iii Acknowledgments I would like to thank Dr. Shaaban for all his input and desire to have an update microcode simulator. I would like to thank Dr. Czernikowski for his support and methodical approach to everything. I would like to thank Dr. -

Arithmetic Logic Unit Architectures with Dynamically Defined Precision
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 12-2015 ARITHMETIC LOGIC UNIT ARCHITECTURES WITH DYNAMICALLY DEFINED PRECISION Getao Liang University of Tennessee - Knoxville, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Computer and Systems Architecture Commons, Digital Circuits Commons, and the VLSI and Circuits, Embedded and Hardware Systems Commons Recommended Citation Liang, Getao, "ARITHMETIC LOGIC UNIT ARCHITECTURES WITH DYNAMICALLY DEFINED PRECISION. " PhD diss., University of Tennessee, 2015. https://trace.tennessee.edu/utk_graddiss/3592 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Getao Liang entitled "ARITHMETIC LOGIC UNIT ARCHITECTURES WITH DYNAMICALLY DEFINED PRECISION." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Doctor of Philosophy, with a major in Computer Engineering. Gregory D. Peterson, Major Professor We have read this dissertation and recommend its acceptance: Jeremy Holleman, Qing Cao, Joshua Fu Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) ARITHMETIC LOGIC UNIT ARCHITECTURES WITH DYNAMICALLY DEFINED PRECISION A Dissertation Presented for the Doctor of Philosophy Degree The University of Tennessee, Knoxville Getao Liang December 2015 DEDICATION This dissertation is dedicated to my wife, Jiemei, and my family. -

Comparative Analysis of ALU Implementation with RCA and Sklansky Adders in ASIC Design Flow
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 7, No. 7, 2016 Comparative Analysis of ALU Implementation with RCA and Sklansky Adders In ASIC Design Flow Abdul Rehman Buzdar, Liguo Sun, Abdullah Buzdar Department of Electronic Engineering and Information Science University of Science and Technology of China (USTC) Hefei, People’s Republic of China Abstract—An Arithmetic Logic Unit (ALU) is the heart followed by ALU circuit basic Synthesis. Later we describe the of every central processing unit (CPU) which performs basic process of Design Respin, Power analysis, Place and Route of operations like addition, subtraction, multiplication, division and ALU circuits. Finally, we summarize our conclusions. bitwise logic operations on binary numbers. This paper deals with implementation of a basic ALU unit using two different types of adder circuits, a ripple carry adder and a sklansky type adder. II. ALU DESIGN-VERIFICATION The ALU is designed using application specific integrated circuit Initial verification of both the ALUs i.e. ALU-RCA and (ASIC) platform where VHDL hardware description language ALU-SKL were performed based on the waveform approach and standard cells are used. The target process technology using ModelSim software tool [47] as we made both the ALUs is 130nm CMOS from the foundry ST Microelectronics. The Cadence EDA tools are used for the ASIC implementation. generic so we reduced the ALU size to 8-bit just to make A comparative analysis is provided for the two ALU circuits initial verification simple. The waveform based approach of designed in terms of area, power and timing requirements. verification is only useful during the initial phases of small designs and always requires more comprehensive verification Keywords—Arithmetic Logic Unit; Ripple Carry Adder; Sklan- in the later design stages. -

ABSTRACT Title of Document
ABSTRACT Title of Document: STUDY OF THE IMPACT OF HARDWARE FAILURES ON SOFTWARE RELIABILITY Bing Huang, Doctor of Philosophy, 2006 Directed By: Professor Joseph B. Bernstein Professor Carol S. Smidts Reliability Engineering Software plays an increasingly important role in modern safety-critical systems. Reliable software becomes desirable for all stakeholders. Typical software related failures include software internal failures, input failures, output failures, support failures and multiple interaction failures. This dissertation provides a methodology to study the impact of hardware support failures on software reliability. The hardware failures we are focusing on in this study are semiconductor device intrinsic failures that are directly related to software execution during device operation. The software execution on hardware devices, in essence, is a series of 0 and 1 signal alternations for the inputs of hardware components. Such signal alternations lead to voltage changes and current flows in the microelectronic hardware device, which serve as electrical stresses on the device and may lead to physical failures. The failure mechanisms include Hot Carrier Injection (HCI), Electromigration (EM), and Time Dependent Dielectric Breakdown (TDDB). During device operation such hardware failures could propagate to circuit level in the form of signal delays, changes of circuit functionality, and signals stuck at a logic value (0 or 1), which could further propagate into the software layer and affect the reliability of the software. The proposed methodology is divided into three parts: (i) analysis of the manifestations of permanent failures on circuit elements (logic gates, flip-flops, etc.), (ii) development of reliability models for the circuit elements as functions of the software execution, and (iii) calculation of failure probability distributions of the hardware circuit elements under the software execution. -

Arithmetic Logic UNIT
Louisiana State University LSU Digital Commons LSU Master's Theses Graduate School 2003 Arithmetic logic UNIT (ALU) design using reconfigurable CMOS logic Chandra Srinivasan Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_theses Part of the Electrical and Computer Engineering Commons Recommended Citation Srinivasan, Chandra, "Arithmetic logic UNIT (ALU) design using reconfigurable CMOS logic" (2003). LSU Master's Theses. 2891. https://digitalcommons.lsu.edu/gradschool_theses/2891 This Thesis is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Master's Theses by an authorized graduate school editor of LSU Digital Commons. For more information, please contact [email protected]. ARITHMETIC LOGIC UNIT (ALU) DESIGN USING RECONFIGURABLE CMOS LOGIC A Thesis Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Master of Science in Electrical Engineering in The Department of Electrical and Computer Engineering by Chandra Srinivasan Bachelor of Engineering, Mysore University, 1997 December 2003 To My parents and in loving memory of my grandmother ii Acknowledgements I would like to acknowledge certain people who have encouraged, supported and helped me complete my thesis at LSU. I am very grateful to my advisor Dr. A. Srivastava for his guidance, patience and understanding throughout this work. His suggestions, discussions and constant encouragement has helped me to get a deep insight in the field of VLSI design. I would like to thank Dr. -

A Low Power and Fast Cmos Arithmetic Logic Unit Nur
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UTHM Institutional Repository A LOW POWER AND FAST CMOS ARITHMETIC LOGIC UNIT NUR UMAIRA BINTI ZULKIFLI A project report submitted in partial fulfillment of the requirement for the award of the Degree of Master of Electrical Engineering Faculty of Electrical and Electronic Engineering Universiti Tun Hussein Onn Malaysia v ABSTRACT This thesis presents the design of a low power and fast Complimentary Metal-Oxide- Semiconductor (CMOS) Arithmetic Logic Unit (ALU). ALU is one of the most important parts of a digital computer which is designed to do the arithmetic and logic operations, including bit shifting operation that need to be done for almost any data that is being processed by the central processing unit (CPU). For most applications of all digital circuits, the two important attributes are maximizing speed and minimizing power consumption. The overall performance of the system will depend on the speed of the different modules used in the design. To achieve the desired outcome, the proposed ALU is designed using pass transistor logic (PTL) based multiplexers and 8 transistors (8T) full adder. Tanner EDA V13 with CMOS technology of 0.25µm is used to design and analyze the circuit. Less number of transistors used will result in small design space area thus reducing the power consumption. The result is being analyzed by different values of supply voltage applied to the circuit which ranging from 5V to 1V. The results obtained shows that the minimum power consumption is for Vdd equal to 1V with 0.533µW.