Improving Car Model Classification Through Vehicle Keypoint Localization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2016 Board of Directors Contents
EFFECTIVE FIRST DAY OF THE MONTH UNLESS OTHERWISE NOTED January 2016 BOARD OF DIRECTORS CONTENTS BOARD OF DIRECTORS | December 4-5, 2015 BOARD OF DIRECTORS 1 SOLO 28 The SCCA National Board of Directors met in Kansas City, Friday, December 4 and SEB Minutes 28 December 5, 2015. Area Directors participating were: John Walsh, Chairman, Dan Helman, Vice-Chairman, Todd Butler, Secretary; Bill Kephart, Treasurer; Dick Patullo, CLUB RACING 32 Lee Hill, Steve Harris, Bruce Lindstrand, Terry Hanushek, Tere Pulliam, Peter Zekert, CRB Minutes 32 Brian McCarthy and KJ Christopher and newly elected directors Arnold Coleman, Bob Technical Bulletin 41 Dowie and Jim Weidenbaum. Court of Appeals 52 Divisional Time Trials Comm. 53 The following SCCA, Inc. staff participated in the meeting: Lisa Noble, President RALLY 54 and CEO; Eric Prill, Chief Operations Officer; Mindi Pfannenstiel, Senior Director of RallyCross 54 Finance and Aimee Thoennes, Executive Assistant. Road Rally 56 Guests attending the meeting were Jim Wheeler, Chairman of the CRB. LINKS 57 The secretary acknowledges that these minutes may not appear in chronological order and that all participants were not present for the entire meeting. The meeting was called to order by Vice Chair Helman. Executive Team Report and Staff Action Items President Noble provided a review of 2015 key programs and deliverables with topic areas of core program growth, scca.com, and partnerships. Current initiatives to streamline event process with e-logbook tied into event registration, modernize timing systems in Pro Solo, connecting experiential programs (eg TNIA, Starting Line) to core programs. Multiple program offerings to enhance weekend events. -

2009 Autocross Entry Form
2021 AUTOCROSS / OPEN TRACK ENTRY FORM RMMR AX Event Classifications Stock Classes (ES, ESL, FS, FSL, LS, LSL): Mustang as produced with options available year of manufacture. One modification allowed over stock to suspension or gear ratio. Suspension must retain original configuration and ride height. Up to two modifications allowed to engine over stock. No power adders (eco boost excepted). No autocross or road race tires with wear indicators of less than 200 allowed. Allowed modifications are as follows: Suspension – higher rate springs, sway bars, wheels, and traction bars. One modification only. Shock absorbers are not considered a modification. No modification is allowed that does not adhere to the original suspension design and mounting points. Devices that allow for suspension alignment tuning are allowed. Upgraded brake system and steering systems that were not available for the model year are not allowed. Gear ratio – any gear ratio that was available during the model years covered by the class. Engine - intake manifold, carburetor, throttle body, air cleaner, exhaust headers, and chip upgrade. Two modifications only. Transmission – Transmission swaps/replacements are allowed only for transmissions that were available during the model year covered by the class. Street Prepared Classes (ESP, ESPL, FSP, FSPL, LSP, LSPL): Additional modifications allowed over stock. Car must be titled, have current license plates, be street driven. No major lightening is allowed. Car must have a full interior. The following models due to their superiority over the standard offerings of their model year are considered as Street Prepared cars:’93-’01 Cobra (non supercharged), Bullitt, ’03 –‘04 Mach1, 2012-13 Boss 302, 2011 - 2021 GT,’06 – ’21 Shelby GT/GTH/GT350 (non supercharged), and other non supercharged Shelby, Roush & Saleen models and all electric power vehicles. -

Revisiting the Compcars Dataset for Hierarchical Car Classification
sensors Article Revisiting the CompCars Dataset for Hierarchical Car Classification: New Annotations, Experiments, and Results Marco Buzzelli * and Luca Segantin Department of Informatics Systems and Communication, University of Milano-Bicocca, 20126 Milano, Italy; [email protected] * Correspondence: [email protected] Abstract: We address the task of classifying car images at multiple levels of detail, ranging from the top-level car type, down to the specific car make, model, and year. We analyze existing datasets for car classification, and identify the CompCars as an excellent starting point for our task. We show that convolutional neural networks achieve an accuracy above 90% on the finest-level classification task. This high performance, however, is scarcely representative of real-world situations, as it is evaluated on a biased training/test split. In this work, we revisit the CompCars dataset by first defining a new training/test split, which better represents real-world scenarios by setting a more realistic baseline at 61% accuracy on the new test set. We also propagate the existing (but limited) type-level annotation to the entire dataset, and we finally provide a car-tight bounding box for each image, automatically defined through an ad hoc car detector. To evaluate this revisited dataset, we design and implement three different approaches to car classification, two of which exploit the hierarchical nature of car annotations. Our experiments show that higher-level classification in terms of car type positively impacts classification at a finer grain, now reaching 70% accuracy. The achieved performance constitutes a baseline benchmark for future research, and our enriched set of annotations is made available for public download. -

PT & TT Car Classification Form
® NASA Performance Touring (PTD-PTF) & Time Trial (TTD-TTF) Car Classification Form--2018 (v13.1/15.1—1-15-18) Driver or Team Name________________________________ Date______________ Car Number________ Region_____________ e-mail________________________________________ Car Color_______________ If a team, list drivers’ names (two maximum per team): ___________________________________________ ___________________________________________ Vehicle: Year_______ Make______________ Model___________________ Special Edition?____________ NASA PT/TT Base Class _____________ Base Weight Listing (from PT/TT Rules)______________lbs. Minimum Competition Weight (w/driver)_______________lbs. Multiple ECU Maps? Describe switching method and HP levels:_____________________________________________ DYNO RE-CLASSED VEHICLES Only: (Only complete this section if the vehicle has been Dyno Re-classed by the National PT/TT Director!) New PT/TT Base Class Assigned by the National PT/TT Director:_________(Attach a copy of the re-classing e-mail) Maximum allowed Peak whp_________hp Minimum Competition Weight__________lbs. All cars with a Motor Swap, Aftermarket Forced Induction, Modified Turbo/Supercharger, Aftermarket Head(s), Increased Number of Camshafts, Hybrid Engine, and Ported Rotary motors MUST be assessed by the National PT/TT Director for re-classification into a new PT/TT Base Class! (See PT Rules sections 6.3.C and 6.4) (E-mail the information in the listed format in PT Rules section 6.4.2 to the National PT/TT Director at [email protected] to receive your new PT/TT Base Class) Note: Any car exceeding the Adjusted Weight/Horsepower Ratio limit for its class will be disqualified. (see PT Rules Section 6.1.2 and Appendix A of PT Rules). Proceed to calculate your vehicle’s Modification Points assessment for up-classing purposes. -

Driving Resistances of Light-Duty Vehicles in Europe
WHITE PAPER DECEMBER 2016 DRIVING RESISTANCES OF LIGHT- DUTY VEHICLES IN EUROPE: PRESENT SITUATION, TRENDS, AND SCENARIOS FOR 2025 Jörg Kühlwein www.theicct.org [email protected] BEIJING | BERLIN | BRUSSELS | SAN FRANCISCO | WASHINGTON International Council on Clean Transportation Europe Neue Promenade 6, 10178 Berlin +49 (30) 847129-102 [email protected] | www.theicct.org | @TheICCT © 2016 International Council on Clean Transportation TABLE OF CONTENTS Executive summary ...................................................................................................................II Abbreviations ........................................................................................................................... IV 1. Introduction ...........................................................................................................................1 1.1 Physical principles of the driving resistances ....................................................................... 2 1.2 Coastdown runs – differences between EU and U.S. ........................................................ 5 1.3 Sensitivities of driving resistance variations on CO2 emissions ..................................... 6 1.4 Vehicle segments ............................................................................................................................. 8 2. Evaluated data sets ..............................................................................................................9 2.1 ICCT internal database ................................................................................................................. -

From Porsche Club of America--Golden Gate Region Date: December 4, 2007 2:39:13 PM PST To: [email protected] Reply-To: [email protected]
From: John Celona <[email protected]> Subject: From Porsche Club of America--Golden Gate Region Date: December 4, 2007 2:39:13 PM PST To: [email protected] Reply-To: [email protected] Porsche Club of America Golden Gate Region December, 2007 - Vol 47, Number 12 In This Issue Dear Porsche Enthusiast, Place dé Leglise Welcome to The Nugget, the email newsletter of the Golden Letter from the Editor Gate Region, Porsche Club of America. Competition Corner If you have any trouble viewing Membership Report this email, you can click here to go to the archive of PDF Board of Directors versions of this newsletter. For AX #10 comments or feedback, click here to email the editor. The Power Chef Thanks for reading. 40 Years Ago in the Nugget Registration for DE #6 Year End GGR Banquet Zone 7 Awards Dinner Crab 34 European Porsche Parade 2008 LA Lit & Toy Show Porsche Web Cinema Porsche Hybrid History Quick Links Event Calendar Classified Ads Join PCA Now Nugget Archive More About Us Zone 7 web site PCA web site Great Links Place dé Leglise --by Claude Leglise, GGR President The State of GGR There are only two events left on the GGR calendar for this year. Driver's Ed at Laguna Seca on December 9 - there are still slots available and the weather is holding up very nicely - and the Friday Night Social on December 21. The club has enjoyed a good year in 2007, yet some challenges face us. Andrew Forrest and the entire Time Trial crew have done a terrific job modernizing and revitalizing the TT Series. -
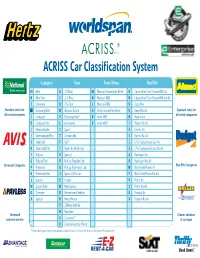
ACRISS Car Classification System
4WS 968 Car Industry Letter 6/12/06 09:15 Page 1 ACRISS Car Classification System Category Type Trans/Drive Fuel/Air M Mini B 2-3 Door M Manual Unspecified Drive R Unspecified Fuel/Power With Air N Mini Elite C 2/4 Door N Manual 4WD N Unspecified Fuel/Power Without Air E Economy D 4-5 Door C Manual AWD D Diesel Air Standard codes for H Economy Elite W Wagon/Estate A Auto Unspecified Drive Q Diesel No Air Standard codes for all rental companies all rental companies C Compact V PassengerVan* B Auto 4WD H Hybrid Air D Compact Elite L Limousine D Auto AWD I Hybrid No Air I Intermediate S Sport E Electric Air J Intermediate Elite T Convertible C Electric No Air S Standard F SUV* L LPG/Compressed Gas Air R Standard Elite J Open Air All Terrain S LPG/Compressed Gas No Air F Fullsize X Special A Hydrogen Air G Fullsize Elite P Pick up Regular Cab B Hydrogen No Air Increased Categories New Elite Categories P Premium Q Pick up Extended Cab M Multi Fuel/Power Air U Premium Elite Z Special Offer Car F Multi Fuel/Power No Air L Luxury E Coupe V Petrol Air W Luxury Elite M Monospace Z Petrol No Air O Oversize R Recreational Vehicle U Ethanol Air X Special H Motor Home X Ethanol No Air Y 2 Wheel Vehicle N Roadster Increased Greater selection customer service G Crossover* of car types K Commercial Van/Truck *These vehicle types require new booking codes which are listed in the chart on the back of this document. -

Assessment of Fuel Economy Technologies for Light-Duty Vehicles
This PDF is available from The National Academies Press at http://www.nap.edu/catalog.php?record_id=12924 Assessment of Fuel Economy Technologies for Light-Duty Vehicles ISBN Committee on the Assessment of Technologies for Improving Light-Duty 978-0-309-15607-3 Vehicle Fuel Economy; National Research Council 260 pages 8 1/2 x 11 PAPERBACK (2011) Visit the National Academies Press online and register for... Instant access to free PDF downloads of titles from the NATIONAL ACADEMY OF SCIENCES NATIONAL ACADEMY OF ENGINEERING INSTITUTE OF MEDICINE NATIONAL RESEARCH COUNCIL 10% off print titles Custom notification of new releases in your field of interest Special offers and discounts Distribution, posting, or copying of this PDF is strictly prohibited without written permission of the National Academies Press. Unless otherwise indicated, all materials in this PDF are copyrighted by the National Academy of Sciences. Request reprint permission for this book Copyright © National Academy of Sciences. All rights reserved. Assessment of Fuel Economy Technologies for Light-Duty Vehicles ASSESSMENT OF FUEL ECONOMY TECHNOLOGIES FOR LIGHT-DUTY VEHICLES Committee on the Assessment of Technologies for Improving Light-Duty Vehicle Fuel Economy Board on Energy and Environmental Systems Division on Engineering and Physical Sciences Copyright © National Academy of Sciences. All rights reserved. Assessment of Fuel Economy Technologies for Light-Duty Vehicles THE NATIONAL ACADEMIES PRESS 500 Fifth Street, N.W. Washington, DC 20001 NOTICE: The project that is the subject of this report was approved by the Governing Board of the National Research Council, whose members are drawn from the councils of the National Academy of Sciences, the National Academy of Engineering, and the Institute of Medicine. -

2017 GCR General Competition Rules
General Competition Rules for 2017 Effective January 1, 2017 (Including approved/ratified changes) These General Competition Rules (GCRs) have been compiled by the Competition Director and Competition Committee of the Porsche Owners Club (POC) and represent a simplified but strict adherence to the competitive spirit and sportsmanship of the POC. Approved and ratified by the POC Board of Directors, these GCRs are to be used by all competitors in POC Performance Driving Series (PDS), Time Attack, and Racing events as a template for car preparation and modification within these rules. Important note: The rules and/or regulations set forth herein are designed to provide for the orderly conduct of POC events and to establish minimum acceptable requirements for such events. These GCRs shall govern the condition of the POC events, and, by participating in these events, all participants are deemed to have complied with these GCRs. No expressed or implied warranty of safety shall result from publication of, or compliance with, these GCRs. They are solely intended as a guide for the conduct of the sport, and are in no way a guarantee against injury or death to participants, spectators, or others. Above all, the POC wishes to promote fair and enjoyable competition for all its members. Questions concerning these rules should be directed to the POC Competition Director via the official POC website: www.porscheclub.com 1 Published by and all rights reserved by the Porsche Owners Club, Inc., a not for profit organization. TABLE OF CONTENTS General 1.0 -

2021 Hpde Gs101 Tech Inspection Form
2021 TECH INSPECTION FORM – GS101 School Prior to bringing your car to the track inspect each item on the car as noted on this Tech Sheet. Consult a tech inspector if there are any questions. Please check each item on this list and bring to track with the car Year ________ Model ______________________________ Engine size_______Supercharged ___ Factory_______Aftermarket_____ Modifications__________________________________________________ Tire Manufacturer: __________Size: ________Model Name _________and Treadwear Rating___________ Your Car Classification: circle one - Stock - Modified - Race • A full-size, street legal windshield. No cracks. Must be clean. • Remove hub caps / trim rings / non-bolted wheel covers • Targa or T-top vehicles must either bolt the removable panels in place or removed entirely. • Car Number on each side of Car visible to Corner Workers – Track can provide. • Open cars must run with the top lowered and safely stowed. Weather Permitting • Brake fluid -Less than 6 months old, reservoir full. (Fluid should be light in color) • Brake Hoses and Lines -Dry and in good condition • Brake Pads - 1/4" thickness or greater. New pads recommended. • Brake Pedal -Must be firm and release freely. • Brake Lights - Fully functioning • Battery - Securely fastened and good condition, no leaks corrosion or exposed • Terminals. Be sure Positive Terminal is covered and protected • Engine and Transmission -No fluid leaks. • Reliable throttle return springs, no binding, returns freely. • Exhaust -Securely mounted. • Front Suspension -No looseness permitted. Bearings and joints in excellent condition. • Rear Suspension - Drive train & components in excellent condition. Suspensions secure. • Wheels - No cracks or bends. Lug nuts torque checked after each session. No hubcaps. • Tires - Good condition. No cracks, bulges, flat spot or cord. -
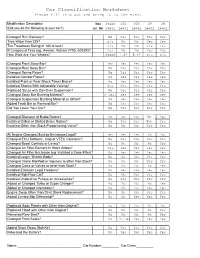
Car Classification Worksheet Please Fill This out and Bring It to the Event
Car Classification Worksheet Please fill this out and bring it to the event Modification Description Yes Stock STS STX SP SM (Did you do the following to your car?) or No Legal Legal Legal Legal Legal Changed Rim Diameter? No Yes Yes Yes Yes Tires Wider than 225? n/a No No Yes Yes Tire Treadwear Rating of 140 or less? n/a No No n/a n/a R Compound Tires (eg: Hoosier, Kuhmo V700, A032R)? Yes No No Yes Yes How Wide Are Your Wheels? Stock 7.5" 8.0" n/a n/a Changed Front Sway Bar? Yes Yes Yes Yes Yes Changed Rear Sway Bar? No Yes Yes Yes Yes Changed Spring Rates? No Yes Yes Yes Yes Installed Camber Plates? No Yes Yes Yes Yes Installed Front or Rear Shock Tower Brace? No Yes Yes Yes Yes Installed Shocks With Adjustable Valving? Yes Yes Yes Yes Yes Replaced Struts with Coil-Over Suspension? No Yes Yes Yes Yes Changed Sway Bar Bushing Material? F Only Yes Yes Yes Yes Changed Suspension Bushing Material or Offset? No Yes Yes Yes Yes Added Track Bar or Panhard Bar? No Yes Yes Yes Yes Did You Lower Your Car? No Yes Yes Yes Yes Changed Diameter of Brake Rotors? No No Yes Yes Yes Installed Drilled or Slotted Brake Rotors? No Yes Yes No Yes Installed Other than Stock Proportioning Valve? No No No Yes Yes All Engine Changes Must be Emissions Legal? Yes Yes Yes No No Changed ECU Software, Chip or VTEC Controller? No Yes Yes Yes Yes Changed Boost Controls or Levels? No No No No Yes Changed Air Filter Element In Stock Airbox? Yes Yes Yes Yes Yes Changed Air Filter Enclosure (eg: Installed a Cone Filter)? No Yes Yes Yes Yes Installed Larger Throttle Body? -

Copyrighted Material
1 Introduction 1.1 History The current world-wide production of vehicle dampers, or so-called shock absorbers, is difficult to estimate with accuracy, but is probably around 50–100 million units per annum with a retail value well in excess of one billion dollars per annum. A typical European country has a demand for over 5 million units per year on new cars and over 1 million replacement units, The US market is several times that. If all is well, these suspension dampers do their work quietly and without fuss. Like punctuation or acting, dampers are at their best when they are not noticed - drivers and passengers simply want the dampers to be trouble free. In contrast, for the designer they are a constant interest and challenge. For the suspension engineer there is some satisfaction in creating a good new damper for a racing car or rally car and perhaps making some contribution to competition success. Less exciting, but economically more important, there is also satisfaction in seeing everyday vehicles travelling safely with comfortable occupants at speeds that would, even on good roads, be quite impractical without an effective suspension system. The need for dampers arises because of the roll and pitch associated with vehicle manoeuvring, and from the roughness of roads. In the mid nineteenth century, road quality was generally very poor. The better horse-drawn carriages of the period therefore had soft suspension, achieved by using long bent leaf springs called semi-elliptics, or even by using a pair of such curved leaf springs set back-to-back on each side, forming full-elliptic suspension.