A Genomic Journey Through a Genus of Large DNA Viruses
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
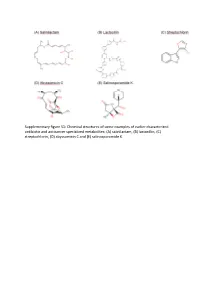
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

The 2014 Golden Gate National Parks Bioblitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event
National Park Service U.S. Department of the Interior Natural Resource Stewardship and Science The 2014 Golden Gate National Parks BioBlitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event Natural Resource Report NPS/GOGA/NRR—2016/1147 ON THIS PAGE Photograph of BioBlitz participants conducting data entry into iNaturalist. Photograph courtesy of the National Park Service. ON THE COVER Photograph of BioBlitz participants collecting aquatic species data in the Presidio of San Francisco. Photograph courtesy of National Park Service. The 2014 Golden Gate National Parks BioBlitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event Natural Resource Report NPS/GOGA/NRR—2016/1147 Elizabeth Edson1, Michelle O’Herron1, Alison Forrestel2, Daniel George3 1Golden Gate Parks Conservancy Building 201 Fort Mason San Francisco, CA 94129 2National Park Service. Golden Gate National Recreation Area Fort Cronkhite, Bldg. 1061 Sausalito, CA 94965 3National Park Service. San Francisco Bay Area Network Inventory & Monitoring Program Manager Fort Cronkhite, Bldg. 1063 Sausalito, CA 94965 March 2016 U.S. Department of the Interior National Park Service Natural Resource Stewardship and Science Fort Collins, Colorado The National Park Service, Natural Resource Stewardship and Science office in Fort Collins, Colorado, publishes a range of reports that address natural resource topics. These reports are of interest and applicability to a broad audience in the National Park Service and others in natural resource management, including scientists, conservation and environmental constituencies, and the public. The Natural Resource Report Series is used to disseminate comprehensive information and analysis about natural resources and related topics concerning lands managed by the National Park Service. -

The Diatoms Big Significance of Tiny Glass Houses
GENERAL ¨ ARTICLE The Diatoms Big Significance of Tiny Glass Houses Aditi Kale and Balasubramanian Karthick Diatoms are unique microscopic algae having intricate cell walls made up of silica. They are the major phytoplankton in aquatic ecosystems and account for 20–25% of the oxygen release and carbon fixation in the world. Their most charac- teristic features are mechanisms they have evolved to utilize silica. Due to their distinctive adaptations and ecology, they (left) Aditi Kale is a PhD student with the are used in various fields like biomonitoring, paleoecology, Biodiversity and nanotechnology and forensics. Paleobiology group of Agharkar Research Introduction Institute. She is studying the biogeography of Diatoms (Class: Bacillariophyceae) are unique microscopic al- freshwater diatoms in gae containing silica and having distinct geometrical shapes. Western Ghats for her They are unicellular, eukaryotic and photosynthetic organisms. thesis. Their cell size ranges between 5 µm–0.5 mm. They occur in wet (right) Balasubramanian or moist places where photosynthesis is possible. Diatoms are Karthick is Scientist with Biodiversity and either planktonic (free-floating) or benthic (attached to a substra- Paleobiology group of tum) in Nature (Figure 1). The individuals are solitary or some- Agharkar Research times form colonies. Diatoms are mostly non-motile; however, Institute. His interests some benthic diatoms have a specialized raphe system1 that include diatom taxonomy and ecology, microbial secretes mucilage to attach or glide along a surface. They are also biogeography,andaquatic known to form biofilms, i. e., layers of tightly attached cells of ecology. microorganisms. Biofilms are formed on a solid surface and are often surrounded by extra-cellular fluids. -

Advance View Proofs
Microbes Environ. Vol. XX, No. X, XXX–XXX, XXXX https://www.jstage.jst.go.jp/browse/jsme2 doi:10.1264/jsme2.ME12193 Isolation and Characterization of a Thermophilic, Obligately Anaerobic and Heterotrophic Marine Chloroflexi Bacterium from a Chloroflexi-dominated Microbial Community Associated with a Japanese Shallow Hydrothermal System, and Proposal for Thermomarinilinea lacunofontalis gen. nov., sp. nov. TAKURO NUNOURA1*, MIHO HIRAI1, MASAYUKI MIYAZAKI1, HIROMI KAZAMA1, HIROKO MAKITA1, HISAKO HIRAYAMA1, YASUO FURUSHIMA2, HIROYUKI YAMAMOTO2, HIROYUKI IMACHI1, and KEN TAKAI1 1Subsurface Geobiology & Advanced Research (SUGAR) Project, Extremobiosphere Research Program, Institute of Biogeosciences, Japan Agency for Marine-Earth Science & Technology (JAMSTEC), 2–15 Natsushima-cho, Yokosuka 237–0061, Japan; and 2Marine Biodiversity Research Program, Institute of Biogeosciences, Japan Agency for Marine-Earth Science & Technology (JAMSTEC), 2–15 Natsushima-cho, Yokosuka 237–0061, Japan (Received October 23, 2012—Accepted January 6, 2013—Published online May 11, 2013) A novel marine thermophilic and heterotrophic Anaerolineae bacterium in the phylum Chloroflexi, strain SW7T, was isolated from an in situ colonization system deployed in the main hydrothermal vent of the Taketomi submarine hot spring field located on the southern part of Yaeyama Archipelago, Japan. The microbial community associated with the hydrothermal vent was predominated by thermophilic heterotrophs such as Thermococcaceae and Anaerolineae, and the next dominant population was thermophilic sulfur oxidizers. Both aerobic and anaerobic hydrogenotrophs including methanogens were detected as minor populations. During the culture-dependent viable count analysis in this study, an Anaerolineae strain SW7T was isolated from an enrichment culture at a high dilution rate. Strain SW7T was an obligately anaerobic heterotroph that grew with fermentation and had non-motileProofs thin rods 3.5–16.5 µm in length and 0.2 µm in width constituting multicellular filaments. -

Diatoms Shape the Biogeography of Heterotrophic Prokaryotes in Early Spring in the Southern Ocean
Diatoms shape the biogeography of heterotrophic prokaryotes in early spring in the Southern Ocean Yan Liu, Pavla Debeljak, Mathieu Rembauville, Stéphane Blain, Ingrid Obernosterer To cite this version: Yan Liu, Pavla Debeljak, Mathieu Rembauville, Stéphane Blain, Ingrid Obernosterer. Diatoms shape the biogeography of heterotrophic prokaryotes in early spring in the Southern Ocean. Environmental Microbiology, Society for Applied Microbiology and Wiley-Blackwell, 2019, 21 (4), pp.1452-1465. 10.1111/1462-2920.14579. hal-02383818 HAL Id: hal-02383818 https://hal.archives-ouvertes.fr/hal-02383818 Submitted on 28 Nov 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Diatoms shape the biogeography of heterotrophic prokaryotes in early spring in the Southern Ocean 5 Yan Liu1, Pavla Debeljak1,2, Mathieu Rembauville1, Stéphane Blain1, Ingrid Obernosterer1* 1 Sorbonne Université, CNRS, Laboratoire d'Océanographie Microbienne, LOMIC, F-66650 10 Banyuls-sur-Mer, France 2 Department of Limnology and Bio-Oceanography, University of Vienna, A-1090 Vienna, Austria -

Genomics 98 (2011) 370–375
Genomics 98 (2011) 370–375 Contents lists available at ScienceDirect Genomics journal homepage: www.elsevier.com/locate/ygeno Whole-genome comparison clarifies close phylogenetic relationships between the phyla Dictyoglomi and Thermotogae Hiromi Nishida a,⁎, Teruhiko Beppu b, Kenji Ueda b a Agricultural Bioinformatics Research Unit, Graduate School of Agricultural and Life Sciences, University of Tokyo, 1-1-1 Yayoi, Bunkyo-ku, Tokyo 113-8657, Japan b Life Science Research Center, College of Bioresource Sciences, Nihon University, Fujisawa, Japan article info abstract Article history: The anaerobic thermophilic bacterial genus Dictyoglomus is characterized by the ability to produce useful Received 2 June 2011 enzymes such as amylase, mannanase, and xylanase. Despite the significance, the phylogenetic position of Accepted 1 August 2011 Dictyoglomus has not yet been clarified, since it exhibits ambiguous phylogenetic positions in a single gene Available online 7 August 2011 sequence comparison-based analysis. The number of substitutions at the diverging point of Dictyoglomus is insufficient to show the relationships in a single gene comparison-based analysis. Hence, we studied its Keywords: evolutionary trait based on whole-genome comparison. Both gene content and orthologous protein sequence Whole-genome comparison Dictyoglomus comparisons indicated that Dictyoglomus is most closely related to the phylum Thermotogae and it forms a Bacterial systematics monophyletic group with Coprothermobacter proteolyticus (a constituent of the phylum Firmicutes) and Coprothermobacter proteolyticus Thermotogae. Our findings indicate that C. proteolyticus does not belong to the phylum Firmicutes and that the Thermotogae phylum Dictyoglomi is not closely related to either the phylum Firmicutes or Synergistetes but to the phylum Thermotogae. © 2011 Elsevier Inc. -

Expanding the Chlamydiae Tree
Digital Comprehensive Summaries of Uppsala Dissertations from the Faculty of Science and Technology 2040 Expanding the Chlamydiae tree Insights into genome diversity and evolution JENNAH E. DHARAMSHI ACTA UNIVERSITATIS UPSALIENSIS ISSN 1651-6214 ISBN 978-91-513-1203-3 UPPSALA urn:nbn:se:uu:diva-439996 2021 Dissertation presented at Uppsala University to be publicly examined in A1:111a, Biomedical Centre (BMC), Husargatan 3, Uppsala, Tuesday, 8 June 2021 at 13:15 for the degree of Doctor of Philosophy. The examination will be conducted in English. Faculty examiner: Prof. Dr. Alexander Probst (Faculty of Chemistry, University of Duisburg-Essen). Abstract Dharamshi, J. E. 2021. Expanding the Chlamydiae tree. Insights into genome diversity and evolution. Digital Comprehensive Summaries of Uppsala Dissertations from the Faculty of Science and Technology 2040. 87 pp. Uppsala: Acta Universitatis Upsaliensis. ISBN 978-91-513-1203-3. Chlamydiae is a phylum of obligate intracellular bacteria. They have a conserved lifecycle and infect eukaryotic hosts, ranging from animals to amoeba. Chlamydiae includes pathogens, and is well-studied from a medical perspective. However, the vast majority of chlamydiae diversity exists in environmental samples as part of the uncultivated microbial majority. Exploration of microbial diversity in anoxic deep marine sediments revealed diverse chlamydiae with high relative abundances. Using genome-resolved metagenomics various marine sediment chlamydiae genomes were obtained, which significantly expanded genomic sampling of Chlamydiae diversity. These genomes formed several new clades in phylogenomic analyses, and included Chlamydiaceae relatives. Despite endosymbiosis-associated genomic features, hosts were not identified, suggesting chlamydiae with alternate lifestyles. Genomic investigation of Anoxychlamydiales, newly described here, uncovered genes for hydrogen metabolism and anaerobiosis, suggesting they engage in syntrophic interactions. -

Annual Conference Abstracts
ANNUAL CONFERENCE 14-17 April 2014 Arena and Convention Centre, Liverpool ABSTRACTS SGM ANNUAL CONFERENCE APRIL 2014 ABSTRACTS (LI00Mo1210) – SGM Prize Medal Lecture (LI00Tu1210) – Marjory Stephenson Climate Change, Oceans, and Infectious Disease Prize Lecture Dr. Rita R. Colwell Understanding the basis of antibiotic resistance University of Maryland, College Park, MD, USA as a platform for early drug discovery During the mid-1980s, satellite sensors were developed to monitor Laura JV Piddock land and oceans for purposes of understanding climate, weather, School of Immunity & Infection and Institute of Microbiology and and vegetation distribution and seasonal variations. Subsequently Infection, University of Birmingham, UK inter-relationships of the environment and infectious diseases Antibiotic resistant bacteria are one of the greatest threats to human were investigated, both qualitatively and quantitatively, with health. Resistance can be mediated by numerous mechanisms documentation of the seasonality of diseases, notably malaria including mutations conferring changes to the genes encoding the and cholera by epidemiologists. The new research revealed a very target proteins as well as RND efflux pumps, which confer innate close interaction of the environment and many other infectious multi-drug resistance (MDR) to bacteria. The production of efflux diseases. With satellite sensors, these relationships were pumps can be increased, usually due to mutations in regulatory quantified and comparatively analyzed. More recent studies of genes, and this confers resistance to antibiotics that are often used epidemic diseases have provided models, both retrospective and to treat infections by Gram negative bacteria. RND MDR efflux prospective, for understanding and predicting disease epidemics, systems not only confer antibiotic resistance, but altered expression notably vector borne diseases. -

Mote Marine Laboratory Red Tide Studies
MOTE MARINE LABORATORY RED TIDE STUDIES FINAL REPORT FL DEP Contract MR 042 July 11, 1994 - June 30, 1995 Submitted To: Dr. Karen Steidinger Florida Marine Research Institute FL DEPARTMENT OF ENVIRONMENTAL PROTECTION 100 Eighth Street South East St. Petersburg, FL 33701-3093 Submitted By: Dr. Richard H. Pierce Director of Research MOTE MARINE LABORATORY 1600 Thompson Parkway Sarasota, FL 34236 Mote Marine Laboratory Technical Report No. 429 June 20, 1995 This document is printed on recycled paper Suggested reference Pierce RH. 1995. Mote Marine Red Tide Studies July 11, 1994 - June 30, 1995. Florida Department of Environmental Pro- tection. Contract no MR 042. Mote Marine Lab- oratory Technical Report no 429. 64 p. Available from: Mote Marine Laboratory Library. TABLE OF CONTENTS I. SUMMARY. 1 II. CULTURE MAINTENANCE AND GROWTH STUDIES . 1 Ill. ECOLOGICAL INTERACTION STUDIES . 2 A. Brevetoxin Ingestion in Black Seabass B. Evaluation of Food Carriers C. First Long Term (14 Day) Clam Exposure With Depuration (2/6/95) D. Second Long Term (14 Day) Clam Exposure (3/21/95) IV. RED TIDE FIELD STUDIES . 24 A. 1994 Red Tide Bloom (9/16/94 - 1/4/95) B. Red Tide Bloom (4/13/94 - 6/16/95) C. Red Tide Pigment D. Bacteriological Studies E. Brevetoxin Analysis in Marine Organisms Exposed to Sublethal Levels of the 1994 Natural Red Tide Bloom V. REFERENCES . 61 Tables Table 1. Monthly Combined Production and Use of Laboratory C. breve Culture. ....... 2 Table 2. Brevetoxin Concentration in Brevetoxin Spiked Shrimp and in Black Seabass Muscle Tissue and Digestive Tract Following Ingestion of the Shrimp ............... -

BD™ Gardnerella Selective Agar with 5% Human Blood
INSTRUCTIONS FOR USE – READY-TO-USE PLATED MEDIA PA-254094.06 Rev.: July 2014 BD Gardnerella Selective Agar with 5% Human Blood INTENDED USE BD Gardnerella Selective Agar with 5% Human Blood is a partially selective and differential medium for the isolation of Gardnerella vaginalis from clinical specimens. PRINCIPLES AND EXPLANATION OF THE PROCEDURE Microbiological method. Gardnerella vaginalis is considered to be one of the organisms causing vaginitis.1-4 Although the organism may be present in a high percentage of normal women in the vaginal flora, its importance as a cause of non-specific vaginitis (also called bacterial vaginosis) has never been questioned. In symptomatic women, G. vaginalis frequently is associated with anaerobes such as Prevotella bivia, P. disiens, Mobiluncus, Peptostreptococcus, and/or others which are a regular part of the urethral or intestinal, but not vaginal flora. In non-specific vaginitis, normal Lactobacillus flora is reduced or absent. Gardnerella vaginalis is considered to be the indicator organism for non-specific vaginitis which, in fact, is a polymicrobial infection.3,4 Although non- culture methods such as a direct Gram stain have been recommended in recent years for genital specimens, culture is still preferred by many laboratories.1,5 G. vaginalis may also be responsible for a variety of other diseases such as preterm birth, chorioamnionitis, urinary tract infections, newborn infections, and septicemia.6 The detection of the organism on routinely used media is difficult since Gardnerella and other -

Evolution Génomique Chez Les Bactéries Du Super Phylum Planctomycetes-Verrucomicrobiae-Chlamydia
AIX-MARSEILLE UNIVERSITE FACULTE DE MEDECINE DE MARSEILLE ECOLE DOCTORALE : SCIENCE DE LA VIE ET DE LA SANTE THESE Présentée et publiquement soutenue devant LA FACULTE DE MEDECINE DE MARSEILLE Le 15 janvier 2016 Par Mme Sandrine PINOS Née à Saint-Gaudens le 09 octobre 1989 TITRE DE LA THESE: Evolution génomique chez les bactéries du super phylum Planctomycetes-Verrucomicrobiae-Chlamydia Pour obtenir le grade de DOCTORAT d'AIX-MARSEILLE UNIVERSITE Spécialité : Génomique et Bioinformatique Membres du jury de la Thèse: Pr Didier RAOULT .................................................................................Directeur de thèse Dr Pierre PONTAROTTI ....................................................................Co-directeur de thèse Pr Gilbert GREUB .............................................................................................Rapporteur Dr Pascal SIMONET............................................................................................Rapporteur Laboratoires d’accueil Unité de Recherche sur les Maladies Infectieuses et Tropicales Emergentes – UMR CNRS 6236, IRD 198 I2M - UMR CNRS 7373 - EBM 1 Avant propos Le format de présentation de cette thèse correspond à une recommandation de la spécialité Maladies Infectieuses et Microbiologie, à l’intérieur du Master de Sciences de la Vie et de la Santé qui dépend de l’Ecole Doctorale des Sciences de la Vie de Marseille. Le candidat est amené à respecter des règles qui lui sont imposées et qui comportent un format de thèse utilisé dans le Nord de l’Europe permettant un meilleur rangement que les thèses traditionnelles. Par ailleurs, la partie introduction et bibliographie est remplacée par une revue envoyée dans un journal afin de permettre une évaluation extérieure de la qualité de la revue et de permettre à l’étudiant de le commencer le plus tôt possible une bibliographie exhaustive sur le domaine de cette thèse. Par ailleurs, la thèse est présentée sur article publié, accepté ou soumis associé d’un bref commentaire donnant le sens général du travail. -

Table S4. Phylogenetic Distribution of Bacterial and Archaea Genomes in Groups A, B, C, D, and X
Table S4. Phylogenetic distribution of bacterial and archaea genomes in groups A, B, C, D, and X. Group A a: Total number of genomes in the taxon b: Number of group A genomes in the taxon c: Percentage of group A genomes in the taxon a b c cellular organisms 5007 2974 59.4 |__ Bacteria 4769 2935 61.5 | |__ Proteobacteria 1854 1570 84.7 | | |__ Gammaproteobacteria 711 631 88.7 | | | |__ Enterobacterales 112 97 86.6 | | | | |__ Enterobacteriaceae 41 32 78.0 | | | | | |__ unclassified Enterobacteriaceae 13 7 53.8 | | | | |__ Erwiniaceae 30 28 93.3 | | | | | |__ Erwinia 10 10 100.0 | | | | | |__ Buchnera 8 8 100.0 | | | | | | |__ Buchnera aphidicola 8 8 100.0 | | | | | |__ Pantoea 8 8 100.0 | | | | |__ Yersiniaceae 14 14 100.0 | | | | | |__ Serratia 8 8 100.0 | | | | |__ Morganellaceae 13 10 76.9 | | | | |__ Pectobacteriaceae 8 8 100.0 | | | |__ Alteromonadales 94 94 100.0 | | | | |__ Alteromonadaceae 34 34 100.0 | | | | | |__ Marinobacter 12 12 100.0 | | | | |__ Shewanellaceae 17 17 100.0 | | | | | |__ Shewanella 17 17 100.0 | | | | |__ Pseudoalteromonadaceae 16 16 100.0 | | | | | |__ Pseudoalteromonas 15 15 100.0 | | | | |__ Idiomarinaceae 9 9 100.0 | | | | | |__ Idiomarina 9 9 100.0 | | | | |__ Colwelliaceae 6 6 100.0 | | | |__ Pseudomonadales 81 81 100.0 | | | | |__ Moraxellaceae 41 41 100.0 | | | | | |__ Acinetobacter 25 25 100.0 | | | | | |__ Psychrobacter 8 8 100.0 | | | | | |__ Moraxella 6 6 100.0 | | | | |__ Pseudomonadaceae 40 40 100.0 | | | | | |__ Pseudomonas 38 38 100.0 | | | |__ Oceanospirillales 73 72 98.6 | | | | |__ Oceanospirillaceae