European Ordering Rules ±± Third Draft
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unicode Request for Cyrillic Modifier Letters Superscript Modifiers
Unicode request for Cyrillic modifier letters L2/21-107 Kirk Miller, [email protected] 2021 June 07 This is a request for spacing superscript and subscript Cyrillic characters. It has been favorably reviewed by Sebastian Kempgen (University of Bamberg) and others at the Commission for Computer Supported Processing of Medieval Slavonic Manuscripts and Early Printed Books. Cyrillic-based phonetic transcription uses superscript modifier letters in a manner analogous to the IPA. This convention is widespread, found in both academic publication and standard dictionaries. Transcription of pronunciations into Cyrillic is the norm for monolingual dictionaries, and Cyrillic rather than IPA is often found in linguistic descriptions as well, as seen in the illustrations below for Slavic dialectology, Yugur (Yellow Uyghur) and Evenki. The Great Russian Encyclopedia states that Cyrillic notation is more common in Russian studies than is IPA (‘Transkripcija’, Bol’šaja rossijskaja ènciplopedija, Russian Ministry of Culture, 2005–2019). Unicode currently encodes only three modifier Cyrillic letters: U+A69C ⟨ꚜ⟩ and U+A69D ⟨ꚝ⟩, intended for descriptions of Baltic languages in Latin script but ubiquitous for Slavic languages in Cyrillic script, and U+1D78 ⟨ᵸ⟩, used for nasalized vowels, for example in descriptions of Chechen. The requested spacing modifier letters cannot be substituted by the encoded combining diacritics because (a) some authors contrast them, and (b) they themselves need to be able to take combining diacritics, including diacritics that go under the modifier letter, as in ⟨ᶟ̭̈⟩BA . (See next section and e.g. Figure 18. ) In addition, some linguists make a distinction between spacing superscript letters, used for phonetic detail as in the IPA tradition, and spacing subscript letters, used to denote phonological concepts such as archiphonemes. -

+1. Introduction 2. Cyrillic Letter Rumanian Yn
MAIN.HTM 10/13/2006 06:42 PM +1. INTRODUCTION These are comments to "Additional Cyrillic Characters In Unicode: A Preliminary Proposal". I'm examining each section of that document, as well as adding some extra notes (marked "+" in titles). Below I use standard Russian Cyrillic characters; please be sure that you have appropriate fonts installed. If everything is OK, the following two lines must look similarly (encoding CP-1251): (sample Cyrillic letters) АабВЕеЗКкМНОопРрСсТуХхЧЬ (Latin letters and digits) Aa6BEe3KkMHOonPpCcTyXx4b 2. CYRILLIC LETTER RUMANIAN YN In the late Cyrillic semi-uncial Rumanian/Moldavian editions, the shape of YN was very similar to inverted PSI, see the following sample from the Ноул Тестамент (New Testament) of 1818, Neamt/Нямец, folio 542 v.: file:///Users/everson/Documents/Eudora%20Folder/Attachments%20Folder/Addons/MAIN.HTM Page 1 of 28 MAIN.HTM 10/13/2006 06:42 PM Here you can see YN and PSI in both upper- and lowercase forms. Note that the upper part of YN is not a sharp arrowhead, but something horizontally cut even with kind of serif (in the uppercase form). Thus, the shape of the letter in modern-style fonts (like Times or Arial) may look somewhat similar to Cyrillic "Л"/"л" with the central vertical stem looking like in lowercase "ф" drawn from the middle of upper horizontal line downwards, with regular serif at the bottom (horizontal, not slanted): Compare also with the proposed shape of PSI (Section 36). 3. CYRILLIC LETTER IOTIFIED A file:///Users/everson/Documents/Eudora%20Folder/Attachments%20Folder/Addons/MAIN.HTM Page 2 of 28 MAIN.HTM 10/13/2006 06:42 PM I support the idea that "IA" must be separated from "Я". -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Ffontiau Cymraeg
This publication is available in other languages and formats on request. Mae'r cyhoeddiad hwn ar gael mewn ieithoedd a fformatau eraill ar gais. [email protected] www.caerphilly.gov.uk/equalities How to type Accented Characters This guidance document has been produced to provide practical help when typing letters or circulars, or when designing posters or flyers so that getting accents on various letters when typing is made easier. The guide should be used alongside the Council’s Guidance on Equalities in Designing and Printing. Please note this is for PCs only and will not work on Macs. Firstly, on your keyboard make sure the Num Lock is switched on, or the codes shown in this document won’t work (this button is found above the numeric keypad on the right of your keyboard). By pressing the ALT key (to the left of the space bar), holding it down and then entering a certain sequence of numbers on the numeric keypad, it's very easy to get almost any accented character you want. For example, to get the letter “ô”, press and hold the ALT key, type in the code 0 2 4 4, then release the ALT key. The number sequences shown from page 3 onwards work in most fonts in order to get an accent over “a, e, i, o, u”, the vowels in the English alphabet. In other languages, for example in French, the letter "c" can be accented and in Spanish, "n" can be accented too. Many other languages have accents on consonants as well as vowels. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Centc304 N932
CEN/TC304 N932 Source: Secretariat Date: 15 Dec 1999 Title: European Fallback Rules, ballot Mailed: 15 Dec 1999 Status: TC-enquiry: DEADLINE 1st March 2000 Action required: Respond before 1 March 2000 * Notes: This is a TC-enquiry, to establish the suitability of N932 to be sent for Formal vote as prENV. National member body officers, responsible for CEN/TC304 issues are asked to fill in this form and send it to the TC-secretariat before 1 March 2000. Comments in any form will be forwarded to the CEN/TC 304 Project Team of European Fallback Rules. The PT will before the next plenary of TC304 in April 2000 produce a disposition of comments and a revised draft. The PT will produce a disposition of comments and plans to ask the TC304 plenary in November to approve a revised draft to be sent for Formal Vote. Comments from affiliated members of CEN and liaisons are welcome and will be considered. Country:______________________________ Approves without comments ___ Approves with comments ___ Disapproves with comments ___ Date:_______________ Signature_____________________________________(National Member Body officer) Name:__________________________________ EUROPEAN PRESTANDARD DRAFT PRÉNORME EUROPÉENNE prENV_____ EUROPÄISCHE VORNORM ICS: 35.040 Descriptors: Data processing, information interchange, text processing, text communication, graphic characters, character sets, representation of characters, coded character sets, conversion, fallback English version Information Technology European fallback rules Technologies de l'information- Informations technologies Character repertoire and coding transformations: Character repertoire and coding transformations: European fallback rules - Nº 1 European fallback rules - Nº 1 This draft ENV is submitted to CEN members for Formal Vote. It has been drawn up by the Technical Committee CEN/TC 304. -

Kyrillische Schrift Für Den Computer
Hanna-Chris Gast Kyrillische Schrift für den Computer Benennung der Buchstaben, Vergleich der Transkriptionen in Bibliotheken und Standesämtern, Auflistung der Unicodes sowie Tastaturbelegung für Windows XP Inhalt Seite Vorwort ................................................................................................................................................ 2 1 Kyrillische Schriftzeichen mit Benennung................................................................................... 3 1.1 Die Buchstaben im Russischen mit Schreibschrift und Aussprache.................................. 3 1.2 Kyrillische Schriftzeichen anderer slawischer Sprachen.................................................... 9 1.3 Veraltete kyrillische Schriftzeichen .................................................................................... 10 1.4 Die gebräuchlichen Sonderzeichen ..................................................................................... 11 2 Transliterationen und Transkriptionen (Umschriften) .......................................................... 13 2.1 Begriffe zum Thema Transkription/Transliteration/Umschrift ...................................... 13 2.2 Normen und Vorschriften für Bibliotheken und Standesämter....................................... 15 2.3 Tabellarische Übersicht der Umschriften aus dem Russischen ....................................... 21 2.4 Transliterationen veralteter kyrillischer Buchstaben ....................................................... 25 2.5 Transliterationen bei anderen slawischen -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets............................................................................................................. -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -
Dyalog APL Binding Strengths
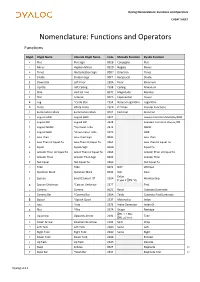
Dyalog Nomenclature: Functions and Operators CHEAT SHEET Nomenclature: Functions and Operators Functions Glyph Glyph Name Unicode Glyph Name Code Monadic Function Dyadic Function + Plus Plus Sign 002B Conjugate Plus - Minus Hyphen-Minus 002D Negate Minus × Times Multiplication Sign 00D7 Direction Times ÷ Divide Division Sign 00F7 Reciprocal Divide ⌊ Downstile Left Floor 230A Floor Minimum ⌈ Upstile Left Ceiling 2308 Ceiling Maximum | Stile Vertical Line 007C Magnitude Residue * Star Asterisk 002A Exponential Power ⍟ Log *Circle Star 235F Natural Logarithm Logarithm ○ Circle White Circle 25CB Pi Times Circular Functions ! Exclamation Mark Exclamation Mark 0021 Factorial Binomial ∧ Logical AND Logical AND 2227 Lowest Common Multiple/AND ∨ Logical OR Logical OR 2228 Greatest Common Divisor/OR ⍲ Logical NAND *Up Caret Tilde 2372 NAND ⍱ Logical NOR *Down Caret Tilde 2371 NOR < Less Than Less-Than Sign 003C Less Than ≤ Less Than Or Equal To Less-Than Or Equal To 2264 Less Than Or Equal To = Equal Equals Sign 003D Equal To ≥ Greater Than Or Equal To Great-Than Or Equal To 2265 Greater Than Or Equal To > Greater Than Greater-Than Sign 003E Greater Than ≠ Not Equal Not Equal To 2260 Not Equal To ~ Tilde Tilde 007E NOT Without ? Question Mark Question Mark 003F Roll Deal Enlist ∊ Epsilon Small Element Of 220A Membership (Type if ⎕ML=0) ⍷ Epsilon Underbar *Epsilon Underbar 2377 Find , Comma Comma 002C Ravel Catenate/Laminate ⍪ Comma Bar *Comma Bar 236A Table Catenate First/Laminate ⌷ Squad *Squish Quad 2337 Materialise Index ⍳ Iota *Iota 2373 Index -

List of Approved Special Characters
List of Approved Special Characters The following list represents the Graduate Division's approved character list for display of dissertation titles in the Hooding Booklet. Please note these characters will not display when your dissertation is published on ProQuest's site. To insert a special character, simply hold the ALT key on your keyboard and enter in the corresponding code. This is only for entering in a special character for your title or your name. The abstract section has different requirements. See abstract for more details. Special Character Alt+ Description 0032 Space ! 0033 Exclamation mark '" 0034 Double quotes (or speech marks) # 0035 Number $ 0036 Dollar % 0037 Procenttecken & 0038 Ampersand '' 0039 Single quote ( 0040 Open parenthesis (or open bracket) ) 0041 Close parenthesis (or close bracket) * 0042 Asterisk + 0043 Plus , 0044 Comma ‐ 0045 Hyphen . 0046 Period, dot or full stop / 0047 Slash or divide 0 0048 Zero 1 0049 One 2 0050 Two 3 0051 Three 4 0052 Four 5 0053 Five 6 0054 Six 7 0055 Seven 8 0056 Eight 9 0057 Nine : 0058 Colon ; 0059 Semicolon < 0060 Less than (or open angled bracket) = 0061 Equals > 0062 Greater than (or close angled bracket) ? 0063 Question mark @ 0064 At symbol A 0065 Uppercase A B 0066 Uppercase B C 0067 Uppercase C D 0068 Uppercase D E 0069 Uppercase E List of Approved Special Characters F 0070 Uppercase F G 0071 Uppercase G H 0072 Uppercase H I 0073 Uppercase I J 0074 Uppercase J K 0075 Uppercase K L 0076 Uppercase L M 0077 Uppercase M N 0078 Uppercase N O 0079 Uppercase O P 0080 Uppercase -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS