When and Why Your Code Starts to Smell Bad (And Whether the Smells Go Away)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Translating Risk Assessment to Contingency Planning for CO2 Geologic Storage: a Methodological Framework
Translating Risk Assessment to Contingency Planning for CO2 Geologic Storage: A Methodological Framework Authors Karim Farhat a and Sally M. Benson b a Department of Management Science and Engineering, Stanford University, Stanford, California, USA b Department of Energy Resources Engineering, Stanford University, Stanford, California, USA Contact Information Karim Farhat: [email protected] Sally M. Benson: [email protected] Corresponding Author Karim Farhat 475 Via Ortega Huang Engineering Center, 245A Stanford, CA 94305, USA Email: [email protected] Tel: +1-650-644-7451 May 2016 1 Abstract In order to ensure safe and effective long-term geologic storage of carbon dioxide (CO2), existing regulations require both assessing leakage risks and responding to leakage incidents through corrective measures. However, until now, these two pieces of risk management have been usually addressed separately. This study proposes a methodological framework that bridges risk assessment to corrective measures through clear and collaborative contingency planning. We achieve this goal in three consecutive steps. First, a probabilistic risk assessment (PRA) approach is adopted to characterize potential leakage features, events and processes (FEP) in a Bayesian events tree (BET), resulting in a risk assessment matrix (RAM). The RAM depicts a mutually exclusive and collectively exhaustive set of leakage scenarios with quantified likelihood, impact, and tolerance levels. Second, the risk assessment matrix is translated to a contingency planning matrix (CPM) that incorporates a tiered- contingency system for risk-preparedness and incident-response. The leakage likelihood and impact dimensions of RAM are translated to resource proximity and variety dimensions in CPM, respectively. To ensure both rapid and thorough contingency planning, more likely or frequent risks require more proximate resources while more impactful risks require more various resources. -

2017 Ram 1500/2500/3500 Truck Owner's Manual
2017 RAM TRUCK 1500/2500/3500 STICK WITH THE SPECIALISTS® RAM TRUCK 2017 1500/2500/3500 OWNER’S MANUAL 17D241-126-AD ©2016 FCA US LLC. All Rights Reserved. fourth Edition Ram is a registered trademark of FCA US LLC. Printed in U.S.A. VEHICLES SOLD IN CANADA This manual illustrates and describes the operation of With respect to any Vehicles Sold in Canada, the name FCA features and equipment that are either standard or op- US LLC shall be deemed to be deleted and the name FCA tional on this vehicle. This manual may also include a Canada Inc. used in substitution therefore. description of features and equipment that are no longer DRIVING AND ALCOHOL available or were not ordered on this vehicle. Please Drunken driving is one of the most frequent causes of disregard any features and equipment described in this accidents. manual that are not on this vehicle. Your driving ability can be seriously impaired with blood FCA US LLC reserves the right to make changes in design alcohol levels far below the legal minimum. If you are and specifications, and/or make additions to or improve- drinking, don’t drive. Ride with a designated non- ments to its products without imposing any obligation drinking driver, call a cab, a friend, or use public trans- upon itself to install them on products previously manu- portation. factured. WARNING! Driving after drinking can lead to an accident. Your perceptions are less sharp, your reflexes are slower, and your judgment is impaired when you have been drinking. Never drink and then drive. -

Superman(Jjabrams).Pdf
L, July 26, 2002 SUPERMAN FADE IN: . .. INT. TV MONITOR - DAY TIGHT ON a video image of a news telecast. Ex ~t th efs no one there -- just the empty newsdesk. Odd. e Suddenly a NEWSCASTER appears behind the desk - rushed and unkempt. Fumbles with his clip mic trembling. It's unsettling; be looks up at us, desperately to sound confident. But his voice Nm?!3CASTER Ladies and gentlen. If you are watching this, and are taking shelter underground, we strongly urg you -- all of vou -- to do so immediately. Anywhere-- anywhere e are, anywhere you can find. (beat) At this hour, all we know is that there are visitors on this planet-- and that there's a conflict between 'v them-- the Giza Pyramids have been @ destroyed-- sections of Paris. Massive fires are raging from Venezuela to Chile-- a great deal of Seoul, Korea ... no longer exists ... All this man wants to-do is cry. But he's a realize now that werite been SLOWLY PUSHING IN NEWSCASTER ( con t ' d ) Only weeks ago this report would've seemed.. ludicrous. Aliens.. usi Earth as a battleground. .. ( then, with growing venom: ) ... but that was before Superman. (beat1 It turns out that our faith was naive. Premature. Perhaps, given Y the state pf the world. .- simply desperate-- .. , Something urgent is YELLED from behind the c Newscaster looks off, ' fied -- he yells but it's masked by a SHATT!L'RING -- FLYING GLASS -- the video . .. camera SHAKES -- . -.~. &+,. 9' .. .-. .. .. .: . .I _ - - . - .. ( CONTINUED) . 2. CONTINUED: 4 -. A TERRIBLE WHI.STLE, then an EXPIX)SION -- '1 WHIPPED OUT OF FRAME in the same horrible inst . -

Virgil, Aeneid 11 (Pallas & Camilla) 1–224, 498–521, 532–96, 648–89, 725–835 G
Virgil, Aeneid 11 (Pallas & Camilla) 1–224, 498–521, 532–96, 648–89, 725–835 G Latin text, study aids with vocabulary, and commentary ILDENHARD INGO GILDENHARD AND JOHN HENDERSON A dead boy (Pallas) and the death of a girl (Camilla) loom over the opening and the closing part of the eleventh book of the Aeneid. Following the savage slaughter in Aeneid 10, the AND book opens in a mournful mood as the warring parti es revisit yesterday’s killing fi elds to att end to their dead. One casualty in parti cular commands att enti on: Aeneas’ protégé H Pallas, killed and despoiled by Turnus in the previous book. His death plunges his father ENDERSON Evander and his surrogate father Aeneas into heart-rending despair – and helps set up the foundati onal act of sacrifi cial brutality that caps the poem, when Aeneas seeks to avenge Pallas by slaying Turnus in wrathful fury. Turnus’ departure from the living is prefi gured by that of his ally Camilla, a maiden schooled in the marti al arts, who sets the mold for warrior princesses such as Xena and Wonder Woman. In the fi nal third of Aeneid 11, she wreaks havoc not just on the batt lefi eld but on gender stereotypes and the conventi ons of the epic genre, before she too succumbs to a premature death. In the porti ons of the book selected for discussion here, Virgil off ers some of his most emoti ve (and disturbing) meditati ons on the tragic nature of human existence – but also knows how to lighten the mood with a bit of drag. -

Roman Criminal Law and Legal Narrative in the Neronian Books of the Annals of Tacitus
Loyola University Chicago Loyola eCommons Dissertations Theses and Dissertations 1993 Roman Criminal Law and Legal Narrative in the Neronian Books of the Annals of Tacitus John Warren Thomas Loyola University Chicago Follow this and additional works at: https://ecommons.luc.edu/luc_diss Part of the Ancient History, Greek and Roman through Late Antiquity Commons Recommended Citation Thomas, John Warren, "Roman Criminal Law and Legal Narrative in the Neronian Books of the Annals of Tacitus" (1993). Dissertations. 3288. https://ecommons.luc.edu/luc_diss/3288 This Dissertation is brought to you for free and open access by the Theses and Dissertations at Loyola eCommons. It has been accepted for inclusion in Dissertations by an authorized administrator of Loyola eCommons. For more information, please contact [email protected]. This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 License. Copyright © 1993 John Warren Thomas LOYOLA UNIVERSITY OF CHICAGO ROMAN CRIMINAL LAW AND LEGAL NARRATIVE IN THE NERONIAN BOOKS OF THE ANNALS OF TACITUS A DISSERTATION SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF CLASSICAL STUDIES BY JOHN WARREN THOMAS III CHICAGO, ILLINOIS MAY 1993 © Copyright by John W. Thomas III, 1993 All Rights Reserved To Kirsten Fortuna spondet multa multis, Praestat nemini. Vive in dies et horas, Nam proprium est nihil. CIL 1.1219 ACKNOWLEDGMENTS For the completion of this study I gratefully acknowledge the direction of Drs. James G. Keenan, John F. Makowski, and Fr. John P. Murphy S. J., whose criticism and advice have been invaluable. -

UC Berkeley UC Berkeley Electronic Theses and Dissertations
UC Berkeley UC Berkeley Electronic Theses and Dissertations Title Visions and Revisions: Gerald of Wales, Authorship, and the Construction of Political, Religious, and Legal Geographies in Twelfth and Thirteenth Century Britain Permalink https://escholarship.org/uc/item/5905x7t1 Author Sargent, Amelia Publication Date 2011 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Visions and Revisions: Gerald of Wales, Authorship, and the Construction of Political, Religious, and Legal Geographies in Twelfth and Thirteenth Century Britain by Amelia Lynn Borrego Sargent A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Comparative Literature in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Frank Bezner, Chair Professor Maura Nolan Professor Joseph Duggan SPRING 2011 Visions and Revisions: Gerald of Wales, Authorship, and the Construction of Political, Religious, and Legal Geographies in Twelfth and Thirteenth Century Britain © 2011 by Amelia Lynn Borrego Sargent Abstract Visions and Revisions: Gerald of Wales, Authorship, and the Construction of Political, Religious, and Legal Geographies in Twelfth and Thirteenth Century Britain by Amelia Lynn Borrego Sargent Doctor of Philosophy in Comparative Literature University of California, Berkeley Professor Frank Bezner, Chair Gerald of Wales revised his Topographia Hibernica and Itinerarium Kambriae multiple times over the course -

2021 RAM Plan
202 1 RAM Plan Administered by Anthem Blue Cross and Blue Shield is the trade name of Rocky Mountain Hospital and Medical Service, Inc. HMO products are underwritten by HMO Colorado, Inc. and HMO Colorado, Inc. dba HMO Nevada. Life and disability products underwritten by Anthem Life Insurance Company. Independent licensees of the Blue Cross and Blue Shield Association. ® ANTHEM is a registered trademark of Anthem Insurance Companies, Inc. The Blue Cross and Blue Shield names and symbols are registered marks of the Blue Cross and Blue Shield Association Si usted necesita ayuda en español para entender éste documento, puede solicitarla gratis llamando al número de servicio al cliente que aparece en su tarjeta de identificación o en su folleto de inscripción. Schedule of Benefits Colorado State University RAM Plan Effective January 1, 2021 PART A: TYPE OF COVERAGE1 IN-NETWORK: PARTICIPATING PROVIDERS: You will have access to a National Blue Cross and Blue Shield PPO Network. Your benefit will be the highest level when you receive covered services from a participating provider. (You are responsible for any applicable copayments, deductible and coinsurance). Anthem Blue Cross and Blue Shield will pay the participating provider directly. OUT-OF-NETWORK: NON-PARTICIPATING PROVIDERS: Non-participating facilities or providers have not entered into any agreement with Anthem Blue Cross and Blue Shield. They may bill Anthem Blue Cross and Blue Shield or the patient. Anthem Blue Cross and Blue Shield will pay you. It is your responsibility to pay the non-participating providers. PART B: SUMMARY OF BENEFITS Important Note: This and the following pages contain a limited description of the coverage available through this group plan. -

2016 RAM Commercial Chassis Cab Owner's Manual
2016 Chassis Cab STICK WITH THE SPECIALISTS® 2016 Chassis Cab 16DD43-126-AD OWNER’S MANUAL ©2015 FCA US LLC. All Rights Reserved. Fourth Edition Ram is a registered trademark of FCA US LLC. Printed in U.S.A. VEHICLES SOLD IN CANADA This manual illustrates and describes the operation of With respect to any Vehicles Sold in Canada, the name FCA features and equipment that are either standard or op- US LLC shall be deemed to be deleted and the name FCA tional on this vehicle. This manual may also include a Canada Inc. used in substitution therefore. description of features and equipment that are no longer DRIVING AND ALCOHOL available or were not ordered on this vehicle. Please Drunken driving is one of the most frequent causes of disregard any features and equipment described in this accidents. manual that are not on this vehicle. Your driving ability can be seriously impaired with blood FCA US LLC reserves the right to make changes in design alcohol levels far below the legal minimum. If you are and specifications, and/or make additions to or improve- drinking, don’t drive. Ride with a designated non- ments to its products without imposing any obligation drinking driver, call a cab, a friend, or use public trans- upon itself to install them on products previously manu- portation. factured. WARNING! Driving after drinking can lead to an accident. Your perceptions are less sharp, your reflexes are slower, and your judgment is impaired when you have been drinking. Never drink and then drive. Copyright © 2015 FCA US LLC SECTION TABLE OF CONTENTS PAGE 1 1 INTRODUCTION . -

Devils, Witches, Pagans and Vampires: Studies in the Magical World View (Dr
Fort Hays State University FHSU Scholars Repository Fort Hays Studies Series 1985 Devils, Witches, Pagans and Vampires: Studies in the Magical World View (Dr. Caligari's Carnival of Shadows Halloween Festival Fort Hays State University) Robert Luehrs Fort Hays State University, [email protected] Gerry R. Cox Fort Hays State University Ronald J. Fundis Fort Hays State University Jeffrey Burton Russell Fort Hays State University Follow this and additional works at: https://scholars.fhsu.edu/fort_hays_studies_series Part of the English Language and Literature Commons Recommended Citation Luehrs, Robert; Cox, Gerry R.; Fundis, Ronald J.; and Russell, Jeffrey Burton, "Devils, Witches, Pagans and Vampires: Studies in the Magical World View (Dr. Caligari's Carnival of Shadows Halloween Festival Fort Hays State University)" (1985). Fort Hays Studies Series. 29. https://scholars.fhsu.edu/fort_hays_studies_series/29 This Book is brought to you for free and open access by FHSU Scholars Repository. It has been accepted for inclusion in Fort Hays Studies Series by an authorized administrator of FHSU Scholars Repository. /7JS FORT HAYS STUD I ES Third Series No. 5 1985 HUMANITIES Devils, Witches, Pagans and Vampires: Studies in the Magical World View (Dr. Caligari's Carnival of Shadows Halloween Festival Fort Hays State University) FORT HAYS STATE UNIVERSITY Museum of the High Plains Fort Hays Studies; Third Series (Humanities) Number 5 Hays, Kansas Copyright@ 1985 b~· Fort Hays Studies Committee Fort Hays State University is located on the eastern margin of the High Plains, an area of one of the most complete section of late cretaceous rocks in North America. The terrain of the Fort Hays region is not that of the forests to the east nor of the mountains to the west. -

When and Why Your Code Starts to Smell
When and Why Your Code Starts to Smell Bad Michele Tufano∗, Fabio Palombay, Gabriele Bavotaz, Rocco Olivetox, Massimiliano Di Pentaz, Andrea De Luciay, Denys Poshyvanyk∗ ∗The College of William and Mary, Williamsburg, VA, USA - yUniversity of Salerno, Fisciano (SA), Italy zUniversity of Sannio, Benevento, Italy - xUniversity of Molise, Pesche (IS), Italy Abstract—In past and recent years, the issues related to man- static code analysis [44], or analysis of software changes [37]. aging technical debt received significant attention by researchers While these tools provide relatively accurate and complete from both industry and academia. There are several factors that identification of a wide variety of smells, most of them work contribute to technical debt. One of these is represented by code bad smells, i.e., symptoms of poor design and implementation by “taking a snapshot” of the system or by looking at recent choices. While the repercussions of smells on code quality have changes, hence providing a snapshot-based recommendation to been empirically assessed, there is still only anecdotal evidence the developer. Hence, they do not consider the circumstances on when and why bad smells are introduced. To fill this gap, that could have caused the smell introduction. In order to better we conducted a large empirical study over the change history of support developers in planning actions to improve design and 200 open source projects from different software ecosystems and investigated when bad smells are introduced by developers, and source code quality, it is imperative to have a contextualized the circumstances and reasons behind their introduction. Our understanding of the circumstances under which particular study required the development of a strategy to identify smell- smells occur. -

Ramamurthy, Priti, Ed. Spotlight on Ramayana
DOCUMENT RESUME ED 426 010 SO 029 230 AUTHOR Wadley, Susan, Ed.; Ramamurthy, Priti, Ed. TITLE Spotlight on Ramayana: An Enduring Tradition. INSTITUTION American Forum for Global Education, New York, NY. SPONS AGENCY Collaborative for Humanities and Arts Teaching.; National Endowment for the Humanities (NFAH), Washington, DC. ISBN ISBN-09-44675-54-9 PUB DATE 1995-00-00 NOTE 368p.; Funding also provided by CHART, Collaboratives for Humanities and Arts Teaching. AVAILABLE FROM The American Forum for Global Education, 120 Wall Street, New York, NY 10005; (Tel: 212-742-8232; Fax: 212-742-8752; e-mail: [email protected] ($40, based on numbers for quantity). PUB TYPE Guides Non-Classroom (055) EDRS PRICE MF01/PC15 Plus Postage. DESCRIPTORS Foreign Countries; *Indians; *Instructional Materials; Literature; Multicultural Education; *Non Western Civilization; Secondary Education; Social Studies IDENTIFIERS *India; *Ramayana ABSTRACT This collection of lessons was developed by teachers in an institute focusing on teaching about India and the Ramayana. Essays providing background information are "The Oral Tradition and the Many 'Ramayanas'" (Philip Lutgendorf) and "Bringing Ramayana into the Classroom" (Hazel Sara Greenberg) .After an introduction by Susan Wadley, a Ramayana glossary, a piece called "The Ramayana! A 'Telling' of the Ancient Indian Epic," and maps of India, the sections include: (1) "How is Ramayana Part of the Great Storytelling Tradition?"; (2) "To What Extent Does Ramayana Introduce India and Its Culture?"; (3) "To What Degree Does Ramayana Help Us Comprehend Hindu Values and Religion?"; (4) "How Can Ramayana Help Us Gain an Understanding of Hindu Rituals?"; and (5)"How Does Ramayana Reflect Change Over Time and Space?" There are 25 units with lessons throughout the five sections. -
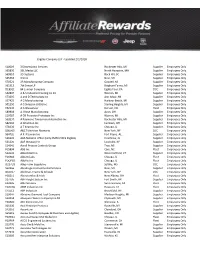
Eligible Company List - Updated 2/1/2018
Eligible Company List - Updated 2/1/2018 S10009 3 Dimensional Services Rochester Hills, MI Supplier Employees Only S65830 3BL Media LLC North Hampton, MA Supplier Employees Only S69510 3D Systems Rock Hill, SC Supplier Employees Only S65364 3IS Inc Novi, MI Supplier Employees Only S70521 3R Manufacturing Company Goodell, MI Supplier Employees Only S61313 7th Sense LP Bingham Farms, MI Supplier Employees Only D18911 84 Lumber Company Eighty Four, PA DCC Employees Only S42897 A & S Industrial Coating Co Inc Warren, MI Supplier Employees Only S73205 A and D Technology Inc Ann Arbor, MI Supplier Employees Only S57425 A G Manufacturing Harbour Beach, MI Supplier Employees Only S01250 A G Simpson (USA) Inc Sterling Heights, MI Supplier Employees Only F02130 A G Wassenaar Denver, CO Fleet Employees Only S80904 A J Rose Manufacturing Avon, OH Supplier Employees Only S19787 A OK Precision Prototype Inc Warren, MI Supplier Employees Only S62637 A Raymond Tinnerman Automotive Inc Rochester Hills, MI Supplier Employees Only S82162 A Schulman Inc Fairlawn, OH Supplier Employees Only S78336 A T Kearney Inc Chicago, IL Supplier Employees Only D80005 A&E Television Networks New York, NY DCC Employees Only S64720 A.P. Plasman Inc. Fort Payne, AL Supplier Employees Only S36205 AAA National Office (Only EMPLOYEES Eligible) Heathrow, FL Supplier Employees Only S31320 AAF McQuay Inc Louisville, KY Supplier Employees Only S14541 Aarell Process Controls Group Troy, MI Supplier Employees Only F05894 ABB Inc Cary, NC Fleet Employees Only S10035 Abbott Ball Co