TDC Syllabus Under CBCS for Persian, Urdu, Bodo, Mizo, Nepali and Hmar
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Origin and Development of the Meitei Language
International Journal of Multidisciplinary Research and Modern Education (IJMRME) ISSN (Online): 2454 - 6119 (www.rdmodernresearch.org) Volume II, Issue I, 2016 ORIGIN AND DEVELOPMENT OF THE MEITEI LANGUAGE Khongbantabam Naobi Devi Ph.D Scholar, Department of English, Ethiraj College for Women, Chennai, Tamilnadu Abstract: Meitei language is an Indo-Aryan language. The Indo- Aryans came to Manipur and settled in the Manipur from the 4th century B.C. onwards. The noted historian and scholar R.K. Jhalajit Singh present his views on the topic to Dr. Suniti Kumar Chatterjee, the great scholar and experts on language. He expressed as Meitei language may not belong to the Kuki- Chin sub-group of the Tibeto-Burman branch; but belongs to the Sino-Tibetan family of language. All the language that belongs to the Tibeto-Burman, a sub-branch of the Sino- Tibetan family of languages, is mono- syllabic. The Meiteis language is not a monosyllabic language; it is a polysyllabic language. In meiteis language, majority of words have more than one syllable. A language should be classified because of grammar. This is the universal principle accepted on all. A language cannot be classified according to vocabulary. If we begin to classify a language according to its vocabulary, the results will be incorrect. The first settlers of the Indo-Aryans in Manipur spoke Sanskrit. Later settlers spoke Prakrit. When Prakrit was removed as spoken language, they spoke Apabhransha.. The combination of Apabhransha and Mongoloid languages gave birth to the Manipuri language by about 1074 A.D. In the olden days of the Meitei language, which was formed by the interaction of Apabhransha and Mongoloid languages, the most important words were taken from Sanskrit. -

Word-Order in Boro Language
Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930 Word-Order in Boro Language Dr. Kanun Basumatary Guest Lecturer, North Eastern Regional Language Centre Guwahati-29, Assam, India Abstract: The present study attempts to analysis and to discuss about the word-order of the Boro language. The Boro language is originated from the Tibeto-Burman group of Sino-Tibetan language family. The language is mainly spoken in Assam and its adjacent areas or countries of India. Like Nepal, Meghalaya, Bangladesh, Arunachal Pradesh, Nagaland, West Bengal etc. The Boro language has some special features in terms of using word-order pattern and it found in different types. The Boro language is found in SOV word-order pattern mainly and along with this pattern there are different types of word- orders in that language. The Tibeto-Burman languages are found in verb-final position. The Boro language is same in such feature. Keywords : Word-order, Boro, Language, SOV, OSV 1. Introduction Boro is the name of the community as well as the language. The Boro language belongs to Sino- Tibetan language family. This stock originated in the plain areas of Yang-Tsze-Kiang and Huang-ho rivers in China. Now, this language family is well spread throughout the eastern and south-eastern parts of Asia including Burma and North eastern parts of India including Assam (MR Baro, 2007:1). The Boro language originated from the Tibeto-Burman sub family of Sino-Tibetan language family. Its well spread throughout the Assam specially in the northern parts of Assam and its adjacent areas. -

(Hons.) in Persian Is Designed
Content: In order to foster quality higher education in India, the syllabus of B.A. (Hons.) LOCFin Persian - Page: 1 of 45 Introductionis designed with the aim of improving the quality of higher education. The syllabus of B.A. (Hons.) in Persian enables effective participation of young people in knowledge production and participation in the knowledge economy, improving national competitiveness in a globalized world and for equipping young people with skills relevant for global and national standards and enhancing the opportunities or social mobility. Persian is not merely a language but the life line of inter-disciplinary studies in the present global scenario as it is a fast growing subject being studied and offered as a major subject in the higher ranking educational institutions at world level. In view of it the proposed course is developed with the aims to equip the students with the linguistic, language and literary skills for meeting the growing demand of this discipline and promoting skill based education. The proposed course will facilitate self-discovery in the students and ensure their enthusiastic and effective participation in responding to the needs and challenges of society. The course is prepared with the objectives to enable students in developing skills and competencies needed for meeting the challenges being faced by our present society and requisite essential demand of harmony among human society as well and for his/her self- growth effectively. Therefore, this syllabus which can be opted by other Persian Departments of all Universities where teaching of Persian is being imparted is compatible and prepared keeping in mind the changing nature of the society, demand of the language skills to be carried with in the form of competencies by the students to understand and respond to the same efficiently and effectively. -

Languages and Peoples of the Eastern Himalayan Region (LPEHR)
Languages and Peoples of the Eastern Himalayan Region (LPEHR) Deictic motion in Hakhun Tangsa Krishna Boro Gauhati University ABSTRACT This paper provides a detailed description of how deictic motion events are encoded in a Tangsa variety called Hakhun, spoken in Arunachal Pradesh and Assam in India, and in Sagaing Region in Myanmar. Deictic motion events in Hakhun are encoded by a set of two motion verbs, their serial or versatile verb counterparts, and a set of two ventive particles. Impersonal deictic motion events are encoded by the motion verbs alone, which orient the motion with reference to a center of interest. Motion events with an SAP figure or ground are simultaneously encoded by the motion verbs and ventive particles. These motion events evoke two frames of reference: a home base and the speech-act location. The motion verbs anchor the motion with reference to the home base of the figure, and the ventives (or their absence) anchor the motion with reference to the location of the speaker, the addressee, or the speech-act. When the motion verbs are concatenated with other verbs, they specify motion associated with the action denoted by the other verb(s). KEYWORDS Hakhun, Tibeto-Burman, deictic motion, motion verbs, ventive This is a contribution from Himalayan Linguistics Vol 19(2) Languages and Peoples of the Eastern Himalayan Region: 9 29. ISSN 1544-7502 © 2020. All rights reserved. This Portable Document Format (PDF) file may not be altered in any way. Tables of contents, abstracts, and submission guidelines are available at escholarship.org/uc/himalayanlinguistics Himalayan Linguistics Vol 19(2) Languages and Peoples of the Eastern Himalayan Region © CC by-nc-nd-4.0 2020 ISSN 1544-7502 Deictic motion in Hakhun Tangsa1 Krishna Boro Gauhati University 1 Introduction This paper describes how deictic motion events are encoded and contextually anchored in the speech situation in Hakhun, a variety of Tangsa or Tangshang (Ethnologue ISO 639-3 nst) spoken in the states of Arunachal Pradesh and Assam, India, and in Sagaing Region, Myanmar. -

E-Newsletter
DELHI Bhasha Samman Presentation hasha Samman for 2012 were presidential address. Ampareen Lyngdoh, Bconferred upon Narayan Chandra Hon’ble Miniser, was the chief guest and Goswami and Hasu Yasnik for Classical Sylvanus Lamare, as the guest of honour. and Medieval Literature, Sondar Sing K Sreenivasarao in in his welcome Majaw for Khasi literature, Addanda C address stated that Sahitya Akademi is Cariappa and late Mandeera Jaya committed to literatures of officially Appanna for Kodava and Tabu Ram recognized languages has realized that Taid for Mising. the literary treasures outside these Akademi felt that while The Sahitya Akademi Bhasha languages are no less invaluable and no it was necessary to Samman Presentation Ceremony and less worthy of celebration. Hence Bhasha continue to encourage Awardees’ Meet were held on 13 May Samman award was instituted to honour writers and scholars in 2013 at the Soso Tham Auditorium, writers and scholars. Sahitya Akademi languages not formally Shillong wherein the Meghalaya Minister has already published quite a number recognised by the of Urban Affairs, Ampareen Lyngdoh of translations of classics from our Akademi, it therefore, was the chief guest. K Sreenivasarao, bhashas. instituted Bhasha Secretary, Sahitya Akademi delivered the He further said, besides the Samman in 1996 to welcome address. President of Sahitya conferment of sammans every year for be given to writers, Akademi, Vishwanath Prasad Tiwari scholars who have explored enduring scholars, editors, presented the Samman and delivered his significance of medieval literatures to lexicographers, collectors, performers or translators. This Samman include scholars who have done valuable contribution in the field of classical and medieval literature. -

The State and Identities in NE India
1 Working Paper no.79 EXPLAINING MANIPUR’S BREAKDOWN AND MANIPUR’S PEACE: THE STATE AND IDENTITIES IN NORTH EAST INDIA M. Sajjad Hassan Development Studies Institute, LSE February 2006 Copyright © M.Sajjad Hassan, 2006 Although every effort is made to ensure the accuracy and reliability of material published in this Working Paper, the Development Research Centre and LSE accept no responsibility for the veracity of claims or accuracy of information provided by contributors. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means without the prior permission in writing of the publisher nor be issued to the public or circulated in any form other than that in which it is published. Requests for permission to reproduce this Working Paper, of any part thereof, should be sent to: The Editor, Crisis States Programme, Development Research Centre, DESTIN, LSE, Houghton Street, London WC2A 2AE. 1 Crisis States Programme Explaining Manipur’s Breakdown and Mizoram’s Peace: the State and Identities in North East India M.Sajjad Hassan Development Studies Institute, LSE Abstract Material from North East India provides clues to explain both state breakdown as well as its avoidance. They point to the particular historical trajectory of interaction of state-making leaders and other social forces, and the divergent authority structure that took shape, as underpinning this difference. In Manipur, where social forces retained their authority, the state’s autonomy was compromised. This affected its capacity, including that to resolve group conflicts. Here powerful social forces politicized their narrow identities to capture state power, leading to competitive mobilisation and conflicts. -

CONFERENCE REPORT the 5TH INTERNATIONAL CONFERENCE of the NORTH EAST INDIAN LINGUISTICS SOCIETY 12-14 February 2010, Shillong, Meghalaya, India
Linguistics of the Tibeto-Burman Area Volume 33.1 — April 2010 CONFERENCE REPORT THE 5TH INTERNATIONAL CONFERENCE OF THE NORTH EAST INDIAN LINGUISTICS SOCIETY 12-14 February 2010, Shillong, Meghalaya, India Stephen Morey La Trobe University The 5th conference of the North East Indian Linguistics Society (NEILS) was held from 12th to 14th February 2010 at the Don Bosco Institute (DBI), Kharguli Hills, Guwahati, Assam. The conference was preceded by a two day workshop, hosted by Gauhati University,1 but also held at DBI. NEILS is grateful to the Research Centre for Linguistic Typology, La Trobe University, for providing funds to assist in the running of the workshops and conference. The two day workshop was in two parts: one day on using the Toolbox program, run by Virginia and David Phillips of SIL; and one day on working with tones, presented by Mark W. Post, Stephen Morey and Priyankoo Sarmah. Both workshops were well-attended and participatory in nature. The tones workshop included an intensive session of the Boro language, with five native speakers, all students of the Gauhati University Linguistics Department, providing information on their language and interacting with the participants. The conference itself began on 12th February with the launch of Morey and Post (2010) North East Indian Linguistics, Volume 2, performed by Nayan J. Kakoty, Resident Area Manager of Cambridge University Press India. This volume contains peer-reviewed and edited papers from the 2nd NEILS conference, held in 2007, representing NEILS’ commitment to the publication of the conference papers. A notable feature of the conference was the presence of seven people, from India, Burma, Australia and Germany, working on the Tangsa group of languages spoken on the India-Burma border. -
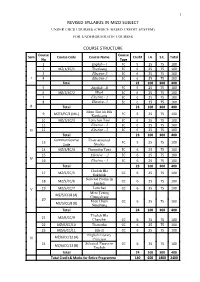
Mizo Subject Under Cbcs Courses (Choice Based Credit System) for Undergraduate Courses
1 REVISED SYLLABUS IN MIZO SUBJECT UNDER CBCS COURSES (CHOICE BASED CREDIT SYSTEM) FOR UNDERGRADUATE COURSES COURSE STRUCTURE Course Course Sem Course Code Course Name Credit I.A. S.E. Total No Type 1 English – I FC 5 25 75 100 2 MZ/1/EC/1 Thutluang EC 6 25 75 100 3 Elective-2 EC 6 25 75 100 I 4 Elective-3 EC 6 25 75 100 Total 23 100 300 400 5 English - II FC 5 25 75 100 6 MZ/2/EC/2 Hla-I EC 6 25 75 100 7 Elective - 2 EC 6 25 75 100 8 Elective- 3 EC 6 25 75 100 II Total 23 100 300 400 Mizo Thu leh Hla 9 MZ/3/FC/3 (MIL) FC 5 25 75 100 Kamkeuna 10 MZ/3/EC/3 Lemchan Tawi EC 6 25 75 100 11 Elective - 2 EC 6 25 75 100 III 12 Elective - 3 EC 6 25 75 100 Total 23 100 300 400 Common Course Environmental 13 FC 5 25 75 100 Code Studies 14 MZ/4/EC/4 Thawnthu Tawi EC 6 25 75 100 15 Elective - 2 EC 6 25 75 100 IV 16 Elective - 3 EC 6 25 75 100 Total 23 100 300 400 Thu leh Hla 17 MZ/5/CC/5 CC 6 25 75 100 Sukthlek Selected Poems in 18 MZ/5/CC/6 CC 6 25 75 100 English V 19 MZ/5/CC/7 Lemchan CC 6 25 75 100 Mizo |awng MZ/5/CC/8 (A) Chungchang 20 Mizo Hnam CC 6 25 75 100 MZ/5/CC/8 (B) Nunphung Total 24 100 300 400 Thu leh Hla 21 MZ/6/CC/9 Chanchin CC 6 25 75 100 22 MZ/6/CC/10 Thawnthu CC 6 25 75 100 23 MZ/6/CC/11 Hla-II CC 6 25 75 100 English Literary MZ/6/CC/12 (A) VI Criticism 24 Selected Essays in CC 6 25 75 100 MZ/6/CC/12 (B) English Total 24 100 300 400 Total Credit & Marks for Entire Programme 140 600 1800 2400 2 DETAILED COURSE CONTENTS SEMESTER-I Course : MZ/1/EC/1 - Thutluang ( Prose & Essays) Unit I : 1) Pu Hanga Leilet Veng - C. -

Persian Prose Credits: 4 = 3 +1+0 ( 48 Lectures)
P .G. 2 nd Semester Paper: PER 8 01C (Core) Classical Persian Prose Credits: 4 = 3 +1+0 ( 48 Lectures) (1) Nizami Aruzi Samarqandi:Chahar Maqala:Dar Mahiat e Ilm o Shayer o Salahiyat (2) Marzaban bin Rustom: Marzaban Nameh:Dastan e Barzighar o Mar, Dastan e Ghulam e Bajarghan,Dastan e Ahu, Mush o Aqab (3) Nasir Khusrau Safar Nameh: Chuni guyedAbu Main Hamid Uddin NasirKhusrau (4) Hamdullah Mustafi:Nazhatul Qulub: Baghdad, Isfahan, Shiraz and Nishapur Prescribed Books: . Md. Asif ; Adabiyat e Classic o Jadid Jald e awwal . Calcutta University: B.A.Persian Selection . Zabiullah Safa : Tarikh e Zaban o Adabiyat e Farsi . Wilber : Iran ; Past and Present Paper: PER 8 0 2 C (Core) Classical Persian Poetry Credits: 4 = 3+1+0 ( 4 8 Lectures) (1) Firdausi: Shahnameh: Amadan e Tahmina Dukht e Shah e Samangan, Gajidan e Sohrab Asp ra,Naburd e Rustam baSohrab (2) Sa’adi:Ai Sarban ,Yran bud ,Saru e simian ,An dost ke man daram (3) Hafiz: Agar an Turk e Shirazi, Dil me rawa,Rasid mizhda kea yam e gham (4) Maulana Rumi: Nala e Nai, Inkar kardan e Musa bar Muajat e Shupan Prescribed Book: . Md.Asif ; Adabiyat e Classic o Jadid Jald e awwal . Calcutta University: B.A.Persian Selection . Zabiullah Safa : Tarikh e Zaban o Adabiyat e Farsi . E.G.Browne : Literary History of Persia vol - II & III . John Ripka:History of Persian Literature . Arberry : Persian Classical Poetry *** Paper: PER 8 03 C History of Persian Literature Credits: 4 = 3+1+0 (48 Lectures) Paper: PER 8 04C Advance Language Development Skill Credits: 4 = 3 +1+0 ( 48 Lectures) 1. -

Outline of Harigaya Koch Grammar
Language and Culture DigitalResources Documentation and Description 46 Outline of Harigaya Koch Grammar Alexander Kondakov Outline of Harigaya Koch Grammar Alexander Kondakov SIL International® 2020 SIL Language and Culture Documentation and Description 46 ©2020 SIL International® ISSN 1939-0785 Fair Use Policy Documents published in the Language and Culture Documentation and Description series are intended for scholarly research and educational use. You may make copies of these publications for research or instructional purposes (under fair use guidelines) free of charge and without further permission. Republication or commercial use of Language and Culture Documentation and Description or the documents contained therein is expressly prohibited without the written consent of the copyright holder. Orphan Works Note Data and materials collected by researchers in an era before documentation of permission was standardized may be included in this publication. SIL makes diligent efforts to identify and acknowledge sources and to obtain appropriate permissions wherever possible, acting in good faith and on the best information available at the time of publication. Series Editor Lana Martens Content Editor Susan Hochstetler Compositor Bonnie Waswick Abstract Harigaya Koch is one of the several speech varieties of the Koch language (ISO 639-3: kdq). It belongs to the Koch subgrouping of the Bodo-Garo group of the Tibeto-Burman family and is spoken by a relatively small number of people in the western part of Meghalaya state in Northeast India (the total number of Koch in Meghalaya is about 25,000 people). Harigaya Koch is well understood by many Koch people of other groups and is used as a lingua franca at Koch social gatherings and in informal settings. -

Corpus Building of Literary Lesser Rich Language-Bodo: Insights And
Corpus Building of Literary Lesser Rich Language- Bodo: Insights and Challenges Biswajit Brahma1 Anup Kr. Barman1 Prof. Shikhar Kr. Sarma1 Bhatima Boro1 (1) DEPT. OF IT, GAUHATI UNIVERSITY, Guwahati - 781014, India [email protected], [email protected], [email protected], [email protected] ABSTRACT Collection of natural language texts in to a machine readable format for investigating various linguistic phenomenons is call a corpus. A well structured corpus can help to know how people used that language in day-to-day life and to build an intelligent system that can understand natural language texts. Here we review our experience with building a corpus containing 1.5 million words of Bodo language. Bodo is a Sino Tibetan family language mainly spoken in Northern parts of Assam, the North Eastern state of India. We try to improve the quality of Bodo corpora considering various characteristics like representativeness, machine readability, finite size etc. Since Bodo is one of the Indian language which is lesser reach on literary and computationally we face big problem on collecting data and our generated corpus will help the researchers in both field. KEYWORD : Bodo language, Corpus, Linguistics, Natural Language Processing. Proceedings of the 10th Workshop on Asian Language Resources, pages 29–34, COLING 2012, Mumbai, December 2012. 29 1 Introduction The term corpus is derived from Latin corpus "body” which it means as a representative collection of texts of a given language, dialect or other subset of a language to be used for linguistic analysis. Precisely, it refers to (a) (loosely) anybody of text; (b) (most commonly) a body of machine readable text; and (c) (more strictly) a finite collection of machine-readable texts sampled to be representative of a language or variety (Mc Enery and Wilson 1996: 218). -

A Critical Study of Tone in Bodo Language
International Journal of Scientific and Research Publications, Volume 5, Issue 4, April 2015 1 ISSN 2250-3153 A Critical Study of Tone in Bodo Language Biren sarma*, Dr. Jogen Boro** *Asstt. Prof., Department of Computer Science, Handique Girls’ College, Assam, India,Pin:781001 **Guest Faculty, Department of Bodo, Gauhati University, Assam, India, Pin: 781014 Abstract- The Indian languages which have tones are mostly Pramod Chandra Bhattacharya described maximum four (4) Tibeto-Burman languages which are spoken in North-Eastern numbers of tone in Bodo language in his Doctoral Thesis “A part of India, except two languages namely Gojri and Punjabi Descriptive Analysis of the Boro Language” (1977), i.e. neutral which belong to Indo-Aryan language family. Like many others /0/, high /1/, mid /2/ and low /3/. Tibeto-Burman Languages, Bodo is also tonal Language. Tone /0/ neutral is dependent on tone/1, 2, 3/, and the However dearth of proper research of its tonal phenomenon has quality of vowel is centralized and more lax. left many questions unanswered. There have been conflicting In high /1/ tone the level of pitch contour is level or rising views about the number of tones (rising from zero to four) tone and the quality of vowel is closer and tense. assignment system and morpho-phonemics of the languages. The In mid tone /2/ the level of pitch contour is level or falling only agreement among the researchers is that, the Bodo language and the quality of vowel is medium as to closeness and tenseness. is a tonal language. So, this analysis is a step to settle regarding In the low tone /3/ the level of pitch contour is falling and the tone or tonal phonology of the Bodo language with the help the quality of vowel is open and lax.