Corpus Building of Literary Lesser Rich Language-Bodo: Insights And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Bodo Movement: Past and Present
© 2019 JETIR June 2019, Volume 6, Issue 6 www.jetir.org (ISSN-2349-5162) THE BODO MOVEMENT: PAST AND PRESENT Berlao K. Karjie Research Scholar Dept. of Political Science Bodoland University INTRODUCTION The Boro or Bodo or Kachari is the earliest known inhabitant of Assam. The Bodos belong to racial origin of Mongoloid group. The Mongoloid population over time had formed a solid bloc spreading throughout the Brahmaputra and Barak valleys stretching to Cachar Hills of Assam, Meghalaya, and Tripura extending to some parts of West Bengal, Bihar, Nepal, Bhutan and Bangladesh with different identities. The Boro, Borok (Tripuri), Garo, Dimasa, Rabha, Chutiya, Tiwa, Sarania, Moholia, Kachari, Deuri, Borahi, Modahi, Sonowal, Thengal, Dhimal, Koch, Mech, Meche, Barman, Moran, Hajong, Rhamsa are historically, racially and linguistically of same ancestry. Since the historically untraced ages, the Bodo had exercised their highly developed political, legal and socio-cultural influences. Today the majority of Bodos are found concentrated in the foot hills of the Himalayan ranges in the north bank of the Brahmaputra valley. HISTORICAL BACKGROUND OF THE BODO NATION The Bodos had a glorious past history which is found mentioned in Hindu mythology like Vedic literature and epic like Mahabharata, Ramayana and Puranas with different derogatory names like Ausura, Mlecha and Kirata dynasty. The Bodos had once ruled the entire part of Himalayan ranges extending to Brahmaputra valley with different names and dynasties. For the first time in the recorded history the Ahoms attacked and invaded their country in the early part of the 13th century which continued almost 200 years. Despite of many external invasions the Bodos lived as a free nation with dignity and honour till the British invaded their dominions. -

Word-Order in Boro Language
Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930 Word-Order in Boro Language Dr. Kanun Basumatary Guest Lecturer, North Eastern Regional Language Centre Guwahati-29, Assam, India Abstract: The present study attempts to analysis and to discuss about the word-order of the Boro language. The Boro language is originated from the Tibeto-Burman group of Sino-Tibetan language family. The language is mainly spoken in Assam and its adjacent areas or countries of India. Like Nepal, Meghalaya, Bangladesh, Arunachal Pradesh, Nagaland, West Bengal etc. The Boro language has some special features in terms of using word-order pattern and it found in different types. The Boro language is found in SOV word-order pattern mainly and along with this pattern there are different types of word- orders in that language. The Tibeto-Burman languages are found in verb-final position. The Boro language is same in such feature. Keywords : Word-order, Boro, Language, SOV, OSV 1. Introduction Boro is the name of the community as well as the language. The Boro language belongs to Sino- Tibetan language family. This stock originated in the plain areas of Yang-Tsze-Kiang and Huang-ho rivers in China. Now, this language family is well spread throughout the eastern and south-eastern parts of Asia including Burma and North eastern parts of India including Assam (MR Baro, 2007:1). The Boro language originated from the Tibeto-Burman sub family of Sino-Tibetan language family. Its well spread throughout the Assam specially in the northern parts of Assam and its adjacent areas. -

6.Hum-RECEPTION and TRANSLATION of INDIAN
IMPACT: International Journal of Research in Humanities, Arts and Literature (IMPACT: IJRHAL) ISSN(E): 2321-8878; ISSN(P): 2347-4564 Vol. 3, Issue 12, Dec 2015, 53-58 © Impact Journals RECEPTION AND TRANSLATION OF INDIAN LITERATURE INTO BORO AND ITS IMPACT IN THE BORO SOCIETY PHUKAN CH. BASUMATARY Associate Professor, Department of Bodo, Bodoland University, Kokrajhar, Assam, India ABSTRACT Reception is an enthusiastic state of mind which results a positive context for diffusing cultural elements and features; even it happens knowingly or unknowingly due to mutual contact in multicultural context. It is worth to mention that the process of translation of literary works or literary genres done from one language to other has a wide range of impact in transmission of culture and its value. On the one hand it helps to bridge mutual intelligibility among the linguistic communities; and furthermore in building social harmony. Keeping in view towards the sociological importance and academic value translation is now-a-day becoming major discipline in the study of comparative literature as well as cultural and literary relations. From this perspective translation is not only a means of transference of text or knowledge from one language to other; but an effective tool for creating a situation of discourse among the cultural surroundings. In this brief discussion basically three major issues have been taken into account. These are (i) situation and reason of welcoming Indian literature and (ii) the process of translation of Indian literature into Boro and (iii) its impact in the society in adaption of translation works. KEYWORDS: Reception, Translation, Transmission of Culture, Discourse, Social Harmony, Impact INTRODUCTION The Boro language is now-a-day a scheduled language recognized by the Government of India in 2003. -

CONFERENCE REPORT the 5TH INTERNATIONAL CONFERENCE of the NORTH EAST INDIAN LINGUISTICS SOCIETY 12-14 February 2010, Shillong, Meghalaya, India
Linguistics of the Tibeto-Burman Area Volume 33.1 — April 2010 CONFERENCE REPORT THE 5TH INTERNATIONAL CONFERENCE OF THE NORTH EAST INDIAN LINGUISTICS SOCIETY 12-14 February 2010, Shillong, Meghalaya, India Stephen Morey La Trobe University The 5th conference of the North East Indian Linguistics Society (NEILS) was held from 12th to 14th February 2010 at the Don Bosco Institute (DBI), Kharguli Hills, Guwahati, Assam. The conference was preceded by a two day workshop, hosted by Gauhati University,1 but also held at DBI. NEILS is grateful to the Research Centre for Linguistic Typology, La Trobe University, for providing funds to assist in the running of the workshops and conference. The two day workshop was in two parts: one day on using the Toolbox program, run by Virginia and David Phillips of SIL; and one day on working with tones, presented by Mark W. Post, Stephen Morey and Priyankoo Sarmah. Both workshops were well-attended and participatory in nature. The tones workshop included an intensive session of the Boro language, with five native speakers, all students of the Gauhati University Linguistics Department, providing information on their language and interacting with the participants. The conference itself began on 12th February with the launch of Morey and Post (2010) North East Indian Linguistics, Volume 2, performed by Nayan J. Kakoty, Resident Area Manager of Cambridge University Press India. This volume contains peer-reviewed and edited papers from the 2nd NEILS conference, held in 2007, representing NEILS’ commitment to the publication of the conference papers. A notable feature of the conference was the presence of seven people, from India, Burma, Australia and Germany, working on the Tangsa group of languages spoken on the India-Burma border. -

Outline of Harigaya Koch Grammar
Language and Culture DigitalResources Documentation and Description 46 Outline of Harigaya Koch Grammar Alexander Kondakov Outline of Harigaya Koch Grammar Alexander Kondakov SIL International® 2020 SIL Language and Culture Documentation and Description 46 ©2020 SIL International® ISSN 1939-0785 Fair Use Policy Documents published in the Language and Culture Documentation and Description series are intended for scholarly research and educational use. You may make copies of these publications for research or instructional purposes (under fair use guidelines) free of charge and without further permission. Republication or commercial use of Language and Culture Documentation and Description or the documents contained therein is expressly prohibited without the written consent of the copyright holder. Orphan Works Note Data and materials collected by researchers in an era before documentation of permission was standardized may be included in this publication. SIL makes diligent efforts to identify and acknowledge sources and to obtain appropriate permissions wherever possible, acting in good faith and on the best information available at the time of publication. Series Editor Lana Martens Content Editor Susan Hochstetler Compositor Bonnie Waswick Abstract Harigaya Koch is one of the several speech varieties of the Koch language (ISO 639-3: kdq). It belongs to the Koch subgrouping of the Bodo-Garo group of the Tibeto-Burman family and is spoken by a relatively small number of people in the western part of Meghalaya state in Northeast India (the total number of Koch in Meghalaya is about 25,000 people). Harigaya Koch is well understood by many Koch people of other groups and is used as a lingua franca at Koch social gatherings and in informal settings. -

A Critical Study of Tone in Bodo Language
International Journal of Scientific and Research Publications, Volume 5, Issue 4, April 2015 1 ISSN 2250-3153 A Critical Study of Tone in Bodo Language Biren sarma*, Dr. Jogen Boro** *Asstt. Prof., Department of Computer Science, Handique Girls’ College, Assam, India,Pin:781001 **Guest Faculty, Department of Bodo, Gauhati University, Assam, India, Pin: 781014 Abstract- The Indian languages which have tones are mostly Pramod Chandra Bhattacharya described maximum four (4) Tibeto-Burman languages which are spoken in North-Eastern numbers of tone in Bodo language in his Doctoral Thesis “A part of India, except two languages namely Gojri and Punjabi Descriptive Analysis of the Boro Language” (1977), i.e. neutral which belong to Indo-Aryan language family. Like many others /0/, high /1/, mid /2/ and low /3/. Tibeto-Burman Languages, Bodo is also tonal Language. Tone /0/ neutral is dependent on tone/1, 2, 3/, and the However dearth of proper research of its tonal phenomenon has quality of vowel is centralized and more lax. left many questions unanswered. There have been conflicting In high /1/ tone the level of pitch contour is level or rising views about the number of tones (rising from zero to four) tone and the quality of vowel is closer and tense. assignment system and morpho-phonemics of the languages. The In mid tone /2/ the level of pitch contour is level or falling only agreement among the researchers is that, the Bodo language and the quality of vowel is medium as to closeness and tenseness. is a tonal language. So, this analysis is a step to settle regarding In the low tone /3/ the level of pitch contour is falling and the tone or tonal phonology of the Bodo language with the help the quality of vowel is open and lax. -
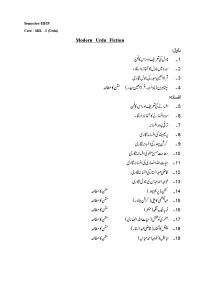
TDC Syllabus Under CBCS for Persian, Urdu, Bodo, Mizo, Nepali and Hmar
Proposed Scheme for Choice Based Credit System (CBCS) in B.A. (Honours) Persian 1 B.A. (Hons.): Persian is not merely a language but the life line of inter-disciplinary studies in the present global scenario as it is a fast growing subject being studied and offered as a major subject in the higher ranking educational institutions at world level. In view of it the proposed course is developed with the aims to equip the students with the linguistic, language and literary skills for meeting the growing demand of this discipline and promoting skill based education. The proposed course will facilitate self-discovery in the students and ensure their enthusiastic and effective participation in responding to the needs and challenges of society. The course is prepared with the objectives to enable students in developing skills and competencies needed for meeting the challenges being faced by our present society and requisite essential demand of harmony amongst human society as well and for his/her self-growth effectively. Therefore, this syllabus which can be opted by other Persian Departments of all Universities where teaching of Persian is being imparted is compatible and prepared keeping in mind the changing nature of the society, demand of the language skills to be carried with in the form of competencies by the students to understand and respond to the same efficiently and effectively. Teaching Method: The proposed course is aimed to inculcate and equip the students with three major components of Persian Language and Literature and Persianate culture which include the Indo-Persianate culture, the vital portion of our secular heritage. -

Tone Systems of Dimasa and Rabha: a Phonetic and Phonological Study
TONE SYSTEMS OF DIMASA AND RABHA: A PHONETIC AND PHONOLOGICAL STUDY By PRIYANKOO SARMAH A DISSERTATION PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY UNIVERSITY OF FLORIDA 2009 1 © 2009 Priyankoo Sarmah 2 To my parents and friends 3 ACKNOWLEDGMENTS The hardships and challenges encountered while writing this dissertation and while being in the PhD program are no way unlike anything experienced by other Ph.D. earners. However, what matters at the end of the day is the set of people who made things easier for me in the four years of my life as a Ph.D. student. My sincere gratitude goes to my advisor, Dr. Caroline Wiltshire, without whom I would not have even dreamt of going to another grad school to do a Ph.D. She has been a great mentor to me. Working with her for the dissertation and for several projects broadened my intellectual horizon and all the drawbacks in me and my research are purely due my own markedness constraint, *INTELLECTUAL. I am grateful to my co-chair, Dr. Ratree Wayland. Her knowledge and sharpness made me see phonetics with a new perspective. Not much unlike the immortal Sherlock Holmes I could often hear her echo: One's ideas must be as broad as Nature if they are to interpret Nature. I am indebted to my committee member Dr. Andrea Pham for the time she spent closely reading my dissertation draft and then meticulously commenting on it. Another committee member, Dr. -

Identity Politics and Social Exclusion in India's North-East
Identity Politics and Social Exclusion in India’s North-East: The Case for Re-distributive Justice N.K.Das• Abstract: This paper examines how various brands of identity politics since the colonial days have served to create the basis of exclusion of groups, resulting in various forms of rifts, often envisaged in binary terms: majority-minority; sons of the soil’-immigrants; local-outsiders; tribal-non-tribal; hills-plains; inter-tribal; and intra-tribal. Given the strategic and sensitive border areas, low level of development, immense cultural diversity, and participatory democratic processes, social exclusion has resulted in perceptions of marginalization, deprivation, and identity losses, all adding to the strong basis of brands of separatist movements in the garb of regionalism, sub-nationalism, and ethnic politics, most often verging on extremism and secession. It is argued that local people’s anxiety for preservation of culture and language, often appearing as ‘narcissist self-awareness’, and their demand of autonomy, cannot be seen unilaterally as dysfunctional for a healthy civil society. Their aspirations should be seen rather as prerequisites for distributive justice, which no nation state can neglect. Colonial Impact and genesis of early ethnic consciousness: Northeast India is a politically vital and strategically vulnerable region of India. Surrounded by five countries, it is connected with the rest of India through a narrow, thirty-kilometre corridor. North-East India, then called Assam, is divided into Arunachal Pradesh, Assam, Manipur, Meghalaya, Mizoram, Nagaland and Tripura. Diversities in terms of Mongoloid ethnic origins, linguistic variation and religious pluralism characterise the region. This ethnic-linguistic-ecological historical heritage characterizes the pervasiveness of the ethnic populations and Tibeto-Burman languages in northeast. -

Swarna Prabha Chainary Community As a Whole
ISSN No. : 2394-0344 REMARKING : VOL-1 * ISSUE-9*February-2015 Survival of Boro Language in the Face of Various Challenges (with Reference to Modern Period) Abstract This paper tries to give an idea on how the Boro peoples are struggling in different periods to keep them and their language alive. Starting from the medium of instruction in their language to the movement demanding Roman script to write their language as well as Bodo accord for formation of Bodoland Autonomous Council in 1993 and later on Bodoland Territorial Area District in 2003 they are not getting it without fighting and without sacrificing the valuable lives of the innocent peoples. Keywords: ABSU, bodo accord, BPAC, Dhubri Boro Literary Club, PTCA. Introduction Boro language is a language belonging to Assam and is recognized as a schedule language under Indian Constitution from the year 2003. The history of survival of this language and its speakers is a big challenge whether it is language, literature, culture, politics or economics. Therefore, when going to discuss on the topic Survival of Boro Language in the Face of Various Challenges, one cannot discuss only the language in isolation, the two other fields literature and politics will come up side by side. Considering this, discussion will cover the period from the formation of the Bodo Sahitya Sabha, the apex socio-literary organization of the Boros on16th November 1952 as it is considered by the Boro intellectuals and the litterateurs not only as the milestone of the beginning of modern Boro literature but also as the year of the revival of language and the Swarna Prabha Chainary community as a whole. -

3.Hum-LOANWORDS in BODO VOCABULARY a BRIEF STUDY
IMPACT: International Journal of Research in Humanities, Arts and Literature (IMPACT: IJRHAL) ISSN (P): 2347-4564; ISSN (E): 2321-8878 Vol. 4, Issue 3, Mar 2016, 15-28 © Impact Journals LOANWORDS IN BODO VOCABULARY: A BRIEF STUDY RAJE BRAHMA Research Scholar, Bodoland University, Assam, India ABSTRACT Bodo language belongs to Assam which falls under the Bodo group of Assam Burmese of the Tibeto-Burman languages of Sino-Tibetan language family. A loanword is a word borrowed from a donor language and incorporated into a recipient language. The study seeks to investigate and establish loanwords in Bodo Vocabulary from the different Indian and foreign group of languages. The study further investigates and establishes the adaptation strategies a loanword undergoes from Indian language family and foreign language family to the Bodo Vocabulary. It also looks at the adaptation strategies a loanword undergoes from different language family so as to be accommodated into Bodo language. The study uses the research methods of interview and questionnaires to collect data from the respondents who are native speakers of the BTAD area. The data is further collected from the secondary data which are related books, thesis and research journals which are given a list of words to give the word equivalents in their sister languages as well as Bodo language. For loanwords data is also collected from the native speakers of sister languages of Bodo like Dimasa, Kokborok etc. The major finding is that there are loanwords in Bodo Vocabulary from Indo-European, Dravidian, Austro-Asiatic language family and foreign language family. The loanwords have to undergo various adaptation strategies so as to be accommodated into the Bodo language of Assam. -

Boro) Dialect of North Bengal and Standard Boro Language Spoken in Assam
International Journal of Scientific and Research Publications, Volume 4, Issue 2, February 2014 1 ISSN 2250-3153 Variation in the lexicon of the Mech (Boro) dialect of North Bengal and standard Boro language spoken in Assam Rujab Muchahary Abstract- The Bodos are known by different names in different words used by the Boro speakers of two geographical areas i.e. places. In North Bengal they are known as Mech, in Nepal as North Bengal and Assam. Meche, in the Brahmaputra valley of Assam as Boro or Bodo. Racially they are the people of Mongoloid origin and linguistically to the Tibeto-Burman branch of Sino-Tibetan III. METHODOLOGY language family. Lexical variations can be observed among the During data collection, primary and secondary methods were Boro speakers of different geographical areas. As such there are used. For primary data sources, a visit was made to the areas of variations in the lexicon among the Boro speakers of North North Bengal concentrated by the Mech people. Then with the Bengal and Assam. In this paper, a study will be made on the application of interview and observation method, a collection of lexicon variation of the Mech dialect of North Bengal and words used by the Mech people was obtained. For secondary standard dialect of Boro spoken in Assam. source, different books written on Mech dialect and Boro standard was collected and referred. Index Terms- Mech, Boro, dialect, standard language, lexicon, variation 1 Bordoloi, B.N., forward in the book ‘Tribes of Assam’ 1991, p- 80 2 Kiryu, Kazuyuki: An Outline of the Meche Language-grammar, I.