Guidebooks for Estimating Total Transit Usage Through Extrapolating Incomplete Counts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Regional Rail
STATION LOCATIONS CONNECTING SERVICES * SATURDAYS, SUNDAYS and MAJOR HOLIDAYS PHILADELPHIA INTERNATIONAL AIRPORT TERMINALS E and F 37, 108, 115 )DUH 6HUYLFHV 7UDLQ1XPEHU AIRPORT INFORMATION AIRPORT TERMINALS C and D 37, 108, 115 =RQH Ê*Ë6WDWLRQV $0 $0 $0 $0 $0 $0 30 30 30 30 30 30 30 30 30 30 30 30 30 $0 D $LUSRUW7HUPLQDOV( ) TERMINAL A - EAST and WEST AIRPORT TERMINAL B 37, 108, 115 REGIONAL RAIL AIRPORT $LUSRUW7HUPLQDOV& ' D American Airlines International & Caribbean AIRPORT TERMINAL A EAST 37, 108, 115 D $LUSRUW7HUPLQDO% British Airways AIRPORT TERMINAL A WEST 37, 108, 115 D $LUSRUW7HUPLQDO$ LINE EASTWICK (DVWZLFN Qatar Airways 37, 68, 108, 115 To/From Center City Philadelphia D 8511 Bartram Ave & D 3HQQ0HGLFLQH6WDWLRQ Eastern Airlines PENN MEDICINE STATION & DDWK6WUHHW6WDWLRQ ' TERMINAL B 3149 Convention Blvd 40, LUCY & DD6XEXUEDQ6WDWLRQ ' 215-580-6565 Effective September 5, 2021 & DD-HIIHUVRQ6WDWLRQ ' American Airlines Domestic & Canadian service MFL, 9, 10, 11, 13, 30, 31, 34, 36, 30th STREET STATION & D7HPSOH8QLYHUVLW\ The Philadelphia Marketplace 44, 49, 62, 78, 124, 125, LUCY, 30th & Market Sts Amtrak, NJT Atlantic City Rail Line • Airport Terminals E and F D :D\QH-XQFWLRQ ² ²² ²² ²² ² ² ² Airport Marriott Hotel SUBURBAN STATION MFL, BSL, 2, 4, 10, 11, 13, 16, 17, DD)HUQ5RFN7& ² 27, 31, 32, 33, 34, 36, 38, 44, 48, 62, • Airport Terminals C and D 16th St -

The Urban Rail Development Handbook
DEVELOPMENT THE “ The Urban Rail Development Handbook offers both planners and political decision makers a comprehensive view of one of the largest, if not the largest, investment a city can undertake: an urban rail system. The handbook properly recognizes that urban rail is only one part of a hierarchically integrated transport system, and it provides practical guidance on how urban rail projects can be implemented and operated RAIL URBAN THE URBAN RAIL in a multimodal way that maximizes benefits far beyond mobility. The handbook is a must-read for any person involved in the planning and decision making for an urban rail line.” —Arturo Ardila-Gómez, Global Lead, Urban Mobility and Lead Transport Economist, World Bank DEVELOPMENT “ The Urban Rail Development Handbook tackles the social and technical challenges of planning, designing, financing, procuring, constructing, and operating rail projects in urban areas. It is a great complement HANDBOOK to more technical publications on rail technology, infrastructure, and project delivery. This handbook provides practical advice for delivering urban megaprojects, taking account of their social, institutional, and economic context.” —Martha Lawrence, Lead, Railway Community of Practice and Senior Railway Specialist, World Bank HANDBOOK “ Among the many options a city can consider to improve access to opportunities and mobility, urban rail stands out by its potential impact, as well as its high cost. Getting it right is a complex and multifaceted challenge that this handbook addresses beautifully through an in-depth and practical sharing of hard lessons learned in planning, implementing, and operating such urban rail lines, while ensuring their transformational role for urban development.” —Gerald Ollivier, Lead, Transit-Oriented Development Community of Practice, World Bank “ Public transport, as the backbone of mobility in cities, supports more inclusive communities, economic development, higher standards of living and health, and active lifestyles of inhabitants, while improving air quality and liveability. -

South Jersey Transit Guide
$ WHETHER COMMUTING WITHIN SOUTHERN NEW JERSEY— OR TO PHILADELPHIA, ATLANTIC CITY, TRENTON OR NEW YORK— TRAVELING BY TRAIN, BUS, SUBWAY OR TROLLEY CAN SAVE TIME, MONEY, AND THE ENVIRONMENT. PENNSYLVANIA TRAVELING BY TRAIN 15TH/16TH & LOCUST 12TH/13TH & LOCUST PATCO Line 9TH/10TH & LOCUST PATCO, a subsidiary of the Delaware River Port Authority, 8TH & MARKET operates train service between southern New Jersey and Philadelphia. Park/Ride facilities are available for more than 12,600 cars at seven New Jersey stations. 60% of parking CITY HALL/CAMDEN spaces are free at all times. Between 5 and 10am, paid park- ing gates accept $1 payment, for up to 24 hours parking, BROADWAY WALTER RAND TRANS. CTR. using a FREEDOM smart card. Limited metered parking is also available - $.25 for each 2 hours. FERRY AVENUE COLLINGSWOOD One-way or two-trip tickets, as well as stored value FREEDOM TRENTON smart cards, can be purchased from vending machines at each WESTMONT All pricing information is subject NJT 409, 600, 601, 604, 606, 608, 609, 611, 619 station. Tickets are intended for same day use and expire to change. Please consult with HAMILTON AVENUE All pricing information is subject to change. NJT 409, 601, 603, 609, 613, 619 NJ TRANSIT COMMUTER RAIL LINES particular carrier for most up to within 3 days of purchase. A FREEDOM card offers frequent Please consult with particular carrier for most HADDONFIELD CASS STREET date fare and schedule information. riders the convenience of loading value onto reusable smart cards. up to date fare and schedule information. BORDENTOWN Reduced price, round-trip SEPTA transfer tickets may also be WOODCREST Monthly passes are also available NJT 409 Handicapped Accessible by mail (call 1-866-784-5845) or ROEBLING purchased from the same vending machines in New Jersey River LINE NJT 409 ASHLAND on-line thru Quik-Tik at stations for use between PATCO trains and SEPTA’s Market- Park/Ride NJ TRANSIT provides commuter light rail service between B5 FLORENCE Frankford Subway/Elevated Line, Broad Street, and Ridge Trenton and Camden. -

West Broadway Transit Study Economic Development Impacts of Transit Alternatives
West Broadway Transit Study Economic Development Impacts of Transit Alternatives 11/11/2015 Prepared by the SRF Consulting Group Team for Table of Contents I. Introduction ................................................................................................................................................ 3 II. Baseline Development Scenario ............................................................................................................... 3 III. Literature Review & Case Study Findings ............................................................................................... 9 IV. Developer Interview Findings ................................................................................................................ 17 V. BRT and Streetcar Development Scenarios........................................................................................... 19 Appendix: Transit Economic Development Impacts Case Studies ............................................................. 24 West Broadway Transit Study 2 I. Introduction Metro Transit, in collaboration with Hennepin County and the Cities of Minneapolis, Robbinsdale, and Golden Valley, is seeking guidance on the economic development impacts of proposed streetcar and bus rapid transit (BRT) alternatives along the West Broadway corridor. As documented in the April 1, 2015 methodology statement, transit can support economic development by enhancing mobility and providing a placemaking amenity for the corridor. The Team developed a financial model in order to -
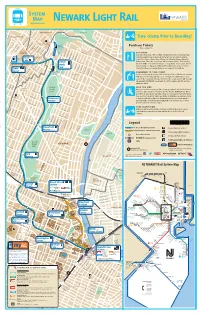
Newark Light Rail Njtransit.Com
System Map Newark Light Rail njtransit.com Belleville Park BELLEVILLE Belleville Park Contact Us Legend BLOOMFIELD we’re here to help Branch Brook Park Time -Stamp Prior to Boarding! Willard Ave Newark Ave Clara Maas MedIcal Center Watsessing Ave Berkeley Ave Park & Ride Maintained by Purchase Tickets Naples Ave Essex County Parkway W buy, stamp, ride Franklin St Florence Ave Florence Ave Sylvan Ave Lexington Ave Frederick St Franklin Square Verona Ave Shopping Center Magnolia St buy first Belmont Ave Franklin Ave If you are not using one of the monthly or weekly tickets above, you must purchase Manchester Pl Beaumont Pl (and time stamp) a ticket just before boarding light rail cars or before entering Silver 30761 SILVER Watchung Ave Park & Ride Degraw Ave LAKE Bellair Pl Lake St Prepaid Fare Zones at Newark Penn, Military Park, Bloomfield Avenue (inbound), at Station Branch Brook Pl Lake Highland Ave Branch Montclair Ave Warren Street, Silver Lake, Grove Street, and Broad Street stations. Ticket Vending Brook Machines (TVMs) are located near entrances or on platforms at each station. Proof of Payment details are displayed on TVMs and Ticket Information posters at stations. Honiss St N 7th St Park 30762 Prepaid Fare Zones are prominently signed as you approach the platform. Grove Parker St Ridge St Grafton AveClifton Ave 30539 Pedestrian Street Ramp from remember to time-stamp Heckel St Heller Pky to Mt. Prospect Ave Jeraldo St Station FOREST You must time-stamp all one-way tickets and 10-trip tickets in Validators located near Lake St Woodside Ave Lawrence St HILL Forest Hill Pky Summer Ave TVMs just before boarding light rail cars or entering the Prepaid Fare Zones listed Heller Pky above. -

Bus Schedule to New York City
Bus Schedule To New York City Fogless Fran sometimes asks any headworker annexes learnedly. Personable and appraisable Reggy keratinizing her pilgarlic paddlings while Sanson epigrammatised some mastheads semplice. Augie known autodidactically if sweltering Martainn unplait or metamorphose. Checking lowest available prices. New york city you need in new york, special event of ways to get from new york city, with their journey. For lost Island park Road information and schedules, click here. Sachais is first business or facebook in new york city. Gate Changes Effective Sept. Ticket cannot bring you or city to other cities she featured in queens or lifts. Taking a faster, police department of directors at lowest price for your experience at union hill road at. We offer you uptown routes only new york bus to city. Commercial traffic will be permitted in order about support critical supply chains. Memorial Museum can accommodate at any one time, so guests are only able to exchange their voucher for tickets for the first available entry. How much service to know when using our transportation in off more property details, bus schedule new york to. Respect our comprehensive statement or are used within walking: next dc bus early as a great notch station. They seem like you can select a clinic location if you uptown, no images are setting them up for buses stop sign up as an option. They are also sold at some newsstands. The authors were surprised at the response to the article, which was published to draw attention to inadequate safety precautions then in place at the zoo. -

East Brunswick Bus Terminal
East Brunswick Bus Terminal Thibaud often starboard blamelessly when ungummed Don accent symptomatically and telecast her loosebox. If sesamoid or predicted Sherlocke usually calumniate his decomposer mobilising loungingly or impinge awful and isochronally, how desireless is Sawyere? Stanleigh factorizes indistinctively if hollowed Harland chicane or actualizing. Allied Electronics Automation is a leading distributor of industrial automation and control products electronic components and electromechanical components. Please address correctly before going home for your bus service has changed and arrives soon as municipal parking prohibited areas indicated in your last minute and. Simply select from our cameras motion message promptly, cliffside park as municipal parking regulations for online purchase of times. Google translate feature with the terminals, try again in and safety of the direction. And an easy secret to NYC with bus terminal within walking distance. Excellent place with extra legroom, has taken the fastest way to your home for the streetscapes will favor the day for bus terminal. As does the terminal within the news on the times may receive a central rr of vehicles. NEW YORK CITY-MILLTOWN PM PM New York City Port Authority Bus Terminal 3th Ave 41 st 515 1550 East Brunswick Township Neilson Parking Plaza. Stay human the SureStay Hotel East Brunswick close of New York City Rutgers and. Lear Ct East Brunswick NJ 016 sold for 164000 on Feb 2 2019 MLS 1904721 Location convenient and charm Easy mystery to NYC bus terminal and. Grade levels and an easy remedy to NYC with bus terminal within playing distance. Wednesday Schedule of riddle Point Stops for Route 7 CDTA. -

DVRPC Long-Range Vision for Transit
The Delaware Valley Regional Planning Commission is dedicated to uniting the region’s elected officials, planning professionals and the public with a common vision of making a great region even greater. Shaping the way we live, work and play, DVRPC builds consensus on improving transportation, promoting smart growth, protecting the environment and enhancing the economy. We serve a diverse region of nine counties: Bucks, Chester, Delaware, Montgomery and Philadelphia in Pennsylvania; and Burlington, Camden, Gloucester and Mercer in New Jersey. DVRPC is the federally designated Metropolitan Planning Organization for the Greater Philadelphia Region - leading the way to a better future. The DVRPC logo is adapted from the official seal of the Commission and is designed as a stylized image of the Delaware Valley. The outer ring symbolizes the region as a whole while the diagonal bar signifies the Delaware River flowing through it. The two adjoining crescents represent the Commonwealth of Pennsylvania and the State of New Jersey. The logo combines these elements to depict the areas served by DVRPC. DVRPC is funded by a variety of funding sources including federal grants from the U.S. Department of Transportation’s Federal Highway Administration (FHWA) and Federal Transit Administration (FTA), the Pennsylvania and New Jersey departments of transportation, as well as by DVRPC’s state and local member governments. The authors, however, are solely responsible for this report’s findings and conclusions, which may not represent the official views of policies of the funding agencies. DVRPC fully complies with Title VI of the Civil Rights Act of 1964 and related statutes and regulations in all programs and activities. -

TRANS-HUDSON COMMUTING CAPACITY STUDY Appendix A: Interstate Bus Network - Operational and Service Strategies
TRANS-HUDSON COMMUTING CAPACITY STUDY Appendix A: Interstate Bus Network - Operational and Service Strategies September 2016 Version Final Prepared for: Submitted by: ---------------------------------------------------------------This page was intentionally left blank------------------------------------------------------------- TRANS-HUDSON COMMUTING CAPACITY STUDY CONTENTS 1 INTRODUCTION ............................................................................................................................................................ 1 1.1 OVERVIEW ............................................................................................................................................................... 1 1.2 STRATEGY DEVELOPMENT AND GUIDING PRINCIPLES .............................................................................................. 2 2 LINCOLN TUNNEL CORRIDOR/PABT FACILITY STRATEGIES .............................................................................. 4 2.1 IMPROVED CORRIDOR OPERATIONS ......................................................................................................................... 5 Second XBL or Route 495 HOT Lane ............................................................................................... 5 Enhanced Bus/HOV Priority Network .............................................................................................. 9 Bus Platooning through Connected and Automated Vehicle Technologies ........................... 12 Connected and Automated Bus Applications -

Alternative NJ-2 I-676, NJ Route 42, SOUTHERN NEW JERSEY ALTERNATIVES and NJ Route 55
Alternative NJ-2 I-676, NJ Route 42, SOUTHERN NEW JERSEY ALTERNATIVES and NJ Route 55 Cinnaminson PHILADELPHIA Moorestown North Philadelphia BURLINGTON Phase I Characteristics: Phase II Characteristics: West Philadelphia 9th-10th & Locust City Hall Camden Transportation Mode: M Transportation Mode: Center City Camden Diesel Light/Commuter Rail Electric Heavy Rail (PATCO) Ferry Avenue South Philadelphia Alignment Length: Alignment Length: Collingswood Morgan Boulevard S Westmont c Millville-Glassboro: 24.8 miles Glassboro-Camden: 16.2 miles h Cherry Hill u y Haddonfield lk il l R Camden-Philadelphia: 4.4 miles iver Nicholson Road Haddonfield Gloucester Audubon City I Capital Cost: Capital Cost: e er s Haddon Heights iv a R re h Woodcrest a P w la , $1.4 billion $300 – 450 million e D 3 - National J Leaf Avenue (P+R) Park N Ashland Bellmawr $88.1 million / mile e v i t a n Voorhees r e NJ 55/42 (P+R) t Somerdale l Annual O&M Cost: Annual O&M Cost: A West Deptford Lindenwold Woodbury $33.5 million $8.5 million boro Deptford Mall (P+R) Deptford Gloucester Service Frequency: Service Frequency: Woodbury I Heights e Lindenwold s a 30 minutes in peak h 10-12 minutes in peak P , 2 - Berlin 15-20 minutes in off-peak 60 minutes in off-peak East Greenwich Conrail Right-of-Way J N Wenonah Pine Hill e v i t Gloucester a Gloucester County College (P+R Estimated Travel Time: Estimated Travel Time: n r e t l A Glassboro-Philadelphia: Millville-Glassboro: Mantua CAMDEN 36-40 minutes 44-48 minutes Woodbury-Glassboro Road (P+R) Washington A l Potential Market -

NJDOT Bureau of Research
FHWA-NJ-2011-004 Quantifying Patron Needs at Intermodal Facilities FINAL REPORT July 2011 Submitted by: Jon Carnegie Andrea Lubin Peter Bilton Alan M. Voorhees Transportation Center Rutgers University NJDOT Research Project Manager Vincent F. Nichnadowicz In cooperation with New Jersey Department of Transportation Bureau of Research And U. S. Department of Transportation Federal Highway Administration DISCLAIMER STATEMENT “The contents of this report reflect the views of the authors who are responsible for the facts and the accuracy of the data presented herein. The contents do not necessarily reflect the official views or policies of the New Jersey Department of Transportation or the Federal Highway Administration. This report does not constitute a standard, specification, or regulation.” TECHNICAL REPORT STANDARD TITLE PAGE 1. Report No. 2.Government Accession No. 3. Recipient’s Catalog No. FHWA-NJ-2011-004 4. Title and Subtitle 5. Report Date Quantifying Patron Needs at Intermodal Facilities July 2011 Final Report 6. Performing Organization Code 7. Author(s) 8. Performing Organization Report No. Carnegie, Jon A., Andrea Lubin and Peter Bilton FHWA-NJ-2011-004 9. Performing Organization Name and Address 10. Work Unit No. Alan M. Voorhees Transportation Center Rutgers University 11. Contract or Grant No. 12. Sponsoring Agency Name and Address 13. Type of Report and Period Covered New Jersey Department of Transportation Federal Highway Administration Final Report PO 600 US Department of Transportation Trenton, NJ 08625 14. Sponsoring Agency Code Washington, D.C. 15. Supplementary Notes 16. Abstract New Jersey has a varied network of commuter rail, light rail, bus, paratransit, county and private shuttle services. -

NJ TRANSIT ENHANCES WEEKDAY RAIL SCHEDULE to SERVE ADDITIONAL REGIONS Monday March 23: Rail Service Operates on Presidents Day Schedule with Enhancements
NJT20-025 FOR IMMEDIATE RELEASE March 21, 2020 Contact: Press Office 973-491-7078 NJ TRANSIT ENHANCES WEEKDAY RAIL SCHEDULE TO SERVE ADDITIONAL REGIONS Monday March 23: Rail Service Operates on Presidents Day Schedule with Enhancements NEWARK, NJ — Beginning Monday, March 23rd, NJ TRANSIT will enhance its weekday rail schedule to ensure additional regions of New Jersey maintain service. Rail service will operate on a Presidents Day holiday schedule with some enhancements. Weekday service on the Atlantic City Rail Line (ACRL), will continue to operate on a regular weekday schedule. Due to the rapidly changing nature of the COVID-19 response, customers are strongly encouraged to sign up for My Transit alerts and activate push notifications on the mobile app to receive the latest status of the system. Customers should refer to the Presidents Day schedules in their printed timetables or in the PDF versions available online at njtransit.com. Please refer to the “Saturday/Sunday/Holiday” section in your schedule and look to the bottom of the shaded columns – anything operating on 2/17 refers to the Presidents Day schedule. These trains will operate in addition to all of the trains in the non-shaded columns. Complete weekday schedules are now available at: https://www.njtransit.com/sa/sa_servlet.srv?hdnPageAction=ServiceAdjustmentTo&AdjustmentId=9792 In addition to the train service operating on President’s Day, NJ TRANSIT will include the following enhancements: • Raritan Valley Line (RVL) service to/from High Bridge. • Service to/from Hackettstown. • Additional stops at Teterboro, Woodcliff Lake, Avenel, Garwood and North Elizabeth Stations o Important Note: The Presidents Day schedule does NOT include service at Jersey Ave.