KERNEL-FREE VIDEO DEBLURRING VIA SYNTHESIS Feitong Tan
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kūnqǔ in Practice: a Case Study
KŪNQǓ IN PRACTICE: A CASE STUDY A DISSERTATION SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI‘I AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN THEATRE OCTOBER 2019 By Ju-Hua Wei Dissertation Committee: Elizabeth A. Wichmann-Walczak, Chairperson Lurana Donnels O’Malley Kirstin A. Pauka Cathryn H. Clayton Shana J. Brown Keywords: kunqu, kunju, opera, performance, text, music, creation, practice, Wei Liangfu © 2019, Ju-Hua Wei ii ACKNOWLEDGEMENTS I wish to express my gratitude to the individuals who helped me in completion of my dissertation and on my journey of exploring the world of theatre and music: Shén Fúqìng 沈福庆 (1933-2013), for being a thoughtful teacher and a father figure. He taught me the spirit of jīngjù and demonstrated the ultimate fine art of jīngjù music and singing. He was an inspiration to all of us who learned from him. And to his spouse, Zhāng Qìnglán 张庆兰, for her motherly love during my jīngjù research in Nánjīng 南京. Sūn Jiàn’ān 孙建安, for being a great mentor to me, bringing me along on all occasions, introducing me to the production team which initiated the project for my dissertation, attending the kūnqǔ performances in which he was involved, meeting his kūnqǔ expert friends, listening to his music lessons, and more; anything which he thought might benefit my understanding of all aspects of kūnqǔ. I am grateful for all his support and his profound knowledge of kūnqǔ music composition. Wichmann-Walczak, Elizabeth, for her years of endeavor producing jīngjù productions in the US. -

Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation
Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation A/L Krishnan Thiinash Bachelor of Information Technology March 2015 A/L Selvaraju Theeban Raju Bachelor of Commerce January 2015 A/P Balan Durgarani Bachelor of Commerce with Distinction March 2015 A/P Rajaram Koushalya Priya Bachelor of Commerce March 2015 Hiba Mohsin Mohammed Master of Health Leadership and Aal-Yaseen Hussein Management July 2015 Aamer Muhammad Master of Quality Management September 2015 Abbas Hanaa Safy Seyam Master of Business Administration with Distinction March 2015 Abbasi Muhammad Hamza Master of International Business March 2015 Abdallah AlMustafa Hussein Saad Elsayed Bachelor of Commerce March 2015 Abdallah Asma Samir Lutfi Master of Strategic Marketing September 2015 Abdallah Moh'd Jawdat Abdel Rahman Master of International Business July 2015 AbdelAaty Mosa Amany Abdelkader Saad Master of Media and Communications with Distinction March 2015 Abdel-Karim Mervat Graduate Diploma in TESOL July 2015 Abdelmalik Mark Maher Abdelmesseh Bachelor of Commerce March 2015 Master of Strategic Human Resource Abdelrahman Abdo Mohammed Talat Abdelziz Management September 2015 Graduate Certificate in Health and Abdel-Sayed Mario Physical Education July 2015 Sherif Ahmed Fathy AbdRabou Abdelmohsen Master of Strategic Marketing September 2015 Abdul Hakeem Siti Fatimah Binte Bachelor of Science January 2015 Abdul Haq Shaddad Yousef Ibrahim Master of Strategic Marketing March 2015 Abdul Rahman Al Jabier Bachelor of Engineering Honours Class II, Division 1 -

The Case of Wang Wei (Ca
_full_journalsubtitle: International Journal of Chinese Studies/Revue Internationale de Sinologie _full_abbrevjournaltitle: TPAO _full_ppubnumber: ISSN 0082-5433 (print version) _full_epubnumber: ISSN 1568-5322 (online version) _full_issue: 5-6_full_issuetitle: 0 _full_alt_author_running_head (neem stramien J2 voor dit article en vul alleen 0 in hierna): Sufeng Xu _full_alt_articletitle_deel (kopregel rechts, hier invullen): The Courtesan as Famous Scholar _full_is_advance_article: 0 _full_article_language: en indien anders: engelse articletitle: 0 _full_alt_articletitle_toc: 0 T’OUNG PAO The Courtesan as Famous Scholar T’oung Pao 105 (2019) 587-630 www.brill.com/tpao 587 The Courtesan as Famous Scholar: The Case of Wang Wei (ca. 1598-ca. 1647) Sufeng Xu University of Ottawa Recent scholarship has paid special attention to late Ming courtesans as a social and cultural phenomenon. Scholars have rediscovered the many roles that courtesans played and recognized their significance in the creation of a unique cultural atmosphere in the late Ming literati world.1 However, there has been a tendency to situate the flourishing of late Ming courtesan culture within the mainstream Confucian tradition, assuming that “the late Ming courtesan” continued to be “integral to the operation of the civil-service examination, the process that re- produced the empire’s political and cultural elites,” as was the case in earlier dynasties, such as the Tang.2 This assumption has suggested a division between the world of the Chinese courtesan whose primary clientele continued to be constituted by scholar-officials until the eight- eenth century and that of her Japanese counterpart whose rise in the mid- seventeenth century was due to the decline of elitist samurai- 1) For important studies on late Ming high courtesan culture, see Kang-i Sun Chang, The Late Ming Poet Ch’en Tzu-lung: Crises of Love and Loyalism (New Haven: Yale Univ. -

Huaqiang ZENG Team Leader and Principal Research Scientist
Huaqiang ZENG Team Leader and Principal Research Scientist +65 6824 7115 [email protected] Team Leader and Principal Research Scientist, NanoBio Lab, Singapore, 2019-present Team Leader and Principal Research Scientist, Institute of Bioengineering and Nanotechnology, Singapore, 2014-2019 Assistant Professor, National University of Singapore, 2006-2013 Postdoctoral Research Fellow, The Scripps Research Institute, USA, 2002-2006 Ph.D. in Organic Chemistry, The State University of New York at Buffalo, USA, 2002 B.S. in Chemical Physics, The University of Science and Technology of China, 1996 Publications 1. A. Roy, H. Joshi, R. Ye, J. Shen, F. Chen, A. Aksimentiev and H. Zeng, “Polyhydrazide‐Based Organic Nanotubes as Efficient and Selective Artificial Iodide Channels,” Angewandte Chemie International Edition, 132 (2020) 4836-4843. IF 12.102 2. J. Shen, J. Fan, R. Ye, N. Li, Y. Mu and H. Zeng, “Polypyridine-Based Helical Amide Foldamer Channels for Rapid Transport of Water and Proton with High Ion Rejection,” Angewandte Chemie International Edition, (2020) DOI: 10.1002/anie.202003512. IF 12.257 3. J. Shen, R. Ye, A. Romanies, A. Roy, F. Chen, C. Ren, Z. Liu and H. Zeng, “An Aquafoldmer-Based Aquaporin-Like Synthetic Water Channel,” Journal of the American Chemical Society, 142 (2020) 10050-10058. IF 14.695 4. H. Zeng, A. Roy, H. Joshi, R. Ye, J. Shen, F. Chen and A. Aksimentiev, “Polyhydrazide-Based Organic Nanotubes as Extremely Efficient and Highly Selective Artificial Iodide Channels,” Angew. Chem. Int. Ed., (2020) DOI: 10.1002/anie.201916287 5. H. Zeng, F. Chen, J. Shen, N. Li, A. -

Origin Narratives: Reading and Reverence in Late-Ming China
Origin Narratives: Reading and Reverence in Late-Ming China Noga Ganany Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2018 © 2018 Noga Ganany All rights reserved ABSTRACT Origin Narratives: Reading and Reverence in Late Ming China Noga Ganany In this dissertation, I examine a genre of commercially-published, illustrated hagiographical books. Recounting the life stories of some of China’s most beloved cultural icons, from Confucius to Guanyin, I term these hagiographical books “origin narratives” (chushen zhuan 出身傳). Weaving a plethora of legends and ritual traditions into the new “vernacular” xiaoshuo format, origin narratives offered comprehensive portrayals of gods, sages, and immortals in narrative form, and were marketed to a general, lay readership. Their narratives were often accompanied by additional materials (or “paratexts”), such as worship manuals, advertisements for temples, and messages from the gods themselves, that reveal the intimate connection of these books to contemporaneous cultic reverence of their protagonists. The content and composition of origin narratives reflect the extensive range of possibilities of late-Ming xiaoshuo narrative writing, challenging our understanding of reading. I argue that origin narratives functioned as entertaining and informative encyclopedic sourcebooks that consolidated all knowledge about their protagonists, from their hagiographies to their ritual traditions. Origin narratives also alert us to the hagiographical substrate in late-imperial literature and religious practice, wherein widely-revered figures played multiple roles in the culture. The reverence of these cultural icons was constructed through the relationship between what I call the Three Ps: their personas (and life stories), the practices surrounding their lore, and the places associated with them (or “sacred geographies”). -
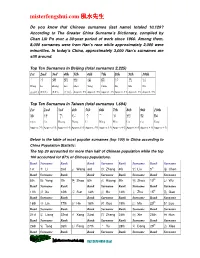
Misterfengshui.Com 風水先生
misterfengshui.com 風水先生 Do you know that Chinese surnames (last name) totaled 10,129? According to The Greater China Surname’s Dictionary, compiled by Chan Lik Pu over a 30-year period of work since 1960. Among them, 8,000 surnames were from Han’s race while approximately 2,000 were minorities. In today’s China, approximately 3,000 Han’s surnames are still around. Top Ten Surnames In Beijing (total surnames 2,225) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 王 李 張 劉 趙 楊 陳 徐 馬 吳 Wang Li Zhang Liu Zhao Yang Chen Xu Ma Wu (10.6% ) (9.6%) (9.6%) (7.7% ) Approx. 5% Approx. 5% Approx. 4% Approx. 4% Approx. 4% Approx. 3% Top Ten Surnames In Taiwan (total surnames 1,694) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 陳 林 黃 張 李 王 吳 劉 蔡 楊 Chen Lin Huang Zhang Li Wang Wux. Liu Cai Yang Approx .7% Approx 6 % Approx 6 % Approx 6 % Approx. 5% Approx 5 % Approx 4 % Approx 4 % Approx 4 % Approx 4 % Below is the table of most popular surnames (top 100) in China according to China Population Statistic: The top 20 accounted for more than half of Chinese population while the top 100 accounted for 87% of Chinese populations. Rank Surname Rank Rank Surname Rank Surname Rank Surname 1st 李 Li 2nd 王 Wang 3rd 張 Zhang 4th 劉 Liu 5th 陳 Chen Rank Surname Rank Rank Surname Rank Surname Rank Surname 6th 楊 Yang 7th 趙 Zhao 8th 黃 Huang 9th 周 Zhou 10 th 吳 Wu Rank Surname Rank Rank Surname Rank Surname Rank Surname 11th 徐 Xu 12th 孫 Sun 13th 胡 Hu 14th 朱 Zhu 15 th 高 Gao Rank Surname Rank Rank Surname Rank Surname Rank Surname 16th 林 Lin 17th 何 He 18th 郭 Guo 19th 馬 Ma 20 th 羅 Luo Rank -

Representing Talented Women in Eighteenth-Century Chinese Painting: Thirteen Female Disciples Seeking Instruction at the Lake Pavilion
REPRESENTING TALENTED WOMEN IN EIGHTEENTH-CENTURY CHINESE PAINTING: THIRTEEN FEMALE DISCIPLES SEEKING INSTRUCTION AT THE LAKE PAVILION By Copyright 2016 Janet C. Chen Submitted to the graduate degree program in Art History and the Graduate Faculty of the University of Kansas in partial fulfillment of the requirements for the degree of Doctor of Philosophy. ________________________________ Chairperson Marsha Haufler ________________________________ Amy McNair ________________________________ Sherry Fowler ________________________________ Jungsil Jenny Lee ________________________________ Keith McMahon Date Defended: May 13, 2016 The Dissertation Committee for Janet C. Chen certifies that this is the approved version of the following dissertation: REPRESENTING TALENTED WOMEN IN EIGHTEENTH-CENTURY CHINESE PAINTING: THIRTEEN FEMALE DISCIPLES SEEKING INSTRUCTION AT THE LAKE PAVILION ________________________________ Chairperson Marsha Haufler Date approved: May 13, 2016 ii Abstract As the first comprehensive art-historical study of the Qing poet Yuan Mei (1716–97) and the female intellectuals in his circle, this dissertation examines the depictions of these women in an eighteenth-century handscroll, Thirteen Female Disciples Seeking Instructions at the Lake Pavilion, related paintings, and the accompanying inscriptions. Created when an increasing number of women turned to the scholarly arts, in particular painting and poetry, these paintings documented the more receptive attitude of literati toward talented women and their support in the social and artistic lives of female intellectuals. These pictures show the women cultivating themselves through literati activities and poetic meditation in nature or gardens, common tropes in portraits of male scholars. The predominantly male patrons, painters, and colophon authors all took part in the formation of the women’s public identities as poets and artists; the first two determined the visual representations, and the third, through writings, confirmed and elaborated on the designated identities. -

Names of Chinese People in Singapore
101 Lodz Papers in Pragmatics 7.1 (2011): 101-133 DOI: 10.2478/v10016-011-0005-6 Lee Cher Leng Department of Chinese Studies, National University of Singapore ETHNOGRAPHY OF SINGAPORE CHINESE NAMES: RACE, RELIGION, AND REPRESENTATION Abstract Singapore Chinese is part of the Chinese Diaspora.This research shows how Singapore Chinese names reflect the Chinese naming tradition of surnames and generation names, as well as Straits Chinese influence. The names also reflect the beliefs and religion of Singapore Chinese. More significantly, a change of identity and representation is reflected in the names of earlier settlers and Singapore Chinese today. This paper aims to show the general naming traditions of Chinese in Singapore as well as a change in ideology and trends due to globalization. Keywords Singapore, Chinese, names, identity, beliefs, globalization. 1. Introduction When parents choose a name for a child, the name necessarily reflects their thoughts and aspirations with regards to the child. These thoughts and aspirations are shaped by the historical, social, cultural or spiritual setting of the time and place they are living in whether or not they are aware of them. Thus, the study of names is an important window through which one could view how these parents prefer their children to be perceived by society at large, according to the identities, roles, values, hierarchies or expectations constructed within a social space. Goodenough explains this culturally driven context of names and naming practices: Department of Chinese Studies, National University of Singapore The Shaw Foundation Building, Block AS7, Level 5 5 Arts Link, Singapore 117570 e-mail: [email protected] 102 Lee Cher Leng Ethnography of Singapore Chinese Names: Race, Religion, and Representation Different naming and address customs necessarily select different things about the self for communication and consequent emphasis. -

“The Hereditary House of King Goujian of Yue”
"Yuewang Goujian Shijia": An Annotated Translation Item Type text; Electronic Thesis Authors Daniels, Benjamin Publisher The University of Arizona. Rights Copyright © is held by the author. Digital access to this material is made possible by the University Libraries, University of Arizona. Further transmission, reproduction or presentation (such as public display or performance) of protected items is prohibited except with permission of the author. Download date 26/09/2021 20:21:08 Link to Item http://hdl.handle.net/10150/293623 “YUEWANG GOUJIAN SHIJIA”: AN ANNOTATED TRANSLATION by Benjamin Daniels ____________________________ Copyright © Benjamin Daniels 2013 A Thesis Submitted to the Faculty of the DEPARTMENT OF EAST ASIAN STUDIES In Partial Fulfillment of the Requirements For the Degree of MASTER OF ARTS In the Graduate College THE UNIVERSITY OF ARIZONA 2013 2 STATEMENT BY AUTHOR This thesis has been submitted in partial fulfillment of requirements for an advanced degree at the University of Arizona and is deposited in the University Library to be made available to borrowers under rules of the Library. Brief quotations from this thesis are allowable without special permission, provided that an accurate acknowledgement of the source is made. Requests for permission for extended quotation from or reproduction of this manuscript in whole or in part may be granted by the copyright holder. SIGNED: Benjamin Daniels APPROVAL BY THESIS DIRECTOR This thesis has been approved on the date shown below: Dr. Brigitta Lee May 8, 2013 3 ACKNOWLEDGEMENTS First, I need to express my deepest gratitude to Dr. Enno Giele, who was my first mentor in anything related to ancient China. -

Zhenzhong Zeng School of Environmental Science And
Zhenzhong Zeng School of Environmental Science and Engineering, Southern University of Science and Technology [email protected] | https://scholar.google.com/citations?user=GsM4YKQAAAAJ&hl=en CURRENT POSITION Associate Professor, Southern University of Science and Technology, since 2019.09.04 PROFESSIONAL EXPERIENCE Postdoctoral Research Associate, Princeton University, 2016-2019 (Mentor: Dr. Eric F. Wood) EDUCATION Ph.D. in Physical Geography, Peking University, 2011-2016 (Supervisor: Dr. Shilong Piao) B.S. in Geography Science, Sun Yat-Sen University, 2007-2011 RESEARCH INTERESTS Global change and the earth system Biosphere-atmosphere interactions Terrestrial hydrology Water and agriculture resources Climate change and its impacts, with a focus on China and the tropics AWARDS & HONORS 2019 Shenzhen High Level Professionals – National Leading Talents 2018 “China Agricultural Science Major Progress” - Impacts of climate warming on global crop yields and feedbacks of vegetation growth change on global climate, Chinese Academy of Agricultural Sciences 2016 Outstanding Graduate of Peking University 2013 – 2016 Presidential (Peking University) Scholarship; 2014 – 2015 Peking University PhD Projects Award; 2013 – 2014 Peking University "Innovation Award"; 2013 – 2014 National Scholarship; 2012 – 2013 Guanghua Scholarship; 2011 – 2012 National Scholarship; 2011 – 2012 Founder Scholarship 2011 Outstanding Graduate of Sun Yat-Sen University 2009 National Undergraduate Mathematical Contest in Modeling (Provincial Award); 2009 – 2010 National Scholarship; 2008 – 2009 National Scholarship; 2007 – 2008 Guanghua Scholarship PUBLICATION LIST 1. Liu, X., Huang, Y., Xu, X., Li, X., Li, X.*, Ciais, P., Lin, P., Gong, K., Ziegler, A. D., Chen, A., Gong, P., Chen, J., Hu, G., Chen, Y., Wang, S., Wu, Q., Huang, K., Estes, L. & Zeng, Z.* High spatiotemporal resolution mapping of global urban change from 1985 to 2015. -

Proquest Dissertations
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6” x 9” black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. Bell & Howell Information and Learning 300 North Zeeb Road, Ann Arbor, Ml 48106-1346 USA 800-521-0600 UMI" ARGUMENT STRUCTURE, HPSG, AND CHINESE GRAMMAR DISSERTATION Presented in Partial Fulfilment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University by Qian Gao, B.A., M.A. ******* The Ohio State University 2001 Dissertation Committee: Approved by Professor Carl J. Pollard, Adviser Professor Peter W. -

A Comparison of the Korean and Japanese Approaches to Foreign Family Names
15 A Comparison of the Korean and Japanese Approaches to Foreign Family Names JIN Guanglin* Abstract There are many foreign family names in Korean and Japanese genealogies. This paper is especially focused on the fact that out of approximately 280 Korean family names, roughly half are of foreign origin, and that out of those foreign family names, the majority trace their beginnings to China. In Japan, the Newly Edited Register of Family Names (新撰姓氏錄), published in 815, records that out of 1,182 aristocratic clans in the capital and its surroundings, 326 clans—approximately one-third—originated from China and Korea. Does the prevalence of foreign family names reflect migration from China to Korea, and from China and Korea to Japan? Or is it perhaps a result of Korean Sinophilia (慕華思想) and Japanese admiration for Korean and Chinese cultures? Or could there be an entirely distinct explanation? First I discuss premodern Korean and ancient Japanese foreign family names, and then I examine the formation and characteristics of these family names. Next I analyze how migration from China to Korea, as well as from China and Korea to Japan, occurred in their historical contexts. Through these studies, I derive answers to the above-mentioned questions. Key words: family names (surnames), Chinese-style family names, cultural diffusion and adoption, migration, Sinophilia in traditional Korea and Japan 1 Foreign Family Names in Premodern Korea The precise number of Korean family names varies by record. The Geography Annals of King Sejong (世宗實錄地理志, 1454), the first systematic register of Korean family names, records 265 family names, but the Survey of the Geography of Korea (東國輿地勝覽, 1486) records 277.