Specifying Optional Malayalam Conjuncts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
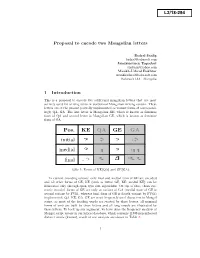
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Design of Javanese Text to Speech Application
Design of Javanese Text to Speech Application Yulia, Liliana, Rudy Adipranata, Gregorius Satia Budhi Informatics Department, Industrial Technology Faculty, Petra Christian University Surabaya, Indonesia [email protected] Abstract—Javanese is one of the many regional languages used in Indonesia. Javanese language is used by most of the population in Java. But now along with the development of the era, the use of regional languages including Javanese language is to be re- duced especially among the younger generation. One way to help conserve the use of Javanese language is to utilize information technologies, one of them is by developing a text to speech appli- cation that can be used to find out how the pronunciation of Ja- vanese language. In this paper, we discussed the design for Java- nese text to speech applications uses finite state automata. The design result will be used as rules to separate syllables when im- plementing text to speech application. Index Terms—Javanese language; Finite state automata; Text to speech. Figure 1: Basic Javanese characters I. INTRODUCTION In addition to the basic characters, the Javanese character Javanese language is a language widely spoken by the peo- has supplementary characters, consist of symbols for express- ple of Java. It is one of the regional languages of many region- ing vowels as well as a combination of two specific conso- al languages spoken in Indonesia. As one of the assets of na- nants. This supplementary characters is called sandhangan tional culture, Javanese language needs to be preserved. The and can be seen in Figure 2 [5]. younger generation is now more interested in learning a for- Symbol Example Read eign language, rather than the native Indonesian local lan- guage. -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

2016 Semi Finalists Medals
2016 US Physics Olympiad Semi Finalists Medal Rankings StudentMedal School City State Abbott, Ryan WHopkinsBronze Medal SchoolNew Haven CT Alton, James SLakesideHonorable Mention High SchoolEvans GA ALUMOOTIL, VARKEY TCanyonHonorable Mention Crest AcademySan Diego CA An, Seung HwanGold Medal Taft SchoolWatertown CT Ashary, Rafay AWilliamHonorable Mention P Clements High SchoolSugar Land TX Balaji, ShreyasSilver Medal John Foster Dulles High SchoolSugar Land TX Bao, MikeGold Medal Cambridge Educational InstituteChino Hills CA Beasley, NicholasGold Medal Stuyvesant High SchoolNew York NY BENABOU, JOSHUA N Gold Medal Plandome NY Bhattacharyya, MoinakSilver Medal Lynbrook High SchoolSan Jose CA Bhattaram, Krishnakumar SLynbrookBronze Medal High SchoolSan Jose CA Bhimnathwala, Tarung SBronze Medal Manalapan High SchoolManalapan NJ Boopathy, AkhilanGold Medal Lakeside Upper SchoolSeattle WA Cao, AntonSilver Medal Evergreen Valley High SchoolSan Jose CA Cen, Edward DBellaireHonorable Mention High SchoolBellaire TX Chadraa, Dalai BRedmondHonorable Mention High SchoolRedmond WA Chakrabarti, DarshanBronze Medal Northside College Preparatory HSChicago IL Chan, Clive ALexingtonSilver Medal High SchoolLexington MA Chang, Kevin YBellarmineSilver Medal Coll PrepSan Jose CA Cheerla, NikhilBronze Medal Monta Vista High SchoolSan Jose CA Chen, AlexanderSilver Medal Princeton High SchoolPrinceton NJ Chen, Andrew LMissionSilver Medal San Jose High SchoolFremont CA Chen, Benjamin YArdentSilver Medal Academy for Gifted YouthIrvine CA Chen, Bryan XMontaHonorable -

1 PASANGAN DAN SANDHANGAN DALAM AKSARA JAWA Oleh
PASANGAN DAN SANDHANGAN DALAM AKSARA JAWA1 oleh: Sri Hertanti Wulan [email protected] Jurusan Pendidikan Bahasa Daerah FBS UNY Aksara nglegena yang digunakan dalam ejaan bahasa Jawa pada dasarnya terdiri atas dua puluh aksara yang bersifat silabik Darusuprapta (2002: 12-13). Masing-masing aksara mempunyai aksara pasangan, yakni aksara yang berfungsi untuk menghubungkan suku kata mati/tertutup dengan suku kata berikutnya, kecuali suku kata yang tertutup dengan wignyan (.. ), layar (....), dan cecak (....). Pasangan – pasangan tersebut antara lain: a) Aksara pasangan wutuh, ditulis di bawah aksara yang diberi pasangan dan tidak disambung, yaitu antara lain: Tabel 1 Pasangan Wutuh pasangan Wujud Contoh Ra … dalan ramé= Ya … tumbas yuyu = Ga … dalan gĕdhé = .… dolan ngomah = nga b) Aksara pasangan tugelan ditulis di belakang aksara yang diberi pasangan dan tidak disambungkan dengan aksara yang diberi pasangan, yaitu antara lain: 1Disampaikan dalam PPM PelatihanAksaraJawadan PendirianHanacaraka Centre sebagaiRevitalisasiFungsiAksaraJawa kerjasama FBS UNY dan Dinas Dikpora DIY. Dilaksanakan di Dikpora DIY, Senin 28 Oktober 2013. 1 Tabel 2.1 Pasangan Tugelan pasangan Wujud Contoh ha … adhĕm hawané = pa … bakul pĕlĕm = sa … dalan sĕpi = c) Aksara pasangan tugelan ditulis di bawah aksara yang diberi pasangan dan tidak disambungkan dengan aksara yang diberi pasangan, yaitu antara lain: Tabel 2.2 Pasangan Tugelan pasangan Wujud Contoh kilèn kalen= ka … wis takon = ta … tas larang = la … Pasangan – pasangan tersebut, bila mendapatkan sandhangan -

Source Readings in Javanese Gamelan and Vocal Music, Volume 2
THE UNIVERSITY OF MICHIGAN CENTER FOR SOUTH AND SOUTHEAST ASIAN STUDIES MICHIGAN PAPERS ON SOUTH AND SOUTHEAST ASIA Editorial Board Alton L. Becker Karl L. Hutterer John K. Musgrave Peter E. Hook, Chairman Ann Arbor, Michigan USA KARAWITAN SOURCE READINGS IN JAVANESE GAMELAN AND VOCAL MUSIC Judith Becker editor Alan H. Feinstein assistant editor Hardja Susilo Sumarsam A. L. Becker consultants Volume 2 MICHIGAN PAPERS ON SOUTH AND SOUTHEAST ASIA; Center for South and Southeast Asian Studies The University of Michigan Number 30 Open access edition funded by the National Endowment for the Humanities/ Andrew W. Mellon Foundation Humanities Open Book Program. Library of Congress Catalog Card Number: 82-72445 ISBN 0-89148-034-X Copyright ©' 1987 by Center for South and Southeast Asian Studies The University of Michigan Publication of this book was assisted in part by a grant from the Publications Program of the National Endowment for the Humanities. Additional funding or assistance was provided by the National Endowment for the Humanities (Transla- tions); the Southeast Asia Regional Council, Association for Asian Studies; The Rackham School of Graduate Studies, The University of Michigan; and the School of Music, The University of Michigan. Printed in the United States of America ISBN 978-0-89-148034-1 (hardcover) ISBN 978-0-47-203819-0 (paper) ISBN 978-0-47-212769-6 (ebook) ISBN 978-0-47-290165-4 (open access) The text of this book is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License: https://creativecommons.org/licenses/by-nc-nd/4.0/ CONTENTS PREFACE: TRANSLATING THE ART OF MUSIC A. -

Halfwidth and Fullwidth Forms Range: FF00–FFEF
Halfwidth and Fullwidth Forms Range: FF00–FFEF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

ISO/IEC JTC1/SC2/WG2 N 2005 Date: 1999-05-29
ISO INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION --------------------------------------------------------------------------------------- ISO/IEC JTC1/SC2/WG2 Universal Multiple-Octet Coded Character Set (UCS) -------------------------------------------------------------------------------- ISO/IEC JTC1/SC2/WG2 N 2005 Date: 1999-05-29 TITLE: ISO/IEC 10646-1 Second Edition text, Draft 2 SOURCE: Bruce Paterson, project editor STATUS: Working paper of JTC1/SC2/WG2 ACTION: For review and comment by WG2 DISTRIBUTION: Members of JTC1/SC2/WG2 1. Scope This paper provides a second draft of the text sections of the Second Edition of ISO/IEC 10646-1. It replaces the previous paper WG2 N 1796 (1998-06-01). This draft text includes: - Clauses 1 to 27 (replacing the previous clauses 1 to 26), - Annexes A to R (replacing the previous Annexes A to T), and is attached here as “Draft 2 for ISO/IEC 10646-1 : 1999” (pages ii & 1 to 77). Published and Draft Amendments up to Amd.31 (Tibetan extended), Technical Corrigenda nos. 1, 2, and 3, and editorial corrigenda approved by WG2 up to 1999-03-15, have been applied to the text. The draft does not include: - character glyph tables and name tables (these will be provided in a separate WG2 document from AFII), - the alphabetically sorted list of character names in Annex E (now Annex G), - markings to show the differences from the previous draft. A separate WG2 paper will give the editorial corrigenda applied to this text since N 1796. The editorial corrigenda are as agreed at WG2 meetings #34 to #36. Editorial corrigenda applicable to the character glyph tables and name tables, as listed in N1796 pages 2 to 5, have already been applied to the draft character tables prepared by AFII. -

Malayalam Range: 0D00–0D7F
Malayalam Range: 0D00–0D7F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten.