Methods to Exploit Reconfigurable Fabrics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Switching Theory for Logic Synthesis Ad Hoc Wireless Networking Data
COMMUNICATION ENGINEERING & SIGNAL PROCESSING Switching Theory for Logic Synthesis Tsutomu Sasao Contents: 1. Mathematical Foundation. 2. Lattice and Boolean Algebra. 3. Logic Functions and their Representations 4. Optimization of and-or Two-level Logic Networks. 5. Logic Functions with Various Properties. 6. Sequential Networks. 7. Optimization of Sequential Networks. 8. Delay and Asynchronous Behavior. 9. Multi-valued Input Two-valued Output Function. 10. Heuristic Optimization of Two- level Networks. 11. Multi-level Logic Synthesis. 12. Logic Design Using Modules. 13. Logic Design Using EXORs. 14. Complexity of Logic Networks Rpt. 2011 379 pp 978-81-84898-02-6 BSPSPR Rs. 595.00 Ad Hoc Wireless Networking For New Arrivals visit Cheng Contents: 1. Introduction 2. Related Work 3. Formulation of Power-aware Routing 4. Online Power-aware Routing with max-min zPmin 5. Hierarchical Routing with max-min zPmin 6. Distributed Routing with max-min zPmin Rpt. 2011 630 pp 978-81-84898-48-4 BSPSPR Rs. 650.00 Communications Satellite Handbook : Walter L. Morgan, Gary D. Gordon www.bspbooks.net / www.bspublications.net Contents: 1. Obtaining Access to the Satellite 2. TELETRAFFIC 3. Interfaces Between Terrestrial and Satellite Systems 4. Telecommunications Systems 5. COMMUNICATIONS SATELLITE SYSTEMS 6. System Modeling 7. Overall System Calculations 8. MULTIPLE-ACCESS TECHNIQUES 9. Frequency Domain Multiple Access 10. Time Domain Multiple Access 11. Space Domain Multiple Access 12. Code Domain Multiple Access 13. Random Multiple Access 14. SPACECRAFT TECHNOLOGY 15. Space Configuration and Subsystems 16. Telemetry, Tracking, and Command 17. Solar Arrays 18. Attitude Control 19. Thermal Control 20. SATELLITE ORBITS 21. Direction of Orbit Normals and of Sun 22. -

Reconfigurable Computing
Reconfigurable Computing: A Survey of Systems and Software KATHERINE COMPTON Northwestern University AND SCOTT HAUCK University of Washington Due to its potential to greatly accelerate a wide variety of applications, reconfigurable computing has become a subject of a great deal of research. Its key feature is the ability to perform computations in hardware to increase performance, while retaining much of the flexibility of a software solution. In this survey, we explore the hardware aspects of reconfigurable computing machines, from single chip architectures to multi-chip systems, including internal structures and external coupling. We also focus on the software that targets these machines, such as compilation tools that map high-level algorithms directly to the reconfigurable substrate. Finally, we consider the issues involved in run-time reconfigurable systems, which reuse the configurable hardware during program execution. Categories and Subject Descriptors: A.1 [Introductory and Survey]; B.6.1 [Logic Design]: Design Style—logic arrays; B.6.3 [Logic Design]: Design Aids; B.7.1 [Integrated Circuits]: Types and Design Styles—gate arrays General Terms: Design, Performance Additional Key Words and Phrases: Automatic design, field-programmable, FPGA, manual design, reconfigurable architectures, reconfigurable computing, reconfigurable systems 1. INTRODUCTION of algorithms. The first is to use hard- wired technology, either an Application There are two primary methods in con- Specific Integrated Circuit (ASIC) or a ventional computing for the execution group of individual components forming a This research was supported in part by Motorola, Inc., DARPA, and NSF. K. Compton was supported by an NSF fellowship. S. Hauck was supported in part by an NSF CAREER award and a Sloan Research Fellowship. -

IBM Haifa Leadership Seminar - Agenda
IBM Haifa Leadership Seminar - Agenda IBM Verification Seminar 2004 November 21, 2004 9:15 Arrival 12:50 Piparazzi: A Micro-architecture Approach to Functional & Performance 9:30 Welcome, Verification in Processors, David Bernstein, Mgr., Software and Eyal Bin, IBM Haifa Labs Verification Technologies, IBM Haifa Labs 13:20 Lunch 9:45 Formal Verification of Synchronizers in GALS SoCs, 14:30 Keynote: Predicate Abstraction Ran Ginosar, Head, VLSI Systems and Refinement Techniques for Verifying Research Center, Electrical Engineering Verilog, Department, Technion - Israel Institute of Ed Clarke, FORE Systems Professor of Technology Computer Science and Professor of Electrical and Computer Engineering, 10:25 A Massively Parallel Platform for Carnegie Mellon University Formal Verification: RuleBase Parallel Edition, 15:30 Break Rachel Tzoref, IBM Haifa Labs 15:45 Debugging complex FPGA 10:55 SystemVerilog: Introduction and a platforms, User Perspective, Ivo Bolsens, Vice President and Chief Johny Srouji, Engineering Manager, Intel Technology Officer, Xilinx CAD Division, Haifa 16:15 Panel: HVL vs. HDVL, 11:25 Coffee break Panelists: Coby Chanoch, Verisity; Jay Lawrence, Cadence Design Systems; 11:40 State of the Technology Industry in Kobi Pines, Marvell Technology Group; Israel... and the Future, Rob Slater, FreeScale Semiconductor, Orna Berry, Venture Partner in Gemini Israel Funds and Former Chief Scientist of 17:00 Concluding Remarks, the Israeli Ministry of Industry and Trade Michael Rodeh, Director, IBM Haifa Labs 12:20 EDA Standards: Motivation, Players, Challenges, and Achievements, Dennis Brophy, Chair, Accellera Standards Organization and Director of Strategic Business Development, Model Technology http://www.haifa.il.ibm.com/Workshops/verification2004/. -

Reconfigurable Computing
Reconfigurable computing: architectures and design methods T.J. Todman, G.A. Constantinides, S.J.E. Wilton, O. Mencer, W. Luk and P.Y.K. Cheung Abstract: Reconfigurable computing is becoming increasingly attractive for many applications. This survey covers two aspects of reconfigurable computing: architectures and design methods. The paper includes recent advances in reconfigurable architectures, such as the Alters Stratix II and Xilinx Virtex 4 FPGA devices. The authors identify major trends in general-purpose and special- purpose design methods. It is shown that reconfigurable computing designs are capable of achieving up to 500 times speedup and 70% energy savings over microprocessor implementations for specific applications. 1 Introduction Recent research suggests that it is a trend rather than a one-off for a wide variety of applications: from image Reconfigurable computing is rapidly establishing itself as a processing [3] to floating-point operations [4]. major discipline that covers various subjects of learning, Sheer speed, while important, is not the only strength of including both computing science and electronic engineer- reconfigurable computing. Another compelling advantage is ing. Reconfigurable computing involves the use of reduced energy and power consumption. In a reconfigurable reconfigurable devices, such as field programmable gate system, the circuitry is optimised for the application, such arrays (FPGAs), for computing purposes. Reconfigurable that the power consumption will tend to be much lower than computing is also known as configurable computing or that for a general-purpose processor. A recent study [5] custom computing, since many of the design techniques can reports that moving critical software loops to reconfigurable be seen as customising a computational fabric for specific hardware results in average energy savings of 35% to 70% applications [1]. -

The Paramountcy of Reconfigurable Computing
Energy Efficient Distributed Computing Systems, Edited by Albert Y. Zomaya, Young Choon Lee. ISBN 978-0-471--90875-4 Copyright © 2012 Wiley, Inc. Chapter 18 The Paramountcy of Reconfigurable Computing Reiner Hartenstein Abstract. Computers are very important for all of us. But brute force disruptive architectural develop- ments in industry and threatening unaffordable operation cost by excessive power consumption are a mas- sive future survival problem for our existing cyber infrastructures, which we must not surrender. The pro- gress of performance in high performance computing (HPC) has stalled because of the „programming wall“ caused by lacking scalability of parallelism. This chapter shows that Reconfigurable Computing is the sil- ver bullet to obtain massively better energy efficiency as well as much better performance, also by the up- coming methodology of HPRC (high performance reconfigurable computing). We need a massive cam- paign for migration of software over to configware. Also because of the multicore parallelism dilemma, we anyway need to redefine programmer education. The impact is a fascinating challenge to reach new hori- zons of research in computer science. We need a new generation of talented innovative scientists and engi- neers to start the beginning second history of computing. This paper introduces a new world model. 18.1 Introduction In Reconfigurable Computing, e. g. by FPGA (Table 15), practically everything can be implemented which is running on traditional computing platforms. For instance, recently the historical Cray 1 supercomputer has been reproduced cycle-accurate binary-compatible using a single Xilinx Spartan-3E 1600 development board running at 33 MHz (the original Cray ran at 80 MHz) 0. -

Table of Contents
43rdDAC-2C 7/3/06 9:16 AM Page 1 The 43rd Design Automation Conference • July 24 - 28, 2006 • San Francisco, CA Table of Contents 44th DAC Call For Papers ........................................................................................64-65 Keynote Addresses Additional Conference and Hotel Information........................................inside back cover • Monday Keynote Address . 6 • Conference Shuttle Bus Service • Tuesday Keynote Address. 7 • First Aid Rooms • Thursday Keynote Address. .8 • Guest/Family Program MEGa Sessions..............................................................................................................5 • Hotel Locations Monday Schedule ........................................................................................................13 • On-Site Information Desk Monday Tutorial Descriptions..................................................................................42 • San Francisco Attractions New Exhibitors ............................................................................................................4 • Weather Panel Committee ........................................................................................................67 • Wednesday Night Party Pavilion Panels ..............................................................................................................9-12 Additional Meetings ....................................................................................................61-63 Proceedings ..................................................................................................................56 -

Efpgas : Architectural Explorations, System Integration & a Visionary Industrial Survey of Programmable Technologies Syed Zahid Ahmed
eFPGAs : Architectural Explorations, System Integration & a Visionary Industrial Survey of Programmable Technologies Syed Zahid Ahmed To cite this version: Syed Zahid Ahmed. eFPGAs : Architectural Explorations, System Integration & a Visionary Indus- trial Survey of Programmable Technologies. Micro and nanotechnologies/Microelectronics. Université Montpellier II - Sciences et Techniques du Languedoc, 2011. English. tel-00624418 HAL Id: tel-00624418 https://tel.archives-ouvertes.fr/tel-00624418 Submitted on 16 Sep 2011 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Université Montpellier 2 (UM2) École Doctorale I2S LIRMM (Laboratoire d'Informatique, de Robotique et de Microélectronique de Montpellier) Domain: Microelectronics PhD thesis report for partial fulfillment of requirements of Doctorate degree of UM2 Thesis conducted in French Industrial PhD (CIFRE) framework between: Menta & LIRMM lab (Dec.2007 – Feb. 2011) in Montpellier, FRANCE “eFPGAs: Architectural Explorations, System Integration & a Visionary Industrial Survey of Programmable Technologies” eFPGAs: Explorations architecturales, integration système, et une enquête visionnaire industriel des technologies programmable by Syed Zahid AHMED Presented and defended publically on: 22 June 2011 Jury: Mr. Guy GOGNIAT Prof. at STICC/UBS (Lorient, FRANCE) President Mr. Habib MEHREZ Prof. at LIP6/UPMC (Paris, FRANCE) Reviewer Mr. -

[email protected]
Reiner Hartenstein, University of Kaiserslautern, Germany [email protected] http://hartenstein.de viewgraph downloading: link found in 60 Semester Informatik I http://kressarray.de Kritik an der Praktischen Informatik Xputer Lab University of Kaiserslautern (in der Lehre) Festkolloquium Universität Dortmund, 18. – 19. Juli 2002 • mißbraucht ihre Zweidrittel-Mehrheit • hält die Prägungsphase strikt „procedural-only“ • Absolventen sind daher völlig unvorbereitet für Reiner Hartenstein die nahe Zukunft Data-Stream-based Computing: Universität – Wo >90% der Anwendungen für eingebettete Kaiserslautern Antimaterie der Kern-Informatik Systeme implementiert werden – Wie für 2010 vorhergesagt • nur wenige % des Kurrikulum wären zu ändern • meine Mission: Sie hierfür zu gewinnen © 2002, [email protected] 2 http://KressArray.de Kritik an der Technischen Informatik, TI die Kern-Informatik: jung ? dynamisch ? University of Kaiserslautern (klassischer Art) University of Kaiserslautern .. ist nach >10 Technologie-Generationen ... • diese ist noch immer weit verbreitet das von Neumann Paradigma .... • keine Vorbereitung auf die heutige Arbeitswelt • 1th 4004 ... der vN Mikroprozessor • 2nd 8008 ... noch immer ist ein Methusalem ... • Indizien: Begriffe wie „Rechnerorganisation“, • 3rd 8086 die vorherrschende „Rechnerstrukturen, “„Rechnerarchitektur“ • 4th 80286 Doktrin • 5th 80386 ... die Dampfmaschine • vN-only, alles andere wird konsequent verschwiegen • 6th 80486 des Silizium-Zeitalters die Mikroelektronik • 7th P5 (Pentium) • Paradebeispiel: -

Volume 11 Number 4 October-December 2019
I Volume 11 Number 4 October-December 2019 International Journal of Nursing Education Editor-in-Chief Amarjeet Kaur Sandhu Principal & Professor, Ambika College of Nursing, Mohali, Punjab E-mail: [email protected] INTERNATIONAL EDITORIAL ADVISORY BOARD NATIONAL EDITORIAL ADVISORY BOARD 1. Dr. Arnel Banaga Salgado (Asst. Professor) 4. Fatima D’Silva (Principal) Psychology and Psychiatric Nursing, Center for Educational Nitte Usha Institute of nursing sciences, Karnataka Development and Research (CEDAR) member, Coordinator, 5. G.Malarvizhi Ravichandran RAKCON Student Affairs Committee,RAK Medical and PSG College of Nursing, Coimbatore, Tamil Nadu Health Sciences University, Ras Al Khaimah, United Arab Emirates 6. S. Baby (Professor) (PSG College of Nursing, Coimbatore, Tamil Nadu, Ministry of Health, New Delhi 2. Elissa Ladd (Associate Professor) MGH Institute of Health Professions Boston, USA 7. Dr. Elsa Sanatombi Devi (Professor and Head) Meidcal Surgical Nursing, Manipal Collge of nursing, Manipal 3. Roymons H. Simamora (Vice Dean Academic) Jember University Nursing School, PSIK Universitas Jember, 8. Dr. Baljit Kaur (Prof. and Principal) Jalan Kalimantan No 37. Jember, Jawa Timur, Indonesia Kular College of Nursing, Ludhiana, Punjab 4. Saleema Allana (Assistant Professor) 9. Mrs. Josephine Jacquline Mary.N.I (Professor Cum AKUSONAM, The Aga Khan University, School of Nursing Principal) Si-Met College of Nursing, Udma, Kerala and Midwifery, Stadium Road, Karachi Pakistan 10. Dr. Sukhpal Kaur (Lecturer) National Institute of Nursing 5. Ms. Priyalatha (Senior lecturer) RAK Medical & Health Education, PGIMER, Chandigarh Sciences University, Ras Al Khaimah,UAE 11. Dr. L. Eilean Victoria (Professor) Dept. of Medical Surgical 6. Mrs. Olonisakin Bolatito Toyin (Senior Nurse Tutor) Nursing at Sri Ramachandra College School of Nursing, University College Hospital, Ibadan, Oyo of Nursing, Chennai, Tamil Nadu State, Nigeria 12. -
Apple Ecosystem Y
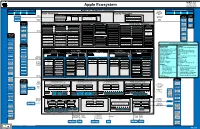
Apple Inc. One Apple Park Way Cupertino, CA 95014 Apple Ecosystem Phone: (408) 996-1010 www.apple.com Outside Relationships Apple Inc. (California Corporation) Securities Outside Relationships Regulation and Regulators Capital Suppliers Customers NASDAQ Listing Customers Suppliers Capital Regulators Debt Structure Equity Structure Rules Bond Debt ( $107B @ 9/28/19) Credit Ratings: Aa1 (Moody’s), AA+ (S&P) Equity Securities Public Debt Financing Common Stock Significant Regulators Common Stock (12.6 Billion Authorized; Holders Senior Floating Senior Fixed Rate Notes ($97.5B), Repurchases Shareholders 4.443 Million Shares Outstanding) US Securities Commercial Rate Notes bearing interest at 0.875% to 3.6% Vanguard Commercial Commercial Paper (9- Equity and Paper ($4.25B) and maturing 2022 to 2042 Group Banks months or less) ($6 billion) $175 Billion Share Repurchase Program Capital Exchange (7.36%) Commission Professional Berkshire Services Governance Human Resources Sales and Marketing Finance and Accounting Corporate Matters Hathaway The NASDAQ Board of Directors Research & (5.6%) Hiring / Training Legal Stock Market Ernst & Young Advertising Budget Support Development Arthur D. Levinson (C) Albert Gore Jr. (C, N) Susan L. Wagner (N, A) Real Estate IP Management BlackRock (Auditors) New Technologies Pension Plans Retail Accounts Internal Audit Fund TBWA/Media Tim Cook Andrea Jung (C, N) Ronald D. Sugar (A) Transactions Subsidiary Management Existing Product Advisors Professional Compensation E Commerce Accounting Arts Lab Enhancements -

Apple Ecosystem Cupertino, CA 95014 Phone: (408) 996-1010
Apple Inc. One Apple Park Way Apple Ecosystem Cupertino, CA 95014 Phone: (408) 996-1010 www.apple.com Outside Relationships Apple Inc. (California Corporation) Securities Outside Relationships Regulation and Regulators Capital Suppliers Customers NASDAQ Listing Customers Suppliers Capital Regulators Debt Structure Equity Structure Rules Bond Debt ( $107B @ 9/28/19) Credit Ratings: Aa1 (Moody’s), AA+ (S&P) Equity Securities Public Debt Financing Common Stock Significant Regulators Common Stock (12.6 Billion Authorized; Holders Senior Floating Senior Fixed Rate Notes ($97.5B), Repurchases Shareholders 4.443 Million Shares Outstanding) US Securities Commercial Rate Notes bearing interest at 0.875% to 3.6% Vanguard Commercial Commercial Paper (9- Equity and Paper ($4.25B) and maturing 2022 to 2042 Group Banks months or less) ($6 billion) $175 Billion Share Repurchase Program Capital Exchange (7.36%) Commission Professional Berkshire Services Governance Human Resources Sales and Marketing Finance and Accounting Corporate Matters Hathaway The NASDAQ Board of Directors Research & (5.6%) Legal Stock Market Ernst & Young Hiring / Training Advertising Budget Support Development Arthur D. Levinson (C) Albert Gore Jr. (C, N) Susan L. Wagner (N, A) Real Estate IP Management BlackRock (Auditors) New Technologies Pension Plans Retail Accounts Internal Audit Fund TBWA/Media Tim Cook Andrea Jung (C, N) Ronald D. Sugar (A) Transactions Subsidiary Management Existing Product Advisors Professional Compensation E Commerce Accounting Arts Lab Enhancements -

Apple Names Jeff Williams As Chief Operating Officer 17 December 2015, Bythe Associated Press
Apple names Jeff Williams as chief operating officer 17 December 2015, byThe Associated Press At Grey, Myhren was chief creative officer and president of its New York office. Apple Inc., based in Cupertino, California, also expanded the roles of two other executives. It upped Johny Srouji's position to senior vice president of hardware technologies from vice president and said Senior Vice President of Worldwide Marketing Phil Schiller would now add Apple's app store to his responsibilities. In afternoon trading, Apple shares slipped $1.95, or 1.7 percent, to $109.39. © 2015 The Associated Press. All rights reserved. In this March 9, 2015 file photo, Apple Vice President of Operations, Jeff Williams, discusses ResearchKit during an Apple event in San Francisco. Apple named Williams as its new chief operating officer Thursday, Dec. 17, 2015, a job that hasn't been filled since Tim Cook left the position more than four years ago to become CEO. Williams has worked at Apple for about 17 years and supervised the launch of the Apple Watch, which went on sale earlier this year. (AP Photo/Eric Risberg) Apple named Jeff Williams as its chief operating officer Thursday, a job that hasn't been filled since Tim Cook left the position more than four years ago to become CEO. Williams has worked at Apple for about 17 years and supervised the launch of the Apple Watch, which went on sale earlier this year. The company said he played a "key role" in the launch of the iPhone. Apple also announced Thursday that it hired Tor Myhren from advertising company Grey Group to be vice president of marketing communications.