A Full Duplex Ethernet Ring Network for New Generation Avionics Systems Ahmed Amari
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
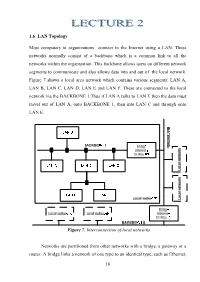
16 1.6 . LAN Topology Most Computers in Organizations Connect to the Internet Using a LAN. These Networks Normally Consist of A
1.6 . LAN Topology Most computers in organizations connect to the Internet using a LAN. These networks normally consist of a backbone which is a common link to all the networks within the organization. This backbone allows users on different network segments to communicate and also allows data into and out of the local network. Figure 7 shows a local area network which contains various segments: LAN A, LAN B, LAN C, LAN D, LAN E and LAN F. These are connected to the local network via the BACKBONE 1.Thus if LAN A talks to LAN E then the data must travel out of LAN A, onto BACKBONE 1, then into LAN C and through onto LAN E. Figure 7. Interconnection of local networks Networks are partitioned from other networks with a bridge, a gateway or a router. A bridge links a network of one type to an identical type, such as Ethernet, 16 or Token Ring to Token Ring. A gateway connects two dissimilar types of networks and routers operate in a similar way to gateways and can either connect to two similar or dissimilar networks. The key operation of a gateway, bridge or router is that they only allow data traffic through that is intended for another network, which is outside the connected network. This filters traffic and stops traffic, not intended for the network, from clogging-up the backbone. Most modern bridges, gateways and routers are intelligent and can automatically determine the topology of the network. Spanning-tree bridges have built-in intelligence and can communicate with other bridges. -

Chapter 6 Medium Access Control Protocols and Local Area Networks
Chapter 6 Medium Access Control Protocols and Local Area Networks Part I: Medium Access Control Part II: Local Area Networks Chapter Overview l Broadcast Networks l Medium Access Control l All information sent to all l To coordinate access to users shared medium l No routing l Data link layer since direct l Shared media transfer of frames l Radio l Local Area Networks l Cellular telephony l High-speed, low-cost l Wireless LANs communications between co-located computers l Copper & Optical l Typically based on l Ethernet LANs broadcast networks l Cable Modem Access l Simple & cheap l Limited number of users Chapter 6 Medium Access Control Protocols and Local Area Networks Part I: Medium Access Control Multiple Access Communications Random Access Scheduling Channelization Delay Performance Chapter 6 Medium Access Control Protocols and Local Area Networks Part II: Local Area Networks Overview of LANs Ethernet Token Ring and FDDI 802.11 Wireless LAN LAN Bridges Chapter 6 Medium Access Control Protocols and Local Area Networks Multiple Access Communications Multiple Access Communications l Shared media basis for broadcast networks l Inexpensive: radio over air; copper or coaxial cable l M users communicate by broadcasting into medium l Key issue: How to share the medium? 3 2 4 1 Shared multiple access medium M 5 … Approaches to Media Sharing Medium sharing techniques Static Dynamic medium channelization access control l Partition medium Scheduling Random access l Dedicated allocation to users l Polling: take turns l Loose l Satellite l Request -

Media Access Control (MAC) (With Some IEEE 802 Standards)
Department of Computer and IT Engineering University of Kurdistan Computer Networks I Media Access Control (MAC) (with some IEEE 802 standards) By: Dr. Alireza Abdollahpouri Media Access Control Multiple access links There is ‘ collision ’ if more than one node sends at the same time only one node can send successfully at a time 2 Media Access Control • When a "collision" occurs, the signals will get distorted and the frame will be lost the link bandwidth is wasted during collision • Question: How to coordinate the access of multiple sending and receiving nodes to the shared link ? • Solution: We need a protocol to determine how nodes share channel Medium Access control (MAC) protocol • The main task of a MAC protocol is to minimize collisions in order to utilize the bandwidth by: - Determining when a node can use the link (medium) - What a node should do when the link is busy - What the node should do when it is involved in collision 3 Ideal Multiple Access Protocol 1. When one node wants to transmit, it can send at rate R bps, where R is the channel rate. 2. When M nodes want to transmit, each can send at average rate R/M (fair) 3. fully decentralized: - No special node to coordinate transmissions - No synchronization of clocks, slots 4. Simple Does not exist!! 4 Three Ways to Share the Media Channel partitioning MAC protocols: • Share channel efficiently and fairly at high load • Inefficient at low load: delay in channel access, 1/N bandwidth allocated even if only 1 active node! “Taking turns” protocols • Eliminates empty slots without -

Network Topologies
Application Notes NETWORK TOPOLOGIES Author John Peter & Timo Perttunen Issued June 2014 Abstract Network topology is the way various components of a network (like nodes, links, peripherals, etc) are arranged. Network topologies define the layout, virtual shape or structure of network, not only physically but also logically. The way in which different systems and nodes are connected and communicate with each other is determined by topology of the network. Topology can be physical or logical. Physical Topology is the physical layout of nodes, workstations and cables in the network; while logical topology is the way information flows between different components. Distances between nodes, physical interconnections, transmission rates, and/or signal types may differ between two networks, yet their topologies may be identical. Keywords Topology, P2P, Bus, Ring, Star, Mesh, Tree, PON, Ethernet. 1 Topology - General Network topology is usually a schematic description of the arrangement of a network, including its nodes and connecting lines. There are two ways of defining network geometry: the physical topology and the logical (or signal) topology. Physical topology describes where the network's various components like its devices and cables are placed and installed, while logical topology explains network's information (data) flow and transmission, apart from physical design. Distances between nodes, physical interconnections, transmission rates, and/or signal types may differ between two networks, yet their topologies may be identical. FTTH example: Nodes in FTTH has one or more physical links to other devices in the network and drawing links, network designing, between these nodes in a map gives the physical topology for the network. -
The 5 Major Technologies
February2013 / Issue 2 SYSTEM COMPARISON The 5 Major Technologies PROFINET, nd POWERLINK, Edition EtherNet/IP, 2 EtherCAT, SERCOS III How the Systems Work The User Organizations A Look behind the Scenes Investment Viability and Performance Everything You Need to Know! Safety protocols Learn the basics! EPSG_IEF2ndEdition_en_140416.indd 1 16.04.14 16:02 Luca Lachello Peter Wratil Anton Meindl Stefan Schönegger Bhagath Singh Karunakaran Huazhen Song Stéphane Potier INTRODUCTION 4 · Selection of Systems for Review Preface Outsiders are not alone in finding the world of Industrial Ethernet somewhat confusing. Experts who examine the matter are similarly puzzled by a broad and intransparent line-up of competing HOW THE SYSTEMS WORK 6 · Approaches to Real-Time systems. Most manufacturers provide very little information of that rare sort that captures tech- · PROFINET Communication nical characteristics and specific functionalities of a certain standard in a way that is both com- · POWERLINK Communication prehensive and easy to comprehend. Users will find themselves even more out of luck if they are · EtherNet/IP Communication seeking material that clearly compares major systems to facilitate an objective assessment. · EtherCAT Communication · SERCOS III Communication We too have seen repeated inquiries asking for a general overview of the major systems and wondering “where the differences actually lie”. We have therefore decided to dedicate an issue ORGANIZATIONS 12 · User Organizations and Licensing Regimes of the Industrial Ethernet Facts to this very topic. In creating this, we have tried to remain as objective as a player in this market can be. Our roundup focuses on technical and economic as well as on strategic criteria, all of which are relevant for a consideration of the long-term viability CRITERIA FOR INVESTMENT VIABILITY 16 · Compatibility / Downward Compatibility · Electromagnetic Compatibility (EMC) · Electrical Contact Points of investments in Industrial Ethernet equipment. -

Understanding Local Area Networking
Understanding Local Area Networking Module 1 Objectives Skills/Concepts Objective Domain Objective Domain Description Number Examining Local Area Understand local area 1.2 Networks, Devices and networks (LANS) Data Transfers Identifying Network Understand network 1.5 Topologies and topologies and access Standards methods Network components and Terminology • Data • Switch • Node • Router • Client • Media • Server • Transport Protocol • Peer • Bandwidth • Network adapter • Hub Local Area Network A Local Area Network (LAN) A LAN is a group of is group of computers computers or devices that confined to a small share a common geographic area, such as a communication medium, single building such as cabled or wireless connections Networks • Networks are used to exchange data • Reasons for networks include • Sharing information • Communication • Organizing data Network Documentation • Network documentation helps describe, define, and explain the physical and logical method for connecting devices • The documentation phase occurs before a network is built, or when changes are made to the network • Microsoft Visio is a tool that can be used to document networks Hub • A Hub is the most basic central connecting device • • Hubs enable computers on a network to • communicate • A host sends data to the hub. The hub sends the data to all devices connected to the hub Switch • Switches work the same was as a hub, but they can identify the • intended recipient of the data • • Switches can send and receive data at the same time Router Internet • Routers enable -

Of 79 UNITED STATES DISTRICT COURT EASTERN DISTRICT of TEXAS MARSHALL DIVISION Plaintiff, V. Defendant. Civil Action
Case 2:18-cv-00060 Document 1 Filed 03/08/18 Page 1 of 79 PageID #: 1 UNITED STATES DISTRICT COURT EASTERN DISTRICT OF TEXAS MARSHALL DIVISION DIFF SCALE OPERATION RESEARCH, LLC, Civil Action No._________ Plaintiff, v. JURY TRIAL DEMANDED CISCO SYSTEMS, INC. Defendant. COMPLAINT FOR PATENT INFRINGEMENT DIFF Scale Operation Research, LLC (“Plaintiff”), by its undersigned counsel, bring this action and make the following allegations of patent infringement relating to U.S. Patent Nos.: 7,881,413 (the, “‘413 patent”); 6,664,827 (the, “‘827 patent”); 7,106,758 (the, “‘758 patent”); 6,407,983 (the, “‘983 patent”); 6,847,609 (the, “‘609 patent”); 6,940,810 (the, “‘810 patent”); 6,990,110 (the, “‘110 patent”); 6,721,328 (the, “‘328 patent”); and 6,216,166 (the, “‘166 patent”); and 6,859,430 (the, “‘430 patent”) (collectively, the “patents-in-suit”). Defendant Cisco Systems, Inc. (“Cisco” or “Defendant”) infringes each of the patents-in-suit in violation of the patent laws of the United States of America, 35 U.S.C. § 1 et seq. INTRODUCTION This case arises from Cisco’s infringement of a portfolio of semiconductor and network infrastructure patents. This patent portfolio arose from the groundbreaking work of ADC Telecommunications, Inc. (“ADC Telecommunications”). Page 1 of 79 Case 2:18-cv-00060 Document 1 Filed 03/08/18 Page 2 of 79 PageID #: 2 In 1935, ADC Telecommunications, then known as the Audio Development Company1 was founded in Minneapolis, Minnesota by two Bell Laboratory engineers to create custom transformers and amplifiers for the broadcast radio industry. -

IP Photonic Node
UDC 535.14:621.391 IP Photonic Node VHaruo Yamashita VTakashi Hatano VSatoshi Nojima VNobuhide Yamaguchi (Manuscript received February 28, 2001) This paper describes an IP photonic node architecture and its migration based on a single virtual-router view network. The IP photonic node features node cut-through at a various levels such as the wavelength, SONET frame, and/or packet path. Its coordi- nation capability for optical and packet paths enables efficient usage of network re- sources, for example, for the transportation and restoration of very large volumes of IP traffic. This paper also presents some recent photonic technology to make the IP photonic node configurable and expandable. 1. Introduction ing (WDM) transport, an optical amplifier for a The volume of IP traffic is growing exponen- large number of wavelengths, and tunable laser tially because of the widespread use of applications diodes and filters. such as the Internet; virtual private networks (VPNs); and communications between data cen- 2. IP photonic node architecture ters, between collocation facilities, and within based on a single virtual- storage area networks. Photonic networking is router view regarded as an essential and core technology to 2.1 Virtual-router view network cope with this trend. Vigorous efforts to accom- To cope with the ever-increasing IP traffic, modate a huge capacity have been made, and solve the processing bottleneck problem, and meet multi-vendor environment construction has been the demands for Class of Service (CoS) and Qual- promoted by organizations such as the ITU-T, In- ity of Service (QoS), we proposed an IP core ternet Engineering Task Force (IETF), and Optical transport network and transport node architec- Internetworking Forum (OIF). -

Local Area Networks for Radiology
Local Area Networks for Radiology Samuel J. Dwyer, III, Nicholas J. Mankovich, Glendon G. Cox, and Roger A. Bauman This article is a tutorial on local area networks (LAN) area were connected to a concentrator which was for radiology applications. LANs are being imple connected by a single communication link to the mented in radiology departments for the manage central computer. This reduced the cost of data ment of text and images. replacing the inflexible point-to-point wiring between two devices (com communication links by replacing a number of puter-to-terminal). These networks enable the shar them with a single link. Second, the computer ing of computers and computer devices. reduce was relieved of all communication processing equipment costs. and provide improved reliability. tasks by special processors called front ends. Any LAN must include items from the following four In the early 1970s, large area data networks categories: transmission medium. topology. data transmission mode. and access protocol. Media for became available for connecting multiple com local area networks are twisted pair. coaxial. and puter systems and peripheral devices. These net optical fiber cables. The topology of these networks works became known as wide area networks. The include the star. ring. bus. tree. and circuit-switch cost of communication links in these wide area ing. Data transmission modes are either analog sig networks remains a significant percentage of the nals or digital signals. Access protocol methods include the broadcast bus system and the ring sys total operating cost. tem. A performance measurement for a LAN is the In the 1980s, solid state technology advances throughput rate as a function of the number of active have provided the powerful microcomputer sys computer nodes. -

Industrial Communications and Control Protocols
PDHonline Course E497 (3 PDH) Industrial Communications and Control Protocols By Michael J. Hamill, P.E. Copyright ©2016 Updated 2019 PDH Online | PDH Center 5272 Meadows Estate Drive Fairfax, VA. 22030-6658 Phone: 703-988-0088 www.PDHonline.com www.PDHcenter.org An Approved Continuing Education Provider www.pdhcenter.org PDHonline Course E497 www.pdhonline.com Index Introduction 3 Protocol: A definition 3 Digital Data Basics 3 Differences in Controller Types 5 Diversity in the PLC/DCS/PAC market and its problems 5 Networks, Nodes, and Topologies 7 The OSI Model and its importance 11 Hardware and Connecting Cables 12 Communication methods 14 Deterministic communications 15 Interface standards and devices 16 Common Features in Protocols 18 Some Notable Automation Companies 19 Proprietary and Open Protocols 20 The HART protocol 20 TCP/IP 21 Control protocols 22 Modbus and some of its variants 23 Modbus Plus 23 Rockwell / Allen-Bradley Protocols 23 Some Important Open Protocols 25 The Fieldbus Foundation and its work 25 FOUNDATION Fieldbus H1 25 FOUNDATION Fieldbus HSE 26 The PROFIBUS Standards 27 PROFIBUS PA 27 PROFIBUS DP 28 PROFINET 28 Protocols used with HMIs 28 Windows OS and OPC 29 Local operator terminals 30 Transmitters, actuators and protocols 30 Disadvantages of using protocols 30 Summary 31 Appendix: Overview of the Modbus RTU Protocol 32 References 34 Endnotes 34 © M.J. Hamill, Industrial Communications and Control Protocols 2 www.pdhcenter.org PDHonline Course E497 www.pdhonline.com Introduction This course is intended to benefit -
STAFFAN TUNIS REAL-TIME INDUSTRIAL ETHERNET in MACHINE AUTOMATION SYSTEMS Master of Science Thesis
STAFFAN TUNIS REAL-TIME INDUSTRIAL ETHERNET IN MACHINE AUTOMATION SYSTEMS Master of Science Thesis Examiner: Professor Seppo Kuikka Examiner and topic approved in the Faculty of Automation, Mechanical and Materials Engineering Council meeting on 9 December 2009 II ABSTRACT TAMPERE UNIVERSITY OF TECHNOLOGY Master’s Degree Programme in Automation Technology TUNIS, STAFFAN: Real-Time Industrial Ethernet in Machine Automation Systems Master of Science Thesis, 89 pages June 2010 Major: Automation Technology Examiner: professor Seppo Kuikka Keywords: Real-Time, Industrial Ethernet, Fieldbus, EtherCAT, Networked Control System, Control Netwok During the last two decades, Ethernet has become the de facto standard in office level networks. There are several motivations for using Ethernet also in control networks, including the abundance of low cost components, the high data transfer rates and the possibility of vertical integration with other networks of the organization. The first in- dustrial implementation of Ethernet was for communication between different devices on the controller level. Modern real-time industrial Ethernet technologies, like the ones studied in this thesis, have brought Ethernet also down to the field level. The thesis is divided into two sections. The first section contains presentations of the seven most used real-time industrial Ethernet technologies. The second section contains a more thorough study of EtherCAT, the one of the seven technologies that promise the best real-time performance. The main goals are to provide a review of the different tech- nologies available and to study the suitability of EtherCAT in the control networks of machine automation systems. In the first section, different real-time industrial Ethernet technologies are divided into three groups based upon how much they differ from standard office Ethernet. -
Communication Interfaces - Overview
Communication Interfaces - Overview Technologies PoE Products Everything for industrial networks Communication Interfaces - Our product portfolio Fieldbus Ethernet Communication Infrastructure Remote Wireless Communication ⌂ Fieldbus Communication 1 Repeater Fast Converter Segment connectors Isolator Coupler (SUBCON) Fiber optic Extender Modular hub converter Serial/Profibus Fieldbus Communication 2 Radioline Protocol Terminator Multipoint- converter resistor Multiplexer ⌂ Fieldbus Communication 2 Fieldbus Serial Foundation Device Device fieldbus Coupler Server Power Zone 2 Fieldbus Fieldbus Fieldbus Device Device Device Fieldbus Coupler Coupler Ethernet Terminal box Communication 1 Zone 2 Zone 1 Infrastructure Profibus Profibus PA Ethernet DP/PA I/O HART Converter Multiplexer Multiplexer ⌂ Ethernet Infrastructure Ethernet Media Ethernet Extender Converter Isolator Ethernet Patch PoE HART Fieldbus Panel Injector Wireless communication 2 Multiplexer Serial Data Device connectors Server ⌂ Wireless Wireless Wireless Radioline Multiplexer HART Radioline Bluetooth Ethernet Outdoor WLAN Remote EPA Infrastructure solution communication ⌂ Remote communication TC Mobile DSL TC MGuard I/O Router TC Cloud mGuard TC Router Wireless Client Secure Cloud Technologies ⌂ Technologies Power PoE over Technology Ethernet Remote communication ⌂ Converter and isolator Interference-free and robust High-grade 2 kV electrical isolation Integrated power supply unit between the power supply and the The device can be supplied directly data interfaces with 24 V AC/DC Improve performance Thanks to integrated signal amplification, you can achieve a significant improvement 3-way-isolation in the transmission speed and range of your network. Product ⌂ overview Converter and isolator . Isolator for RS-232 . Repeater RS 485 . Repeater LON . Converter for RS-232 to RS-422 RS-485 2-wire RS-485 4-wire . Converter for RS-232 to TTY .