Reliability and Availability Design Issues for Lans
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introducing Zigbee Theory and Practice Into Information and Computer Technology Disciplines
AC 2007-1072: INTRODUCING ZIGBEE THEORY AND PRACTICE INTO INFORMATION AND COMPUTER TECHNOLOGY DISCIPLINES Crystal Bateman, Brigham Young University Crystal Bateman is an Undergraduate Student at BYU studying Information Technology. Her academic interests include ubiquitous technologies and usability. She is currently finishing an honors thesis on using mobile ZigBee motes in a home environment, and enjoying life with her husband and two daughters Janell Armstrong, Brigham Young University Janell Armstrong is a Graduate Student in Information Technology at BYU. Her interests are in ZigBee and public key infrastructure. She has three years experience as a Teacher's Assistant. Student memberships include IEEE, IEEE-CS, ACM, SWE, ASEE. C. Richard Helps, Brigham Young University Richard Helps is the Program Chair of the Information Technology program at BYU and has been a faculty member in the School of Technology since 1986. His primary scholarly interests are in embedded and real-time computing and in technology education. He also has interests in human-computer interfacing. He has been involved in ABET accreditation for about 8 years and is a Commissioner of CAC-ABET and a CAC accreditation team chair. He spent ten years in industry designing industrial automation systems and in telecommunications. Professional memberships include IEEE, IEEE-CS, ACM, SIGITE, ASEE. Page 12.982.1 Page © American Society for Engineering Education, 2007 Introducing ZigBee Theory and Practice into Information and Computer Technology Disciplines Abstract As pervasive computing turns from the desktop model to the ubiquitous computing ideal, the development challenges become more complex than simply connecting a peripheral to a PC. A pervasive computing system has potentially hundreds of interconnected devices within a small area. -

13 Embedded Communication Protocols
13 Embedded Communication Protocols Distributed Embedded Systems Philip Koopman October 12, 2015 © Copyright 2000-2015, Philip Koopman Where Are We Now? Where we’ve been: •Design • Distributed system intro • Reviews & process • Testing Where we’re going today: • Intro to embedded networking – If you want to be distributed, you need to have a network! Where we’re going next: • CAN (a representative current network protocol) • Scheduling •… 2 Preview “Serial Bus” = “Embedded Network” = “Multiplexed Wire” ~= “Muxing” = “Bus” Getting Bits onto the wire • Physical interface • Bit encoding Classes of protocols • General operation • Tradeoffs (there is no one “best” protocol) • Wired vs. wireless “High Speed Bus” 3 Linear Network Topology BUS • Good fit to long skinny systems – elevators, assembly lines, etc... • Flexible - many protocol options • Break in the cable splits the bus • May be a poor choice for fiber optics due to problems with splitting/merging • Was prevalent for early desktop systems • Is used for most embedded control networks 4 Star Network Topologies Star • Can emulate bus functions – Easy to detect and isolate failures – Broken wire only affects one node – Good for fiber optics – Requires more wiring; common for Star current desktop systems • Broken hub is catastrophic • Gives a centralized location if needed – Can be good for isolating nodes that generate too much traffic Star topologies increasing in popularity • Bus topology has startup problems in some fault scenarios • Safety critical control networks moving -

Survey of Important Issues in UAV Communications Networks
1 Survey of Important Issues in UAV Communication Networks Lav Gupta*, Senior Member IEEE, Raj Jain, Fellow, IEEE, and Gabor Vaszkun technology that can be harnessed for military, public and civil Abstract—Unmanned Aerial Vehicles (UAVs) have enormous applications. Military use of UAVs is more than 25 years old potential in the public and civil domains. These are particularly primarily consisting of border surveillance, reconnaissance and useful in applications where human lives would otherwise be strike. Public use is by the public agencies such as police, endangered. Multi-UAV systems can collaboratively complete missions more efficiently and economically as compared to single public safety and transportation management. UAVs can UAV systems. However, there are many issues to be resolved provide timely disaster warnings and assist in speeding up before effective use of UAVs can be made to provide stable and rescue and recovery operations when the public communication reliable context-specific networks. Much of the work carried out in network gets crippled. They can carry medical supplies to areas the areas of Mobile Ad Hoc Networks (MANETs), and Vehicular rendered inaccessible. In situations like poisonous gas Ad Hoc Networks (VANETs) does not address the unique infiltration, wildfires and wild animal tracking UAVs could be characteristics of the UAV networks. UAV networks may vary from slow dynamic to dynamic; have intermittent links and fluid used to quickly envelope a large area without risking the safety topology. While it is believed that ad hoc mesh network would be of the personnel involved. most suitable for UAV networks yet the architecture of multi-UAV UAVs come networks has been an understudied area. -

Comparison of Network Topologies for Optical Fiber Communication
International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Vol. 1 Issue 10, December- 2012 Comparison Of Network Topologies For Optical Fiber Communication Mr. Bhupesh Bhatia Ms. Ashima Bhatnagar Bhatia Department of Electronics and Communication, Department of Computer Science, Guru Prem Sukh Memorial College of Engineering, Tecnia Institute of Advanced Studies, Delhi Delhi Ms. Rashmi Ishrawat Department of Computer Science, Tecnia Institute of Advanced Studies, Delhi Abstract advent of the Information age. Optical In this paper, the various network topologies technologies can cost effectively meet have been compared. The signal is analyzed as it corporate bandwidth needs today and passes through each node in each of the network tomorrow. Internet connections offering topology. There is no appreciable signal degradation in the ring network. Also there is bandwidth on demand, to fiber on the increase in Quality factor i.e. signal keeps on LAN. Fiber to the home can provide true improving as it passes through the successiveIJERT IJERTbroadband connectivity for nodes. For the bus topology, the quality of signal telecommuters as well as converged goes on decreasing with increase in the number multimedia offerings for consumers [2]. of nodes and the power penalty goes on increasing. For the star topology, it is observed These different communication networks that received power values of each node at a can be configured in a number of same distance from the hub are same and the topologies. These include a bus, with or performance is same. For the tree topology, it is without a backbone, a star network, a observed that the performance is almost identical ring network, which can be redundant to the performance of ring topology, as signal quality is improved as it passes through the and/ or self-healing, or some successive nodes of the hierarchy. -
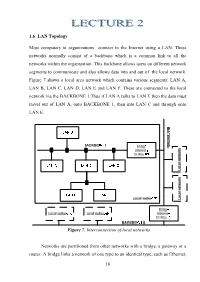
16 1.6 . LAN Topology Most Computers in Organizations Connect to the Internet Using a LAN. These Networks Normally Consist of A
1.6 . LAN Topology Most computers in organizations connect to the Internet using a LAN. These networks normally consist of a backbone which is a common link to all the networks within the organization. This backbone allows users on different network segments to communicate and also allows data into and out of the local network. Figure 7 shows a local area network which contains various segments: LAN A, LAN B, LAN C, LAN D, LAN E and LAN F. These are connected to the local network via the BACKBONE 1.Thus if LAN A talks to LAN E then the data must travel out of LAN A, onto BACKBONE 1, then into LAN C and through onto LAN E. Figure 7. Interconnection of local networks Networks are partitioned from other networks with a bridge, a gateway or a router. A bridge links a network of one type to an identical type, such as Ethernet, 16 or Token Ring to Token Ring. A gateway connects two dissimilar types of networks and routers operate in a similar way to gateways and can either connect to two similar or dissimilar networks. The key operation of a gateway, bridge or router is that they only allow data traffic through that is intended for another network, which is outside the connected network. This filters traffic and stops traffic, not intended for the network, from clogging-up the backbone. Most modern bridges, gateways and routers are intelligent and can automatically determine the topology of the network. Spanning-tree bridges have built-in intelligence and can communicate with other bridges. -

Satellite Communication & Networking
SATELLITE COMMUNICATION & NETWORKING Submitted By- Sanket Gupta NTPC Electronics & Communication National Thermal Power Corporation Raj Kumar Goel Engg. College INDEX 11.. IInnttrroodduuccttiioonn aa.. HHooww DDoo SSaatteelllliitteess WWoorrkk?? bb.. FFaaccttoorrss IInn SSaatteelllliittee Communication 22.. MMaajjoorr PPrroobblleemmss FFoorr SSaatteelllliitteess aa.. AAddvvaannttaaggeess OOff SSaatteelllliitteess Communication b.b. Disadvantages Of Satellites Communication 33.. TTyyppeess OOff SSaatteelllliitteess aa.. GGeeoossttaattiioonnaarryy EEaarrtthh OOrrbbiitt (GEO) bb.. LLooww EEaarrtthh OOrrbbiitt ((LLEEOO)) cc.. MMeeddiiuumm EEaarrtthh OOrrbbiitt ((MMEEOO)) 44.. FFrreeqquueennccyy BBaannddss OOff SSaatteelllliitteess aa.. SSaatteelllliittee SSeerrvviicceess bb.. FFrreeqquueennccyy BBaannddss 55.. TTeerrmmss UUsseedd IInn SSaatteelllliittee Communication 66.. CCoommppoonneennttss OOff SSaatteelllliittee Communication 7.7. Satellite Communication System 88.. SSaatteelllliittee EEaarrtthh SSttaattiioonn Introduction How Do Satellites Work? If two Stations on Earth want to communicate through rraaddiioo bbrrooaaddccaasstt bbuutt aarree ttoooo ffaarr aawwaayy ttoo uussee coconvnvenentitiononalal memeanans,s, ththenen ththesesee ststatatioionsns cacann ususee aa satellite as a relay station for their communicacommunication.tion. One Earth Station sends a transmission to the satellite. This is called an Uplink . ThThee sasateltellitlitee Transponder earthconverts station. the signalThis is calledand sends a Downlink it down.. to the -

Dwdm Topologies
CHAPTER 16 DWDM TOPOLOGIES 16.1 INTRODUCTION Dense wavelength division multiplexing (DWDM) networks are classified into four major topological configurations: DWDM point-to-point with or without add-drop multiplexing network, fully connected mesh network, star network, and DWDM ring network with OADM nodes and a hub. Each topology has its own requirements and, based on the application, different optical components may be involved in the re- spective designs. In addition, there are hybrid network topologies that may consist of stars and/or rings that are interconnected with point-to-point links. For example, the Metropolitan Optical Network project (MONET) is a WDM network developed for and funded by a number of private companies and by U.S. government agencies. It consists of two sub- networks, one located in New Jersey and one in the Washington, D.C./Maryland area; the two are interconnected with a long-distance point-to-point optical link. 16.2 POINT-TO-POINT TOPOLOGY Point-to-point topology is predominantly for long-haul transport that requires ultrahigh speed (10-40 Gb/s), ultrahigh aggregate bandwidth (in the order ofseveral ter- abits per second), high signal integrity, great reliability, and fast path restoration capa- bility. The distance between transmitter and receiver may be several hundred kilome- ters, and the number of amplifiers between the two end points is typically less than 10 (as determined by power loss and signal distortion). Point-to-point with add-drop mul- tiplexing enables the system to drop and add channels along its path. Number of chan- nels, channel spacing, type of fiber, signal modulation method, and component type se- lection are all important parameters in the calculation of the power budget. -

TR 101 984 V1.2.1 (2007-12) Technical Report
ETSI TR 101 984 V1.2.1 (2007-12) Technical Report Satellite Earth Stations and Systems (SES); Broadband Satellite Multimedia (BSM); Services and architectures 2 ETSI TR 101 984 V1.2.1 (2007-12) Reference RTR/SES-00274 Keywords architecture, broadband, IP, multimedia, satellite ETSI 650 Route des Lucioles F-06921 Sophia Antipolis Cedex - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 Important notice Individual copies of the present document can be downloaded from: http://www.etsi.org The present document may be made available in more than one electronic version or in print. In any case of existing or perceived difference in contents between such versions, the reference version is the Portable Document Format (PDF). In case of dispute, the reference shall be the printing on ETSI printers of the PDF version kept on a specific network drive within ETSI Secretariat. Users of the present document should be aware that the document may be subject to revision or change of status. Information on the current status of this and other ETSI documents is available at http://portal.etsi.org/tb/status/status.asp If you find errors in the present document, please send your comment to one of the following services: http://portal.etsi.org/chaircor/ETSI_support.asp Copyright Notification No part may be reproduced except as authorized by written permission. The copyright and the foregoing restriction extend to reproduction in all media. -

Power Characterisation of a Zigbee Wireless Network in a Real Time Monitoring Application
Power Characterisation of a Zigbee Wireless Network in a Real Time Monitoring Application Arrian Prince-Pike A thesis submitted to Auckland University of Technology in fulfilment of the requirements for the degree of Master of Engineering (ME) April 2009 School of Engineering Primary Supervisor: Dr John Collins Acknowledgements In completing this research I received help from a number of people. First I must thank my supervisor Dr John Collins for his support, guidance and advice during the course of this investigation. I must also thank AUT technician Achala Perera who provided me with much of the equipment required for the experimental investigation. Finally, thanks to my friends and family for their support during the course of my research. i Attestation of Authorship ‘I hereby declare that this submission is my own work and that, to the best of my knowledge and belief, it contains no material previously published or written by another person (except where explicitly defined in the acknowledgements), nor material which to a substantial extent has been submitted for the award of any other degree or diploma of a university or other institution of higher learning’ Arrian Prince-Pike April 2009 ii Table of Contents Acknowledgements.....................................................................................................................i Attestation of Authorship...........................................................................................................ii Table of Contents.................................................................................................................... -

Investigation of Wavelength Division Multiplexed Hybrid Ring-Tree-Star
Optik 125 (2014) 6516–6519 Contents lists available at ScienceDirect Optik jo urnal homepage: www.elsevier.de/ijleo Investigation of wavelength division multiplexed hybrid ring-tree-star network topology to enhance the system capacity a a b Simranjit Singh , Raman , R.S. Kaler a Department of Electronics and Communication Engineering, Punjabi University, Patiala, Punjab, 147002, India b Department of Electronics and Communication Engineering, Thapar University, Patiala, Punjab, 147004, India a r a t i b s c t l e i n f o r a c t Article history: In this paper, we have investigated wavelength division multiplexed (WDM) hybrid (ring-tree-star) topol- Received 16 November 2013 ogy. Eight optical add/drop multiplexers (OADMs) are used to make ring structure. The single mode fiber Accepted 19 June 2014 and dispersion compensating fiber and semiconductor optical amplifier (SOA) are employed between each OADM to achieve a maximum. To increase the number of users each OADM node of ring network Keywords: is connected to star and tree network topology which can accommodate more than 2048 users. Various Passive optical network (PON) system parameters (for different channel spacing, different input power signal, different data rates and Rmote node the fiber length) are varied to investigate the system performance in the term of BER and Q factor. Bit error rate © 2014 Elsevier GmbH. All rights reserved. Semiconductor optical amplifier (SOA) Optical add/drop multiplexer (OADM) 1. Introduction Chenwei Wu et al. [11] purposed a tree ring structure with the bit rate 1.25 Gbps at 27 km that protected the network at from Optical networks are the revolution in technology because they either dual or single fiber failure and also crosstalk between deliver the increased bandwidth demanded by the information uplink and downlink in fiber. -

Chapter 6 Medium Access Control Protocols and Local Area Networks
Chapter 6 Medium Access Control Protocols and Local Area Networks Part I: Medium Access Control Part II: Local Area Networks Chapter Overview l Broadcast Networks l Medium Access Control l All information sent to all l To coordinate access to users shared medium l No routing l Data link layer since direct l Shared media transfer of frames l Radio l Local Area Networks l Cellular telephony l High-speed, low-cost l Wireless LANs communications between co-located computers l Copper & Optical l Typically based on l Ethernet LANs broadcast networks l Cable Modem Access l Simple & cheap l Limited number of users Chapter 6 Medium Access Control Protocols and Local Area Networks Part I: Medium Access Control Multiple Access Communications Random Access Scheduling Channelization Delay Performance Chapter 6 Medium Access Control Protocols and Local Area Networks Part II: Local Area Networks Overview of LANs Ethernet Token Ring and FDDI 802.11 Wireless LAN LAN Bridges Chapter 6 Medium Access Control Protocols and Local Area Networks Multiple Access Communications Multiple Access Communications l Shared media basis for broadcast networks l Inexpensive: radio over air; copper or coaxial cable l M users communicate by broadcasting into medium l Key issue: How to share the medium? 3 2 4 1 Shared multiple access medium M 5 … Approaches to Media Sharing Medium sharing techniques Static Dynamic medium channelization access control l Partition medium Scheduling Random access l Dedicated allocation to users l Polling: take turns l Loose l Satellite l Request -

Media Access Control (MAC) (With Some IEEE 802 Standards)
Department of Computer and IT Engineering University of Kurdistan Computer Networks I Media Access Control (MAC) (with some IEEE 802 standards) By: Dr. Alireza Abdollahpouri Media Access Control Multiple access links There is ‘ collision ’ if more than one node sends at the same time only one node can send successfully at a time 2 Media Access Control • When a "collision" occurs, the signals will get distorted and the frame will be lost the link bandwidth is wasted during collision • Question: How to coordinate the access of multiple sending and receiving nodes to the shared link ? • Solution: We need a protocol to determine how nodes share channel Medium Access control (MAC) protocol • The main task of a MAC protocol is to minimize collisions in order to utilize the bandwidth by: - Determining when a node can use the link (medium) - What a node should do when the link is busy - What the node should do when it is involved in collision 3 Ideal Multiple Access Protocol 1. When one node wants to transmit, it can send at rate R bps, where R is the channel rate. 2. When M nodes want to transmit, each can send at average rate R/M (fair) 3. fully decentralized: - No special node to coordinate transmissions - No synchronization of clocks, slots 4. Simple Does not exist!! 4 Three Ways to Share the Media Channel partitioning MAC protocols: • Share channel efficiently and fairly at high load • Inefficient at low load: delay in channel access, 1/N bandwidth allocated even if only 1 active node! “Taking turns” protocols • Eliminates empty slots without