(10) Patent No.: US 8119385 B2
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
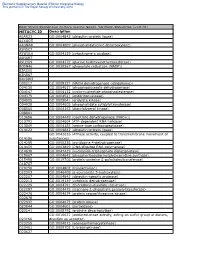
METACYC ID Description A0AR23 GO:0004842 (Ubiquitin-Protein Ligase
Electronic Supplementary Material (ESI) for Integrative Biology This journal is © The Royal Society of Chemistry 2012 Heat Stress Responsive Zostera marina Genes, Southern Population (α=0. -

KO Kidney.Xlsx
Supplemental Table 18: Dietary Impact on the CGL KO Kidney Sulfhydrome DR/AL Accession Molecular Cysteine Spectral Protein Name Number Alternate ID Weight Residues Count Ratio P‐value Ig gamma‐2A chain C region, A allele P01863 (+1) Ighg 36 kDa 10 C 5.952 0.03767 Heterogeneous nuclear ribonucleoprotein M Q9D0E1 (+1) Hnrnpm 78 kDa 6 C 5.000 0.00595 Phospholipase D3 O35405 Pld3 54 kDa 8 C 4.167 0.04761 Ig kappa chain V‐V region L7 (Fragment) P01642 Gm10881 13 kDa 2 C 2.857 0.01232 UPF0160 protein MYG1, mitochondrial Q9JK81 Myg1 43 kDa 7 C 2.333 0.01613 Copper homeostasis protein cutC homolog Q9D8X1 Cutc 29 kDa 7 C 10.333 0.16419 Corticosteroid‐binding globulin Q06770 Serpina6 45 kDa 3 C 10.333 0.16419 28S ribosomal protein S22, mitochondrial Q9CXW2 Mrps22 41 kDa 2 C 7.333 0.3739 Isoform 3 of Agrin A2ASQ1‐3 Agrn 198 kDa 2 C 7.333 0.3739 3‐oxoacyl‐[acyl‐carrier‐protein] synthase, mitochondrial Q9D404 Oxsm 49 kDa 11 C 7.333 0.3739 Cordon‐bleu protein‐like 1 Q3UMF0 (+3)Cobll1 137 kDa 10 C 5.833 0.10658 ADP‐sugar pyrophosphatase Q9JKX6 Nudt5 24 kDa 5 C 4.167 0.15819 Complement C4‐B P01029 C4b 193 kDa 29 C 3.381 0.23959 Protein‐glutamine gamma‐glutamyltransferase 2 P21981 Tgm2 77 kDa 20 C 3.381 0.23959 Isochorismatase domain‐containing protein 1 Q91V64 Isoc1 32 kDa 5 C 3.333 0.10588 Serpin B8 O08800 Serpinb8 42 kDa 11 C 2.903 0.06902 Heterogeneous nuclear ribonucleoprotein A0 Q9CX86 Hnrnpa0 31 kDa 3 C 2.667 0.5461 Proteasome subunit beta type‐8 P28063 Psmb8 30 kDa 5 C 2.583 0.36848 Ig kappa chain V‐V region MOPC 149 P01636 12 kDa 2 C 2.583 0.36848 -

Phospholipid:Diacylglycerol Acyltransferase: an Enzyme That Catalyzes the Acyl-Coa-Independent Formation of Triacylglycerol in Yeast and Plants
Phospholipid:diacylglycerol acyltransferase: An enzyme that catalyzes the acyl-CoA-independent formation of triacylglycerol in yeast and plants Anders Dahlqvist*†‡, Ulf Ståhl†§, Marit Lenman*, Antoni Banas*, Michael Lee*, Line Sandager¶, Hans Ronne§, and Sten Stymne¶ *Scandinavian Biotechnology Research (ScanBi) AB, Herman Ehles Va¨g 2 S-26831 Svaloˆv, Sweden; ¶Department of Plant Breeding Research, Swedish University of Agricultural Sciences, Herman Ehles va¨g 2–4, S-268 31 Svalo¨v, Sweden; and §Department of Plant Biology, Uppsala Genetic Center, Swedish University of Agricultural Sciences, Box 7080, S-750 07 Uppsala, Sweden Edited by Christopher R. Somerville, Carnegie Institution of Washington, Stanford, CA, and approved March 31, 2000 (received for review February 15, 2000) Triacylglycerol (TAG) is known to be synthesized in a reaction that acid) and epoxidated fatty acid (vernolic acid) in TAG in castor uses acyl-CoA as acyl donor and diacylglycerol (DAG) as acceptor, bean (Ricinus communis) and the hawk’s-beard Crepis palaestina, and which is catalyzed by the enzyme acyl-CoA:diacylglycerol respectively. Furthermore, a similar enzyme is shown to be acyltransferase. We have found that some plants and yeast also present in the yeast Saccharomyces cerevisiae, and the gene have an acyl-CoA-independent mechanism for TAG synthesis, encoding this enzyme, YNR008w, is identified. which uses phospholipids as acyl donors and DAG as acceptor. This reaction is catalyzed by an enzyme that we call phospholipid:dia- Materials and Methods cylglycerol acyltransferase, or PDAT. PDAT was characterized in Yeast Strains and Plasmids. The wild-type yeast strains used were microsomal preparations from three different oil seeds: sunflower, either FY1679 (MAT␣ his3-⌬200 leu2-⌬1 trp1-⌬6 ura3-52) (9) or castor bean, and Crepis palaestina. -

Synthesis and Functions of Jasmonates in Maize
plants Review Synthesis and Functions of Jasmonates in Maize Eli J. Borrego and Michael V. Kolomiets * Department of Plant Pathology and Microbiology, Texas A&M University, College Station, TX 77843, USA; [email protected] * Correspondence: [email protected]; Tel.: +1-979-458-4624 Academic Editor: Eve Syrkin Wurtele Received: 29 October 2016; Accepted: 22 November 2016; Published: 29 November 2016 Abstract: Of the over 600 oxylipins present in all plants, the phytohormone jasmonic acid (JA) remains the best understood in terms of its biosynthesis, function and signaling. Much like their eicosanoid analogues in mammalian system, evidence is growing for the role of the other oxylipins in diverse physiological processes. JA serves as the model plant oxylipin species and regulates defense and development. For several decades, the biology of JA has been characterized in a few dicot species, yet the function of JA in monocots has only recently begun to be elucidated. In this work, the synthesis and function of JA in maize is presented from the perspective of oxylipin biology. The maize genes responsible for catalyzing the reactions in the JA biosynthesis are clarified and described. Recent studies into the function of JA in maize defense against insect herbivory, pathogens and its role in growth and development are highlighted. Additionally, a list of JA-responsive genes is presented for use as biological markers for improving future investigations into JA signaling in maize. Keywords: jasmonic acid; maize; lipoxygenase; oxylipins; plant-insect interactions; plant-microbe interactions 1. Importance of Maize as a Crop and a Genetic Model Despite contributing over 50% of the annual calories for humans [1] and 34% of the production for animal feed [2], little is known about fundamental hormone biology in monocot plants compared to greater advances with dicot plants, primarily Arabidopsis. -

June 2009 MONTHLY MEETING : PLEASE PAY YOUR DUES: WHEN? Monday, June 22, 2009 – the Fourth Monday of in Accordance with the By-Laws, Dues, in the the Month
Spore-Addct The Newsletter of the Pikes PeakTime Mycological Society 1974 – 2009 Vol. XXXV ISSUE 3 June 2009 MONTHLY MEETING : PLEASE PAY YOUR DUES: WHEN? Monday, June 22, 2009 – The fourth Monday of In accordance with the By-laws, dues, in the the month. amount of $15.00, are due and payable on or before the April monthly meeting. If you still WHAT TIME? 6:30 pm; the meeting will come to order at have not paid, please pay at the June meeting or 7:00 pm. mail the payment to PPMS, PO Box 39, Colorado Springs, CO 80901-0039. Thanks! WHERE? Pikes Peak National Bank, 2401 W. Colorado Ave. (across from Bancroft Park). Enter at the door on Colorado Ave., just west of the bank door. There you will find stairs and an elevator. You may use either. The FORAY REPORT: room is on the second floor near the head of the stairs. May 30th 2009: Ten of us (including 2 newcomers to WEBSITE: http://www.pikespeakmushrooms.com/ PPMS) gathered at the Red Rocks Safeway parking lot at 8:30 a.m. All had either been contacted by e-mail or PROGRAM: personal phone call. All club forays will be scheduled like this. Our eager forayers found only 6 small morels, A NAMA Educational Program: 2 L.B.Ms, and some dubious polypors. We did come “Guide to the Major Genera of Gilled Mushrooms: The across 6 Calypso orchids (unaccompanied by morels). Light Spored Mushrooms I: Pluteaceae, Pleurotaceae, It was a beautiful day on Rampart Range Road. Rain Entolomataceae, Marasmiaceae and Others” and warmer temperatures have brought out city This program covers the best edible and most mushrooms galore. -

Peroxisomal Fatty Acid Beta-Oxidation in Relation to the Accumulation Of
Peroxisomal fatty acid beta-oxidation in relation to the accumulation of very long chain fatty acids in cultured skin fibroblasts from patients with Zellweger syndrome and other peroxisomal disorders. R J Wanders, … , A W Schram, J M Tager J Clin Invest. 1987;80(6):1778-1783. https://doi.org/10.1172/JCI113271. Research Article The peroxisomal oxidation of the long chain fatty acid palmitate (C16:0) and the very long chain fatty acids lignocerate (C24:0) and cerotate (C26:0) was studied in freshly prepared homogenates of cultured skin fibroblasts from control individuals and patients with peroxisomal disorders. The peroxisomal oxidation of the fatty acids is almost completely dependent on the addition of ATP, coenzyme A (CoA), Mg2+ and NAD+. However, the dependency of the oxidation of palmitate on the concentration of the cofactors differs markedly from that of the oxidation of lignocerate and cerotate. The peroxisomal oxidation of all three fatty acid substrates is markedly deficient in fibroblasts from patients with the Zellweger syndrome, the neonatal form of adrenoleukodystrophy and the infantile form of Refsum disease, in accordance with the deficiency of peroxisomes in these patients. In fibroblasts from patients with X-linked adrenoleukodystrophy the peroxisomal oxidation of lignocerate and cerotate is impaired, but not that of palmitate. Competition experiments indicate that in fibroblasts, as in rat liver, distinct enzyme systems are responsible for the oxidation of palmitate on the one hand and lignocerate and cerotate on the other hand. Fractionation studies indicate that in rat liver activation of cerotate and lignocerate to cerotoyl-CoA and lignoceroyl-CoA, respectively, occurs in two subcellular fractions, the endoplasmic reticulum and the peroxisomes but not in the mitochondria. -

Supplementary Table 1
Supplemental Table 1. GO terms for the Flavonoid biosynthesis pathway and genes identified through pathway-level co-expression analysis. The ranking is sorted for descending counts within the pathway. The last two columns give the number of genes within or outside the pathway that are annotated with the term listed in the second column. GO id GO term Genes Genes within outside pathway pathway GO:0008372 cellular component unknown 13 28 GO:0016207 4-coumarate-CoA ligase activity 12 0 GO:0008152 metabolism 8 7 GO:0019350 teichoic acid biosynthesis 8 0 GO:0009234 menaquinone biosynthesis 8 0 GO:0009698 phenylpropanoid metabolism 7 0 GO:0009813 flavonoid biosynthesis 7 0 GO:0008299 isoprenoid biosynthesis 6 0 GO:0009507 chloroplast 5 24 GO:0009411 response to UV 4 0 GO:0016706 "oxidoreductase activity, acting on paired donors, with 4 0 incorporation or reduction of molecular oxygen, 2- oxoglutarate as one donor, and incorporation of one atom each of oxygen into both donors" GO:0009058 biosynthesis 3 2 GO:0009699 phenylpropanoid biosynthesis 3 1 GO:0008415 acyltransferase activity 3 1 GO:0004315 3-oxoacyl-[acyl-carrier protein] synthase activity 3 0 GO:0006633 fatty acid biosynthesis 3 0 GO:0005739 mitochondrion 2 7 GO:0005783 endoplasmic reticulum 2 1 GO:0009695 jasmonic acid biosynthesis 2 1 GO:0009611 response to wounding 2 1 GO:0005506 iron ion binding 2 1 GO:0016216 isopenicillin-N synthase activity 2 0 GO:0005777 peroxisome 2 0 GO:0045430 chalcone isomerase activity 2 0 GO:0009705 vacuolar membrane (sensu Magnoliophyta) 2 0 GO:0004321 -

Enzymatic Encoding Methods for Efficient Synthesis Of
(19) TZZ__T (11) EP 1 957 644 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C12N 15/10 (2006.01) C12Q 1/68 (2006.01) 01.12.2010 Bulletin 2010/48 C40B 40/06 (2006.01) C40B 50/06 (2006.01) (21) Application number: 06818144.5 (86) International application number: PCT/DK2006/000685 (22) Date of filing: 01.12.2006 (87) International publication number: WO 2007/062664 (07.06.2007 Gazette 2007/23) (54) ENZYMATIC ENCODING METHODS FOR EFFICIENT SYNTHESIS OF LARGE LIBRARIES ENZYMVERMITTELNDE KODIERUNGSMETHODEN FÜR EINE EFFIZIENTE SYNTHESE VON GROSSEN BIBLIOTHEKEN PROCEDES DE CODAGE ENZYMATIQUE DESTINES A LA SYNTHESE EFFICACE DE BIBLIOTHEQUES IMPORTANTES (84) Designated Contracting States: • GOLDBECH, Anne AT BE BG CH CY CZ DE DK EE ES FI FR GB GR DK-2200 Copenhagen N (DK) HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI • DE LEON, Daen SK TR DK-2300 Copenhagen S (DK) Designated Extension States: • KALDOR, Ditte Kievsmose AL BA HR MK RS DK-2880 Bagsvaerd (DK) • SLØK, Frank Abilgaard (30) Priority: 01.12.2005 DK 200501704 DK-3450 Allerød (DK) 02.12.2005 US 741490 P • HUSEMOEN, Birgitte Nystrup DK-2500 Valby (DK) (43) Date of publication of application: • DOLBERG, Johannes 20.08.2008 Bulletin 2008/34 DK-1674 Copenhagen V (DK) • JENSEN, Kim Birkebæk (73) Proprietor: Nuevolution A/S DK-2610 Rødovre (DK) 2100 Copenhagen 0 (DK) • PETERSEN, Lene DK-2100 Copenhagen Ø (DK) (72) Inventors: • NØRREGAARD-MADSEN, Mads • FRANCH, Thomas DK-3460 Birkerød (DK) DK-3070 Snekkersten (DK) • GODSKESEN, -

Properties of Chlorophyllase from Capsicum Annuum L. Fruits
Properties of Chlorophyllase from Capsicum annuum L. Fruits Dámaso Hornero-Méndez and Marí a Isabel Mínguez-Mosquera* Departamento de Biotecnologia de Alimentos, Instituto de la Grasa (CSIC), Av. Padre Garcia Tejero, 4, 41012-Sevilla, SPAIN. Fax: +34-954691262. E-mail: [email protected] * Author for correspondence and reprint requests Z. Naturforsch. 56c, 1015-1021 (2001); received June 27/August 6 , 2001 Chlorophyll, Chlorophyllase, Capsicum annuum The in vitro properties of semi-purified chlorophyllase (chlorophyll-chlorophyllido hy drolase, EC 3.1.1.14) from Capsicum annuum fruits have been studied. The enzyme showed an optimum of activity at pH 8.5 and 50 °C. Substrate specificity was studied for chlorophyll (Chi) a, Chi b, pheophytin (Phe) a and Phe b, with K m values of 10.70, 4.04, 2.67 and 6.37 ^im respectively. Substrate inhibition was found for Phe b at concentrations higher than 5 ^m. Chlorophyllase action on Chi a ’ and Chi b' was also studied but no hydrolysis was observed, suggesting that the mechanism of action depends on the configuration at C-132 in the chloro phyll molecule, with the enzyme acting only on compounds with R132 stereochemistry. The effect of various metals (Mg2+, Hg2+, Cu2+, Zn2+, Co , Fe2+ and Fe3+) was also investigated, and a general inhibitory effect was found, this being more marked for Hg2+ and Fe2+. Func tional groups such as -SH and -S-S- seemed to participate in the formation of the enzyme- substrate complex. Chelating ion and the carbonyl group at C3 appeared to be important in substrate recognition by the enzyme. -

Type of the Paper (Article
Supplementary Material A Proteomics Study on the Mechanism of Nutmeg-induced Hepatotoxicity Wei Xia 1, †, Zhipeng Cao 1, †, Xiaoyu Zhang 1 and Lina Gao 1,* 1 School of Forensic Medicine, China Medical University, Shenyang 110122, P. R. China; lessen- [email protected] (W.X.); [email protected] (Z.C.); [email protected] (X.Z.) † The authors contributed equally to this work. * Correspondence: [email protected] Figure S1. Table S1. Peptide fraction separation liquid chromatography elution gradient table. Time (min) Flow rate (mL/min) Mobile phase A (%) Mobile phase B (%) 0 1 97 3 10 1 95 5 30 1 80 20 48 1 60 40 50 1 50 50 53 1 30 70 54 1 0 100 1 Table 2. Liquid chromatography elution gradient table. Time (min) Flow rate (nL/min) Mobile phase A (%) Mobile phase B (%) 0 600 94 6 2 600 83 17 82 600 60 40 84 600 50 50 85 600 45 55 90 600 0 100 Table S3. The analysis parameter of Proteome Discoverer 2.2. Item Value Type of Quantification Reporter Quantification (TMT) Enzyme Trypsin Max.Missed Cleavage Sites 2 Precursor Mass Tolerance 10 ppm Fragment Mass Tolerance 0.02 Da Dynamic Modification Oxidation/+15.995 Da (M) and TMT /+229.163 Da (K,Y) N-Terminal Modification Acetyl/+42.011 Da (N-Terminal) and TMT /+229.163 Da (N-Terminal) Static Modification Carbamidomethyl/+57.021 Da (C) 2 Table S4. The DEPs between the low-dose group and the control group. Protein Gene Fold Change P value Trend mRNA H2-K1 0.380 0.010 down Glutamine synthetase 0.426 0.022 down Annexin Anxa6 0.447 0.032 down mRNA H2-D1 0.467 0.002 down Ribokinase Rbks 0.487 0.000 -

Structure of Pigment Metabolic Pathways and Their Contributions to White Tepal Color Formation of Chinese Narcissus Tazetta Var
International Journal of Molecular Sciences Article Structure of Pigment Metabolic Pathways and Their Contributions to White Tepal Color Formation of Chinese Narcissus tazetta var. chinensis cv Jinzhanyintai Yujun Ren † ID , Jingwen Yang †, Bingguo Lu, Yaping Jiang, Haiyang Chen, Yuwei Hong, Binghua Wu and Ying Miao * Center for Molecular Cell and Systems Biology, Fujian Provincial Key Laboratory of Haixia Applied Plant Systems Biology, College of Life Sciences, Fujian Agriculture and Forestry University, Fuzhou 350002, China; [email protected] (Y.R.); [email protected] (J.Y.); [email protected] (B.L.); [email protected] (Y.J.); [email protected] (H.C.); [email protected] (Y.H.); [email protected] (B.W.) * Correspondence: [email protected]; Tel.:/Fax: +86-591-8639-2987 † These authors contributed equally to this work. Received: 7 August 2017; Accepted: 4 September 2017; Published: 8 September 2017 Abstract: Chinese narcissus (Narcissus tazetta var. chinensis) is one of the ten traditional flowers in China and a famous bulb flower in the world flower market. However, only white color tepals are formed in mature flowers of the cultivated varieties, which constrains their applicable occasions. Unfortunately, for lack of genome information of narcissus species, the explanation of tepal color formation of Chinese narcissus is still not clear. Concerning no genome information, the application of transcriptome profile to dissect biological phenomena in plants was reported to be effective. As known, pigments are metabolites of related metabolic pathways, which dominantly decide flower color. In this study, transcriptome profile and pigment metabolite analysis methods were used in the most widely cultivated Chinese narcissus “Jinzhanyintai” to discover the structure of pigment metabolic pathways and their contributions to white tepal color formation during flower development and pigmentation processes. -

Expression of Genes Encoding Acetyl-Coa Carboxylase, Biotin Synthase, and Acetyl-Coa Generating Enzymes in Arabidopsis Thaliana Jinshan Ke Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1997 Expression of genes encoding acetyl-CoA carboxylase, biotin synthase, and acetyl-CoA generating enzymes in Arabidopsis thaliana Jinshan Ke Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Botany Commons, and the Molecular Biology Commons Recommended Citation Ke, Jinshan, "Expression of genes encoding acetyl-CoA carboxylase, biotin synthase, and acetyl-CoA generating enzymes in Arabidopsis thaliana " (1997). Retrospective Theses and Dissertations. 11996. https://lib.dr.iastate.edu/rtd/11996 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly fi"om the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter fece, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely aflfect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion.