Memory Hierarchy and Multiprocessors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evolution of Microprocessor Performance
EvolutionEvolution ofof MicroprocessorMicroprocessor PerformancePerformance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static & dynamic branch predication. Even with these improvements, the restriction of issuing a single instruction per cycle still limits the ideal CPI = 1 Multiple Issue (CPI <1) Multi-cycle Pipelined T = I x CPI x C (single issue) Superscalar/VLIW/SMT Original (2002) Intel Predictions 1 GHz ? 15 GHz to ???? GHz IPC CPI > 10 1.1-10 0.5 - 1.1 .35 - .5 (?) Source: John P. Chen, Intel Labs We next examine the two approaches to achieve a CPI < 1 by issuing multiple instructions per cycle: 4th Edition: Chapter 2.6-2.8 (3rd Edition: Chapter 3.6, 3.7, 4.3 • Superscalar CPUs • Very Long Instruction Word (VLIW) CPUs. Single-issue Processor = Scalar Processor EECC551 - Shaaban Instructions Per Cycle (IPC) = 1/CPI EECC551 - Shaaban #1 lec # 6 Fall 2007 10-2-2007 ParallelismParallelism inin MicroprocessorMicroprocessor VLSIVLSI GenerationsGenerations Bit-level parallelism Instruction-level Thread-level (?) (TLP) 100,000,000 (ILP) Multiple micro-operations Superscalar /VLIW per cycle Simultaneous Single-issue CPI <1 u Multithreading SMT: (multi-cycle non-pipelined) Pipelined e.g. Intel’s Hyper-threading 10,000,000 CPI =1 u uuu u u Chip-Multiprocessors (CMPs) u Not Pipelined R10000 e.g IBM Power 4, 5 CPI >> 1 uuuuuuu u AMD Athlon64 X2 u uuuuu Intel Pentium D u uuuuuuuu u u 1,000,000 u uu uPentium u u uu i80386 u i80286 -

Intel® Core™ Microarchitecture • Wrap Up
EW N IntelIntel®® CoreCore™™ MicroarchitectureMicroarchitecture MarchMarch 8,8, 20062006 Stephen L. Smith Bob Valentine Vice President Architect Digital Enterprise Group Intel Architecture Group Agenda • Multi-core Update and New Microarchitecture Level Set • New Intel® Core™ Microarchitecture • Wrap Up 2 Intel Multi-core Roadmap – Updates since Fall IDF 3 Ramping Multi-core Everywhere 4 All products and dates are preliminary and subject to change without notice. Refresher: What is Multi-Core? Two or more independent execution cores in the same processor Specific implementations will vary over time - driven by product implementation and manufacturing efficiencies • Best mix of product architecture and volume mfg capabilities – Architecture: Shared Caches vs. Independent Caches – Mfg capabilities: volume packaging technology • Designed to deliver performance, OEM and end user experience Single die (Monolithic) based processor Multi-Chip Processor Example: 90nm Pentium® D Example: Intel Core™ Duo Example: 65nm Pentium D Processor (Smithfield) Processor (Yonah) Processor (Presler) Core0 Core1 Core0 Core1 Core0 Core1 Front Side Bus Front Side Bus Front Side Bus *Not representative of actual die photos or relative size 5 Intel® Core™ Micro-architecture *Not representative of actual die photo or relative size 6 Intel Multi-core Roadmap 7 Intel Multi-core Roadmap 8 Intel® Core™ Microarchitecture Based Platforms Platform 2006 20072007 Caneland Platform (2007) MP Servers Tigerton (QC) (2007) Bensley Platform (Q2’06)/ Glidewell Platform (Q2’06) ) DP Servers/ Woodcrest (Q3’06) DP Workstation Clovertown (QC) (Q1’07) Kaylo Platform (Q3’06)/ Wyloway Platform (Q3 ’06) UP Servers/ Conroe (Q3’06) UP Workstation Kentsfield (QC) (Q1’07) Bridge Creek Platform (Mid’06) Desktop -Home Conroe (Q3’06) Kentsfield (QC) (Q1’07) Desktop -Office Averill Platform (Mid’06) Conroe (Q3’06) Mobile Client Napa Platform (Q1’06) Merom (2H’06) All products and dates are preliminary 9 Note: only Intel® Core™ microarchitecture QC refers to Quad-Core and subject to change without notice. -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

Energy Per Instruction Trends in Intel® Microprocessors
Energy per Instruction Trends in Intel® Microprocessors Ed Grochowski, Murali Annavaram Microarchitecture Research Lab, Intel Corporation 2200 Mission College Blvd, Santa Clara, CA 95054 [email protected], [email protected] Abstract where throughput performance is the primary objective. In order to deliver high throughput performance within a Energy per Instruction (EPI) is a measure of the amount fixed power budget, a microprocessor must achieve low of energy expended by a microprocessor for each EPI. instruction that the microprocessor executes. In this It is important to note that MIPS/watt and EPI do not paper, we present an overview of EPI, explain the consider the amount of time (latency) needed to process factors that affect a microprocessor’s EPI, and derive a an instruction from start to finish. Other metrics such as MIPS 2/watt (related to energy•delay) and MIPS 3/watt historical comparison of the trends in EPI over multiple 2 generations of Intel microprocessors. We show that the (related to energy•delay ) assign increasing importance recent Intel® Pentium® M and Intel® Core™ Duo to the time required to process instructions, and are thus microprocessors achieve significantly lower EPI than used in environments in which latency performance is what would be expected from a continuation of historical the primary objective. trends. 2. What Determines EPI? 1. Introduction Consider a capacitor that is charged and discharged With the power consumption of recent desktop by a CMOS inverter as shown in Figure 1. microprocessors having reached 130 watts, power has emerged at the forefront of challenges facing the V microprocessor designer [1, 2]. -

5 Microprocessors
Color profile: Disabled Composite Default screen BaseTech / Mike Meyers’ CompTIA A+ Guide to Managing and Troubleshooting PCs / Mike Meyers / 380-8 / Chapter 5 5 Microprocessors “MEGAHERTZ: This is a really, really big hertz.” —DAVE BARRY In this chapter, you will learn or all practical purposes, the terms microprocessor and central processing how to Funit (CPU) mean the same thing: it’s that big chip inside your computer ■ Identify the core components of a that many people often describe as the brain of the system. You know that CPU CPU makers name their microprocessors in a fashion similar to the automobile ■ Describe the relationship of CPUs and memory industry: CPU names get a make and a model, such as Intel Core i7 or AMD ■ Explain the varieties of modern Phenom II X4. But what’s happening inside the CPU to make it able to do the CPUs amazing things asked of it every time you step up to the keyboard? ■ Install and upgrade CPUs 124 P:\010Comp\BaseTech\380-8\ch05.vp Friday, December 18, 2009 4:59:24 PM Color profile: Disabled Composite Default screen BaseTech / Mike Meyers’ CompTIA A+ Guide to Managing and Troubleshooting PCs / Mike Meyers / 380-8 / Chapter 5 Historical/Conceptual ■ CPU Core Components Although the computer might seem to act quite intelligently, comparing the CPU to a human brain hugely overstates its capabilities. A CPU functions more like a very powerful calculator than like a brain—but, oh, what a cal- culator! Today’s CPUs add, subtract, multiply, divide, and move billions of numbers per second. -

The Intel X86 Microarchitectures Map Version 2.2
The Intel x86 Microarchitectures Map Version 2.2 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • New instructions: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -
Intel Mobile CPU Roadmap
Intel Mobile CPU Roadmap 2004 2005 2006 2008 2009 2010 System Price 2007 TDP System CPU Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 2H Q4 Price Core2 Extreme Nehalem/Core 2 Clarksfield QX Quad-Core Quad core Boundary 2.xxGHz/ Calpella Extreme 4 cores/2 cores Penryn QC 8MB/PCIe 45W Extreme Boundary QX9300 (2.53GHz/ Montevina 4cores/PCIe x16 (55W) QC XE 12MB/FSB1066) $1000 Penryn 6M Merom 4M Core2 Extreme Core2 Quad Santa Rosa X9000(2.8GHz/ Penryn 6M Penryn QC Clarksfield 6MB/FSB800) 2.xxGHz/ X/Q Quad-Core Dual core 8MB/PCIe -45W Performance2 Extreme Yonah/Core 2 X7800 (2.6GHz/ X7900 (2.8GHz/ Q9100 (2.26GHz/ Calpella 2 cores/1 core Boundary 4MB/FSB800) 4MB/FSB800) X9100(3.06GHz/ 12MB/FSB1066) (55W) QC P2 Boundary Merom 4M Santa Rosa 6MB/FSB1066) Refresh $750 Montevina Napa Napa Refresh Merom 4M 2.xxGHz/ Clarksfield Quad-Core Dothan 533 Santa Rosa ?MB/PCIe 2.13GHz(770) 2.33GHz(T7600) Q9000 (2GHz/ Calpella Performance1 Yonah Dual-Core2M Core2 Duo 6MB/FSB1066) QC P1 T9500 (2.6GHz/ $34x Performance 2.16GHz(T2600) 2.33GHz(T2700) 6MB/FSB800) Penryn 6M Montevina 2.1GHz(765) T7700 (2.4GHz/ T7800 (2.6GHz/ T9600 (2.8GHz/ T9800 (2.93GHz/ T9900 (3.06GHz/ T Dual-Core 2.26GHz(780) 4MB/FSB800) 4MB/FSB800) 6MB/FSB1066) 6MB/FSB1066) 6MB/FSB1066) 35W Performance2 Core2 Duo (45W) DC P2 Core2 Duo $500 2GHz(760) 2GHz(T2500) Penryn 6M 35W Dual-Core Dothan 2.16GHz(T7400) 2GHz(755) Core Duo T9400 (2.53GHz/ T9550 (2.66GHz/ T9600 (2.8GHz/ Performance1 6MB/FSB1066) 6MB/FSB1066) 6MB/FSB1066) DC P1 2.13GHz(770) 2.16GHz(T2600) T9300 (2.5GHz/ -

Tuning IBM System X Servers for Performance
Front cover Tuning IBM System x Servers for Performance Identify and eliminate performance bottlenecks in key subsystems Expert knowledge from inside the IBM performance labs Covers Windows, Linux, and VMware ESX David Watts Alexandre Chabrol Phillip Dundas Dustin Fredrickson Marius Kalmantas Mario Marroquin Rajeev Puri Jose Rodriguez Ruibal David Zheng ibm.com/redbooks International Technical Support Organization Tuning IBM System x Servers for Performance August 2009 SG24-5287-05 Note: Before using this information and the product it supports, read the information in “Notices” on page xvii. Sixth Edition (August 2009) This edition applies to IBM System x servers running Windows Server 2008, Windows Server 2003, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, and VMware ESX. © Copyright International Business Machines Corporation 1998, 2000, 2002, 2004, 2007, 2009. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Contents Notices . xvii Trademarks . xviii Foreword . xxi Preface . xxiii The team who wrote this book . xxiv Become a published author . xxix Comments welcome. xxix Part 1. Introduction . 1 Chapter 1. Introduction to this book . 3 1.1 Operating an efficient server - four phases . 4 1.2 Performance tuning guidelines . 5 1.3 The System x Performance Lab . 5 1.4 IBM Center for Microsoft Technologies . 7 1.5 Linux Technology Center . 7 1.6 IBM Client Benchmark Centers . 8 1.7 Understanding the organization of this book . 10 Chapter 2. Understanding server types . 13 2.1 Server scalability . 14 2.2 Authentication services . 15 2.2.1 Windows Server 2008 Active Directory domain controllers . -

Specialty Processors ECE570 Winter 2008
Specialty Processors ECE570 Winter 2008 Steve Meliza Matt Shuman Table of Contents Introduction..............................................................................................................................................3 Intel Core Processors..............................................................................................................................3 Instruction Execution Details:..........................................................................................................4 Memory:..........................................................................................................................................4 Unique Attributes and Design Choices:..........................................................................................5 GPU Processors......................................................................................................................................5 Instruction Execution Details:..........................................................................................................6 Memory/Architecture Details:..........................................................................................................7 Unique Attributes and Design Choices:..........................................................................................8 STI Cell Processors...............................................................................................................................10 Instruction Execution Details:........................................................................................................11 -

Intel's Core 2 Family
Intel’s Core 2 family - TOCK lines II Nehalem to Haswell Dezső Sima Vers. 3.11 August 2018 Contents • 1. Introduction • 2. The Core 2 line • 3. The Nehalem line • 4. The Sandy Bridge line • 5. The Haswell line • 6. The Skylake line • 7. The Kaby Lake line • 8. The Kaby Lake Refresh line • 9. The Coffee Lake line • 10. The Cannon Lake line 3. The Nehalem line 3.1 Introduction to the 1. generation Nehalem line • (Bloomfield) • 3.2 Major innovations of the 1. gen. Nehalem line 3.3 Major innovations of the 2. gen. Nehalem line • (Lynnfield) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) (1) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) Developed at Hillsboro, Oregon, at the site where the Pentium 4 was designed. Experiences with HT Nehalem became a multithreaded design. The design effort took about five years and required thousands of engineers (Ronak Singhal, lead architect of Nehalem) [37]. The 1. gen. Nehalem line targets DP servers, yet its first implementation appeared in the desktop segment (Core i7-9xx (Bloomfield)) 4C in 11/2008 1. gen. 2. gen. 3. gen. 4. gen. 5. gen. West- Core 2 Penryn Nehalem Sandy Ivy Haswell Broad- mere Bridge Bridge well New New New New New New New New Microarch. Process Microarchi. Microarch. Process Microarch. Process Process 45 nm 65 nm 45 nm 32 nm 32 nm 22 nm 22 nm 14 nm TOCK TICK TOCK TICK TOCK TICK TOCK TICK (2006) (2007) (2008) (2010) (2011) (2012) (2013) (2014) Figure : Intel’s Tick-Tock development model (Based on [1]) * 3.1 Introduction to the 1. -
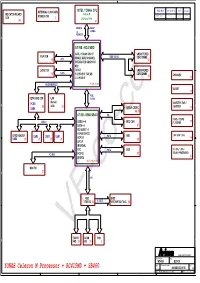
YONAH Celeron M Processor + RC415MD + SB460 Custom 40GAB1230-B100 B Date:Wednesday, June 21, 2006 Sheet : 139Of 5 4 3 2 1 a B C D E
5 4 3 2 1 EXTERNAL CLOCK GEN. INTEL YONAH CPU PCI BUS GNT#/REQ# INTR IDSEL INDICATOR BOARD Celeron M RTM865T-300 MINI PCI 0 C/D AD25 CON 2 uFCPGA 479 Pin 24 4, 5 4X DATA AGTL+ 2X 533MHz ADDRESS D D ATI NB - RC415MD AGTL+ YONAH CPU I/F UNBUFFERED VGA CON SINGLE DDR2 CHANNEL DDRII 400/533 DDR2 DIMM0 15 CRT 12 INTEGRATED GRAPHICS M22 LVDS CON TVOUT UNBUFFERED 15 LVDS 1 X2 PCIE I/F FOR SB DDR2 DIMM1 13 CHARGER 4 X1 PCIE I/F 32 PCIE INTERFACE 7, 8, 9, 10, 11 VCORE 36 PCIE NEW CARD CON LAN X2/(X4) Marvell PCIE0 3.3VSTBY / 5VS / C 26 8038 23 1.8VSTBY C USB6 AZALIA CODEC 33 28, 29 ATI SB - SB600/SB460 HD 1.5VS / 1.05VS USB 2.0 USB2.0---8 MDC CON /1.2VS-NB 35 SATA---4 27 HD AUDIO 1.0 ATA 66/100/133 CARD READER HDD 1.8V / 0.9V/ 1.2VS USB3 USB2 USB1 PATA 34 USB4 25 21 21 21 ACPI 1.1 22 LPC I/F INTERNAL RTC PATA ODD 3V / 3VS / 1.8VS / 3VLAN / POWERGOOD PCI BUS PCI/PCI 22 BRIDGE 32 16, 17, 18, 19, 20 MINI PCI B 27 B LPC KBC BIOS IT8510G 30 X-BUS SST39VF080-70-4C 30 TOUCH SCAN FAN A VF-co-ccPAD 24 KB 24 3 A ARIMA COMPUTER CORP. Project Name : Title : W340UI BLOCK Size : Document Number : Rev : YONAH Celeron M Processor + RC415MD + SB460 Custom 40GAB1230-B100 B Date:Wednesday, June 21, 2006 Sheet : 139of 5 4 3 2 1 A B C D E 3VS L32 0.1UF/16V 0.1UF/16V 0.1UF/16V 1 2 BEAD/120_600mA 1 1 1 1 1 1 32-7D0603-120G C393 3VS 10UF/10V C731 C727 C730 C729 C728 2 2 2 2 2 2 L29 31-481069-900G 0.1UF/16V 0.1UF/16V 1 2 3VS 4 1 1 4 L31 31-461049-940G U19 BEAD/120_600mA 1 2 C365 C363 1 1 45 0.1UF/16V 10UF/10V BEAD/120_600mA 2 2 35 VDDCPU 39 VDDSRC VDDA C392 C390 32 38 -

Importance of New Apple Computers
Importance of New Apple Computers Lorrin R. Garson OPCUG & PATACS December 12, 2020 © 2020 Lorrin R. Garson Rapidly Changing Scene •Some information will have changed within the past few days and even hours •Expect new developments over the next several months 2 A Short Prologue: Computer Systems I’ve Worked On •Alpha Microsystems* (late 1970s ➜ 1990s) •Various Unix systems (1980s ➜ 2000s) Active hypertext •Microsoft Windows (~1985 ➜ 2013) links •Apple Computers (~1986 ➜ 2020) * Major similarities to DEC PDP/11 3 Not me in disguise! No emotional attachment to any computer system 4 Short History of Apple CPUs •1976 Apple I & II; MOS 6502 •1977 Apple III; Synertek 6502B •1985 Macintosh; Motorola 68000 ✓ 68020, 68030 and 68030 •1994 Macintosh; PowerPC 601 ✓ 603, 604, G3, G4 and G5 5 History of Apple Hardware (CPUs) (cont.) •2006 Macintosh; Intel x86 ✓ Yonah, Core Penryn, Nehalem, Westmere, Sandy Bridge, Ivy Bridge, Haswell, Broadwell, Skylake, Kaby Lake, Coffee Lake, Ice Lake, Tiger Lake ✓ 2009 Apple dropped support for PowerPC •2020 Mac Computers; Apple Silicon 6 Terminology •“Apple Silicon” refers to Apple’s proprietary ARM- based hardware •Apple Silicon aka “System* on a Chip” aka “SoC” •“M1” name of the chip implementing Apple Silicon** * Not silicon on a chip ** The M1 is a “superset” of the iPhone A14 chip 7 ARM vs. x86 •ARM uses RISC architecture (Reduced Instruction Set Computing) ✓ Fugaku supercomputer (world’s fastest computer) •x86 uses CISC architecture (Complex Instruction Set Computing) ✓ Intel-based computers •ARM focuses