Supporting Tulu Language Written in the Kannada Script §1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Updated Proposal to Encode Tulu-Tigalari Script in Unicode
Updated proposal to encode Tulu-Tigalari script in Unicode Vaishnavi Murthy Kodipady Yerkadithaya [ [email protected] ] Vinodh Rajan [ [email protected] ] 04/03/2021 Document History & Background Documents : (This document replaces L2/17-378) L2/11-120R Preliminary proposal for encoding the Tulu script in the SMP of the UCS – Michael Everson L2/16-241 Preliminary proposal to encode Tigalari script – Vaishnavi Murthy K Y L2/16-342 Recommendations to UTC #149 November 2016 on Script Proposals – Deborah Anderson, Ken Whistler, Roozbeh Pournader, Andrew Glass and Laurentiu Iancu L2/17-182 Comments on encoding the Tigalari script – Srinidhi and Sridatta L2/18-175 Replies to Script Ad Hoc Recommendations (L2/16-342) and Comments (L2/17-182) on Tigalari proposal (L2/16-241) – Vaishnavi Murthy K Y L2/17-378 Preliminary proposal to encode Tigalari script – Vaishnavi Murthy K Y, Vinodh Rajan L2/17-411 Letter in support of preliminary proposal to encode Tigalari – Guru Prasad (Has withdrawn support. This letter needs to be disregarded.) L2/17-422 Letter to Vaishnavi Murthy in support of Tigalari encoding proposal – A. V. Nagasampige L2/18-039 Recommendations to UTC #154 January 2018 on Script Proposals – Deborah Anderson, Ken Whistler, Roozbeh Pournader, Lisa Moore, Liang Hai, and Richard Cook PROPOSAL TO ENCODE TIGALARI SCRIPT IN UNICODE 2 A note on recent updates : −−−Tigalari Script is renamed Tulu-Tigalari script. The reason for the same is discussed under section 1.1 (pp. 4-5) of this paper & elaborately in the supplementary paper Tulu Language and Tulu-Tigalari script (pp. 5-13). −−−This proposal attempts to harmonize the use of the Tulu-Tigalari script for Tulu, Sanskrit and Kannada languages for archival use. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

A Script Independent Approach for Handwritten Bilingual Kannada and Telugu Digits Recognition
IJMI International Journal of Machine Intelligence ISSN: 0975–2927 & E-ISSN: 0975–9166, Volume 3, Issue 3, 2011, pp-155-159 Available online at http://www.bioinfo.in/contents.php?id=31 A SCRIPT INDEPENDENT APPROACH FOR HANDWRITTEN BILINGUAL KANNADA AND TELUGU DIGITS RECOGNITION DHANDRA B.V.1, GURURAJ MUKARAMBI1, MALLIKARJUN HANGARGE2 1Department of P.G. Studies and Research in Computer Science Gulbarga University, Gulbarga, Karnataka. 2Department of Computer Science, Karnatak Arts, Science and Commerce College Bidar, Karnataka. *Corresponding author. E-mail: [email protected],[email protected],[email protected] Received: September 29, 2011; Accepted: November 03, 2011 Abstract- In this paper, handwritten Kannada and Telugu digits recognition system is proposed based on zone features. The digit image is divided into 64 zones. For each zone, pixel density is computed. The KNN and SVM classifiers are employed to classify the Kannada and Telugu handwritten digits independently and achieved average recognition accuracy of 95.50%, 96.22% and 99.83%, 99.80% respectively. For bilingual digit recognition the KNN and SVM classifiers are used and achieved average recognition accuracy of 96.18%, 97.81% respectively. Keywords- OCR, Zone Features, KNN, SVM 1. Introduction recognition of isolated handwritten Kannada numerals Recent advances in Computer technology, made every and have reported the recognition accuracy of 90.50%. organization to implement the automatic processing Drawback of this procedure is that, it is not free from systems for its activities. For example, automatic thinning. U. Pal et al. [11] have proposed zoning and recognition of vehicle numbers, postal zip codes for directional chain code features and considered a feature sorting the mails, ID numbers, processing of bank vector of length 100 for handwritten Kannada numeral cheques etc. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Unit 2 Distribution of Indian Tribes, Groups and Sub-Groups: Causes of Variations
Tribal Cosmogenies UNIT 2 DISTRIBUTION OF INDIAN TRIBES, GROUPS AND SUB-GROUPS: CAUSES OF VARIATIONS Structure 2.0 Objectives 2.1 Introduction 2.2 Distribution of Indian tribes: groups and sub-groups 2.2.1 Geographical 2.2.2 Linguistic 2.2.3 Racial 2.2.4 Size 2.2.5 Economy or subsistence pattern 2.2.6 Degree of incorporation into the Hindu society 2.3 Causes of variations 2.3.1 Migration 2.3.2 Acculturation and assimilation. 2.3.3 Geography or the physical environment 2.4 Let us sum up 2.5 Activity 2.6 References and further reading 2.7 Glossary 2.8 Answers to questions 2.0 OBJECTIVES After having read this Unit, you will be able to: x get a panoramic view of the Indian tribes; x understand the principles upon which their classification is based; and x map their distribution on the basis of their geographical location, language, physical attributes, economy and social structure. 2.1 INTRODUCTION We have had a general outline about the tribes of India in the preceding Unit (Course 4-Block 1- Unit 1). In this present Unit we will deal with distribution of the tribes of India in detail. Structurally this Unit is divided into two main sections. In this first section of the Unit we will discuss the distribution pattern of Indian tribes and how they are classified into different groups and sub-groups based on various criteria. 24 These criteria are based on their geographical location, language, physical Migrant Tribes / Nomads attributes, economy and the degree of incorporation into the Hindu society. -
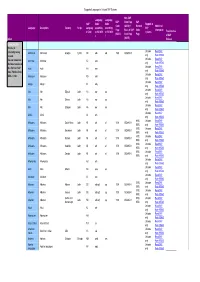
Supported Languages in Unicode SAP Systems Index Language
Supported Languages in Unicode SAP Systems Non-SAP Language Language SAP Code Page SAP SAP Code Code Support in Code (ASCII) = Blended Additional Language Description Country Script Languag according according SAP Page Basis of SAP Code Information e Code to ISO 639- to ISO 639- systems Translated as (ASCII) Code Page Page 2 1 of SAP Index (ASCII) Release Download Info: AThis list is Unicode Read SAP constantly being Abkhazian Abkhazian Georgia Cyrillic AB abk ab 1500 ISO8859-5 revised. only Note 895560 Unicode Read SAP You can download Achinese Achinese AC ace the latest version of only Note 895560 Unicode Read SAP this file from SAP Acoli Acoli AH ach Note 73606 or from only Note 895560 Unicode Read SAP SDN -> /i18n Adangme Adangme AD ada only Note 895560 Unicode Read SAP Adygei Adygei A1 ady only Note 895560 Unicode Read SAP Afar Afar Djibouti Latin AA aar aa only Note 895560 Unicode Read SAP Afar Afar Eritrea Latin AA aar aa only Note 895560 Unicode Read SAP Afar Afar Ethiopia Latin AA aar aa only Note 895560 Unicode Read SAP Afrihili Afrihili AI afh only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans South Africa Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Botswana Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Malawi Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Namibia Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Zambia -

WO 2010/131256 Al
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date 18 November 2010 (18.11.2010) WO 2010/131256 Al (51) International Patent Classification: AO, AT, AU, AZ, BA, BB, BG, BH, BR, BW, BY, BZ, G06F 3/01 (2006.01) CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, (21) International Application Number: HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, PCT/IN20 10/000052 KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, (22) International Filing Date: ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, 29 January 2010 (29.01 .2010) NO, NZ, OM, PE, PG, PH, PL, PT, RO, RS, RU, SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, (25) Filing Language: English TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (26) Publication Language: English (84) Designated States (unless otherwise indicated, for every (30) Priority Data: kind of regional protection available): ARIPO (BW, GH, 974/DEL/2009 13 May 2009 (13.05.2009) IN GM, KE, LS, MW, MZ, NA, SD, SL, SZ, TZ, UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, MD, RU, TJ, (72) Inventor; and TM), European (AT, BE, BG, CH, CY, CZ, DE, DK, EE, (71) Applicant : MEHRA, Rajesh [IN/IN]; H-39, Tagore ES, FI, FR, GB, GR, HR, HU, IE, IS, IT, LT, LU, LV, Path, Bani Park, Jaipur 302 0 16, Rajasthan (IN). -

Tugboat, Volume 19 (1998), No. 2 115 an Overview of Indic Fonts For
TUGboat, Volume 19 (1998), No. 2 115 the Indo-Aryan and Dravidian language families of Fonts India. Such uniformity in phonetics is reflected in orthography, which in turn enables all scripts to be transliterated through a single scheme. This unifor- An Overview of Indic Fonts for TEX mity has subsequently been reflected in the translit- Anshuman Pandey eration schemes of the Indic language/script pack- ages. 1 Introduction Most packages have their own transliteration Many scholars and students in the humanities have scheme, but these schemes are essentially variations on a single scheme, differing merely in the coding preferred TEX over other “word processors” or doc- ument preparation systems because of the ease TEX of a few vowel, nasal, and retroflex letters. Most provides them in typesetting non-Roman scripts, the of these packages accept input in one of the two availability of TEX fonts of interest to them, and the primary 7-bit transliteration schemes— ITRANS or ability TEX has in producing well-structured docu- Velthuis—or a derivative of one of them. There ments. is also an 8-bit format called CS/CSX which a few However, this is not the case amongst Indol- of these packages support. CS/CSX is described in ogists. The lack of Indic fonts for TEXandthe further detail in Section 3. perceived difficulty of typesetting them have often 2 The Fonts and Packages turned Indologists away from using TEX. Little do they realize that TEXisthe foremost tool for de- Figure 1 shows examples of the various fonts de- veloping Indic language/script documents. -

Comparison of Different Orthographies for Machine
Comparison of Different Orthographies for Machine Translation of Under-Resourced Dravidian Languages Bharathi Raja Chakravarthi Insight Centre for Data Analytics, Data Science Institute, National University of Ireland Galway, IDA Business Park, Lower Dangan, Galway, Ireland https://bharathichezhiyan.github.io/bharathiraja/ [email protected] Mihael Arcan Insight Centre for Data Analytics, Data Science Institute, National University of Ireland Galway, IDA Business Park, Lower Dangan, Galway, Ireland [email protected] John P. McCrae Insight Centre for Data Analytics, Data Science Institute, National University of Ireland Galway, IDA Business Park, Lower Dangan, Galway, Ireland https://john.mccr.ae/ [email protected] Abstract Under-resourced languages are a significant challenge for statistical approaches to machine translation, and recently it has been shown that the usage of training data from closely-related languages can improve machine translation quality of these languages. While languages within the same language family share many properties, many under-resourced languages are written in their own native script, which makes taking advantage of these language similarities difficult. In this paper, we propose to alleviate the problem of different scripts by transcribing the native script into common representation i.e. the Latin script or the International Phonetic Alphabet (IPA). In particular, we compare the difference between coarse-grained transliteration to the Latin script and fine-grained IPA transliteration. We performed experiments on the language pairs English-Tamil, English-Telugu, and English-Kannada translation task. Our results show improvements in terms of the BLEU, METEOR and chrF scores from transliteration and we find that the transliteration into the Latin script outperforms the fine-grained IPA transcription.