Parallel Programming 2021-01-26
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
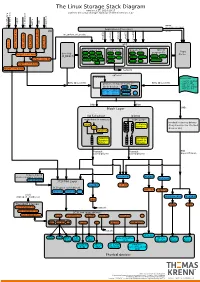
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18]. -

Bcache (Kernel-Modul Seit 3.11 ...)
DFN-Forum 2016: RZ Storage für die Virtualisierung Konrad Meier, Martin Ullrich, Dirk von Suchodoletz 31.05.2016 – Rechenzentrum Universität Rostock Ausgangslage . Praktiker-Beitrag, deshalb Fokus auf Problemlage und Ergebnisse / Erkenntnisse - Beschaffung neuen Speichersystems bereits in Ausschreibung - Übergangslösung für Problem für ca. halbes Jahr gesucht - Abt. eScience für Strat.entwicklung, bwCloud, HPC - Interessanter „Case“ im RZ-Geschäft, da Storage inzwischen sehr zentral - Storage im Übergang zu SSD/Flash aber All-Flash noch nicht bezahlbar - Flash attraktiver Beschleuniger/Cache - Bisher keine Erfahrung (wenig explizite Erfolgsberichte, jedoch viele Hinweise auf deutliche Verbesserungen), Probleme jedoch so groß, dass Risiko eines Scheiterns akzeptabel (Abschätzung Umbauaufwand etc.) 04.07.16 9. DFN-Forum in Rostock 2 Damalige Ausgangssituation . Zwei ESX-Cluster im Einsatz - Virtualisierung 1 Altsystem, klassiches FC-Setup - Virtualisierung 2 modernes System hoher Performance als zukünftiges Modell . Storage: Klass. Massen- speicher (nicht virt.-optimiert) . Für einfache Migration der VMs Einsatz von NFSv3 . Realisiert über Linux-Fileserver - Fibrechannel-Infrastruktur - LUNs mit Multipath-Anbindung als Blockdevices mit ext4 04.07.16 9. DFN-Forum in Rostock 3 Problem: Schlechte Storage Performance . Mehrfache Ausfälle des NFS-Kopfes mit unklaren Ursachen - Hohe Latenzen seit einigen Wochen - Last sollte aufgrund Semesterpause eher gering sein - Keine bekannten Veränderungen im Lastprofil der vorhandenen VMs . Aufschaukeleffekte - NFS „staut“ lange Queues auf (async Konfiguration) - Bei Crashes, je nach Gast-OS ziemlich kaputte FS - Linux-Gäste setzen bei langen Latenzen (virt.) Blockdevice ro, NTFS toleranter - Ungeschickte Konfigurationen in VMs verschlimmern Zustand . Ergebnisse von fio (iotop, htop ebenso betrachtet) lat(usec): 250=26.96%, 500=72.49%, 750=0.29%, 1000=0.07% lat(msec): 2=0.09%, 4=0.08%, 10=0.01%, 20=0.01%, 50=0.01% lat(msec): 100=0.01%, 250=0.01%, 500=0.01%, 750=0.01%, 2000=0.01% lat(msec): >=2000=0.01% 04.07.16 9. -

Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, Nicex Lab, NUDT; Yuxing Peng, NUDT
MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices Lujia Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, NiceX Lab, NUDT; Yuxing Peng, NUDT https://www.usenix.org/conference/atc21/presentation/yin This paper is included in the Proceedings of the 2021 USENIX Annual Technical Conference. July 14–16, 2021 978-1-939133-23-6 Open access to the Proceedings of the 2021 USENIX Annual Technical Conference is sponsored by USENIX. MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices Lujia Yin Li Wang Yiming Zhang [email protected] [email protected] [email protected] (Corresponding) NUDT Didi Chuxing NiceX Lab, NUDT Yuxing Peng [email protected] NUDT Abstract replicas on SSDs and replicates backup replicas on HDDs; and SSHD [28] integrates a small SSD inside a large HDD DM-cache is a component of the device mapper of Linux of which the SSD acts as a cache. kernel, which has been widely used to map SSDs and HDDs As the demand of HDD-SSD hybrid storage increases, onto higher-level virtual block devices that take fast SSDs as Linux kernel has supported users to combine HDDs and a cache for slow HDDs to achieve high I/O performance at SSDs to jointly provide virtual block storage service. DM- low monetary cost. While enjoying the benefit of persistent cache [5] is a component of the device mapper [4] in the caching where SSDs accelerate normal I/O without affecting kernel, which has been widely used in industry to map SSDs durability, the current design of DM-cache suffers from and HDDs onto higher-level virtual block devices that take long crash recovery times (at the scale of hours) and low fast SSDs as a cache for slow HDDs. -

Think ALL Distros Offer the Best Linux Devsecops Environment?
Marc Staimer, Dragon Slayor Consulting WHITE PAPER Think All Distros Offer the Best Linux DevSecOps What You’re Not Being Told About Environment? Database as a Service (DBaaS) Think Again! WHITE PAPER • Think Again! Think All Distros Provide the Best Linux DevSecOps Environment? Think Again! Introduction DevOps is changing. Developing code with after the fact bolt-on security is dangerously flawed. When that bolt-on fails to correct exploitable code vulnerabilities, it puts the entire organization at risk. Security has been generally an afterthought for many doing DevOps. It was often assumed the IT organization’s systemic multiple layers of security measures and appliances would protect any new code from malware or breaches. And besides, developing code with security built in, adds tasks and steps to development and testing time. More tasks and steps delay time-to-market. Multi-tenant clouds have radically changed the market. Any vulnerability in a world with increasing cyber-attacks, can put millions of user’s data at risk. Those legacy DevOps attitudes are unsound. They are potentially quite costly in the current environment. Consider that nearly every developed and most developing countries have enacted laws and regulation protecting personally identifiable information or PII1. PII is incredibly valuable to cybercriminals. Stealing PII enables them to commit many cybercrimes including the cybertheft of identities, finances, intellectual property, admin privileges, and much more. PII can also be sold on the web. Those PII laws and regulations are meant to force IT organizations to protect PII. Non-compliance of these laws and regulations often carry punitive financial penalties. -

Dm-Cache.Pdf
DM-Cache Marc Skinner Principal Solutions Architect Twin Cities Users Group :: Q1/2016 Why Cache? ● Spinning disks are slow! ● Solid state disks (SSD) are fast!! ● Non-Volatile Memory Express (NVMe) devices are insane!!! Why not? ● Hybrid drives make 5900rpm drives act like 7200rpm drives with very small on board SSD cache ● Hmm, talk to FAST and move to SLOW? FAST SLOW Linux Caching Options ● DM-Cache ● Oldest and most stable. Developed in 2006 by IBM research group, and merged into Linux kernel tree in version 3.9. Uses the device-mapper framework to cache a slower device ● FlashCache ● Kernel module inspired by dm-cache and developed/maintained by Facebook. Also uses the device-mapper framework. ● EnhanceIO, RapidCache ● Both variations of FlashCache ● BCache ● Newest option and does not rely on device-mapper framework DM-Cache Modes ● write-through ● Red Hat default ● Write requests are not returned until the data reaches the origin and the cache device ● write-back ● Writes go only to the cache device ● pass-through ● Used to by pass the cache, used if cache is corrupt DM-Cache Setup ● Enable discards first # vi /etc/lvm/lvm.conf issue_discards = 1 # dracut -f # sync # reboot DM-Cache Setup ● Create PV, VG and LV with Cache # pvcreate /dev/md2 (raid 10 - 6 x 250gb SSD) # pvcreate /dev/md3 (raid 10 - 6 x 2tb SATA) # vgcreate vg_iscsi /dev/md3 /dev/md2 # lvcreate -l 100%FREE -n lv_sata vg_iscsi /dev/md3 # lvcreate -L 5G -n lv_cache_meta vg_iscsi /dev/md2 # lvcreate -L 650G -n lv_cache vg_iscsi /dev/md2 # lvconvert --type cache-pool -

06 使用bcache为ceph OSD加速的具体实践 by 花瑞
杉岩官方微信 Practices for accelerating Ceph OSD with bcache 花瑞 [email protected] www.szsandstone.com Outline n Caching choices for Ceph n Practices for accelerating OSD with bcache n Bcache introduction n Challenge for production ready n Next step www.szsandstone.com 01 Caching choices for Ceph n Ceph Cache Tiering n Complexity in operation and maintenance, too much strategy n Data migration between cache pool and base pool cost too much n Coarse-grained objects promotion, slower performance in some workloads n Longer IO path when cache miss Ceph cache tiering n OSD Cache SSD n Simple to deploy, simple replacement strategy HDD n It is more worthy to accelerate OSD metadata and journal n Fine-grained sensitivity to active and inactive data OSD Cache www.szsandstone.com 02 Caching choices for Ceph n Linux block caching choices Bcache Flashcache EnhanceIO Dm-cache • First committed to • Support by facebook • Derived from • First committed to kernel-3.10 Flashcache kernel-3.9 • Using kernel device- • Good performance mapper • Normal performance • Using kernel device- mapper • SSD-friendly design • Normal performance • Easy maintain • Normal performance • Pooling SSD resource, • Easy develop, debug • Poor features thin-provisioning • No more developed • Rich features and maintained www.szsandstone.com 03 Why bcache n Feature comparison Bcache Flashcache/EnhanceIO Management SSD pooled, thin-provisioning, easy to add SSD(partition) binding to backing HDD, non backing HDD flexible Hit ratio Extent-based/B+tree Index, high hit ratio Block-based/hash -

Reliable Storage for HA, DR, Clouds and Containers Philipp Reisner, CEO LINBIT LINBIT - the Company Behind It
Reliable Storage for HA, DR, Clouds and Containers Philipp Reisner, CEO LINBIT LINBIT - the company behind it COMPANY OVERVIEW TECHNOLOGY OVERVIEW • Developer of DRBD • 100% founder owned • Offices in Europe and US • Team of 30 highly experienced Linux experts • Partner in Japan REFERENCES 25 Linux Storage Gems LVM, RAID, SSD cache tiers, deduplication, targets & initiators Linux's LVM logical volume snapshot logical volume Volume Group physical volume physical volume physical volume 25 Linux's LVM • based on device mapper • original objects • PVs, VGs, LVs, snapshots • LVs can scatter over PVs in multiple segments • thinlv • thinpools = LVs • thin LVs live in thinpools • multiple snapshots became efficient! 25 Linux's LVM thin-LV thin-LV thin-sLV LV snapshot thinpool VG PV PV PV 25 Linux's RAID RAID1 • original MD code • mdadm command A1 A1 • Raid Levels: 0,1,4,5,6,10 A2 A2 • Now available in LVM as well A3 A3 A4 A4 • device mapper interface for MD code • do not call it ‘dmraid’; that is software for hardware fake-raid • lvcreate --type raid6 --size 100G VG_name 25 SSD cache for HDD • dm-cache • device mapper module • accessible via LVM tools • bcache • generic Linux block device • slightly ahead in the performance game 25 Linux’s DeDupe • Virtual Data Optimizer (VDO) since RHEL 7.5 • Red hat acquired Permabit and is GPLing VDO • Linux upstreaming is in preparation • in-line data deduplication • kernel part is a device mapper module • indexing service runs in user-space • async or synchronous writeback • Recommended to be used below LVM 25 Linux’s targets & initiators • Open-ISCSI initiator IO-requests • Ietd, STGT, SCST Initiator Target data/completion • mostly historical • LIO • iSCSI, iSER, SRP, FC, FCoE • SCSI pass through, block IO, file IO, user-specific-IO • NVMe-OF • target & initiator 25 ZFS on Linux • Ubuntu eco-system only • has its own • logic volume manager (zVols) • thin provisioning • RAID (RAIDz) • caching for SSDs (ZIL, SLOG) • and a file system! 25 Put in simplest form DRBD – think of it as .. -

Oracle Linux and the Unbreakable Enterprise Kernel, Including Premier
ORACLE DATA SHEET Oracle Linux The Oracle Linux operating system is engineered for open cloud infrastructure. It delivers leading performance, scalability, reliability and security for enterprise SaaS and PaaS workloads as well as traditional enterprise applications. Oracle Linux Support offers access to award-winning Oracle support resources and Linux support specialists, zero-downtime updates using Ksplice, additional management tools such as Oracle Enterprise Manager and lifetime support, all at a low cost. Unlike many other commercial Linux distributions, Oracle Linux is easy to download and completely free to use, distribute and update. KEY FEATURES Latest Linux Innovations • Free to use, free to distribute, free to Oracle Linux comes with a choice of two kernels, the Unbreakable Enterprise Kernel update (UEK), which is installed and enabled by default, and the Red Hat Compatible Kernel. • Zero-downtime kernel, hypervisor UEK tracks the latest Linux kernel releases, supplying more innovation than other and user space updates with Ksplice commercial Linux kernels while providing binary compatibility with applications certified • Comprehensive kernel and to run on Red Hat Enterprise Linux. UEK is designed for enterprise workloads requiring application tracing with DTrace stability, scalability and performance, such as Oracle Database. • Linux management and high availability included at no additional Oracle Linux delivers advanced features for supporting and optimizing the latest charge for Oracle Linux Support enterprise hardware and software. For example: customers • Optimized for Oracle, including Ksplice Zero Downtime Updates – Available to Oracle Linux Premier Support Oracle Database and Oracle customers, Ksplice technology updates the kernels, hypervisors and critical user Applications space libraries without requiring a reboot or interruption. -

Smart Prefetch
Smart Prefetch User Guide Issue 02 Date 2021-03-30 HUAWEI TECHNOLOGIES CO., LTD. Copyright © Huawei Technologies Co., Ltd. 2021. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without prior written consent of Huawei Technologies Co., Ltd. Trademarks and Permissions and other Huawei trademarks are trademarks of Huawei Technologies Co., Ltd. All other trademarks and trade names mentioned in this document are the property of their respective holders. Notice The purchased products, services and features are stipulated by the contract made between Huawei and the customer. All or part of the products, services and features described in this document may not be within the purchase scope or the usage scope. Unless otherwise specified in the contract, all statements, information, and recommendations in this document are provided "AS IS" without warranties, guarantees or representations of any kind, either express or implied. The information in this document is subject to change without notice. Every effort has been made in the preparation of this document to ensure accuracy of the contents, but all statements, information, and recommendations in this document do not constitute a warranty of any kind, express or implied. Issue 02 (2021-03-30) Copyright © Huawei Technologies Co., Ltd. i Smart Prefetch User Guide Contents Contents 1 Introduction.............................................................................................................................. 1 2 Environment Preparations.....................................................................................................3 -

Linux Kernel User Documentation V4.20.0
usepackagefontspec setsansfontDejaVu Sans setromanfontDejaVu Serif setmonofontDejaVu Sans Mono Linux Kernel User Documentation v4.20.0 The kernel development community 1 16, 2019 Contents 1 Linux kernel release 4.x <http://kernel.org/> 3 2 The kernel’s command-line parameters 9 3 Linux allocated devices (4.x+ version) 109 4 L1TF - L1 Terminal Fault 171 5 Reporting bugs 181 6 Security bugs 185 7 Bug hunting 187 8 Bisecting a bug 193 9 Tainted kernels 195 10 Ramoops oops/panic logger 197 11 Dynamic debug 201 12 Explaining the dreaded “No init found.” boot hang message 207 13 Rules on how to access information in sysfs 209 14 Using the initial RAM disk (initrd) 213 15 Control Group v2 219 16 Linux Serial Console 245 17 Linux Braille Console 247 18 Parport 249 19 RAID arrays 253 20 Kernel module signing facility 263 21 Linux Magic System Request Key Hacks 267 i 22 Unicode support 273 23 Software cursor for VGA 277 24 Kernel Support for miscellaneous (your favourite) Binary Formats v1.1 279 25 Mono(tm) Binary Kernel Support for Linux 283 26 Java(tm) Binary Kernel Support for Linux v1.03 285 27 Reliability, Availability and Serviceability 293 28 A block layer cache (bcache) 309 29 ext4 General Information 319 30 Power Management 327 31 Thunderbolt 349 32 Linux Security Module Usage 353 33 Memory Management 369 ii Linux Kernel User Documentation, v4.20.0 The following is a collection of user-oriented documents that have been added to the kernel over time. There is, as yet, little overall order or organization here — this material was not written to be a single, coherent document! With luck things will improve quickly over time.