Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, Nicex Lab, NUDT; Yuxing Peng, NUDT
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Linux Kernel Module Programming Guide
The Linux Kernel Module Programming Guide Peter Jay Salzman Michael Burian Ori Pomerantz Copyright © 2001 Peter Jay Salzman 2007−05−18 ver 2.6.4 The Linux Kernel Module Programming Guide is a free book; you may reproduce and/or modify it under the terms of the Open Software License, version 1.1. You can obtain a copy of this license at http://opensource.org/licenses/osl.php. This book is distributed in the hope it will be useful, but without any warranty, without even the implied warranty of merchantability or fitness for a particular purpose. The author encourages wide distribution of this book for personal or commercial use, provided the above copyright notice remains intact and the method adheres to the provisions of the Open Software License. In summary, you may copy and distribute this book free of charge or for a profit. No explicit permission is required from the author for reproduction of this book in any medium, physical or electronic. Derivative works and translations of this document must be placed under the Open Software License, and the original copyright notice must remain intact. If you have contributed new material to this book, you must make the material and source code available for your revisions. Please make revisions and updates available directly to the document maintainer, Peter Jay Salzman <[email protected]>. This will allow for the merging of updates and provide consistent revisions to the Linux community. If you publish or distribute this book commercially, donations, royalties, and/or printed copies are greatly appreciated by the author and the Linux Documentation Project (LDP). -

Studying the Real World Today's Topics
Studying the real world Today's topics Free and open source software (FOSS) What is it, who uses it, history Making the most of other people's software Learning from, using, and contributing Learning about your own system Using tools to understand software without source Free and open source software Access to source code Free = freedom to use, modify, copy Some potential benefits Can build for different platforms and needs Development driven by community Different perspectives and ideas More people looking at the code for bugs/security issues Structure Volunteers, sponsored by companies Generally anyone can propose ideas and submit code Different structures in charge of what features/code gets in Free and open source software Tons of FOSS out there Nearly everything on myth Desktop applications (Firefox, Chromium, LibreOffice) Programming tools (compilers, libraries, IDEs) Servers (Apache web server, MySQL) Many companies contribute to FOSS Android core Apple Darwin Microsoft .NET A brief history of FOSS 1960s: Software distributed with hardware Source included, users could fix bugs 1970s: Start of software licensing 1974: Software is copyrightable 1975: First license for UNIX sold 1980s: Popularity of closed-source software Software valued independent of hardware Richard Stallman Started the free software movement (1983) The GNU project GNU = GNU's Not Unix An operating system with unix-like interface GNU General Public License Free software: users have access to source, can modify and redistribute Must share modifications under same -

Android (Operating System) 1 Android (Operating System)
Android (operating system) 1 Android (operating system) Android Home screen displayed by Samsung Nexus S with Google running Android 2.3 "Gingerbread" Company / developer Google Inc., Open Handset Alliance [1] Programmed in C (core), C++ (some third-party libraries), Java (UI) Working state Current [2] Source model Free and open source software (3.0 is currently in closed development) Initial release 21 October 2008 Latest stable release Tablets: [3] 3.0.1 (Honeycomb) Phones: [3] 2.3.3 (Gingerbread) / 24 February 2011 [4] Supported platforms ARM, MIPS, Power, x86 Kernel type Monolithic, modified Linux kernel Default user interface Graphical [5] License Apache 2.0, Linux kernel patches are under GPL v2 Official website [www.android.com www.android.com] Android is a software stack for mobile devices that includes an operating system, middleware and key applications.[6] [7] Google Inc. purchased the initial developer of the software, Android Inc., in 2005.[8] Android's mobile operating system is based on a modified version of the Linux kernel. Google and other members of the Open Handset Alliance collaborated on Android's development and release.[9] [10] The Android Open Source Project (AOSP) is tasked with the maintenance and further development of Android.[11] The Android operating system is the world's best-selling Smartphone platform.[12] [13] Android has a large community of developers writing applications ("apps") that extend the functionality of the devices. There are currently over 150,000 apps available for Android.[14] [15] Android Market is the online app store run by Google, though apps can also be downloaded from third-party sites. -

Android Operating System
Software Engineering ISSN: 2229-4007 & ISSN: 2229-4015, Volume 3, Issue 1, 2012, pp.-10-13. Available online at http://www.bioinfo.in/contents.php?id=76 ANDROID OPERATING SYSTEM NIMODIA C. AND DESHMUKH H.R. Babasaheb Naik College of Engineering, Pusad, MS, India. *Corresponding Author: Email- [email protected], [email protected] Received: February 21, 2012; Accepted: March 15, 2012 Abstract- Android is a software stack for mobile devices that includes an operating system, middleware and key applications. Android, an open source mobile device platform based on the Linux operating system. It has application Framework,enhanced graphics, integrated web browser, relational database, media support, LibWebCore web browser, wide variety of connectivity and much more applications. Android relies on Linux version 2.6 for core system services such as security, memory management, process management, network stack, and driver model. Architecture of Android consist of Applications. Linux kernel, libraries, application framework, Android Runtime. All applications are written using the Java programming language. Android mobile phone platform is going to be more secure than Apple’s iPhone or any other device in the long run. Keywords- 3G, Dalvik Virtual Machine, EGPRS, LiMo, Open Handset Alliance, SQLite, WCDMA/HSUPA Citation: Nimodia C. and Deshmukh H.R. (2012) Android Operating System. Software Engineering, ISSN: 2229-4007 & ISSN: 2229-4015, Volume 3, Issue 1, pp.-10-13. Copyright: Copyright©2012 Nimodia C. and Deshmukh H.R. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. -

Introduction to Linux Kernel Driver Programming
IntroductionIntroduction toto LinuxLinux kernelkernel driverdriver programmingprogramming Introduction to Linux kernel driver programming The Linux kernel device model Authors and license ● Authors – Michael Opdenacker ([email protected]) Founder of Bootlin, kernel and embedded Linux engineering company https://bootlin.com/company/staff/michael-opdenacker ● License – Creative Commons Attribution – Share Alike 4.0 https://creativecommons.org/licenses/by-sa/4.0/ – Document sources: https://github.com/e-ale/Slides Need for a device model ● For the same device, need to use the same device driver on multiple CPU architectures (x86, ARM…), even though the hardware controllers are different. ● Need for a single driver to support multiple devices of the same kind. ● This requires a clean organization of the code, with the device drivers separated from the controller drivers, the hardware description separated from the drivers themselves, etc. Driver: between bus infrastructure and framework In Linux, a driver is always interfacing with: ● a framework that allows the driver to expose the hardware features in a generic way. ● a bus infrastructure, part of the device model, to detect/communicate with the hardware. Let’s focus on the bus infrastructure for now Device model data structures The device model is organized around three main data structures: ● The struct bus_type structure, which represent one type of bus (USB, PCI, I2C, etc.) ● The struct device_driver structure, which represents one driver capable of handling certain devices on a certain bus. ● The struct device structure, which represents one device connected to a bus The kernel uses inheritance to create more specialized versions of struct device_driver and struct device for each bus subsystem. -

History and Evolution of the Android OS
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Springer - Publisher Connector CHAPTER 1 History and Evolution of the Android OS I’m going to destroy Android, because it’s a stolen product. I’m willing to go thermonuclear war on this. —Steve Jobs, Apple Inc. Android, Inc. started with a clear mission by its creators. According to Andy Rubin, one of Android’s founders, Android Inc. was to develop “smarter mobile devices that are more aware of its owner’s location and preferences.” Rubin further stated, “If people are smart, that information starts getting aggregated into consumer products.” The year was 2003 and the location was Palo Alto, California. This was the year Android was born. While Android, Inc. started operations secretly, today the entire world knows about Android. It is no secret that Android is an operating system (OS) for modern day smartphones, tablets, and soon-to-be laptops, but what exactly does that mean? What did Android used to look like? How has it gotten where it is today? All of these questions and more will be answered in this brief chapter. Origins Android first appeared on the technology radar in 2005 when Google, the multibillion- dollar technology company, purchased Android, Inc. At the time, not much was known about Android and what Google intended on doing with it. Information was sparse until 2007, when Google announced the world’s first truly open platform for mobile devices. The First Distribution of Android On November 5, 2007, a press release from the Open Handset Alliance set the stage for the future of the Android platform. -

Linux Kernel and Driver Development Training Slides
Linux Kernel and Driver Development Training Linux Kernel and Driver Development Training © Copyright 2004-2021, Bootlin. Creative Commons BY-SA 3.0 license. Latest update: October 9, 2021. Document updates and sources: https://bootlin.com/doc/training/linux-kernel Corrections, suggestions, contributions and translations are welcome! embedded Linux and kernel engineering Send them to [email protected] - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/470 Rights to copy © Copyright 2004-2021, Bootlin License: Creative Commons Attribution - Share Alike 3.0 https://creativecommons.org/licenses/by-sa/3.0/legalcode You are free: I to copy, distribute, display, and perform the work I to make derivative works I to make commercial use of the work Under the following conditions: I Attribution. You must give the original author credit. I Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. I For any reuse or distribution, you must make clear to others the license terms of this work. I Any of these conditions can be waived if you get permission from the copyright holder. Your fair use and other rights are in no way affected by the above. Document sources: https://github.com/bootlin/training-materials/ - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/470 Hyperlinks in the document There are many hyperlinks in the document I Regular hyperlinks: https://kernel.org/ I Kernel documentation links: dev-tools/kasan I Links to kernel source files and directories: drivers/input/ include/linux/fb.h I Links to the declarations, definitions and instances of kernel symbols (functions, types, data, structures): platform_get_irq() GFP_KERNEL struct file_operations - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/470 Company at a glance I Engineering company created in 2004, named ”Free Electrons” until Feb. -

Filesystem Considerations for Embedded Devices ELC2015 03/25/15
Filesystem considerations for embedded devices ELC2015 03/25/15 Tristan Lelong Senior embedded software engineer Filesystem considerations ABSTRACT The goal of this presentation is to answer a question asked by several customers: which filesystem should you use within your embedded design’s eMMC/SDCard? These storage devices use a standard block interface, compatible with traditional filesystems, but constraints are not those of desktop PC environments. EXT2/3/4, BTRFS, F2FS are the first of many solutions which come to mind, but how do they all compare? Typical queries include performance, longevity, tools availability, support, and power loss robustness. This presentation will not dive into implementation details but will instead summarize provided answers with the help of various figures and meaningful test results. 2 TABLE OF CONTENTS 1. Introduction 2. Block devices 3. Available filesystems 4. Performances 5. Tools 6. Reliability 7. Conclusion Filesystem considerations ABOUT THE AUTHOR • Tristan Lelong • Embedded software engineer @ Adeneo Embedded • French, living in the Pacific northwest • Embedded software, free software, and Linux kernel enthusiast. 4 Introduction Filesystem considerations Introduction INTRODUCTION More and more embedded designs rely on smart memory chips rather than bare NAND or NOR. This presentation will start by describing: • Some context to help understand the differences between NAND and MMC • Some typical requirements found in embedded devices designs • Potential filesystems to use on MMC devices 6 Filesystem considerations Introduction INTRODUCTION Focus will then move to block filesystems. How they are supported, what feature do they advertise. To help understand how they compare, we will present some benchmarks and comparisons regarding: • Tools • Reliability • Performances 7 Block devices Filesystem considerations Block devices MMC, EMMC, SD CARD Vocabulary: • MMC: MultiMediaCard is a memory card unveiled in 1997 by SanDisk and Siemens based on NAND flash memory. -

DM-Relay - Safe Laptop Mode Via Linux Device Mapper
' $ DM-Relay - Safe Laptop Mode via Linux Device Mapper Study Thesis by cand. inform. Fabian Franz at the Faculty of Informatics Supervisor: Prof. Dr. Frank Bellosa Supervising Research Assistant: Dipl.-Inform. Konrad Miller Day of completion: 04/05/2010 &KIT – Universitat¨ des Landes Baden-Wurttemberg¨ und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu % I hereby declare that this thesis is my own original work which I created without illegitimate help by others, that I have not used any other sources or resources than the ones indicated and that due acknowledgment is given where reference is made to the work of others. Karlsruhe, April 5th, 2010 Contents Deutsche Zusammenfassung xi 1 Introduction 1 1.1 Problem Definition . .1 1.2 Objectives . .1 1.3 Methodology . .1 1.4 Contribution . .2 1.5 Thesis Outline . .2 2 Background 3 2.1 Problems of Disk Power Management . .3 2.2 State of the Art . .4 2.3 Summary of this chapter . .8 3 Analysis 9 3.1 Pro and Contra . .9 3.2 A new approach . 13 3.3 Analysis of Proposal . 15 3.4 Summary of this chapter . 17 4 Design 19 4.1 Common problems . 19 4.2 System-Design . 21 4.3 Summary of this chapter . 21 5 Implementation of a dm-module for the Linux kernel 23 5.1 System-Architecture . 24 5.2 Log suitable for Flash-Storage . 28 5.3 Using dm-relay in practice . 31 5.4 Summary of this chapter . 31 vi Contents 6 Evaluation 33 6.1 Methodology . 33 6.2 Benchmarking setup . -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
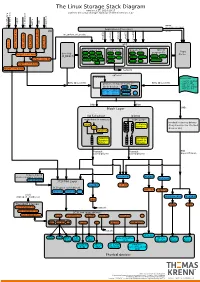
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18].