Effective Cache Apportioning for Performance Isolation Under
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Linux 2.4 Kernel's Startup Procedure
The Linux 2.4 Kernel’s Startup Procedure William Gatliff 1. Overview This paper describes the Linux 2.4 kernel’s startup process, from the moment the kernel gets control of the host hardware until the kernel is ready to run user processes. Along the way, it covers the programming environment Linux expects at boot time, how peripherals are initialized, and how Linux knows what to do next. 2. The Big Picture Figure 1 is a function call diagram that describes the kernel’s startup procedure. As it shows, kernel initialization proceeds through a number of distinct phases, starting with basic hardware initialization and ending with the kernel’s launching of /bin/init and other user programs. The dashed line in the figure shows that init() is invoked as a kernel thread, not as a function call. Figure 1. The kernel’s startup procedure. Figure 2 is a flowchart that provides an even more generalized picture of the boot process, starting with the bootloader extracting and running the kernel image, and ending with running user programs. Figure 2. The kernel’s startup procedure, in less detail. The following sections describe each of these function calls, including examples taken from the Hitachi SH7750/Sega Dreamcast version of the kernel. 3. In The Beginning... The Linux boot process begins with the kernel’s _stext function, located in arch/<host>/kernel/head.S. This function is called _start in some versions. Interrupts are disabled at this point, and only minimal memory accesses may be possible depending on the capabilities of the host hardware. -

Question Bank Mca Semester V Vol. I
QUESTION BANK MCA SEMESTER V VOL. I 1 FOR PRIVATE CIRCULATION The Questions contained in this booklet have been prepared by the faculty of the Institute from the sources believed to be reliable. Neither the Institute nor the faculty gives any guarantee with respect to completeness or accuracy of the contents contained in the booklet and shall in no event be liable for any errors, omissions or damages arising out of use of the matter contained in the booklet. The Institute and the faculty specifically disclaim any implied warranty as to merchantability or fitness of the information for any particular purpose. 2 QUESTION BANK LINUX PROGRAMMING MCA 301 3 QUESTION BANK LINUX PROGRAMMING - MCA 301 MCA V UNIT - I I Test Your Skills: (a) State Whether the Following Statements are True or False: 1 The “no” option informs the machine that there is no grace period or time to wait for other users to log off. 2 Telnet command is used for changing the run level or state of the computer without rebooting. 3 IP address is a unique identifier for the system. 4 Transmission control protocol (TCP) builds on top of UPS and certifies that each message has been received. 5 Cron is known for arranging the files in the disk in chronological manner. 6 ARP (Address Resolution Protocol) converts IP address to MAC Address. 7 UNIX is a command-based system. 8 A program is synonymous with a process. 9 All UNIX flavors today offer a Command User Interface. 10 The operating system allocates memory for the program and loads the program to the allocated memory. -
The Linux Startup Process
The Linux startup process Jerry Feldman <[email protected]> The Linux Expertise Center Hewlett-Packard Company Document produced via OpenOffice.org Overview ● The Linux boot process – GRUB. This is the default for X86/Linux – LILO – Other boot loaders ● The Linux Operating modes – Single-user mode – Multi-user mode. ● Run Levels – What are run levels – What are the Linux standard run levels – How Linux manages run levels 2 The Linux Boot process ● The PC boot process is a 3-stage boot process that begins with the BIOS executing a short program that is stored in the Master Boot Record (MBR) of the first physical drive. Since this stage 1 boot loader needs to fit in the MBR, it is limited to 512 bytes and is normally written in assembly language. There are a number of boot loaders that can load Linux. ● GRUB and LILO are the most commonly used ones on X86 hardware. ® ® ● EFI is used on the Intel Itanium family. 3 The GRand Unified Bootloader The GRand Unified Bootloader (GRUB) is default boot loader on most distributions today. It has the capability to load a number of different operating systems. 1.The stage 1 boot resides in the MBR and contains the sector number of the stage 2 boot that is usually located in the /boot/grub directory on Linux. 2.The stage 2 boot loader presents a boot menu to the user based on /boot/grub/grub.conf or menu.lst. This contains a boot script. It is the stage2 loader actually loads the Linux kernel or 4 other OS. -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
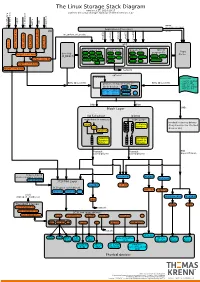
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Implementing Full Device Cloning on the NVIDIA Jetson Platform
Implementing Full Device Cloning on the NVIDIA Jetson Platform March 2, 2018 Calvin Chen Linh Hoang Connor Smith Advisor: Professor Mark Claypool Sponsor - Mentor : NVIDIA - Jimmy Zhang Abstract NVIDIA’s Linux For Tegra development team provides support for many tools which exist on the Jetson-TX2 embedded AI computing device. While tools to clone the user partitions of the Jetson-TX2 exist, no tool exists to fully backup and restore all of the partitions and configurations of these boards. The goal of this project was to develop a tool that allows a user to create a complete clone of the Jetson-TX2 board’s partitions and their contents. We developed a series of bash scripts that fully backup the partitions and configurations of one Jetson-TX2 board and restore them onto another board of the same type. 1 Table of Contents Abstract 1 Table of Contents 2 1 Introduction 3 2 Background 5 2.1 Preliminary Research 5 2.1.1 UEFI Booting and Flashing 5 2.1.2 Tegra Linux Driver Package 8 2.1.3 Network File System 8 2.1.4 Jetson TX2 Bootloader 10 2.2 Linux Terminology, RCM boot and Initial ramdisk 12 2.2.1 Linux Terminology 12 2.2.2 USB Recovery Mode (RCM) Boot 13 2.2.3 Initial Ramdisk 14 2.3 Associated Technologies 15 2.3.1 Linux tools 15 2.3.2 Serial Console 16 3 Methodology 17 4 Product 20 4.1 Backup Script 20 4.2 Restore Script 22 4.3 Initial ramdisk (initrd) 24 4.4 Script Development Guidelines 26 4.4.1 Use Case 26 4.4.2 Integrity 26 4.4.3 Performance 27 5 Future Work 29 6 Conclusions 30 7 Bibliography 31 2 1 Introduction The Jetson-TX2 is a low power, high performance embedded artificial intelligence supercomputer utilized in many modern technologies. -

Bcache (Kernel-Modul Seit 3.11 ...)
DFN-Forum 2016: RZ Storage für die Virtualisierung Konrad Meier, Martin Ullrich, Dirk von Suchodoletz 31.05.2016 – Rechenzentrum Universität Rostock Ausgangslage . Praktiker-Beitrag, deshalb Fokus auf Problemlage und Ergebnisse / Erkenntnisse - Beschaffung neuen Speichersystems bereits in Ausschreibung - Übergangslösung für Problem für ca. halbes Jahr gesucht - Abt. eScience für Strat.entwicklung, bwCloud, HPC - Interessanter „Case“ im RZ-Geschäft, da Storage inzwischen sehr zentral - Storage im Übergang zu SSD/Flash aber All-Flash noch nicht bezahlbar - Flash attraktiver Beschleuniger/Cache - Bisher keine Erfahrung (wenig explizite Erfolgsberichte, jedoch viele Hinweise auf deutliche Verbesserungen), Probleme jedoch so groß, dass Risiko eines Scheiterns akzeptabel (Abschätzung Umbauaufwand etc.) 04.07.16 9. DFN-Forum in Rostock 2 Damalige Ausgangssituation . Zwei ESX-Cluster im Einsatz - Virtualisierung 1 Altsystem, klassiches FC-Setup - Virtualisierung 2 modernes System hoher Performance als zukünftiges Modell . Storage: Klass. Massen- speicher (nicht virt.-optimiert) . Für einfache Migration der VMs Einsatz von NFSv3 . Realisiert über Linux-Fileserver - Fibrechannel-Infrastruktur - LUNs mit Multipath-Anbindung als Blockdevices mit ext4 04.07.16 9. DFN-Forum in Rostock 3 Problem: Schlechte Storage Performance . Mehrfache Ausfälle des NFS-Kopfes mit unklaren Ursachen - Hohe Latenzen seit einigen Wochen - Last sollte aufgrund Semesterpause eher gering sein - Keine bekannten Veränderungen im Lastprofil der vorhandenen VMs . Aufschaukeleffekte - NFS „staut“ lange Queues auf (async Konfiguration) - Bei Crashes, je nach Gast-OS ziemlich kaputte FS - Linux-Gäste setzen bei langen Latenzen (virt.) Blockdevice ro, NTFS toleranter - Ungeschickte Konfigurationen in VMs verschlimmern Zustand . Ergebnisse von fio (iotop, htop ebenso betrachtet) lat(usec): 250=26.96%, 500=72.49%, 750=0.29%, 1000=0.07% lat(msec): 2=0.09%, 4=0.08%, 10=0.01%, 20=0.01%, 50=0.01% lat(msec): 100=0.01%, 250=0.01%, 500=0.01%, 750=0.01%, 2000=0.01% lat(msec): >=2000=0.01% 04.07.16 9. -

A Reliable Booting System for Zynq Ultrascale+ Mpsoc Devices
A reliable booting system for Zynq Ultrascale+ MPSoC devices An embedded solution that provides fallbacks in different parts of the Zynq MPSoC booting process, to assure successful booting into a Linux operating system. A thesis presented for the Bachelor of Science in Electrical Engineering at the University of Applied Sciences Utrecht Name Nekija Dˇzemaili Student ID 1702168 University supervisor Corn´eDuiser CERN supervisors Marc Dobson & Petr Zejdlˇ Field of study Electrical Engineering (embedded systems) CERN-THESIS-2021-031 17/03/2021 February 15th, 2021 Geneva, Switzerland A reliable booting system for Zynq Ultrascale+ MPSoC devices Disclaimer The board of the foundation HU University of Applied Sciences in Utrecht does not accept any form of liability for damage resulting from usage of data, resources, methods, or procedures as described in this report. Duplication without consent of the author or the college is not permitted. If the graduation assignment is executed within a company, explicit consent of the company is necessary for duplication or copying of text from this report. Het bestuur van de Stichting Hogeschool Utrecht te Utrecht aanvaardt geen enkele aansprakelijkheid voor schade voortvloeiende uit het gebruik van enig gegeven, hulpmiddel, werkwijze of procedure in dit verslag beschreven. Vermenigvuldiging zonder toestemming van de auteur(s) en de school is niet toegestaan. Indien het afstudeerwerk in een bedrijf is verricht, is voor vermenigvuldiging of overname van tekst uit dit verslag eveneens toestemming van het bedrijf vereist. N. Dˇzemaili page 1 of 110 A reliable booting system for Zynq Ultrascale+ MPSoC devices Preface This thesis was written for the BSc Electrical Engineering degree of the HU University of Applied Sciences Utrecht, the Netherlands. -

Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, Nicex Lab, NUDT; Yuxing Peng, NUDT
MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices Lujia Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, NiceX Lab, NUDT; Yuxing Peng, NUDT https://www.usenix.org/conference/atc21/presentation/yin This paper is included in the Proceedings of the 2021 USENIX Annual Technical Conference. July 14–16, 2021 978-1-939133-23-6 Open access to the Proceedings of the 2021 USENIX Annual Technical Conference is sponsored by USENIX. MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices Lujia Yin Li Wang Yiming Zhang [email protected] [email protected] [email protected] (Corresponding) NUDT Didi Chuxing NiceX Lab, NUDT Yuxing Peng [email protected] NUDT Abstract replicas on SSDs and replicates backup replicas on HDDs; and SSHD [28] integrates a small SSD inside a large HDD DM-cache is a component of the device mapper of Linux of which the SSD acts as a cache. kernel, which has been widely used to map SSDs and HDDs As the demand of HDD-SSD hybrid storage increases, onto higher-level virtual block devices that take fast SSDs as Linux kernel has supported users to combine HDDs and a cache for slow HDDs to achieve high I/O performance at SSDs to jointly provide virtual block storage service. DM- low monetary cost. While enjoying the benefit of persistent cache [5] is a component of the device mapper [4] in the caching where SSDs accelerate normal I/O without affecting kernel, which has been widely used in industry to map SSDs durability, the current design of DM-cache suffers from and HDDs onto higher-level virtual block devices that take long crash recovery times (at the scale of hours) and low fast SSDs as a cache for slow HDDs. -

Think ALL Distros Offer the Best Linux Devsecops Environment?
Marc Staimer, Dragon Slayor Consulting WHITE PAPER Think All Distros Offer the Best Linux DevSecOps What You’re Not Being Told About Environment? Database as a Service (DBaaS) Think Again! WHITE PAPER • Think Again! Think All Distros Provide the Best Linux DevSecOps Environment? Think Again! Introduction DevOps is changing. Developing code with after the fact bolt-on security is dangerously flawed. When that bolt-on fails to correct exploitable code vulnerabilities, it puts the entire organization at risk. Security has been generally an afterthought for many doing DevOps. It was often assumed the IT organization’s systemic multiple layers of security measures and appliances would protect any new code from malware or breaches. And besides, developing code with security built in, adds tasks and steps to development and testing time. More tasks and steps delay time-to-market. Multi-tenant clouds have radically changed the market. Any vulnerability in a world with increasing cyber-attacks, can put millions of user’s data at risk. Those legacy DevOps attitudes are unsound. They are potentially quite costly in the current environment. Consider that nearly every developed and most developing countries have enacted laws and regulation protecting personally identifiable information or PII1. PII is incredibly valuable to cybercriminals. Stealing PII enables them to commit many cybercrimes including the cybertheft of identities, finances, intellectual property, admin privileges, and much more. PII can also be sold on the web. Those PII laws and regulations are meant to force IT organizations to protect PII. Non-compliance of these laws and regulations often carry punitive financial penalties. -

MX-19.2 Users Manual
MX-19.2 Users Manual v. 20200801 manual AT mxlinux DOT org Ctrl-F = Search this Manual Ctrl+Home = Return to top Table of Contents 1 Introduction...................................................................................................................................4 1.1 About MX Linux................................................................................................................4 1.2 About this Manual..............................................................................................................4 1.3 System requirements..........................................................................................................5 1.4 Support and EOL................................................................................................................6 1.5 Bugs, issues and requests...................................................................................................6 1.6 Migration............................................................................................................................7 1.7 Our positions......................................................................................................................8 1.8 Notes for Translators.............................................................................................................8 2 Installation...................................................................................................................................10 2.1 Introduction......................................................................................................................10 -

Dm-Cache.Pdf
DM-Cache Marc Skinner Principal Solutions Architect Twin Cities Users Group :: Q1/2016 Why Cache? ● Spinning disks are slow! ● Solid state disks (SSD) are fast!! ● Non-Volatile Memory Express (NVMe) devices are insane!!! Why not? ● Hybrid drives make 5900rpm drives act like 7200rpm drives with very small on board SSD cache ● Hmm, talk to FAST and move to SLOW? FAST SLOW Linux Caching Options ● DM-Cache ● Oldest and most stable. Developed in 2006 by IBM research group, and merged into Linux kernel tree in version 3.9. Uses the device-mapper framework to cache a slower device ● FlashCache ● Kernel module inspired by dm-cache and developed/maintained by Facebook. Also uses the device-mapper framework. ● EnhanceIO, RapidCache ● Both variations of FlashCache ● BCache ● Newest option and does not rely on device-mapper framework DM-Cache Modes ● write-through ● Red Hat default ● Write requests are not returned until the data reaches the origin and the cache device ● write-back ● Writes go only to the cache device ● pass-through ● Used to by pass the cache, used if cache is corrupt DM-Cache Setup ● Enable discards first # vi /etc/lvm/lvm.conf issue_discards = 1 # dracut -f # sync # reboot DM-Cache Setup ● Create PV, VG and LV with Cache # pvcreate /dev/md2 (raid 10 - 6 x 250gb SSD) # pvcreate /dev/md3 (raid 10 - 6 x 2tb SATA) # vgcreate vg_iscsi /dev/md3 /dev/md2 # lvcreate -l 100%FREE -n lv_sata vg_iscsi /dev/md3 # lvcreate -L 5G -n lv_cache_meta vg_iscsi /dev/md2 # lvcreate -L 650G -n lv_cache vg_iscsi /dev/md2 # lvconvert --type cache-pool