ZEA, a Data Management Approach for SMR
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 12 SP4
SUSE Linux Enterprise Server 12 SP4 Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 12 SP4 Provides information about how to manage storage devices on a SUSE Linux Enterprise Server. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xii 2 Giving Feedback xiv 3 Documentation Conventions xiv 4 Product Life Cycle and Support xvi Support Statement for SUSE Linux Enterprise Server xvii • Technology Previews xviii I FILE SYSTEMS AND MOUNTING 1 1 Overview -

Rootless Containers with Podman and Fuse-Overlayfs
CernVM Workshop 2019 (4th June 2019) Rootless containers with Podman and fuse-overlayfs Giuseppe Scrivano @gscrivano Introduction 2 Rootless Containers • “Rootless containers refers to the ability for an unprivileged user (i.e. non-root user) to create, run and otherwise manage containers.” (https://rootlesscontaine.rs/ ) • Not just about running the container payload as an unprivileged user • Container runtime runs also as an unprivileged user 3 Don’t confuse with... • sudo podman run --user foo – Executes the process in the container as non-root – Podman and the OCI runtime still running as root • USER instruction in Dockerfile – same as above – Notably you can’t RUN dnf install ... 4 Don’t confuse with... • podman run --uidmap – Execute containers as a non-root user, using user namespaces – Most similar to rootless containers, but still requires podman and runc to run as root 5 Motivation of Rootless Containers • To mitigate potential vulnerability of container runtimes • To allow users of shared machines (e.g. HPC) to run containers without the risk of breaking other users environments • To isolate nested containers 6 Caveat: Not a panacea • Although rootless containers could mitigate these vulnerabilities, it is not a panacea , especially it is powerless against kernel (and hardware) vulnerabilities – CVE 2013-1858, CVE-2015-1328, CVE-2018-18955 • Castle approach : it should be used in conjunction with other security layers such as seccomp and SELinux 7 Podman 8 Rootless Podman Podman is a daemon-less alternative to Docker • $ alias -

Oracle® Linux 7 Release Notes for Oracle Linux 7.2
Oracle® Linux 7 Release Notes for Oracle Linux 7.2 E67200-22 March 2021 Oracle Legal Notices Copyright © 2015, 2021 Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -

Globalfs: a Strongly Consistent Multi-Site File System
GlobalFS: A Strongly Consistent Multi-Site File System Leandro Pacheco Raluca Halalai Valerio Schiavoni University of Lugano University of Neuchatelˆ University of Neuchatelˆ Fernando Pedone Etienne Riviere` Pascal Felber University of Lugano University of Neuchatelˆ University of Neuchatelˆ Abstract consistency, availability, and tolerance to partitions. Our goal is to ensure strongly consistent file system operations This paper introduces GlobalFS, a POSIX-compliant despite node failures, at the price of possibly reduced geographically distributed file system. GlobalFS builds availability in the event of a network partition. Weak on two fundamental building blocks, an atomic multicast consistency is suitable for domain-specific applications group communication abstraction and multiple instances of where programmers can anticipate and provide resolution a single-site data store. We define four execution modes and methods for conflicts, or work with last-writer-wins show how all file system operations can be implemented resolution methods. Our rationale is that for general-purpose with these modes while ensuring strong consistency and services such as a file system, strong consistency is more tolerating failures. We describe the GlobalFS prototype in appropriate as it is both more intuitive for the users and detail and report on an extensive performance assessment. does not require human intervention in case of conflicts. We have deployed GlobalFS across all EC2 regions and Strong consistency requires ordering commands across show that the system scales geographically, providing replicas, which needs coordination among nodes at performance comparable to other state-of-the-art distributed geographically distributed sites (i.e., regions). Designing file systems for local commands and allowing for strongly strongly consistent distributed systems that provide good consistent operations over the whole system. -

In Search of the Ideal Storage Configuration for Docker Containers
In Search of the Ideal Storage Configuration for Docker Containers Vasily Tarasov1, Lukas Rupprecht1, Dimitris Skourtis1, Amit Warke1, Dean Hildebrand1 Mohamed Mohamed1, Nagapramod Mandagere1, Wenji Li2, Raju Rangaswami3, Ming Zhao2 1IBM Research—Almaden 2Arizona State University 3Florida International University Abstract—Containers are a widely successful technology today every running container. This would cause a great burden on popularized by Docker. Containers improve system utilization by the I/O subsystem and make container start time unacceptably increasing workload density. Docker containers enable seamless high for many workloads. As a result, copy-on-write (CoW) deployment of workloads across development, test, and produc- tion environments. Docker’s unique approach to data manage- storage and storage snapshots are popularly used and images ment, which involves frequent snapshot creation and removal, are structured in layers. A layer consists of a set of files and presents a new set of exciting challenges for storage systems. At layers with the same content can be shared across images, the same time, storage management for Docker containers has reducing the amount of storage required to run containers. remained largely unexplored with a dizzying array of solution With Docker, one can choose Aufs [6], Overlay2 [7], choices and configuration options. In this paper we unravel the multi-faceted nature of Docker storage and demonstrate its Btrfs [8], or device-mapper (dm) [9] as storage drivers which impact on system and workload performance. As we uncover provide the required snapshotting and CoW capabilities for new properties of the popular Docker storage drivers, this is a images. None of these solutions, however, were designed with sobering reminder that widespread use of new technologies can Docker in mind and their effectiveness for Docker has not been often precede their careful evaluation. -

MINCS - the Container in the Shell (Script)
MINCS - The Container in the Shell (script) - Masami Hiramatsu <[email protected]> Tech Lead, Linaro Ltd. Open Source Summit Japan 2017 LEADING COLLABORATION IN THE ARM ECOSYSTEM Who am I... Masami Hiramatsu - Linux kernel kprobes maintainer - Working for Linaro as a Tech Lead LEADING COLLABORATION IN THE ARM ECOSYSTEM Demo # minc top # minc -r /opt/debian/x86_64 # minc -r /opt/debian/arm64 --arch arm64 LEADING COLLABORATION IN THE ARM ECOSYSTEM What Is MINCS? My Personal Fun Project to learn how linux containers work :-) LEADING COLLABORATION IN THE ARM ECOSYSTEM What Is MINCS? Mini Container Shell Scripts (pronounced ‘minks’) - Container engine implementation using POSIX shell scripts - It is small (~60KB, ~2KLOC) (~20KB in minimum) - It can run on busybox - No architecture dependency (* except for qemu/um mode) - No need for special binaries (* except for libcap, just for capsh --exec) - Main Features - Namespaces (Mount, PID, User, UTS, Net*) - Cgroups (CPU, Memory) - Capabilities - Overlay filesystem - Qemu cross-arch/system emulation - User-mode-linux - Image importing from dockerhub And all are done by CLI commands :-) LEADING COLLABORATION IN THE ARM ECOSYSTEM Why Shell Script? That is my favorite language :-) - Easy to understand for *nix administrators - Just a bunch of commands - Easy to modify - Good for prototyping - Easy to deploy - No architecture dependencies - Very small - Able to run on busybox (+ libcap is perfect) LEADING COLLABORATION IN THE ARM ECOSYSTEM MINCS Use-Cases For Learning - Understand how containers work For Development - Prepare isolated (cross-)build environment For Testing - Test new applications in isolated environment - Test new kernel features on qemu using local tools For products? - Maybe good for embedded devices which has small resources LEADING COLLABORATION IN THE ARM ECOSYSTEM What Is A Linux Container? There are many linux container engines - Docker, LXC, rkt, runc, .. -

Using the Andrew File System on *BSD [email protected], Bsdcan, 2006 Why Another Network Filesystem
Using the Andrew File System on *BSD [email protected], BSDCan, 2006 why another network filesystem 1-slide history of Andrew File System user view admin view OpenAFS Arla AFS on OpenBSD, FreeBSD and NetBSD Filesharing on the Internet use FTP or link to HTTP file interface through WebDAV use insecure protocol over vpn History of AFS 1984: developed at Carnegie Mellon 1989: TransArc Corperation 1994: over to IBM 1997: Arla, aimed at Linux and BSD 2000: IBM releases source 2000: foundation of OpenAFS User view <1> global filesystem rooted at /afs /afs/cern.ch/... /afs/cmu.edu/... /afs/gorlaeus.net/users/h/hugo/... User view <2> authentication through Kerberos #>kinit <username> obtain krbtgt/<realm>@<realm> #>afslog obtain afs@<realm> #>cd /afs/<cell>/users/<username> User view <3> ACL (dir based) & Quota usage runs on Windows, OS X, Linux, Solaris ... and *BSD Admin view <1> <cell> <partition> <server> <volume> <volume> <server> <partition> Admin view <2> /afs/gorlaeus.net/users/h/hugo/presos/afs_slides.graffle gorlaeus.net /vicepa fwncafs1 users hugo h bram <server> /vicepb Admin view <2a> /afs/gorlaeus.net/users/h/hugo/presos/afs_slides.graffle gorlaeus.net /vicepa fwncafs1 users hugo /vicepa fwncafs2 h bram Admin view <3> servers require KeyFile ~= keytab procedure differs for Heimdal: ktutil copy MIT: asetkey add Admin view <4> entry in CellServDB >gorlaeus.net #my cell name 10.0.0.1 <dbserver host name> required on servers required on clients without DynRoot Admin view <5> File locking no databases on AFS (requires byte range locking) -

Filesystems HOWTO Filesystems HOWTO Table of Contents Filesystems HOWTO
Filesystems HOWTO Filesystems HOWTO Table of Contents Filesystems HOWTO..........................................................................................................................................1 Martin Hinner < [email protected]>, http://martin.hinner.info............................................................1 1. Introduction..........................................................................................................................................1 2. Volumes...............................................................................................................................................1 3. DOS FAT 12/16/32, VFAT.................................................................................................................2 4. High Performance FileSystem (HPFS)................................................................................................2 5. New Technology FileSystem (NTFS).................................................................................................2 6. Extended filesystems (Ext, Ext2, Ext3)...............................................................................................2 7. Macintosh Hierarchical Filesystem − HFS..........................................................................................3 8. ISO 9660 − CD−ROM filesystem.......................................................................................................3 9. Other filesystems.................................................................................................................................3 -

Tizen Based Remote Controller CAR Using Raspberry Pi2
#ELC2016 Tizen based remote controller CAR using raspberry pi2 Pintu Kumar ([email protected], [email protected]) Samsung Research India – Bangalore : Tizen Kernel/BSP Team Embedded Linux Conference – 06th April/2016 1 CONTENT #ELC2016 • INTRODUCTION • RASPBERRY PI2 OVERVIEW • TIZEN OVERVIEW • HARDWARE & SOFTWARE REQUIREMENTS • SOFTWARE CUSTOMIZATION • SOFTWARE SETUP & INTERFACING • HARDWARE INTERFACING & CONNECTIONS • ROBOT CONTROL MECHANISM • SOME RESULTS • CONCLUSION • REFERENCES Embedded Linux Conference – 06th April/2016 2 INTRODUCTION #ELC2016 • This talk is about designing a remote controller robot (toy car) using the raspberry pi2 hardware, pi2 Linux Kernel and Tizen OS as platform. • In this presentation, first we will see how to replace and boot Tizen OS on Raspberry Pi using the pre-built Tizen images. Then we will see how to setup Bluetooth, Wi-Fi on Tizen and finally see how to control a robot remotely using Tizen smart phone application. Embedded Linux Conference – 06th April/2016 3 RASPBERRY PI2 - OVERVIEW #ELC2016 1 GB RAM Embedded Linux Conference – 06th April/2016 4 Raspberry PI2 Features #ELC2016 • Broadcom BCM2836 900MHz Quad Core ARM Cortex-A7 CPU • 1GB RAM • 4 USB ports • 40 GPIO pins • Full HDMI port • Ethernet port • Combined 3.5mm audio jack and composite video • Camera interface (CSI) • Display interface (DSI) • Micro SD card slot • Video Core IV 3D graphics core Embedded Linux Conference – 06th April/2016 5 PI2 GPIO Pins #ELC2016 Embedded Linux Conference – 06th April/2016 6 TIZEN OVERVIEW #ELC2016 Embedded Linux Conference – 06th April/2016 7 TIZEN Profiles #ELC2016 Mobile Wearable IVI TV TIZEN Camera PC/Tablet Printer Common Next?? • TIZEN is the OS of everything. -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
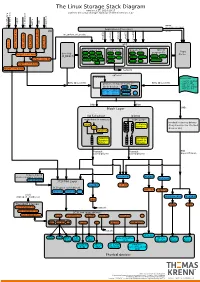
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18].