06 使用bcache为ceph OSD加速的具体实践 by 花瑞
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Linux Kernel Module Programming Guide
The Linux Kernel Module Programming Guide Peter Jay Salzman Michael Burian Ori Pomerantz Copyright © 2001 Peter Jay Salzman 2007−05−18 ver 2.6.4 The Linux Kernel Module Programming Guide is a free book; you may reproduce and/or modify it under the terms of the Open Software License, version 1.1. You can obtain a copy of this license at http://opensource.org/licenses/osl.php. This book is distributed in the hope it will be useful, but without any warranty, without even the implied warranty of merchantability or fitness for a particular purpose. The author encourages wide distribution of this book for personal or commercial use, provided the above copyright notice remains intact and the method adheres to the provisions of the Open Software License. In summary, you may copy and distribute this book free of charge or for a profit. No explicit permission is required from the author for reproduction of this book in any medium, physical or electronic. Derivative works and translations of this document must be placed under the Open Software License, and the original copyright notice must remain intact. If you have contributed new material to this book, you must make the material and source code available for your revisions. Please make revisions and updates available directly to the document maintainer, Peter Jay Salzman <[email protected]>. This will allow for the merging of updates and provide consistent revisions to the Linux community. If you publish or distribute this book commercially, donations, royalties, and/or printed copies are greatly appreciated by the author and the Linux Documentation Project (LDP). -

The Xen Port of Kexec / Kdump a Short Introduction and Status Report
The Xen Port of Kexec / Kdump A short introduction and status report Magnus Damm Simon Horman VA Linux Systems Japan K.K. www.valinux.co.jp/en/ Xen Summit, September 2006 Magnus Damm ([email protected]) Kexec / Kdump Xen Summit, September 2006 1 / 17 Outline Introduction to Kexec What is Kexec? Kexec Examples Kexec Overview Introduction to Kdump What is Kdump? Kdump Kernels The Crash Utility Xen Porting Effort Kexec under Xen Kdump under Xen The Dumpread Tool Partial Dumps Current Status Magnus Damm ([email protected]) Kexec / Kdump Xen Summit, September 2006 2 / 17 Introduction to Kexec Outline Introduction to Kexec What is Kexec? Kexec Examples Kexec Overview Introduction to Kdump What is Kdump? Kdump Kernels The Crash Utility Xen Porting Effort Kexec under Xen Kdump under Xen The Dumpread Tool Partial Dumps Current Status Magnus Damm ([email protected]) Kexec / Kdump Xen Summit, September 2006 3 / 17 Kexec allows you to reboot from Linux into any kernel. as long as the new kernel doesn’t depend on the BIOS for setup. Introduction to Kexec What is Kexec? What is Kexec? “kexec is a system call that implements the ability to shutdown your current kernel, and to start another kernel. It is like a reboot but it is indepedent of the system firmware...” Configuration help text in Linux-2.6.17 Magnus Damm ([email protected]) Kexec / Kdump Xen Summit, September 2006 4 / 17 . as long as the new kernel doesn’t depend on the BIOS for setup. Introduction to Kexec What is Kexec? What is Kexec? “kexec is a system call that implements the ability to shutdown your current kernel, and to start another kernel. -

Anatomy of Linux Loadable Kernel Modules a 2.6 Kernel Perspective
Anatomy of Linux loadable kernel modules A 2.6 kernel perspective Skill Level: Intermediate M. Tim Jones ([email protected]) Consultant Engineer Emulex Corp. 16 Jul 2008 Linux® loadable kernel modules, introduced in version 1.2 of the kernel, are one of the most important innovations in the Linux kernel. They provide a kernel that is both scalable and dynamic. Discover the ideas behind loadable modules, and learn how these independent objects dynamically become part of the Linux kernel. The Linux kernel is what's known as a monolithic kernel, which means that the majority of the operating system functionality is called the kernel and runs in a privileged mode. This differs from a micro-kernel, which runs only basic functionality as the kernel (inter-process communication [IPC], scheduling, basic input/output [I/O], memory management) and pushes other functionality outside the privileged space (drivers, network stack, file systems). You'd think that Linux is then a very static kernel, but in fact it's quite the opposite. Linux can be dynamically altered at run time through the use of Linux kernel modules (LKMs). More in Tim's Anatomy of... series on developerWorks • Anatomy of Linux flash file systems • Anatomy of Security-Enhanced Linux (SELinux) • Anatomy of real-time Linux architectures • Anatomy of the Linux SCSI subsystem • Anatomy of the Linux file system • Anatomy of the Linux networking stack Anatomy of Linux loadable kernel modules © Copyright IBM Corporation 1994, 2008. All rights reserved. Page 1 of 11 developerWorks® ibm.com/developerWorks • Anatomy of the Linux kernel • Anatomy of the Linux slab allocator • Anatomy of Linux synchronization methods • All of Tim's Anatomy of.. -

Kdump, a Kexec-Based Kernel Crash Dumping Mechanism
Kdump, A Kexec-based Kernel Crash Dumping Mechanism Vivek Goyal Eric W. Biederman Hariprasad Nellitheertha IBM Linux NetworkX IBM [email protected] [email protected] [email protected] Abstract important consideration for the success of a so- lution has been the reliability and ease of use. Kdump is a crash dumping solution that pro- Kdump is a kexec based kernel crash dump- vides a very reliable dump generation and cap- ing mechanism, which is being perceived as turing mechanism [01]. It is simple, easy to a reliable crash dumping solution for Linux R . configure and provides a great deal of flexibility This paper begins with brief description of what in terms of dump device selection, dump saving kexec is and what it can do in general case, and mechanism, and plugging-in filtering mecha- then details how kexec has been modified to nism. boot a new kernel even in a system crash event. The idea of kdump has been around for Kexec enables booting into a new kernel while quite some time now, and initial patches for preserving the memory contents in a crash sce- kdump implementation were posted to the nario, and kdump uses this feature to capture Linux kernel mailing list last year [03]. Since the kernel crash dump. Physical memory lay- then, kdump has undergone significant design out and processor state are encoded in ELF core changes to ensure improved reliability, en- format, and these headers are stored in a re- hanced ease of use and cleaner interfaces. This served section of memory. Upon a crash, new paper starts with an overview of the kdump de- kernel boots up from reserved memory and pro- sign and development history. -

Communicating Between the Kernel and User-Space in Linux Using Netlink Sockets
SOFTWARE—PRACTICE AND EXPERIENCE Softw. Pract. Exper. 2010; 00:1–7 Prepared using speauth.cls [Version: 2002/09/23 v2.2] Communicating between the kernel and user-space in Linux using Netlink sockets Pablo Neira Ayuso∗,∗1, Rafael M. Gasca1 and Laurent Lefevre2 1 QUIVIR Research Group, Departament of Computer Languages and Systems, University of Seville, Spain. 2 RESO/LIP team, INRIA, University of Lyon, France. SUMMARY When developing Linux kernel features, it is a good practise to expose the necessary details to user-space to enable extensibility. This allows the development of new features and sophisticated configurations from user-space. Commonly, software developers have to face the task of looking for a good way to communicate between kernel and user-space in Linux. This tutorial introduces you to Netlink sockets, a flexible and extensible messaging system that provides communication between kernel and user-space. In this tutorial, we provide fundamental guidelines for practitioners who wish to develop Netlink-based interfaces. key words: kernel interfaces, netlink, linux 1. INTRODUCTION Portable open-source operating systems like Linux [1] provide a good environment to develop applications for the real-world since they can be used in very different platforms: from very small embedded devices, like smartphones and PDAs, to standalone computers and large scale clusters. Moreover, the availability of the source code also allows its study and modification, this renders Linux useful for both the industry and the academia. The core of Linux, like many modern operating systems, follows a monolithic † design for performance reasons. The main bricks that compose the operating system are implemented ∗Correspondence to: Pablo Neira Ayuso, ETS Ingenieria Informatica, Department of Computer Languages and Systems. -

Detecting Exploit Code Execution in Loadable Kernel Modules
Detecting Exploit Code Execution in Loadable Kernel Modules HaizhiXu WenliangDu SteveJ.Chapin Systems Assurance Institute Syracuse University 3-114 CST, 111 College Place, Syracuse, NY 13210, USA g fhxu02, wedu, chapin @syr.edu Abstract and pointer checks can lead to kernel-level exploits, which can jeopardize the integrity of the running kernel. Inside the In current extensible monolithic operating systems, load- kernel, exploitcode has the privilegeto interceptsystem ser- able kernel modules (LKM) have unrestricted access to vice routines, to modify interrupt handlers, and to overwrite all portions of kernel memory and I/O space. As a result, kernel data. In such cases, the behavior of the entire sys- kernel-module exploitation can jeopardize the integrity of tem may become suspect. the entire system. In this paper, we analyze the threat that Kernel-level protection is different from user space pro- comes from the implicit trust relationship between the oper- tection. Not every application-level protection mechanism ating system kernel and loadable kernel modules. We then can be applied directly to kernel code, because privileges present a specification-directed access monitoring tool— of the kernel environment is different from that of the user HECK, that detects kernel modules for malicious code ex- space. For example, non-executableuser page [21] and non- ecution. Inside the module, HECK prevents code execution executable user stack [29] use virtual memory mapping sup- on the kernel stack and the data sections; on the bound- port for pages and segments, but inside the kernel, a page ary, HECK restricts the module’s access to only those kernel or segment fault can lead to kernel panic. -

DM-Relay - Safe Laptop Mode Via Linux Device Mapper
' $ DM-Relay - Safe Laptop Mode via Linux Device Mapper Study Thesis by cand. inform. Fabian Franz at the Faculty of Informatics Supervisor: Prof. Dr. Frank Bellosa Supervising Research Assistant: Dipl.-Inform. Konrad Miller Day of completion: 04/05/2010 &KIT – Universitat¨ des Landes Baden-Wurttemberg¨ und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu % I hereby declare that this thesis is my own original work which I created without illegitimate help by others, that I have not used any other sources or resources than the ones indicated and that due acknowledgment is given where reference is made to the work of others. Karlsruhe, April 5th, 2010 Contents Deutsche Zusammenfassung xi 1 Introduction 1 1.1 Problem Definition . .1 1.2 Objectives . .1 1.3 Methodology . .1 1.4 Contribution . .2 1.5 Thesis Outline . .2 2 Background 3 2.1 Problems of Disk Power Management . .3 2.2 State of the Art . .4 2.3 Summary of this chapter . .8 3 Analysis 9 3.1 Pro and Contra . .9 3.2 A new approach . 13 3.3 Analysis of Proposal . 15 3.4 Summary of this chapter . 17 4 Design 19 4.1 Common problems . 19 4.2 System-Design . 21 4.3 Summary of this chapter . 21 5 Implementation of a dm-module for the Linux kernel 23 5.1 System-Architecture . 24 5.2 Log suitable for Flash-Storage . 28 5.3 Using dm-relay in practice . 31 5.4 Summary of this chapter . 31 vi Contents 6 Evaluation 33 6.1 Methodology . 33 6.2 Benchmarking setup . -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
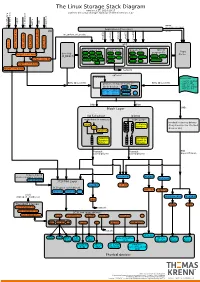
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18]. -

An Evolutionary Study of Linux Memory Management for Fun and Profit Jian Huang, Moinuddin K
An Evolutionary Study of Linux Memory Management for Fun and Profit Jian Huang, Moinuddin K. Qureshi, and Karsten Schwan, Georgia Institute of Technology https://www.usenix.org/conference/atc16/technical-sessions/presentation/huang This paper is included in the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16). June 22–24, 2016 • Denver, CO, USA 978-1-931971-30-0 Open access to the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16) is sponsored by USENIX. An Evolutionary Study of inu emory anagement for Fun and rofit Jian Huang, Moinuddin K. ureshi, Karsten Schwan Georgia Institute of Technology Astract the patches committed over the last five years from 2009 to 2015. The study covers 4587 patches across Linux We present a comprehensive and uantitative study on versions from 2.6.32.1 to 4.0-rc4. We manually label the development of the Linux memory manager. The each patch after carefully checking the patch, its descrip- study examines 4587 committed patches over the last tions, and follow-up discussions posted by developers. five years (2009-2015) since Linux version 2.6.32. In- To further understand patch distribution over memory se- sights derived from this study concern the development mantics, we build a tool called MChecker to identify the process of the virtual memory system, including its patch changes to the key functions in mm. MChecker matches distribution and patterns, and techniues for memory op- the patches with the source code to track the hot func- timizations and semantics. Specifically, we find that tions that have been updated intensively. -

Comparison of Kernel and User Space File Systems
Comparison of kernel and user space file systems — Bachelor Thesis — Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg Vorgelegt von: Kira Isabel Duwe E-Mail-Adresse: [email protected] Matrikelnummer: 6225091 Studiengang: Informatik Erstgutachter: Professor Dr. Thomas Ludwig Zweitgutachter: Professor Dr. Norbert Ritter Betreuer: Michael Kuhn Hamburg, den 28. August 2014 Abstract A file system is part of the operating system and defines an interface between OS and the computer’s storage devices. It is used to control how the computer names, stores and basically organises the files and directories. Due to many different requirements, such as efficient usage of the storage, a grand variety of approaches arose. The most important ones are running in the kernel as this has been the only way for a long time. In 1994, developers came up with an idea which would allow mounting a file system in the user space. The FUSE (Filesystem in Userspace) project was started in 2004 and implemented in the Linux kernel by 2005. This provides the opportunity for a user to write an own file system without editing the kernel code and therefore avoid licence problems. Additionally, FUSE offers a stable library interface. It is originally implemented as a loadable kernel module. Due to its design, all operations have to pass through the kernel multiple times. The additional data transfer and the context switches are causing some overhead which will be analysed in this thesis. So, there will be a basic overview about on how exactly a file system operation takes place and which mount options for a FUSE-based system result in a better performance.