Think ALL Distros Offer the Best Linux Devsecops Environment?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 7 7.1 Release Notes
Red Hat Enterprise Linux 7 7.1 Release Notes Release Notes for Red Hat Enterprise Linux 7 Red Hat Customer Content Services Red Hat Enterprise Linux 7 7.1 Release Notes Release Notes for Red Hat Enterprise Linux 7 Red Hat Customer Content Services Legal Notice Copyright © 2015 Red Hat, Inc. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

Fast and Scalable VMM Live Upgrade in Large Cloud Infrastructure
Fast and Scalable VMM Live Upgrade in Large Cloud Infrastructure Xiantao Zhang Xiao Zheng Zhi Wang Alibaba Group Alibaba Group Florida State University [email protected] [email protected] [email protected] Qi Li Junkang Fu Yang Zhang Tsinghua University Alibaba Group Alibaba Group [email protected] [email protected] [email protected] Yibin Shen Alibaba Group [email protected] Abstract hand over passthrough devices to the new KVM instance High availability is the most important and challenging prob- without losing any ongoing (DMA) operations. Our evalua- lem for cloud providers. However, virtual machine mon- tion shows that Orthus can reduce the total migration time itor (VMM), a crucial component of the cloud infrastruc- and downtime by more than 99% and 90%, respectively. We ture, has to be frequently updated and restarted to add secu- have deployed Orthus in one of the largest cloud infrastruc- rity patches and new features, undermining high availabil- tures for a long time. It has become the most effective and ity. There are two existing live update methods to improve indispensable tool in our daily maintenance of hundreds of the cloud availability: kernel live patching and Virtual Ma- thousands of servers and millions of VMs. chine (VM) live migration. However, they both have serious CCS Concepts • Security and privacy → Virtualization drawbacks that impair their usefulness in the large cloud and security; • Computer systems organization → Avail- infrastructure: kernel live patching cannot handle complex ability. changes (e.g., changes to persistent data structures); and VM live migration may incur unacceptably long delays when Keywords virtualization; live upgrade; cloud infrastructure migrating millions of VMs in the whole cloud, for example, ACM Reference Format: to deploy urgent security patches. -

Live Kernel Patching Using Kgraft
SUSE Linux Enterprise Server 12 SP4 Live Kernel Patching Using kGraft SUSE Linux Enterprise Server 12 SP4 This document describes the basic principles of the kGraft live patching technology and provides usage guidelines for the SLE Live Patching service. kGraft is a live patching technology for runtime patching of the Linux kernel, without stopping the kernel. This maximizes system uptime, and thus system availability, which is important for mission-critical systems. By allowing dynamic patching of the kernel, the technology also encourages users to install critical security updates without deferring them to a scheduled downtime. A kGraft patch is a kernel module, intended for replacing whole functions in the kernel. kGraft primarily oers in-kernel infrastructure for integration of the patched code with base kernel code at runtime. SLE Live Patching is a service provided on top of regular SUSE Linux Enterprise Server maintenance. kGraft patches distributed through SLE Live Patching supplement regular SLES maintenance updates. Common update stack and procedures can be used for SLE Live Patching deployment. Publication Date: 09/24/2021 Contents 1 Advantages of kGraft 3 2 Low-level Function of kGraft 3 1 Live Kernel Patching Using kGraft 3 Installing kGraft Patches 4 4 Patch Lifecycle 6 5 Removing a kGraft Patch 6 6 Stuck Kernel Execution Threads 6 7 The kgr Tool 7 8 Scope of kGraft Technology 7 9 Scope of SLE Live Patching 8 10 Interaction with the Support Processes 8 11 GNU Free Documentation License 8 2 Live Kernel Patching Using kGraft 1 Advantages of kGraft Live kernel patching using kGraft is especially useful for quick response in emergencies (when serious vulnerabilities are known and should be xed when possible or there are serious system stability issues with a known x). -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
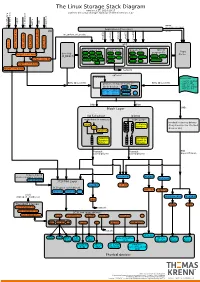
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18]. -

Bcache (Kernel-Modul Seit 3.11 ...)
DFN-Forum 2016: RZ Storage für die Virtualisierung Konrad Meier, Martin Ullrich, Dirk von Suchodoletz 31.05.2016 – Rechenzentrum Universität Rostock Ausgangslage . Praktiker-Beitrag, deshalb Fokus auf Problemlage und Ergebnisse / Erkenntnisse - Beschaffung neuen Speichersystems bereits in Ausschreibung - Übergangslösung für Problem für ca. halbes Jahr gesucht - Abt. eScience für Strat.entwicklung, bwCloud, HPC - Interessanter „Case“ im RZ-Geschäft, da Storage inzwischen sehr zentral - Storage im Übergang zu SSD/Flash aber All-Flash noch nicht bezahlbar - Flash attraktiver Beschleuniger/Cache - Bisher keine Erfahrung (wenig explizite Erfolgsberichte, jedoch viele Hinweise auf deutliche Verbesserungen), Probleme jedoch so groß, dass Risiko eines Scheiterns akzeptabel (Abschätzung Umbauaufwand etc.) 04.07.16 9. DFN-Forum in Rostock 2 Damalige Ausgangssituation . Zwei ESX-Cluster im Einsatz - Virtualisierung 1 Altsystem, klassiches FC-Setup - Virtualisierung 2 modernes System hoher Performance als zukünftiges Modell . Storage: Klass. Massen- speicher (nicht virt.-optimiert) . Für einfache Migration der VMs Einsatz von NFSv3 . Realisiert über Linux-Fileserver - Fibrechannel-Infrastruktur - LUNs mit Multipath-Anbindung als Blockdevices mit ext4 04.07.16 9. DFN-Forum in Rostock 3 Problem: Schlechte Storage Performance . Mehrfache Ausfälle des NFS-Kopfes mit unklaren Ursachen - Hohe Latenzen seit einigen Wochen - Last sollte aufgrund Semesterpause eher gering sein - Keine bekannten Veränderungen im Lastprofil der vorhandenen VMs . Aufschaukeleffekte - NFS „staut“ lange Queues auf (async Konfiguration) - Bei Crashes, je nach Gast-OS ziemlich kaputte FS - Linux-Gäste setzen bei langen Latenzen (virt.) Blockdevice ro, NTFS toleranter - Ungeschickte Konfigurationen in VMs verschlimmern Zustand . Ergebnisse von fio (iotop, htop ebenso betrachtet) lat(usec): 250=26.96%, 500=72.49%, 750=0.29%, 1000=0.07% lat(msec): 2=0.09%, 4=0.08%, 10=0.01%, 20=0.01%, 50=0.01% lat(msec): 100=0.01%, 250=0.01%, 500=0.01%, 750=0.01%, 2000=0.01% lat(msec): >=2000=0.01% 04.07.16 9. -

Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, Nicex Lab, NUDT; Yuxing Peng, NUDT
MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices Lujia Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, NiceX Lab, NUDT; Yuxing Peng, NUDT https://www.usenix.org/conference/atc21/presentation/yin This paper is included in the Proceedings of the 2021 USENIX Annual Technical Conference. July 14–16, 2021 978-1-939133-23-6 Open access to the Proceedings of the 2021 USENIX Annual Technical Conference is sponsored by USENIX. MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices Lujia Yin Li Wang Yiming Zhang [email protected] [email protected] [email protected] (Corresponding) NUDT Didi Chuxing NiceX Lab, NUDT Yuxing Peng [email protected] NUDT Abstract replicas on SSDs and replicates backup replicas on HDDs; and SSHD [28] integrates a small SSD inside a large HDD DM-cache is a component of the device mapper of Linux of which the SSD acts as a cache. kernel, which has been widely used to map SSDs and HDDs As the demand of HDD-SSD hybrid storage increases, onto higher-level virtual block devices that take fast SSDs as Linux kernel has supported users to combine HDDs and a cache for slow HDDs to achieve high I/O performance at SSDs to jointly provide virtual block storage service. DM- low monetary cost. While enjoying the benefit of persistent cache [5] is a component of the device mapper [4] in the caching where SSDs accelerate normal I/O without affecting kernel, which has been widely used in industry to map SSDs durability, the current design of DM-cache suffers from and HDDs onto higher-level virtual block devices that take long crash recovery times (at the scale of hours) and low fast SSDs as a cache for slow HDDs. -

Fast and Live Hypervisor Replacement
Fast and Live Hypervisor Replacement Spoorti Doddamani Piush Sinha Hui Lu Binghamton University Binghamton University Binghamton University New York, USA New York, USA New York, USA [email protected] [email protected] [email protected] Tsu-Hsiang K. Cheng Hardik H. Bagdi Kartik Gopalan Binghamton University Binghamton University Binghamton University New York, USA New York, USA New York, USA [email protected] [email protected] [email protected] Abstract International Conference on Virtual Execution Environments (VEE Hypervisors are increasingly complex and must be often ’19), April 14, 2019, Providence, RI, USA. ACM, New York, NY, USA, updated for applying security patches, bug fixes, and feature 14 pages. https://doi.org/10.1145/3313808.3313821 upgrades. However, in a virtualized cloud infrastructure, up- 1 Introduction dates to an operational hypervisor can be highly disruptive. Before being updated, virtual machines (VMs) running on Virtualization-based server consolidation is a common prac- a hypervisor must be either migrated away or shut down, tice in today’s cloud data centers [2, 24, 43]. Hypervisors host resulting in downtime, performance loss, and network over- multiple virtual machines (VMs), or guests, on a single phys- head. We present a new technique, called HyperFresh, to ical host to improve resource utilization and achieve agility transparently replace a hypervisor with a new updated in- in resource provisioning for cloud applications [3, 5–7, 50]. stance without disrupting any running VMs. A thin shim Hypervisors must be often updated or replaced for various layer, called the hyperplexor, performs live hypervisor re- purposes, such as for applying security/bug fixes [23, 41] placement by remapping guest memory to a new updated adding new features [15, 25], or simply for software reju- hypervisor on the same machine. -

(12) United States Patent (10) Patent No.: US 8,124,082 B2 Fong Et Al
USOO8124082B2 (12) United States Patent (10) Patent No.: US 8,124,082 B2 Fong et al. (45) Date of Patent: Feb. 28, 2012 (54) HUMANIZED ANTI-BETA7 ANTAGONISTS 3.68 A 13 3. SEetC ren al. et al.1 AND USES THEREFOR 5,624,821 A 4/1997 Winter et al. 5,648,260 A 7, 1997 Winter et al. (75) Inventors: Sherman Fong, Alameda, CA (US); 5,658,727 A 8, 1997 Barbas et al. Mark S. Dennis, San Carlos, CA (US) 5,693,762 A 12/1997 Queen et al. 5,712.374. A 1/1998 Kuntsmann et al. 5,714,586 A 2, 1998 Kunstmann et al. (73) Assignee: Genentech, Inc., South San Francisco, 5,731, 168 A 3, 1998 Carter et al. CA (US) 5,733,743 A 3/1998 Johnson et al. 5,739,116 A 4, 1998 Hamann et al. (*) Notice: Subject to any disclaimer, the term of this 5,750,373 A 5/1998 Garrard et al. patent is extended or adjusted under 35 5,767.285 A 6/1998 Hamann et al. U.S.C. 154(b) by 119 days 5,770,701 A 6/1998 McGahren et al. M YW- y yS. 5,770,710 A 6/1998 McGahren et al. 5,773,001 A 6/1998 Hamann et al. (21) Appl. No.: 12/390,730 5,837.242 A 1 1/1998 Holliger et al. 5,877,296 A 3, 1999 Hamann et al. (22) Filed: Feb. 23, 2009 5,969,108 A 10/1999 McCafferty et al. 9 6,172,197 B1 1/2001 McCafferty et al. -

Instant OS Updates Via Userspace Checkpoint-And
Instant OS Updates via Userspace Checkpoint-and-Restart Sanidhya Kashyap, Changwoo Min, Byoungyoung Lee, and Taesoo Kim, Georgia Institute of Technology; Pavel Emelyanov, CRIU and Odin, Inc. https://www.usenix.org/conference/atc16/technical-sessions/presentation/kashyap This paper is included in the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16). June 22–24, 2016 • Denver, CO, USA 978-1-931971-30-0 Open access to the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16) is sponsored by USENIX. Instant OS Updates via Userspace Checkpoint-and-Restart Sanidhya Kashyap Changwoo Min Byoungyoung Lee Taesoo Kim Pavel Emelyanov† Georgia Institute of Technology †CRIU & Odin, Inc. # errors # lines Abstract 50 1000K 40 100K In recent years, operating systems have become increas- 10K 30 1K 20 ingly complex and thus more prone to security and per- 100 formance issues. Accordingly, system updates to address 10 10 these issues have become more frequently available and 0 1 increasingly important. To complete such updates, users 3.13.0-x 3.16.0-x 3.19.0-x May 2014 must reboot their systems, resulting in unavoidable down- build/diff errors #layout errors Jun 2015 time and further loss of the states of running applications. #static local errors #num lines++ We present KUP, a practical OS update mechanism that Figure 1: Limitation of dynamic kernel hot-patching using employs a userspace checkpoint-and-restart mechanism, kpatch. Only two successful updates (3.13.0.32 34 and → which uses an optimized data structure for checkpoint- 3.19.0.20 21) out of 23 Ubuntu kernel package releases. -

Dm-Cache.Pdf
DM-Cache Marc Skinner Principal Solutions Architect Twin Cities Users Group :: Q1/2016 Why Cache? ● Spinning disks are slow! ● Solid state disks (SSD) are fast!! ● Non-Volatile Memory Express (NVMe) devices are insane!!! Why not? ● Hybrid drives make 5900rpm drives act like 7200rpm drives with very small on board SSD cache ● Hmm, talk to FAST and move to SLOW? FAST SLOW Linux Caching Options ● DM-Cache ● Oldest and most stable. Developed in 2006 by IBM research group, and merged into Linux kernel tree in version 3.9. Uses the device-mapper framework to cache a slower device ● FlashCache ● Kernel module inspired by dm-cache and developed/maintained by Facebook. Also uses the device-mapper framework. ● EnhanceIO, RapidCache ● Both variations of FlashCache ● BCache ● Newest option and does not rely on device-mapper framework DM-Cache Modes ● write-through ● Red Hat default ● Write requests are not returned until the data reaches the origin and the cache device ● write-back ● Writes go only to the cache device ● pass-through ● Used to by pass the cache, used if cache is corrupt DM-Cache Setup ● Enable discards first # vi /etc/lvm/lvm.conf issue_discards = 1 # dracut -f # sync # reboot DM-Cache Setup ● Create PV, VG and LV with Cache # pvcreate /dev/md2 (raid 10 - 6 x 250gb SSD) # pvcreate /dev/md3 (raid 10 - 6 x 2tb SATA) # vgcreate vg_iscsi /dev/md3 /dev/md2 # lvcreate -l 100%FREE -n lv_sata vg_iscsi /dev/md3 # lvcreate -L 5G -n lv_cache_meta vg_iscsi /dev/md2 # lvcreate -L 650G -n lv_cache vg_iscsi /dev/md2 # lvconvert --type cache-pool