The Effects of SSD Caching on the I/O Performance of Unified Storage Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 7 7.1 Release Notes
Red Hat Enterprise Linux 7 7.1 Release Notes Release Notes for Red Hat Enterprise Linux 7 Red Hat Customer Content Services Red Hat Enterprise Linux 7 7.1 Release Notes Release Notes for Red Hat Enterprise Linux 7 Red Hat Customer Content Services Legal Notice Copyright © 2015 Red Hat, Inc. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

Speeding up Linux Disk Encryption Ignat Korchagin @Ignatkn $ Whoami
Speeding Up Linux Disk Encryption Ignat Korchagin @ignatkn $ whoami ● Performance and security at Cloudflare ● Passionate about security and crypto ● Enjoy low level programming @ignatkn Encrypting data at rest The storage stack applications @ignatkn The storage stack applications filesystems @ignatkn The storage stack applications filesystems block subsystem @ignatkn The storage stack applications filesystems block subsystem storage hardware @ignatkn Encryption at rest layers applications filesystems block subsystem SED, OPAL storage hardware @ignatkn Encryption at rest layers applications filesystems LUKS/dm-crypt, BitLocker, FileVault block subsystem SED, OPAL storage hardware @ignatkn Encryption at rest layers applications ecryptfs, ext4 encryption or fscrypt filesystems LUKS/dm-crypt, BitLocker, FileVault block subsystem SED, OPAL storage hardware @ignatkn Encryption at rest layers DBMS, PGP, OpenSSL, Themis applications ecryptfs, ext4 encryption or fscrypt filesystems LUKS/dm-crypt, BitLocker, FileVault block subsystem SED, OPAL storage hardware @ignatkn Storage hardware encryption Pros: ● it’s there ● little configuration needed ● fully transparent to applications ● usually faster than other layers @ignatkn Storage hardware encryption Pros: ● it’s there ● little configuration needed ● fully transparent to applications ● usually faster than other layers Cons: ● no visibility into the implementation ● no auditability ● sometimes poor security https://support.microsoft.com/en-us/help/4516071/windows-10-update-kb4516071 @ignatkn Block -

Operating System Support for Redundant Multithreading
Operating System Support for Redundant Multithreading Dissertation zur Erlangung des akademischen Grades Doktoringenieur (Dr.-Ing.) Vorgelegt an der Technischen Universität Dresden Fakultät Informatik Eingereicht von Dipl.-Inf. Björn Döbel geboren am 17. Dezember 1980 in Lauchhammer Betreuender Hochschullehrer: Prof. Dr. Hermann Härtig Technische Universität Dresden Gutachter: Prof. Frank Mueller, Ph.D. North Carolina State University Fachreferent: Prof. Dr. Christof Fetzer Technische Universität Dresden Statusvortrag: 29.02.2012 Eingereicht am: 21.08.2014 Verteidigt am: 25.11.2014 FÜR JAKOB *† 15. Februar 2013 Contents 1 Introduction 7 1.1 Hardware meets Soft Errors 8 1.2 An Operating System for Tolerating Soft Errors 9 1.3 Whom can you Rely on? 12 2 Why Do Transistors Fail And What Can Be Done About It? 15 2.1 Hardware Faults at the Transistor Level 15 2.2 Faults, Errors, and Failures – A Taxonomy 18 2.3 Manifestation of Hardware Faults 20 2.4 Existing Approaches to Tolerating Faults 25 2.5 Thesis Goals and Design Decisions 36 3 Redundant Multithreading as an Operating System Service 39 3.1 Architectural Overview 39 3.2 Process Replication 41 3.3 Tracking Externalization Events 42 3.4 Handling Replica System Calls 45 3.5 Managing Replica Memory 49 3.6 Managing Memory Shared with External Applications 57 3.7 Hardware-Induced Non-Determinism 63 3.8 Error Detection and Recovery 65 4 Can We Put the Concurrency Back Into Redundant Multithreading? 71 4.1 What is the Problem with Multithreaded Replication? 71 4.2 Can we make Multithreading -

Communicating Between the Kernel and User-Space in Linux Using Netlink Sockets
SOFTWARE—PRACTICE AND EXPERIENCE Softw. Pract. Exper. 2010; 00:1–7 Prepared using speauth.cls [Version: 2002/09/23 v2.2] Communicating between the kernel and user-space in Linux using Netlink sockets Pablo Neira Ayuso∗,∗1, Rafael M. Gasca1 and Laurent Lefevre2 1 QUIVIR Research Group, Departament of Computer Languages and Systems, University of Seville, Spain. 2 RESO/LIP team, INRIA, University of Lyon, France. SUMMARY When developing Linux kernel features, it is a good practise to expose the necessary details to user-space to enable extensibility. This allows the development of new features and sophisticated configurations from user-space. Commonly, software developers have to face the task of looking for a good way to communicate between kernel and user-space in Linux. This tutorial introduces you to Netlink sockets, a flexible and extensible messaging system that provides communication between kernel and user-space. In this tutorial, we provide fundamental guidelines for practitioners who wish to develop Netlink-based interfaces. key words: kernel interfaces, netlink, linux 1. INTRODUCTION Portable open-source operating systems like Linux [1] provide a good environment to develop applications for the real-world since they can be used in very different platforms: from very small embedded devices, like smartphones and PDAs, to standalone computers and large scale clusters. Moreover, the availability of the source code also allows its study and modification, this renders Linux useful for both the industry and the academia. The core of Linux, like many modern operating systems, follows a monolithic † design for performance reasons. The main bricks that compose the operating system are implemented ∗Correspondence to: Pablo Neira Ayuso, ETS Ingenieria Informatica, Department of Computer Languages and Systems. -

DM-Relay - Safe Laptop Mode Via Linux Device Mapper
' $ DM-Relay - Safe Laptop Mode via Linux Device Mapper Study Thesis by cand. inform. Fabian Franz at the Faculty of Informatics Supervisor: Prof. Dr. Frank Bellosa Supervising Research Assistant: Dipl.-Inform. Konrad Miller Day of completion: 04/05/2010 &KIT – Universitat¨ des Landes Baden-Wurttemberg¨ und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu % I hereby declare that this thesis is my own original work which I created without illegitimate help by others, that I have not used any other sources or resources than the ones indicated and that due acknowledgment is given where reference is made to the work of others. Karlsruhe, April 5th, 2010 Contents Deutsche Zusammenfassung xi 1 Introduction 1 1.1 Problem Definition . .1 1.2 Objectives . .1 1.3 Methodology . .1 1.4 Contribution . .2 1.5 Thesis Outline . .2 2 Background 3 2.1 Problems of Disk Power Management . .3 2.2 State of the Art . .4 2.3 Summary of this chapter . .8 3 Analysis 9 3.1 Pro and Contra . .9 3.2 A new approach . 13 3.3 Analysis of Proposal . 15 3.4 Summary of this chapter . 17 4 Design 19 4.1 Common problems . 19 4.2 System-Design . 21 4.3 Summary of this chapter . 21 5 Implementation of a dm-module for the Linux kernel 23 5.1 System-Architecture . 24 5.2 Log suitable for Flash-Storage . 28 5.3 Using dm-relay in practice . 31 5.4 Summary of this chapter . 31 vi Contents 6 Evaluation 33 6.1 Methodology . 33 6.2 Benchmarking setup . -

SUSE Linux Enterprise Server 15 SP2 Autoyast Guide Autoyast Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 AutoYaST Guide AutoYaST Guide SUSE Linux Enterprise Server 15 SP2 AutoYaST is a system for unattended mass deployment of SUSE Linux Enterprise Server systems. AutoYaST installations are performed using an AutoYaST control le (also called a “prole”) with your customized installation and conguration data. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents 1 Introduction to AutoYaST 1 1.1 Motivation 1 1.2 Overview and Concept 1 I UNDERSTANDING AND CREATING THE AUTOYAST CONTROL FILE 4 2 The AutoYaST Control -
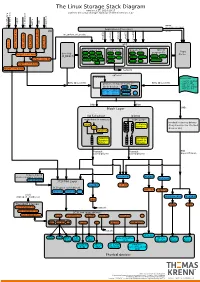
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Effective Cache Apportioning for Performance Isolation Under
Effective Cache Apportioning for Performance Isolation Under Compiler Guidance Bodhisatwa Chatterjee Sharjeel Khan Georgia Institute of Technology Georgia Institute of Technology Atlanta, USA Atlanta, USA [email protected] [email protected] Santosh Pande Georgia Institute of Technology Atlanta, USA [email protected] Abstract cache partitioning to divide the LLC among the co-executing With a growing number of cores per socket in modern data- applications in the system. Ideally, a cache partitioning centers where multi-tenancy of a diverse set of applications scheme obtains overall gains in system performance by pro- must be efficiently supported, effective sharing of the last viding a dedicated region of cache memory to high-priority level cache is a very important problem. This is challenging cache-intensive applications and ensures security against because modern workloads exhibit dynamic phase behaviour cache-sharing attacks by the notion of isolated execution in - their cache requirements & sensitivity vary across different an otherwise shared LLC. Apart from achieving superior execution points. To tackle this problem, we propose Com- application performance and improving system throughput CAS, a compiler guided cache apportioning system that pro- [7, 20, 31], cache partitioning can also serve a variety of pur- vides smart cache allocation to co-executing applications in a poses - improving system power and energy consumption system. The front-end of Com-CAS is primarily a compiler- [6, 23], ensuring fairness in resource allocation [26, 36] and framework equipped with learning mechanisms to predict even enabling worst case execution-time analysis of real-time cache requirements, while the backend consists of allocation systems [18]. -

A Hybrid Swapping Scheme Based on Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018)
Received August 19, 2018, accepted September 14, 2018, date of publication October 1, 2018, date of current version October 25, 2018. Digital Object Identifier 10.1109/ACCESS.2018.2872794 A Hybrid Swapping Scheme Based On Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018) JUNYEONG HAN 1, SUNGEUN KIM1, SUNGYOUNG LEE1, JAEHWAN LEE2, AND SUNG JO KIM2 1LG Electronics, Seoul 07336, South Korea 2School of Software, Chung-Ang University, Seoul 06974, South Korea Corresponding author: Sung Jo Kim ([email protected]) This work was supported in part by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education under Grant 2016R1D1A1B03931004 and in part by the Chung-Ang University Research Scholarship Grants in 2015. ABSTRACT As a way to increase the actual main memory capacity of Android smartphones, most of them make use of zRAM swapping, but it has limitation in increasing its capacity since it utilizes main memory. Unfortunately, they cannot use secondary storage as a swap space due to the long response time and wear-out problem. In this paper, we propose a hybrid swapping scheme based on per-process reclaim that supports both secondary-storage swapping and zRAM swapping. It attempts to swap out all the pages in the working set of a process to a zRAM swap space rather than killing the process selected by a low-memory killer, and to swap out the least recently used pages into a secondary storage swap space. The main reason being is that frequently swap- in/out pages use the zRAM swap space while less frequently swap-in/out pages use the secondary storage swap space, in order to reduce the page operation cost. -

Mellanox Linux Switch †
SOFTWARE PRODUCT BRIEF Mellanox Linux Switch † – Taking Open Ethernet to the next level, Mellanox Linux Switch provides users with the ability to deploy any standard Linux operating HIGHLIGHTS system on their switch devices – Mellanox Linux Switch enables users to natively install and use any standard Linux distribution as • 100% free open source software the switch operating system on the Open Ethernet Mellanox Spectrum® switch platforms. Mellanox Linux Switch is based on Switchdev, a Linux kernel driver model for Ethernet switches. Mellanox is • L2/L3 switch system as standard Linux the first switch vendor to embrace this model by implementing the switchdev driver for its Mellanox server Spectrum switches. This revolutionary concept breaks the dependency of using vendor-specific • Uniform Linux interfaces software development kits (SDK). Instead of proprietary APIs, fully standard Linux kernel interfaces are used to control the switch chip. This allows users to natively install and use any standard Linux • Fully supported by the Linux distribution as the switch operating system, while the switchdev driver ensures all network traffic is community seamlessly offloaded to the switch hardware. • Hardware independent abstraction layer Openness and Freedom • User choice of Linux operating The 100% free open-source Mellanox switchdev driver is developed and maintained as part of the systems and network applications Linux kernel and is promoted by the Linux community. There is no longer a need for closed code from switch vendors, no more binary blobs, and no need to sign a service level agreement (SLA). • Industry’s highest performance switch systems portfolio, including the high- Linux Switch provides users the flexibility to customize and optimize the switch to their exact needs density half-width Mellanox SN2100 without paying for expensive proprietary software that includes features they neither need nor will never use. -

Sbadmin Device-Mapper Multipath Devices
DM-Multipath Guide Version 8.2 SBAdmin and DM-Multipath Guide The purpose of this guide is to provide the steps necessary to use SBAdmin in an environment where SAN storage is used in conjunction with device-mapper multipath devices. When a system is using dm-multipath devices, there are several considerations that need to be addressed. The device naming, tools available, and device modules loaded become critical issues in discovery of devices and recreation of those devices upon restore. The information in this guide should provide the necessary information to create backups from systems using dm-multipath devices or for users who want to migrate a system backup to multipath devices. This guide is not intended to assist users in the initial setup of dm-multipath devices. For information on initially setting up dm-multipath devices, contact your Linux OS support vendors directly. Requirements for DM-Multipath support Software requirements Support for dm-multipath devices has been available to Linux users for years, however, how the devices are created and supported by distributions has changed greatly over time as the technology matures. Below is the minimal level of the tools and file sets that SBAdmin has tested and will support. dm-multipath-tools version 0.4.5 (also known as device-mapper-multipath) device-mapper version 1.02 udev version 039-10 Device detection requirements Device naming If you plan on creating backups from a system using dm-multipath devices, the SBAdmin software must be able to recognize the devices by name prior to creating the backup. Multipath devices can be named several different ways such as by the World Wide Identifier (WWID), dm-[0-9], mpath[a-z], and mpath[0-9]. -

Project-Team REGAL
IN PARTNERSHIP WITH: CNRS Université Pierre et Marie Curie (Paris 6) Activity Report 2013 Project-Team REGAL Large-Scale Distributed Systems and Applications IN COLLABORATION WITH: Laboratoire d’informatique de Paris 6 (LIP6) RESEARCH CENTER Paris - Rocquencourt THEME Distributed Systems and middleware Table of contents 1. Members :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 2. Overall Objectives :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 2.1. Overall Objectives2 2.2. Highlights of the Year2 3. Research Program :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 3.1.1. Modern computer systems are increasingly parallel and distributed.3 3.1.2. Multicore architectures are everywhere.3 4. Software and Platforms ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 4.1. Coccinelle 4 4.2. SwiftCloud 4 4.3. JESSY 4 4.4. Java and .Net runtimes for LLVM5 5. New Results :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 5 5.1. Introduction 5 5.2. Distributed algorithms for dynamic networks5 5.2.1. Mutual Exclusion and Failure Detection.6 5.2.2. Self-Stabilization and Self-* Services.6 5.2.3. Dissemination and Data Finding in Large Scale Systems.6 5.2.4. Peer certification.7 5.3. Management of distributed data7 5.3.1. Long term durability7 5.3.2. Adaptative replication8 5.3.3. Strong consistency8 5.3.4. Distributed Transaction Scheduling9 5.3.5. Eventual consistency9 5.3.6. Mixing commutative and non-commutative updates: reservations9 5.4. Performance and Robustness of Systems Software in Multicore Architectures 10 5.4.1. Managed Runtime Environments 10 5.4.2. System software robustness 10 5.4.3. Domain-specific languages for systems software 11 6. Bilateral Contracts and Grants with Industry ::::::::::::::::::::::::::::::::::::::::::::: 11 6.1. Bilateral Contracts with Industry 11 6.2. Bilateral Grants with Industry 11 7.