University of Florida Thesis Or Dissertation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CPTM Forma Técnicos Em Manutenção Metroferroviária
Poder Executivo seção II Estado de São Paulo Geraldo Alckmin - Governador Palácio dos Bandeirantes • Av. Morumbi 4.500 • Morumbi • São Paulo • CEP 05650-000 • Tel. 2193-8000 Volume 127 • Número 196 • São Paulo, quinta-feira, 19 de outubro de 2017 www.imprensaofi cial.com.br CPTM forma técnicos em manutenção metroferroviária possibilidade de o aluno aprendiz boa parte fez curso técnico e de aprendizado ser contratado como profissional é no Senai”, menciona o diretor. A um dos atrativos do curso Técnico de Manutenção de Sistemas Metro- Guilherme (ao Teoria e prática – Na Via Perma- ferroviários. Ministrado no Centro lado do instrutor nente Didática há “treino de rede aérea de Formação Profissional Eng° James Cândido): “Ser (não energizada), que é baixa para facilitar C. Stewart, é mantido pela Compa- efetivado na CPTM a observação de detalhes”, informa o dire- FOTOS: GENIVALDO CARVALHO FOTOS: GENIVALDO nhia Paulista de Trens Metropoli- é meu objetivo” tor. Há trilhos com dormentes de madeira tanas (CPTM), em convênio com o e de concreto na via de 1,60 metro de bitola. Senai-SP. “O curso oferece formação “É para aprenderem as particularidades das muito específica – em São Paulo é o seis linhas da CPTM”. A Estação Ferroviária único curso de técnico em manuten- Didática serve para mostrar “o funcionamen- ção metroferroviária. Por isso, tem to da linha de bloqueio (catraca), sistemas uma concorrência gigantesca”, des- envolvidos na operação e segurança, além taca o diretor do Centro de For ma- de outros recursos disponíveis nas estações”. ção, Wilson Sanches. Há também vários laboratórios (hidráu- lica, pneumática, soldagem) usados para Três mil alunos já “ensaios técnicos e aplicação de conceitos”, diz Sanches. -

Relatório De Acompanhamento 2 – Diagnóstico Municipal
Relatório de Acompanhamento 2 – Diagnóstico municipal Objeto: Plano de Mobilidade de Caieiras (SP) – PlanMob Caieiras Número do contrato : Nº 106/2016 Número do processo de licitação: Tomada de Preços Nº 001/15, PM nº 481/2015 PREFEITURA MUNICIPAL DE CAIEIRAS São Paulo Setembro/2017 Rua Paulistânia, 154 Inteligência Territorial Vila Madalena - São Paulo - SP Planejamento Estratégico CEP 05440-000 - Brasil Gestão Ambiental Tel. +55 11 3034-1490 geobrasilis.com.br São Paulo, 11 de Setembro de 2017. Prefeitura do Município de Caieiras A/C Sr. Sidnei Moraes e Sr. Rodrigo Nery Santiago Referência: Plano de Mobilidade de Caieiras – PlanMob Caieiras Encaminhamos à V.Sas. o diagnóstico municipal focado em mobilidade e desenvolvimento urbano de Caieiras, que será utilizado como um dos elementos para a definição de propostas para a Política Municipal de Mobilidade, após a validação em audiência pública. Esperamos que este documento contenha todas as informações requeridas por V.Sa. e permanecemos à disposição para prestar quaisquer esclarecimentos que se façam necessários. Atenciosamente, Rua Paulistânia, 154 Inteligência Territorial Vila Madalena - São Paulo - SP Planejamento Estratégico CEP 05440-000 - Brasil Gestão Ambiental Tel. +55 11 3034-1490 geobrasilis.com.br | 2 SUMÁRIO 1. APRESENTAÇÃO ........................................................................................................ 12 2. SÍNTESE DO DIAGNÓSTICO ........................................................................................ 13 3. ASPECTOS GERAIS DE CAIEIRAS -

Nomenclatura Das Estações Da CPTM – Metodologia Para Escolha De Nome, Custos E As Consequências De Sua Alteração
22ª SEMANA DE TECNOLOGIA METROFERROVIÁRIA 3º PRÊMIO TECNOLOGIA E DESENVOLVIMENTO METROFERROVIÁRIOS CATEGORIA 1 Nomenclatura das estações da CPTM – Metodologia para escolha de nome, custos e as consequências de sua alteração INTRODUÇÃO A Companhia Paulista de Trens Metropolitanos - CPTM que, atualmente, tem uma extensão operacional de 258,55 km, conta com 6 linhas de trens e 92 estações distribuídas em 22 municípios, sendo que 19 delas situam-se na Região Metropolitana de São Paulo. Das seis linhas, três possuem extensões por motivo de estratégia operacional. Na Linha 7-Rubi, que liga a Estação Luz à Estação Jundiaí, tem a extensão operacional entre as estações Francisco Morato e Jundiaí, Na Linha 8-Diamante, que liga a Estação Júlio Prestes à Estação Amador Bueno, tem a extensão operacional entre as estações Itapevi e Amador Bueno e, a Linha 11-Coral está dividida em dois trechos: o Expresso Leste ligando a Estação Luz até a Estação Guaianases e a extensão ligando a estação Guaianases à estação Estudantes. 1 No início do ano de 2000 a empresa iniciou além do processo de aquisição de novos trens, a modernização e reforma das estações existentes. Esse projeto teve a finalidade de ampliar sua capacidade de transporte para melhor atender à população. Além da modernização, foram construídas novas estações e outras estão sendo implantadas em novos segmentos e novos serviços a serem oferecidos pela CPTM. Os nomes das estações são, primeiramente, ferramentas essenciais de informação que permitem aos usuários orientarem-se facilmente graças à identificação de pontos de início, final ou de integração de viagens. São elementos indispensáveis na utilização da rede e na programação de um deslocamento. -

Cptm Dez2010
COMPANHIA PAULISTA DE TRENS METROPOLITANOS RELAÇÃO DE EMPREGADOS - DEZ/2010 MATRÍCULA NOME ADMISSÃO CARGO SALÁRIO ORGLOT DESCRIÇÃO SIGLA 92.005.103-0 ABEDNEGO BATISTA DO NASCIMENTO 27/06/2005 ELETRICISTA MANUTENCAO I 1864,98 1015261005 REDE AEREA 7/10 - MAUA DOFE 92.003.811-5 ABIGAIL DINIZ FREIRE MONTEIRO 19/01/1998 AGENTE SEGURANCA OPER 1801,89 1016321210 GRUPAMENTO LINHA 10 - BASE MAUA DOSV 92.004.678-9 ABIGAIL PASSOS SANTOS DE OLIVEIRA 30/06/2000 AGENTE OPERACIONAL I 1606,39 1016630050 ESTACAO MAUA DOED 92.000.554-3 ABILIO DOS SANTOS SILVA 06/06/1984 ASSIST TEC EXECUT I 8002,62 1015375000 EQUIPE CONTROLE E SUPRIMENTO DE MATERIAIS E TREINAMENTO DORO 92.004.030-6 ABNER AFONSO PADOVEZI 01/09/1998 TEC MANUTENCAO I 2643,34 1015360015 ABRIGO ENG SP CORRETIVA DORE 92.006.970-3 ABNER ORRA PEREIRA 01/03/2010 ALUNO APRENDIZ 510 1011711001 CENTRO DE FORMACAO PROFISSIONAL/APRENDIZES DRHT 92.006.842-1 ABRAAO JOSE MASALA DOS SANTOS 28/09/2009 ELETRICISTA MANUTENCAO I 1786,18 1015273011 SINALIZACAO PREVENTIVA BRAS DOFS 92.006.531-7 ABRAAO MOURA DE HOLANDA 25/05/2009 MAQUINISTA 2091,9 1016222005 MOVIMENTO DE TRENS 8/9-BARRA FUNDA DOCC 92.007.263-1 ABRAHAO BALDINO 01/06/2010 MAQUINISTA 2091,9 1016222005 MOVIMENTO DE TRENS 8/9-BARRA FUNDA DOCC 92.003.455-1 ABRAHAO FERREIRA DE OLIVEIRA 23/06/1997 CONT CIRC TRENS II 6H 3212,18 1016212005 CONTROLE DE TRAFEGO-CCO 8/9 DOCP 92.000.819-4 ACIB MARIONI ABIB 03/11/1983 ENCARREGADO ESTACAO 2428,63 1016630045 ESTACAO CAPUAVA DOED 92.004.250-3 ADAILTO RODRIGUES DE SOUZA 01/12/1998 ENCARREGADO MANUTENCAO 2428,63 -

Artigo Trata Da Proposição De Um Zoneamento Para a Malha Ferroviária Da Região
25ª SEMANA DE TECNOLOGIA METROFERROVIÁRIA 6º PRÊMIO TECNOLOGIA E DESENVOLVIMENTO METROFERROVIÁRIOS CATEGORIA: 1 TÍTULO: ZONEAMENTO TERRITORIAL DA FAIXA FERROVIÁRIA INTRODUÇÃO Este artigo trata da proposição de um zoneamento para a malha ferroviária da Região Metropolitana de São Paulo – RMSP, desenvolvido sob a perspectiva da gestão territorial da Companhia Paulista de Trens Metropolitanos – CPTM, de forma a subsidiar as estratégias da empresa nas tomadas de decisões quanto ao uso e gestão dos espaços ferroviários e na articulação institucional com agentes públicos e privados atuantes em sua área de influência. A CPTM é gestora de um território predominantemente linear com 273 quilômetros de extensão, que se estende por 23 municípios na Região Metropolitana de São Paulo e Aglomeração Urbana de Jundiaí, abrangendo cerca de 11,5 milhões de m². São 94 estações, 04 complexos de manutenção e inúmeras instalações e unidades de apoio que garantem o transporte de cerca de 3 milhões de pessoas por dia útil. Seu território é compartilhado com áreas da União destinadas ao transporte de cargas, e compreende também uma infinidade de usos não ferroviários, tais como residências, áreas comerciais e institucionais cedidas à terceiros, redes de infraestruturas aéreas e subterrâneas, viadutos, túneis e passarelas, além de diversos focos de invasões por habitações precárias. 1 25ª SEMANA DE TECNOLOGIA METROFERROVIÁRIA 6º PRÊMIO TECNOLOGIA E DESENVOLVIMENTO METROFERROVIÁRIOS Ao longo das suas 07 linhas em operação, o território da CPTM está em permanente interação com os diversos agentes públicos e privados que ocupam ou respondem pela gestão de seu entorno, lançando seus projetos sobre a faixa ferroviária, requisitando áreas para requalificação urbana e implantação de novas infraestruturas e equipamentos, disputando ou convergindo interesses quanto ao uso do espaço urbano. -

Cptm Dez2012
COMPANHIA PAULISTA DE TRENS METROPOLITANOS - CPTM RELAÇÃO DE EMPREGADOS - DEZ/2012 MATRÍCULA NOME ADMISSÃO CARGO SALÁRIO ORGLOT DESCRIÇÃO SIGLA 92.008.674-8 ABDALLA TAIAR JUNIOR 25/06/2012 ASSESSOR TEC EXECUT I 8.302,93 1012410000 DEPTO DE LOGISTICA ADMINISTRATIVA DFAL 92.005.103-0 ABEDNEGO BATISTA DO NASCIMENTO 27/06/2005 ELETRICISTA MANUTENCAO I 2.125,83 1015261005 REDE AEREA 7/10 - MAUA DOFE 92.007.902-4 ABELITO PEREIRA DA CONCEICAO 29/12/2010 MAQUINISTA 2.384,49 1016221006 MOVIMENTO DE TRENS 7/10-FCO MORATO DOCC 92.003.811-5 ABIGAIL DINIZ FREIRE 19/01/1998 AGENTE SEGURANCA OPER 2.053,92 1016321210 GRUPAMENTO LINHA 10 - BASE MAUA DOSV 92.004.678-9 ABIGAIL PASSOS SANTOS DE OLIVEIRA 30/06/2000 AGENTE OPERACIONAL I 1.831,08 1016630050 ESTACAO MAUA DOED 92.000.554-3 ABILIO DOS SANTOS SILVA 06/06/1984 CHEFE DE DEPARTAMENTO 10.432,35 1015420000 DEPTO DE ENG DE MANUT DE MATERIAL RODANTE DOTM 92.004.030-6 ABNER AFONSO PADOVEZI 01/09/1998 TEC MANUTENCAO I 3.039,59 1015360015 ABRIGO ENG SP CORRETIVA DORE 92.008.296-3 ABNER ORRA PEREIRA 13/09/2011 ELETRICISTA MANUTENCAO I 2.053,92 1015273021 SINALIZACAO PREVENTIVA CALMON VIANA DOFS 92.006.842-1 ABRAAO JOSE MASALA DOS SANTOS 28/09/2009 ELETRICISTA MANUTENCAO I 2.053,92 1015273011 SINALIZACAO PREVENTIVA BRAS DOFS 92.006.531-7 ABRAAO MOURA DE HOLANDA 25/05/2009 MAQUINISTA 2.384,49 1016221005 MOVIMENTO DE TRENS 7/10-LUZ DOCC 92.003.455-1 ABRAHAO FERREIRA DE OLIVEIRA 23/06/1997 CONT CIRC TRENS II 3.693,69 1016212005 CONTROLE DE TRAFEGO-CCO 8/9 DOCP 92.000.819-4 ACIB MARIONI ABIB 03/11/1983 ENCARREGADO -

Gestão De Processos De Inundação, Enchente E
25ª SEMANA DE TECNOLOGIA METROFERROVIÁRIA 6º PRÊMIO TECNOLOGIA E DESENVOLVIMENTO METROFERROVIÁRIOS CATEGORIA: 2 TÍTULO: GESTÃO DE PROCESSOS DE INUNDAÇÃO, ENCHENTE E MOVIMENTAÇÃO DE SOLO NA FERROVIA INTRODUÇÃO Este artigo tem como objetivo apresentar uma proposta de gestão de eventos geodinâmicos, tais como inundação, enchente e movimentação de solo, para o sistema ferroviário operado pela Companhia Paulista de Trens Metropolitanos - CPTM, por meio de utilização de ferramenta SIG e banco de dados corporativo. A ocorrência de eventos geodinâmicos, principalmente, dos processos de inundação, enchente e movimentação de solo na Região Metropolitana de São Paulo (RMSP) possui expressiva relevância na atividade ferroviária uma vez que impacta de forma significativa a operação e circulação de trens, incorrendo em paralisação e redução dos serviços de transporte ofertados, perda de receita, elevados custos na atuação das ocorrências, danos à equipamentos e materiais, riscos aos usuários, funcionários e comunidade lindeira, e prejuízo à confiabilidade do serviço e à imagem da companhia. Ao longo dos anos o tema vem sendo tratado pela companhia apenas de forma reativa, pontual e descentralizada, com isso, as soluções adotadas, muitas vezes, não se mostram efetivas ao longo do tempo, implicando no retorno/recorrência dos eventos. 1 25ª SEMANA DE TECNOLOGIA METROFERROVIÁRIA 6º PRÊMIO TECNOLOGIA E DESENVOLVIMENTO METROFERROVIÁRIOS Este trabalho apresenta uma inovação na gestão do tema para a companhia, por meio de utilização de ferramenta SIG para mapeamento e monitoramento de eventos desta natureza, de forma a organizar as ações e estabelecer uma atuação integrada, preventiva, racional e estratégica, envolvendo as diferentes áreas internas, bem como outros órgãos, entidades e instituições. -

Subprefeitura Pirituba/ Jaraguá
ANÁLISE TÉCNICA DA INFRAESTRUTURA CICLOVIÁRIA POR SUBPREFEITURA SUBPREFEITURA PIRITUBA/ JARAGUÁ ÍNDICE I. Introdução ao Planejamento Cicloviário do Município de São Paulo II. Caracterização da Subprefeitura de Pirituba 1. Estruturação do Planejamento Cicloviário e o processo de trabalho 2 2. Caracterização do Cenário Atual 15 1.1. Histórico do Planejamento Cicloviário 2 2.1. Histórico Local 15 43 1.2. O processo de trabalho para estruturação do Planejamento Cicloviário 2 2.2. Dados Censitários (2010) 15 1.2.1. Mapeamento dos estudos já realizados de infraestrutura cicloviaria 2.3. Viário de Pirituba-Jaraguá 16 no Município de São Paulo 3 2.4. Uso do Solo 20 1.2.2. Coleta de dados 3 2.5. Pontos de Atração de Viagens 20 1.2.2.1. Coleta de dados de intervenções viárias 3 2.6. Integração Modal 23 1.2.2.2. Coleta de dados estatísticos dos usuários de bicicletas 3 2.7. Panorama Cicloviário de Pirituba 24 1.3. Definição das diretrizes 5 2.8. Acidentes 24 1.3.1. Diretrizes da Rede Cicloviária 5 2.9. Demandas 29 1.3.2. Proposição da Rede Estrutural Cicloviária para o Município 5 1.4. Ações complementares 6 III: Definição das Ligações de Interesse Cicloviário 1.4.1. Processo de participação social 6 3. Ligações Cicloviárias na Subprefeitura de Perus 31 1.4.2. Oficinas de capacitação técnica 6 3.1. Avaliação urbanística atual da Subprefeitura de Pirituba 31 1.5. A implantação da infraestrutura cicloviária 7 3.2. Plano Diretor Estratégico 31 1.6. O processo de elaboração do Plano de Mobilidade 8 3.2.1. -

Infrastructure
BLUE BOOK INFRASTRUCTURE A RADIOGRAPHY OF INFRASTRUCTURE PROJECTS IN BRAZIL INDEX 1. Presentation 3 2. A look at the infrastructure 4 3. Brazil in numbers 8 4. Federal Government infrastructure projects 14 4.1 Federal Projects - Railroad 15 4.2 Federal Projects - Airports 17 4.3 Federal Projects - Highways 20 4.4 Federal Projects - Ports 24 4.5 Federal Projects - Electric Power 29 4.6 Federal Projects - Oil and Gas 30 5. Midwest Region 32 5.1 Distrito Federal 35 5.2 Goiás 41 5.3 Mato Grosso 46 5.4 Mato Grosso do Sul 50 6. Northeast Region 55 6.1 Alagoas 58 6.2 Bahia 63 6.3 Ceará 67 6.4 Maranhão 76 6.5 Paraiba 78 6.6 Pernambuco 84 6.7 Piauí 90 6.8 Rio Grande do Norte 97 6.9 Sergipe 102 7. North Region 108 7.1 Acre 111 7.2 Amapá 114 7.3 Amazonas 117 7.4 Pará 123 7.5 Rondônia 127 7.6 Roraima 130 7.7 Tocantins 133 8. Southeast Region 142 8.1 Espírito Santo 145 8.2 Minas Gerais 151 8.3 Rio de Janeiro 156 8.4 São Paulo 162 9. South Region 171 9.1 Paraná 174 9.2 Rio Grande do Sul 179 9.3 Santa Catarina 183 10. Federal and State investment projections: 2021 – 2025 189 11. Proposals to accelerate investments in infrastructure 195 12. Appendix 199 13. Notes 200 14. Bibliography 201 1. PRESENTATION he Brazilian Association of Infrastructure and Basic Industries T (ABDIB) holds this year, in a virtual model, the ABDIB Forum 2020 - Experience Edition, an annual event already consolidated in the sector as one of the biggest infrastructure events in the country. -
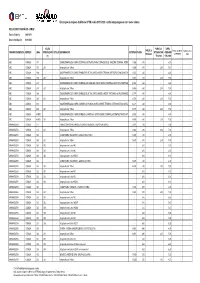
Rel.Tarifário Rmsp
Em função do reajuste do Metrô e CPTM no dia 01/01/2020 a tarifa integrada passa a ter novos valores. RELATÓRIO TARIFÁRIO - RMSP Data da Vigência: 20.01.2019 Data da Atualização: 03.01.2020 SEÇÃO/ PARCELA TARIFA PARCELA Ônibus com Metrô Complemento a CONSÓRCIO/EMPRESA SERVIÇO LINHA INTEGRAÇÃO CIRCULAR DENOMINAÇÃO EXTENSÃO TARIFA INTEGRAÇÃO + PEDÁGIO PEDÁGIO ou SPTRANS pagar (2) TRILHOS + TRILHOS ABC COMUM 195 - - SAO BERNARDO DO CAMPO (TERMINAL METROPOLITANO FERRAZOPOLIS)- DIADEMA (TERMINAL METROPOLITANO 13,096 PIRAPORIN 4,55HA) via SAO -BERNARDO DO - CAMPO (BAIRRO 4,55 DOS CASA) - - ABC COMUM 195 261 - Integração com Trilhos 13,096 4,55 - 2,90 7,45 - - ABC COMUM 196 - - SAO BERNARDO DO CAMPO (PARQUE SELECTA)- SANTO ANDRE (TERMINAL METROPOLITANO SANTO ANDRE-OESTE) 18,551 via SAO 4,60 BERNARDO DO- CAMPO (BAETA - NEVES) 4,60 - - ABC COMUM 196 261 - Integração com Trilhos 18,551 4,60 - 2,90 7,50 - - ABC COMUM 238 - - SAO BERNARDO DO CAMPO (PARQUE LOS ANGELES)- SANTO ANDRE (TERMINAL METROPOLITANO SANTO ANDRE-OESTE) 25,850 via 4,60 SAO BERNADO - DO CAMPO -(JARDIM DA 4,60 REPRESA) - - ABC COMUM 238 261 - Integração com Trilhos 25,850 4,60 - 2,90 7,50 - - ABC COMUM 366 - - SAO BERNARDO DO CAMPO (PARQUE SELECTA)- SANTO ANDRE (JARDIM CRISTIANE) via SAO BERNARDO DO CAMPO21,774 (BAET A 4,60 NEVES) - - 4,60 - - ABC COMUM 366 261 - Integração com Trilhos 21,774 4,60 - 2,90 7,50 - - ABC COMUM 409 - - SAO BERNARDO DO CAMPO (JARDIM LAS PALMAS)- SANTO ANDRE (TERMINAL METROPOLITANO SANTO ANDRE-OESTE) 25,577 4,60 - - 4,60 - - ABC COMUM 409 261 - Integração -

Fidc Companhia Paulista De Trens Metropolitanos - Cptm
FIDC COMPANHIA PAULISTA DE TRENS METROPOLITANOS - CPTM Processo CVM RJ-2006-7551 Histórico do Processo: Entrada: 29.Set.2006 Envio de ofício de exigências: 30.Out.2006 Resposta do regulado: 17.Nov.2006 Envio de ofício de oportunidade para suprir vícios sanáveis: 4.Dez.2006 Pleito do Regulado: Obtenção dos registros de funcionamento de que trata o art. 8º e de oferta pública de distribuição de cotas previsto no art. 20, ambos da Instrução CVM nº 356/01. Motivo do envio ao Colegiado: A parcela preponderante do patrimônio líquido do Fundo é composta por créditos não-performados, conforme disposto no item 9.1 do regulamento. Características do Fundo: Forma de condomínio: fundo fechado. Prazo de duração: 84 meses. Administrador: BEM DTVM Ltda. Cedente: Companhia Paulista de Trens Metropolitanos – CPTM Custodiante: Banco Bradesco S.A. Auditor Independente: KPMG Auditores Independentes. Assessoria Jurídica: Pinheiro Neto Advogados. Rating: Aa3.br, concedido pela Moody´s América Latina Ltda. Benchmark: O Fundo buscará atingir a rentabilidade equivalente à variação do IPCA no período, acrescida de uma taxa de juros anual a ser apurada em processo de bookbuilding. Houve pagamento da taxa de fiscalização de que trata a Lei nº 7940/89. O prospecto da presente oferta foi encaminhado à STN assim que recebido pela GER-1. O montante de R$ 50 milhões em cotas subordinadas será subscrito privadamente pela cedente, a qual transferirá a titularidade de tais cotas, imediatamente após sua integralização, à Companhia Paulista de Parcerias – CPP, mediante a celebração de instrumento particular de compra e venda de cotas subordinadas, consoante informação disposta na seção IX do prospecto do Fundo. -

Cptm Dez2007
COMPANHIA PAULISTA DE TRENS METROPOLITANOS - CPTM RELAÇÃO DE PESSOAL - EMPREGADOS - DEZ/2007 MATRICULA NOME ADMISSÃO CARGO SALÁRIO ORGLOT DESCRIÇÃO SIGLA 50.003.601-2 ABEDNEGO BATISTA DO NASCIMENTO 27/06/2005 ELETRICISTA MANUTENCAO I 1.582,59 5231005 REDE AEREA A/D-MAUA DOFE 50.001.487-6 ABIGAIL DINIZ FREIRE MONTEIRO 19/01/1998 AGENTE SEGURANCA OPER 1.582,59 5621000 EQUIPE-SEGURANCA A/D DOSV 50.002.808-7 ABIGAIL PASSOS SANTOS DE OLIVEIRA 30/06/2000 AGENTE OPERACIONAL I 1.363,14 5441105 ESTACAO SAO CAETANO DOPL 40.026.348-3 ABILIO DOS SANTOS SILVA 06/06/1984 ASSIST TEC EXECUT I 6.397,51 5313000 EQUIPE-QUALIDADE DE ENGENHARIA DE MATERIAL RODANTE DORG 50.001.833-2 ABNER AFONSO PADOVEZI 01/09/1998 TEC MANUTENCAO I 2.262,84 5337010 ABRIGO ENG SAO PAULO-CORRETIVA DORM 50.001.024-2 ABRAHAO FERREIRA DE OLIVEIRA 23/06/1997 CONT CIRC TRENS I 6H 2.281,12 5521005 CONTROLE DE TRAFEGO-CCO A/D DOOC 40.024.716-X ACACIO TADEU DE ALMEIDA 21/12/1983 ELETRICISTA MANUTENCAO II 1.837,30 5234040 TELECOMUN-LAPA DOFE 40.023.954-X ACIB MARIONI ABIB 03/11/1983 ENCARREGADO ESTACAO 2.133,04 5441109 ESTACAO CAPUAVA DOPL 50.002.205-4 ADAILTO RODRIGUES DE SOUZA 01/12/1998 ENCARREGADO MANUTENCAO 2.133,04 5251021 MANUT SUPERESTRUTURA LINHA D DOFV 50.003.789-2 ADAILTON DE SOUSA DAMASCENO 23/01/2006 MAQUINISTA 1.837,30 5532005 MOVIMENTO DE TRENS B/C DOCC 50.002.066-3 ADAILTON FERREIRA DA SILVA 15/10/1998 ENCARREGADO MANUTENCAO 2.133,04 5252005 SOLDAS E EQUIPAMENTOS-PRES ALTINO DOFV 50.002.490-1 ADAILTON FERREIRA SANTOS 08/05/2000 ENCARREGADO ESTACAO 2.133,04 5431306 ESTACAO