The Microarchitecture of the IBM Eserver Z900 Processor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
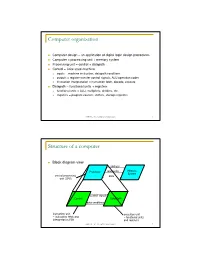
Computer Organization
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

The 32-Bit PA-RISC Run-Time Architecture Document, V. 1.0 for HP
The 32-bit PA-RISC Run-time Architecture Document HP-UX 11.0 Version 1.0 (c) Copyright 1997 HEWLETT-PACKARD COMPANY. The information contained in this document is subject to change without notice. HEWLETT-PACKARD MAKES NO WARRANTY OF ANY KIND WITH REGARD TO THIS MATERIAL, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. Hewlett-Packard shall not be liable for errors contained herein or for incidental or consequential damages in connection with furnishing, performance, or use of this material. Hewlett-Packard assumes no responsibility for the use or reliability of its software on equipment that is not furnished by Hewlett-Packard. This document contains proprietary information which is protected by copyright. All rights are reserved. No part of this document may be photocopied, reproduced, or translated to another language without the prior written consent of Hewlett-Packard Company. CSO/STG/STD/CLO Hewlett-Packard Company 11000 Wolfe Road Cupertino, California 95014 By The Run-time Architecture Team 32-bit PA-RISC RUN-TIME ARCHITECTURE DOCUMENT 11.0 version 1.0 -1 -2 CHAPTER 1 Introduction 7 1.1 Target Audiences 7 1.2 Overview of the PA-RISC Runtime Architecture Document 8 CHAPTER 2 Common Coding Conventions 9 2.1 Memory Model 9 2.1.1 Text Segment 9 2.1.2 Initialized and Uninitialized Data Segments 9 2.1.3 Shared Memory 10 2.1.4 Subspaces 10 2.2 Register Usage 10 2.2.1 Data Pointer (GR 27) 10 2.2.2 Linkage Table Register (GR 19) 10 2.2.3 Stack Pointer (GR 30) 11 2.2.4 Space -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Implementation, Verification and Validation of an Openrisc-1200
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 1, 2019 Implementation, Verification and Validation of an OpenRISC-1200 Soft-core Processor on FPGA Abdul Rafay Khatri Department of Electronic Engineering, QUEST, NawabShah, Pakistan Abstract—An embedded system is a dedicated computer system in which hardware and software are combined to per- form some specific tasks. Recent advancements in the Field Programmable Gate Array (FPGA) technology make it possible to implement the complete embedded system on a single FPGA chip. The fundamental component of an embedded system is a microprocessor. Soft-core processors are written in hardware description languages and functionally equivalent to an ordinary microprocessor. These soft-core processors are synthesized and implemented on the FPGA devices. In this paper, the OpenRISC 1200 processor is used, which is a 32-bit soft-core processor and Fig. 1. General block diagram of embedded systems. written in the Verilog HDL. Xilinx ISE tools perform synthesis, design implementation and configure/program the FPGA. For verification and debugging purpose, a software toolchain from (RISC) processor. This processor consists of all necessary GNU is configured and installed. The software is written in C components which are available in any other microproces- and Assembly languages. The communication between the host computer and FPGA board is carried out through the serial RS- sor. These components are connected through a bus called 232 port. Wishbone bus. In this work, the OR1200 processor is used to implement the system on a chip technology on a Virtex-5 Keywords—FPGA Design; HDLs; Hw-Sw Co-design; Open- FPGA board from Xilinx. -

Python Console Target Device 78K0 Microcontroller RL78 Family 78K0R Microcontroller V850 Family RX Family RH850 Family
User’s Manual CS+ V4.01.00 Integrated Development Environment User’s Manual: Python Console Target Device 78K0 Microcontroller RL78 Family 78K0R Microcontroller V850 Family RX Family RH850 Family All information contained in these materials, including products and product specifications, represents information on the product at the time of publication and is subject to change by Renesas Electronics Corp. without notice. Please review the latest information published by Renesas Electronics Corp. through various means, including the Renesas Electronics Corp. website (http://www.renesas.com). www.renesas.com Rev.1.00 2016.09 Notice 1. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. You are fully responsible for the incorporation of these circuits, software, and information in the design of your equipment. Renesas Electronics assumes no responsibility for any losses incurred by you or third parties arising from the use of these circuits, software, or information. 2. Renesas Electronics has used reasonable care in preparing the information included in this document, but Renesas Electronics does not warrant that such information is error free. Renesas Electronics assumes no liability whatsoever for any damages incurred by you resulting from errors in or omissions from the information included herein. 3. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. -

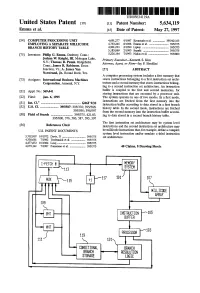
Emcissonfrom L0 \ 001Mm: R" W \14
United States Patent [19] [11] Patent Number: 4,821,183 Hauris [45] Date of Patent: Apr. 11, 1989 [54] A MICROSEQUENCER CIRCUIT WITH 4,439,827 3/1984 Wilkes ............................... .. 364/21!) PLURAL MICROPROGROM INSTRUCTION 4,446,518 5/1984 Casamatta 364/200 COUNTERS 4,551,798 11/1985 Horvath ............................ .. 364/200 [75] Inventor: Jon F. Hauris, Manassas, Va. FOREIGN PATENT DOCUMENTS 73 Assi ee: Internatio :11 B siness Mach'nes “(H843 8/l932 PCT In“ APPL ' l 1 g“ corpom?gn, Armonk N_Y_ ' 2013923 4/1980 United Kingdom. 21 A LN .: 937772 Primag'Y Examiner-David Y. Eng . [ 1 pp 0 ’ Attorney, Agent, or Firm—H. St. Julian; John E. Hoel 22 F1 d: D .4 1986 [ 1 16 W ’ [51] ABSTRACT [51] Int. Cl.4 .............................................. .. G06F 9/30 A . l I [52] US. Cl. .................................................. .. 364/200 mlcliosequencer ‘.nc “.des at Fast two prcigram count [58] Field of S e at ch 364/200 MS File 900 MS File ers which access microinstrucnons stored in a memory ’ system. A ?rst program counter is cyclicly incremented [56] References Cited to sequentially access rnicroinstructions of a principal U_s_ PATENT DOCUMENTS microprogram. When a particular microinstruction is accessed which indicates that a subroutine will be the gardner e‘ """"""" " next program to be executed, a branched-from address, 3'967’lo4 6/1976 33:21:51‘;smleets' 364/900 representing the microinstruction calling the subrou 3:978:454 8/1976 - ' ' 364/900 tine, is retained in the ?rst program counter. An address 3,991,404 11/1976 364/200 representing the ?rst instruction of the subroutine 15 4,003,033 1/1977 364/200 loaded into a second program counter. -

Value Prediction Design for High-Frequency Microprocessors 1
Value Prediction Design for High-Frequency Microprocessors Ravi Bhargava and Lizy K. John Technical Report TR-020508-01 Laboratory for Computer Architecture Department of Electrical and Computer Engineering The University of Texas at Austin fravib,[email protected] May 2002 Abstract This paper studies value predictor design under table access latency and energy constraints for high-frequency, wide-issue microprocessors. Previous value prediction efforts make generous assumptions regarding table sizes and access conditions, while ignoring prediction latencies and energy issues. Our work shows that the latency of a high-performance value predictor cannot be completely hidden by the early stages of the instruction pipeline as previously assumed, and causes noticeable performance degradation versus unconstrained value prediction. This work describes and compares three varieties of value prediction strategies: At-Fetch, Post-Decode, and Decoupled. Decoupled value prediction excels at overcoming the high-frequency table access constraints but with high energy consumption requirements. A load-only value predictor can greatly reduce energy consumption but at the cost of performance. We propose a value prediction approach that combines the latency-friendly approach of Decoupled value prediction with a more energy- efficient implementation. The traditional PC-indexed prediction tables are removed and replaced by updates of buffered prediction traces. This latency and energy aware form of accounting for and distributing the value predictions leads to a 58%-95% reduction in dynamic energy versus common high-performance value prediction hardware while still maintaining high performance. 1 Introduction A trend in recent microprocessors design is the increasing density of on-die transistors. This trend has allowed designers and researchers to explore creative new techniques for improving instruction throughput. -
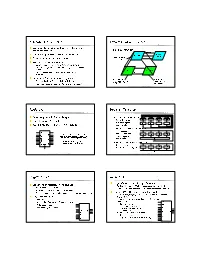
Computer Organization Structure of a Computer Registers Register
Computer Organization Structure of a Computer z Computer design as an application of digital logic design procedures z Block diagram view address z Computer = processing unit + memory system Processor read/write Memory System central processing data z Processing unit = control + datapath unit (CPU) z Control = finite state machine y Inputs = machine instruction, datapath conditions y Outputs = register transfer control signals, ALU operation control signals codes Control Data Path y Instruction interpretation = instruction fetch, decode, data conditions execute z Datapath = functional units + registers instruction unit execution unit y Functional units = ALU, multipliers, dividers, etc. instruction fetch and functional units interpretation FSM y Registers = program counter, shifters, storage registers and registers CS 150 - Spring 2001 - Computer Organization - 1 CS 150 - Spring 2001 - Computer Organization - 2 Registers Register Transfer z Selectively loaded EN or LD input z Point-to-point connection MUX MUX MUX MUX z Output enable OE input y Dedicated wires y Muxes on inputs of rs rt rd R4 z Multiple registers group 4 or 8 in parallel each register z Common input from multiplexer y Load enables LD OE for each register rs rt rd R4 D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they y Control signals D5 Q5 are left unconnected (high impedance) MUX D4 Q4 for multiplexer D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs z Common bus with output enables D0 CLK -
Processor-103
US005634119A United States Patent 19 11 Patent Number: 5,634,119 Emma et al. 45 Date of Patent: May 27, 1997 54) COMPUTER PROCESSING UNIT 4,691.277 9/1987 Kronstadt et al. ................. 395/421.03 EMPLOYING ASEPARATE MDLLCODE 4,763,245 8/1988 Emma et al. ........................... 395/375 BRANCH HISTORY TABLE 4,901.233 2/1990 Liptay ...... ... 395/375 5,185,869 2/1993 Suzuki ................................... 395/375 75) Inventors: Philip G. Emma, Danbury, Conn.; 5,226,164 7/1993 Nadas et al. ............................ 395/800 Joshua W. Knight, III, Mohegan Lake, Primary Examiner-Kenneth S. Kim N.Y.; Thomas R. Puzak. Ridgefield, Attorney, Agent, or Firm-Jay P. Sbrollini Conn.; James R. Robinson, Essex Junction, Vt.; A. James Wan 57 ABSTRACT Norstrand, Jr., Round Rock, Tex. A computer processing system includes a first memory that 73 Assignee: International Business Machines stores instructions belonging to a first instruction set archi Corporation, Armonk, N.Y. tecture and a second memory that stores instructions belong ing to a second instruction set architecture. An instruction (21) Appl. No.: 369,441 buffer is coupled to the first and second memories, for storing instructions that are executed by a processor unit. 22 Fied: Jan. 6, 1995 The system operates in one of two modes. In a first mode, instructions are fetched from the first memory into the 51 Int, C. m. G06F 9/32 instruction buffer according to data stored in a first branch 52 U.S. Cl. ....................... 395/587; 395/376; 395/586; history table. In the second mode, instructions are fetched 395/595; 395/597 from the second memory into the instruction buffer accord 58 Field of Search ...........................