Modern Computer Architectures Lecture-1: Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pipelining and Vector Processing
Chapter 8 Pipelining and Vector Processing 8–1 If the pipeline stages are heterogeneous, the slowest stage determines the flow rate of the entire pipeline. This leads to other stages idling. 8–2 Pipeline stalls can be caused by three types of hazards: resource, data, and control hazards. Re- source hazards result when two or more instructions in the pipeline want to use the same resource. Such resource conflicts can result in serialized execution, reducing the scope for overlapped exe- cution. Data hazards are caused by data dependencies among the instructions in the pipeline. As a simple example, suppose that the result produced by instruction I1 is needed as an input to instruction I2. We have to stall the pipeline until I1 has written the result so that I2 reads the correct input. If the pipeline is not designed properly, data hazards can produce wrong results by using incorrect operands. Therefore, we have to worry about the correctness first. Control hazards are caused by control dependencies. As an example, consider the flow control altered by a branch instruction. If the branch is not taken, we can proceed with the instructions in the pipeline. But, if the branch is taken, we have to throw away all the instructions that are in the pipeline and fill the pipeline with instructions at the branch target. 8–3 Prefetching is a technique used to handle resource conflicts. Pipelining typically uses just-in- time mechanism so that only a simple buffer is needed between the stages. We can minimize the performance impact if we relax this constraint by allowing a queue instead of a single buffer. -

Diploma Thesis
Faculty of Computer Science Chair for Real Time Systems Diploma Thesis Timing Analysis in Software Development Author: Martin Däumler Supervisors: Jun.-Prof. Dr.-Ing. Robert Baumgartl Dr.-Ing. Andreas Zagler Date of Submission: March 31, 2008 Martin Däumler Timing Analysis in Software Development Diploma Thesis, Chemnitz University of Technology, 2008 Abstract Rapid development processes and higher customer requirements lead to increasing inte- gration of software solutions in the automotive industry’s products. Today, several elec- tronic control units communicate by bus systems like CAN and provide computation of complex algorithms. This increasingly requires a controlled timing behavior. The following diploma thesis investigates how the timing analysis tool SymTA/S can be used in the software development process of the ZF Friedrichshafen AG. Within the scope of several scenarios, the benefits of using it, the difficulties in using it and the questions that can not be answered by the timing analysis tool are examined. Contents List of Figures iv List of Tables vi 1 Introduction 1 2 Execution Time Analysis 3 2.1 Preface . 3 2.2 Dynamic WCET Analysis . 4 2.2.1 Methods . 4 2.2.2 Problems . 4 2.3 Static WCET Analysis . 6 2.3.1 Methods . 6 2.3.2 Problems . 7 2.4 Hybrid WCET Analysis . 9 2.5 Survey of Tools: State of the Art . 9 2.5.1 aiT . 9 2.5.2 Bound-T . 11 2.5.3 Chronos . 12 2.5.4 MTime . 13 2.5.5 Tessy . 14 2.5.6 Further Tools . 15 2.6 Examination of Methods . 16 2.6.1 Software Description . -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

Towards Attack-Tolerant Trusted Execution Environments
Master’s Programme in Security and Cloud Computing Towards attack-tolerant trusted execution environments Secure remote attestation in the presence of side channels Max Crone MASTER’S THESIS Aalto University — KTH Royal Institute of Technology MASTER’S THESIS 2021 Towards attack-tolerant trusted execution environments Secure remote attestation in the presence of side channels Max Crone Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Espoo, 12 July 2021 Supervisors: Prof. N. Asokan Prof. Panagiotis Papadimitratos Advisors: Dr. HansLiljestrand Dr. Lachlan Gunn Aalto University School of Science KTH Royal Institute of Technology School of Electrical Engineering and Computer Science Master’s Programme in Security and Cloud Computing Abstract Aalto University, P.O. Box 11000, FI-00076 Aalto www.aalto.fi Author Max Crone Title Towards attack-tolerant trusted execution environments: Secure remote attestation in the presence of side channels School School of Science Master’s programme Security and Cloud Computing Major Security and Cloud Computing Code SCI3113 Supervisors Prof. N. Asokan, Prof. Panagiotis Papadimitratos Advisors Dr. Hans Liljestrand, Dr. Lachlan Gunn Level Master’s thesis Date 12 July 2021 Pages 64 Language English Abstract In recent years, trusted execution environments (TEEs) have seen increasing deployment in comput- ing devices to protect security-critical software from run-time attacks and provide isolation from an untrustworthy operating system (OS). A trusted party verifies the software that runs in a TEE using remote attestation procedures. However, the publication of transient execution attacks such as Spectre and Meltdown revealed fundamental weaknesses in many TEE architectures, including Intel Software Guard Exentsions (SGX) and Arm TrustZone. -
Computer Organization
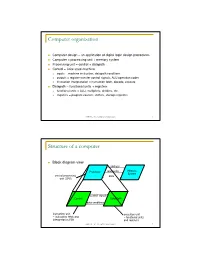
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Instruction Pipelining (1 of 7)
Chapter 5 A Closer Look at Instruction Set Architectures Objectives • Understand the factors involved in instruction set architecture design. • Gain familiarity with memory addressing modes. • Understand the concepts of instruction- level pipelining and its affect upon execution performance. 5.1 Introduction • This chapter builds upon the ideas in Chapter 4. • We present a detailed look at different instruction formats, operand types, and memory access methods. • We will see the interrelation between machine organization and instruction formats. • This leads to a deeper understanding of computer architecture in general. 5.2 Instruction Formats (1 of 31) • Instruction sets are differentiated by the following: – Number of bits per instruction. – Stack-based or register-based. – Number of explicit operands per instruction. – Operand location. – Types of operations. – Type and size of operands. 5.2 Instruction Formats (2 of 31) • Instruction set architectures are measured according to: – Main memory space occupied by a program. – Instruction complexity. – Instruction length (in bits). – Total number of instructions in the instruction set. 5.2 Instruction Formats (3 of 31) • In designing an instruction set, consideration is given to: – Instruction length. • Whether short, long, or variable. – Number of operands. – Number of addressable registers. – Memory organization. • Whether byte- or word addressable. – Addressing modes. • Choose any or all: direct, indirect or indexed. 5.2 Instruction Formats (4 of 31) • Byte ordering, or endianness, is another major architectural consideration. • If we have a two-byte integer, the integer may be stored so that the least significant byte is followed by the most significant byte or vice versa. – In little endian machines, the least significant byte is followed by the most significant byte. -

Pipelining 2
Instruction-Level Parallelism Dynamic Scheduling CS448 1 Dynamic Scheduling • Static Scheduling – Compiler rearranging instructions to reduce stalls • Dynamic Scheduling – Hardware rearranges instruction stream to reduce stalls – Possible to account for dependencies that are only known at run time - e. g. memory reference – Simplifies the compiler – Code built for one pipeline in mind could also run efficiently on a different pipeline – minimizes the need for speculative slot filling - NP hard • Once a common tactic with supercomputers and mainframes but was too expensive for single-chip – Now fits on a desktop PC’s 2 1 Dynamic Scheduling • Dependencies that are close together stall the entire pipeline – DIVD F0, F2, F4 – ADDD F10, F0, F8 – SUBD F12, F8, F14 • The ADD needs the DIV to finish, so there is a stall… which also stalls the SUBD – Looong stall for DIV – But the SUBD is independent so there is no reason why we shouldn’t execute it – Or is there? • Precise Interrupts - Ignore for now • Compiler could rearrange instructions, but so could the hardware 3 Dynamic Scheduling • It would be desirable to decode instructions into the pipe in order but then let them stall individually while waiting for operands before issue to execution units. • Dynamic Scheduling – Out of Order Issue / Execution • Scoreboarding 4 2 Scoreboarding Split ID stage into two: Issue (Decode, check for Structural hazards) Read Operands (Wait until no data hazards, read operands) 5 Scoreboard Overview • Consider another example: – DIVD F0, F2, F4 – ADDD F10, F0, -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Pipelining: Basic Concepts and Approaches
International Journal of Scientific & Engineering Research, Volume 7, Issue 4, April-2016 1197 ISSN 2229-5518 Pipelining: Basic Concepts and Approaches RICHA BAIJAL1 1Student,M.Tech,Computer Science And Engineering Career Point University,Alaniya,Jhalawar Road,Kota-325003 (Rajasthan) Abstract-This paper is concerned with the pipelining principles while designing a processor.The basics of instruction pipeline are discussed and an approach to minimize a pipeline stall is explained with the help of example.The main idea is to understand the working of a pipeline in a processor.Various hazards that cause pipeline degradation are explained and solutions to minimize them are discussed. Index Terms— Data dependency, Hazards in pipeline, Instruction dependency, parallelism, Pipelining, Processor, Stall. —————————— —————————— 1 INTRODUCTION does the paint. Still,2 rooms are idle. These rooms that I want to paint constitute my hardware.The painter and his skills are the objects and the way i am using them refers to the stag- O understand what pipelining is,let us consider the as- T es.Now,it is quite possible i limit my resources,i.e. I just have sembly line manufacturing of a car.If you have ever gone to a two buckets of paint at a time;therefore,i have to wait until machine work shop ; you might have seen the different as- these two stages give me an output.Although,these are inde- pendent tasks,but what i am limiting is the resources. semblies developed for developing its chasis,adding a part to I hope having this comcept in mind,now the reader -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

EECS 570 Lecture 5 GPU Winter 2021 Prof
EECS 570 Lecture 5 GPU Winter 2021 Prof. Satish Narayanasamy http://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Adve, Falsafi, Martin, Roth, Nowatzyk, and Wenisch of EPFL, CMU, UPenn, U-M, UIUC. 1 EECS 570 • Slides developed in part by Profs. Adve, Falsafi, Martin, Roth, Nowatzyk, and Wenisch of EPFL, CMU, UPenn, U-M, UIUC. Discussion this week • Term project • Form teams and start to work on identifying a problem you want to work on Readings For next Monday (Lecture 6): • Michael Scott. Shared-Memory Synchronization. Morgan & Claypool Synthesis Lectures on Computer Architecture (Ch. 1, 4.0-4.3.3, 5.0-5.2.5). • Alain Kagi, Doug Burger, and Jim Goodman. Efficient Synchronization: Let Them Eat QOLB, Proc. 24th International Symposium on Computer Architecture (ISCA 24), June, 1997. For next Wednesday (Lecture 7): • Michael Scott. Shared-Memory Synchronization. Morgan & Claypool Synthesis Lectures on Computer Architecture (Ch. 8-8.3). • M. Herlihy, Wait-Free Synchronization, ACM Trans. Program. Lang. Syst. 13(1): 124-149 (1991). Today’s GPU’s “SIMT” Model CIS 501 (Martin): Vectors 5 Graphics Processing Units (GPU) • Killer app for parallelism: graphics (3D games) Tesla S870 What is Behind such an Evolution? • The GPU is specialized for compute-intensive, highly data parallel computation (exactly what graphics rendering is about) ❒ So, more transistors can be devoted to data processing rather than data caching and flow control ALU ALU Control ALU ALU CPU GPU Cache DRAM DRAM • The fast-growing video game industry