Max Lin Software Engineer | Google
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Domestic Biometric Data Operator
Domestic Biometric Data Operator Sector: IT–ITeS Class XI Domestic Biometric Data Operator (Job Role) Qualification Pack: Ref. Id. SSC/Q2213 Sector: Information Technology and Information Technology enabled Services (IT-ITeS) 171105 NCERT ISBN 978-81-949859-6-9 Textbook for Class XI 2021-22 Cover I_IV.indd All Pages 19-Mar-21 12:56:47 PM ` ` 100/pp.112 ` 90/pp.100 125/pp.136 Code - 17918 Code - 17903 Code - 17913 ISBN - 978-93-5292-075-4 ISBN - 978-93-5292-074-7 ISBN - 978-93-5292-083-9 ` 100/pp.112 ` 120/pp. 128 ` 85/pp. 92 Code - 17914 Code - 17946 Code - 171163 ISBN - 978-93-5292-082-2 ISBN - 978-93-5292-068-6 ISBN - 978-93-5292-080-8 ` 65/pp.68 ` 85/pp.92 ` 100/pp.112 Code - 17920 Code - 171111 Code - 17945 ISBN - 978-93-5292-087-7 ISBN - 978-93-5292-086-0 ISBN - 978-93-5292-077-8 For further enquiries, please visit www.ncert.nic.in or contact the Business Managers at the addresses of the regional centres given on the copyright page. 2021-22 Cover II_III.indd 3 10-Mar-21 4:37:56 PM Domestic Biometric Data Operator (Job Role) Qualification Pack: Ref. Id. SSC/Q2213 Sector: Information Technology and Information Technology enabled Services (IT-ITeS) Textbook for Class XI 2021-22 Prelims.indd 1 19-Mar-21 2:56:01 PM 171105 – Domestic Biometric Data Operator ISBN 978-81-949859-6-9 Vocational Textbook for Class XI First Edition ALL RIGHTS RESERVED March 2021 Phalguna 1942 No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise without the prior PD 5T BS permission of the publisher. -
Crystal Reports Activex Designer
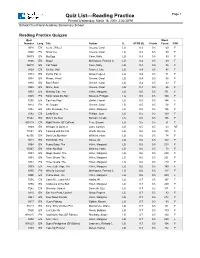
Quiz List—Reading Practice Page 1 Printed Wednesday, March 18, 2009 2:36:33PM School: Churchland Academy Elementary School Reading Practice Quizzes Quiz Word Number Lang. Title Author IL ATOS BL Points Count F/NF 9318 EN Ice Is...Whee! Greene, Carol LG 0.3 0.5 59 F 9340 EN Snow Joe Greene, Carol LG 0.3 0.5 59 F 36573 EN Big Egg Coxe, Molly LG 0.4 0.5 99 F 9306 EN Bugs! McKissack, Patricia C. LG 0.4 0.5 69 F 86010 EN Cat Traps Coxe, Molly LG 0.4 0.5 95 F 9329 EN Oh No, Otis! Frankel, Julie LG 0.4 0.5 97 F 9333 EN Pet for Pat, A Snow, Pegeen LG 0.4 0.5 71 F 9334 EN Please, Wind? Greene, Carol LG 0.4 0.5 55 F 9336 EN Rain! Rain! Greene, Carol LG 0.4 0.5 63 F 9338 EN Shine, Sun! Greene, Carol LG 0.4 0.5 66 F 9353 EN Birthday Car, The Hillert, Margaret LG 0.5 0.5 171 F 9305 EN Bonk! Goes the Ball Stevens, Philippa LG 0.5 0.5 100 F 7255 EN Can You Play? Ziefert, Harriet LG 0.5 0.5 144 F 9314 EN Hi, Clouds Greene, Carol LG 0.5 0.5 58 F 9382 EN Little Runaway, The Hillert, Margaret LG 0.5 0.5 196 F 7282 EN Lucky Bear Phillips, Joan LG 0.5 0.5 150 F 31542 EN Mine's the Best Bonsall, Crosby LG 0.5 0.5 106 F 901618 EN Night Watch (SF Edition) Fear, Sharon LG 0.5 0.5 51 F 9349 EN Whisper Is Quiet, A Lunn, Carolyn LG 0.5 0.5 63 NF 74854 EN Cooking with the Cat Worth, Bonnie LG 0.6 0.5 135 F 42150 EN Don't Cut My Hair! Wilhelm, Hans LG 0.6 0.5 74 F 9018 EN Foot Book, The Seuss, Dr. -

Mining Version Histories for Detecting Code Smells
W&M ScholarWorks Arts & Sciences Articles Arts and Sciences 2015 Mining Version Histories for Detecting Code Smells Fabio Palomba Andrea De Lucia Gabriele Bavota Denys Poshyvanyk College of William and Mary Follow this and additional works at: https://scholarworks.wm.edu/aspubs Recommended Citation Palomba, F., Bavota, G., Di Penta, M., Oliveto, R., Poshyvanyk, D., & De Lucia, A. (2014). Mining version histories for detecting code smells. IEEE Transactions on Software Engineering, 41(5), 462-489. This Article is brought to you for free and open access by the Arts and Sciences at W&M ScholarWorks. It has been accepted for inclusion in Arts & Sciences Articles by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. 462 IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 41, NO. 5, MAY 2015 Mining Version Histories for Detecting Code Smells Fabio Palomba, Student Member, IEEE, Gabriele Bavota, Member, IEEE Computer Society, Massimiliano Di Penta, Rocco Oliveto, Member, IEEE Computer Society, Denys Poshyvanyk, Member, IEEE Computer Society, and Andrea De Lucia, Senior Member, IEEE Abstract—Code smells are symptoms of poor design and implementation choices that may hinder code comprehension, and possibly increase change- and fault-proneness. While most of the detection techniques just rely on structural information, many code smells are intrinsically characterized by how code elements change over time. In this paper, we propose Historical Information for Smell deTection (HIST), an approach exploiting change history information to detect instances of five different code smells, namely Divergent Change, Shotgun Surgery, Parallel Inheritance, Blob, and Feature Envy. We evaluate HIST in two empirical studies. -

View of Siebel Mobile Siebel Mobile Products
Siebel[1] CRM Siebel Mobile Guide: Disconnected Siebel Innovation Pack 2015, Rev. D E52427-01 September 2016 Siebel Mobile Guide: Disconnected, Siebel Innovation Pack 2015, Rev. D E52427-01 Copyright © 2005, 2016 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Sumdog Spelling Words
Sumdog spelling words a accommodates actuality adverb agoraphobia allows and aardvark accommodation actually adverbs agree almighty android aardvarks accommodations acute adversities agreeable almost androids abandon accompanied adapt adversity agreed alocoholics angel abandoned accompaniment adaptable advert agreeing alone angelic abbey accompany adapted advertise agreement along angels abbeys accordance adapting advertised agreements aloud anger abbreviated according adapts advertisement agriculture alphabet angered abbreviation accordion add advertisements aground alphabetical angle abbreviations accordions added advertises ahead alphabetically angled abduct account addict advertising ahoy already angler abducted accountant addicted adverts aid alright anglers abilities accountants addicting advice aided also angles ability accounted addiction advisable aiding altar angling ablaze accounting addictions advise aids altars angrier able accounts addicts advised ail alter angriest abnormal accurate adding adviser ailment alteration angrily abnormalities accurately addition advises ailments altering angry abnormality accuse additional advising aim alternate anguish aboard accused additionally aero aimed alternative animal abominable accusing address aerobatics aiming alternatively animals aboriginal ace addressed aerobics aimless alternatives ankle aboriginals aced addresses aerodromes air although ankles about ache addressing aerodynamic airplane altogether anniversaries above ached adds aerodynamics airplanes always anniversary abracadabra -

Merger Policy in Digital Markets: an Ex Post Assessment 3 Study Is to Undertake a Less Common Form of Ex Post Assessment
Journal of Competition Law & Economics, 00(00), 1–46 doi: 10.1093/joclec/nhaa020 MERGER POLICY IN DIGITAL MARKETS: AN EX Downloaded from https://academic.oup.com/jcle/advance-article/doi/10.1093/joclec/nhaa020/5874037 by guest on 18 December 2020 POST ASSESSMENT† Elena Argentesi,∗Paolo Buccirossi,†Emilio Calvano,‡ Tomaso Duso,§,∗ & Alessia Marrazzo,¶ & Salvatore Nava† ABSTRACT This paper presents a broad retrospective evaluation of mergers and merger decisions in markets dominated by multisided digital platforms. First, we doc- ument almost 300 acquisitions carried out by three major tech companies— Amazon, Facebook, and Google—between 2008 and 2018. We cluster target companies on their area of economic activity providing suggestive evidence on the strategies behind these mergers. Second, we discuss the features of digital markets that create new challenges for competition policy. By using relevant case studies as illustrative examples, we discuss theories of harm that have been used or, alternatively, could have been formulated by authorities in these cases. Finally, we retrospectively examine two important merger cases, Facebook/Instagram and Google/Waze, providing a systematic assessment of the theories of harm considered by the UK competition authorities as well as evidence on the evolution of the market after the transactions were approved. We discuss whether the competition authority performed complete and careful analyses to foresee the competitive consequences of the investigated mergers and whether a more effective merger control regime can be achieved within the current legal framework. JEL codes: L4; K21 ∗ Department of Economics, University of Bologna † Lear, Rome ‡ Department of Economics, University of Bologna, Toulouse School of Economics and CEPR, London § Deutsches Institut fuer Wirtschaftsforschung (DIW Berlin), Department of Economics, Tech- nical University (TU) Berlin, CEPR, London and CESifo, Munich ¶ Lear, Rome and Department of Economics, University of Bologna ∗ Corresponding author. -

Anarchists Cookbook V2000
ANARCHY COOKBOOK VERSION 2000 Table of Contents 1.Counterfeiting Money 58.Generic Bomb 2.Credit Card Fraud 59.Green Box Plans 3.Making Plastic Explosives 60.Portable Grenade Launcher 4.Picking Master Locks 61.Basic Hacking Tutorial I 5.The Arts of Lockpicking I 62.Basic Hacking Tutorial II 6.The Arts of Lockpicking II 63.Hacking DEC's 7.Solidox Bombs 64.Harmless Bombs 8.High Tech Revenge: The Beigebox 65.Breaking into Houses 9.COý Bombs 66.Hypnotism 10.Thermite II Bombs 67.Remote Informer Issue #1 11.Touch Explosives 68.Jackpotting ATM Machines 12.Letter Bombs 69.Jug Bomb 13.Paint Bombs 70.Fun at K-Mart 14.Ways to send a car to HELL 71.Mace Substitute 15.Do you hate school? 72.How to Grow Marijuana 16.Phone related vandalism 73.Match Head Bomb 17.Highway police radar jamming 74.Terrorizing McDonalds 18.Smoke Bombs 75."Mentor's" Last Words 19.Mail Box Bombs 76.The Myth of the 2600hz Detector 20.Hot-wiring cars 77.Blue Box Plans 21.Napalm 78.Napalm II 22.Fertilizer Bomb 79.Nitroglycerin Recipe 23.Tennis Ball Bomb 80.Operation: Fuckup 24.Diskette Bombs 81.Stealing Calls from Payphones 25.Unlisted Phone Numbers 82.Pool Fun 26.Fuses 83.Free Postage 27.How to make Potassium Nitrate 84.Unstable Explosives 28.Exploding Light bulbs 85.Weird Drugs 29.Under water igniters 86.The Art of Carding 30.Home-brew blast cannon 87.Recognizing Credit Cards 31.Chemical Equivalency List 88.How to Get a New Identity 32.Phone Taps 89.Remote Informer Issue #2 33.Landmines 90.Remote Informer Issue #3 34.A different Molitov Cocktail 91.Remote Informer Issue #4 35.Phone -

Data Governance User Guide Company
PUBLIC SAP Data Intelligence Document Version: 3.1.5 – 2021-09-03 Data Governance User Guide company. All rights reserved. All rights company. affiliate THE BEST RUN 2021 SAP SE or an SAP SE or an SAP SAP 2021 © Content 1 Data Governance User Guide for SAP Data Intelligence...............................6 1.1 Using the Metadata Explorer.....................................................6 Using the Discovery Dashboard................................................ 9 Configure User Settings and View Notifications.....................................11 2 Managing Connections.......................................................13 2.1 Overview of Metadata Extraction................................................. 19 2.2 Profile a Dataset.............................................................21 2.3 Publish a Dataset............................................................22 View Published Datasets in a Folder or Connection..................................23 Update or Delete a Publication................................................ 24 View Connection Capabilities.................................................25 2.4 Manage Files and Folders.......................................................25 3 Managing the Catalog....................................................... 28 3.1 Create Hierarchical Tags....................................................... 31 3.2 Manage Tags...............................................................32 4 Rules.................................................................... 35 4.1 -

Sumdog Spelling Words
Sumdog spelling words a acquitted again amount appeal ashore awoke aardvark acrobat against amphibian appear ask axe abandon acrobatic age ample appearance asked axle abandoned across ageless amuse appetite asleep Ayr abbey act aggression amusement applauded aspirin abbeys action aggressive amusements applause assemble babble abbreviation active ago an apple assent babies abducted activity agony anagram appliance assessment baboon Aberdeen actor agoraphobia analyse applicable assignment baboons abilities actress agree analysis applicably assist baby ability actual agreeable ancestor application assistance baby’s able actually agreed anchor applied assistant babysitter abnormal adapt agreement ancient applies assorted back abnormalities add aground and apply assume backbone aboard addict ahead android applying assurance backed abominable addiction ahoy angel appointment asterisk backfired aboriginal addition aid angelic apprentice asteroid backflip about additional ail anger apprenticeship astonish background above address aim angle apprenticeships astonishing backhand abracadabra addressed aimless angler approach astrology backing abrasive addresses air angles appropriate astronaut backpack abroad adjective Airdrie angrier approximate astronomy backside abrupt adjust airport angriest April at backstage absence adjustment aisle angrily aqua ate backstretch absent admiration ajar animal aquaplane athlete backstroke absolute admire alarm animals aquarium athletic backup absolutely admission albatross ankle aquatic atlas backward absolve admit -

NET-2020-11-1.Pdf
Chair of Network Architectures and Services Department of Informatics Technical University of Munich Proceedings of the Seminar Innovative Internet Technologies and Mobile Communications (IITM) Summer Semester 2020 February 28, 2020 – August 16, 2020 Munich, Germany Editors Georg Carle, Stephan Gunther,¨ Benedikt Jaeger Publisher Chair of Network Architectures and Services Network Architectures and Services NET 2020-11-1 Chair of Network Architectures and Services Department of Informatics Technical University of Munich Proceedings of the Seminar Innovative Internet Technologies and Mobile Communications (IITM) Summer Semester 2020 Munich, February 28, 2020 – August 16, 2020 Editors: Georg Carle, Stephan Günther, Benedikt Jaeger Network Architectures and Services NET 2020-11-1 Proceedings of the Seminar Innovative Internet Technologies and Mobile Communications (IITM) Summer Semester 2020 Editors: Georg Carle Chair of Network Architectures and Services (I8) Technical University of Munich Boltzmannstraße 3, 85748 Garching b. München, Germany E-mail: [email protected] Internet: https://net.in.tum.de/~carle/ Stephan Günther Chair of Network Architectures and Services (I8) E-mail: [email protected] Internet: https://net.in.tum.de/~guenther/ Benedikt Jaeger Chair of Network Architectures and Services (I8) E-mail: [email protected] Internet: https://net.in.tum.de/~jaeger/ Cataloging-in-Publication Data Seminar IITM SS 20 Proceedings of the Seminar Innovative Internet Technologies and Mobile Communications (IITM) Munich, Germany, February 28, 2020 – August 16, 2020 ISBN: 978-3-937201-70-2 ISSN: 1868-2634 (print) ISSN: 1868-2642 (electronic) DOI: 10.2313/NET-2020-11-1 Innovative Internet Technologies and Mobile Communications (IITM) NET 2020-11-1 Series Editor: Georg Carle, Technical University of Munich, Germany © 2020, Technical University of Munich, Germany II Preface We are pleased to present you the proceedings of the Seminar Innovative Internet Technologies and Mobile Communications (IITM) during the Summer Semester 2020. -

Ask, Don't Search: a Social Help Engine for Online Social Network
Ask, Don’t Search: A Social Help Engine for Online Social Network Mobile Users Tam Vu, Akash Baid WINLAB, Rutgers University {tamvu,baid}@winlab.rutgers.edu Abstract—In this paper, we present the architectural details The rapid growth of online social networks such as Face- of Odin Help Engine, a novel social search engine that leverages book [1], LinkedIn [2], Twitter [3] provides a unique oppor- online social networks and sensing data from mobile devices to tunity for such a class of help engines. Connections between find targeted answers for subjective queries and recommendation requests. In Odin, users’ queries are routed to those connections users in such services can serve as links along which questions in their social network who (i) are most likely to help answer can be routed. Along the same lines, Aardvark [4], the state-of- the question and (ii) can do so with a high level of confidence. the-art social search engine, was recently proposed to match Specifically, we first apply a link-based latent variable model to questions from a user to other users based on their area of infer social relationships between users from their social network expertise. However, it requires participants to explicitly list data to form a strength-weighted relationship graph. We then infer users’ expertise by context mining from social network data their skill set. We argue that the assumption of users being as well as from their mobile device sensor data. Lastly we apply fully aware of the topics that they can potentially answer about pagerank-like algorithm that takes both relationship strength and is too restrictive. -

Siebel Mobile Guide: Disconnected
Oracle Siebel Mobile Guide: Disconnected Siebel 2018 September 2018 Mobile Guide: Disconnected Part Number: E98493-01 Copyright © 2018, Oracle and/or its affiliates. All rights reserved Authors: Siebel Information Development Team This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display in any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/ or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S.