Ask, Don't Search: a Social Help Engine for Online Social Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Metadata for Semantic and Social Applications
etadata is a key aspect of our evolving infrastructure for information management, social computing, and scientific collaboration. DC-2008M will focus on metadata challenges, solutions, and innovation in initiatives and activities underlying semantic and social applications. Metadata is part of the fabric of social computing, which includes the use of wikis, blogs, and tagging for collaboration and participation. Metadata also underlies the development of semantic applications, and the Semantic Web — the representation and integration of multimedia knowledge structures on the basis of semantic models. These two trends flow together in applications such as Wikipedia, where authors collectively create structured information that can be extracted and used to enhance access to and use of information sources. Recent discussion has focused on how existing bibliographic standards can be expressed as Semantic Metadata for Web vocabularies to facilitate the ingration of library and cultural heritage data with other types of data. Harnessing the efforts of content providers and end-users to link, tag, edit, and describe their Semantic and information in interoperable ways (”participatory metadata”) is a key step towards providing knowledge environments that are scalable, self-correcting, and evolvable. Social Applications DC-2008 will explore conceptual and practical issues in the development and deployment of semantic and social applications to meet the needs of specific communities of practice. Edited by Jane Greenberg and Wolfgang Klas DC-2008 -

A Comparison of Information Seeking Using Search Engines and Social Networks
A Comparison of Information Seeking Using Search Engines and Social Networks Meredith Ringel Morris1, Jaime Teevan1, Katrina Panovich2 1Microsoft Research, Redmond, WA, USA, 2Massachusetts Institute of Technology, Cambridge, MA, USA {merrie, teevan}@microsoft.com, [email protected] Abstract et al. 2009 or Groupization by Morris et al. 2008). Social The Web has become an important information repository; search engines can also be devised using the output of so- often it is the first source a person turns to with an informa- cial tagging systems such as delicious (delicious.com). tion need. One common way to search the Web is with a Social search also encompasses active requests for help search engine. However, it is not always easy for people to from the searcher to other people. Evans and Chi (2008) find what they are looking for with keyword search, and at describe the stages of the search process when people tend times the desired information may not be readily available to interact with others. Morris et al. (2010) surveyed Face- online. An alternative, facilitated by the rise of social media, is to pose a question to one‟s online social network. In this book and Twitter users about situations in which they used paper, we explore the pros and cons of using a social net- a status message to ask questions of their social networks. working tool to fill an information need, as compared with a A well-studied type of social searching behavior is the search engine. We describe a study in which 12 participants posting of a question to a Q&A site (e.g., Harper et al. -

Domestic Biometric Data Operator
Domestic Biometric Data Operator Sector: IT–ITeS Class XI Domestic Biometric Data Operator (Job Role) Qualification Pack: Ref. Id. SSC/Q2213 Sector: Information Technology and Information Technology enabled Services (IT-ITeS) 171105 NCERT ISBN 978-81-949859-6-9 Textbook for Class XI 2021-22 Cover I_IV.indd All Pages 19-Mar-21 12:56:47 PM ` ` 100/pp.112 ` 90/pp.100 125/pp.136 Code - 17918 Code - 17903 Code - 17913 ISBN - 978-93-5292-075-4 ISBN - 978-93-5292-074-7 ISBN - 978-93-5292-083-9 ` 100/pp.112 ` 120/pp. 128 ` 85/pp. 92 Code - 17914 Code - 17946 Code - 171163 ISBN - 978-93-5292-082-2 ISBN - 978-93-5292-068-6 ISBN - 978-93-5292-080-8 ` 65/pp.68 ` 85/pp.92 ` 100/pp.112 Code - 17920 Code - 171111 Code - 17945 ISBN - 978-93-5292-087-7 ISBN - 978-93-5292-086-0 ISBN - 978-93-5292-077-8 For further enquiries, please visit www.ncert.nic.in or contact the Business Managers at the addresses of the regional centres given on the copyright page. 2021-22 Cover II_III.indd 3 10-Mar-21 4:37:56 PM Domestic Biometric Data Operator (Job Role) Qualification Pack: Ref. Id. SSC/Q2213 Sector: Information Technology and Information Technology enabled Services (IT-ITeS) Textbook for Class XI 2021-22 Prelims.indd 1 19-Mar-21 2:56:01 PM 171105 – Domestic Biometric Data Operator ISBN 978-81-949859-6-9 Vocational Textbook for Class XI First Edition ALL RIGHTS RESERVED March 2021 Phalguna 1942 No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise without the prior PD 5T BS permission of the publisher. -

A Federated Search and Social Recommendation Widget
A Federated Search and Social Recommendation Widget Sten Govaerts1 Sandy El Helou2 Erik Duval3 Denis Gillet4 Dept. Computer Science1,3 REACT group2,4 Katholieke Universiteit Leuven Ecole Polytechnique Fed´ erale´ de Lausanne Celestijnenlaan 200A, Heverlee, Belgium 1015 Lausanne, Switzerland fsten.govaerts1, [email protected] fsandy.elhelou2, denis.gillet4g@epfl.ch ABSTRACT are very useful, but their generality can sometimes be an ob- This paper presents a federated search and social recommen- stacle and this can make it difficult to know where to search dation widget. It describes the widget’s interface and the un- for the needed information [2]. Federated searching over derlying social recommendation engine. A preliminary eval- collections of topic-specific repositories can assist with this uation of the widget’s usability and usefulness involving 15 and save time. When the user sends a search request, the subjects is also discussed. The evaluation helped identify us- federated search widget collects relevant resources from dif- ability problems that will be addressed prior to the widget’s ferent social media sites [3], repositories and search engines. usage in a real learning context. Before rendering aggregated results, the widget calls a per- sonalized social recommendation service deemed as crucial Author Keywords in helping users select relevant resources especially in our federated search, social recommendations, widget, Web, per- information overload age [4,5]. The recommendation ser- sonal learning environment (PLE), Pagerank, social media, vice ranks these resources according to their global popu- Web 2.0 larity and most importantly their popularity within the social network of the target user. Ranks are computed by exploiting attention metadata and social networks in the widget. -

Unicorn: a System for Searching the Social Graph
Unicorn: A System for Searching the Social Graph Michael Curtiss, Iain Becker, Tudor Bosman, Sergey Doroshenko, Lucian Grijincu, Tom Jackson, Sandhya Kunnatur, Soren Lassen, Philip Pronin, Sriram Sankar, Guanghao Shen, Gintaras Woss, Chao Yang, Ning Zhang Facebook, Inc. ABSTRACT rative of the evolution of Unicorn's architecture, as well as Unicorn is an online, in-memory social graph-aware index- documentation for the major features and components of ing system designed to search trillions of edges between tens the system. of billions of users and entities on thousands of commodity To the best of our knowledge, no other online graph re- servers. Unicorn is based on standard concepts in informa- trieval system has ever been built with the scale of Unicorn tion retrieval, but it includes features to promote results in terms of both data volume and query volume. The sys- with good social proximity. It also supports queries that re- tem serves tens of billions of nodes and trillions of edges quire multiple round-trips to leaves in order to retrieve ob- at scale while accounting for per-edge privacy, and it must jects that are more than one edge away from source nodes. also support realtime updates for all edges and nodes while Unicorn is designed to answer billions of queries per day at serving billions of daily queries at low latencies. latencies in the hundreds of milliseconds, and it serves as an This paper includes three main contributions: infrastructural building block for Facebook's Graph Search • We describe how we applied common information re- product. In this paper, we describe the data model and trieval architectural concepts to the domain of the so- query language supported by Unicorn. -
Crystal Reports Activex Designer
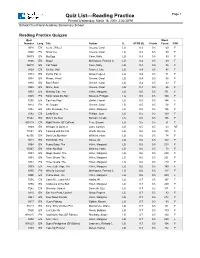
Quiz List—Reading Practice Page 1 Printed Wednesday, March 18, 2009 2:36:33PM School: Churchland Academy Elementary School Reading Practice Quizzes Quiz Word Number Lang. Title Author IL ATOS BL Points Count F/NF 9318 EN Ice Is...Whee! Greene, Carol LG 0.3 0.5 59 F 9340 EN Snow Joe Greene, Carol LG 0.3 0.5 59 F 36573 EN Big Egg Coxe, Molly LG 0.4 0.5 99 F 9306 EN Bugs! McKissack, Patricia C. LG 0.4 0.5 69 F 86010 EN Cat Traps Coxe, Molly LG 0.4 0.5 95 F 9329 EN Oh No, Otis! Frankel, Julie LG 0.4 0.5 97 F 9333 EN Pet for Pat, A Snow, Pegeen LG 0.4 0.5 71 F 9334 EN Please, Wind? Greene, Carol LG 0.4 0.5 55 F 9336 EN Rain! Rain! Greene, Carol LG 0.4 0.5 63 F 9338 EN Shine, Sun! Greene, Carol LG 0.4 0.5 66 F 9353 EN Birthday Car, The Hillert, Margaret LG 0.5 0.5 171 F 9305 EN Bonk! Goes the Ball Stevens, Philippa LG 0.5 0.5 100 F 7255 EN Can You Play? Ziefert, Harriet LG 0.5 0.5 144 F 9314 EN Hi, Clouds Greene, Carol LG 0.5 0.5 58 F 9382 EN Little Runaway, The Hillert, Margaret LG 0.5 0.5 196 F 7282 EN Lucky Bear Phillips, Joan LG 0.5 0.5 150 F 31542 EN Mine's the Best Bonsall, Crosby LG 0.5 0.5 106 F 901618 EN Night Watch (SF Edition) Fear, Sharon LG 0.5 0.5 51 F 9349 EN Whisper Is Quiet, A Lunn, Carolyn LG 0.5 0.5 63 NF 74854 EN Cooking with the Cat Worth, Bonnie LG 0.6 0.5 135 F 42150 EN Don't Cut My Hair! Wilhelm, Hans LG 0.6 0.5 74 F 9018 EN Foot Book, The Seuss, Dr. -

The Top 10 Alternative Search Engines (ASE) - Within Selected Categories Ranked by Webometric Indicators
The Top 10 Alternative search Engines (ASE) - within Selected Categories Ranked by Webometric Indicators Bernd Markscheff el Bastian Eine Within the scientifi c fi eld of webometrics many research objects had been analyzed and compared with the help of webometric indicators (e.g., the performance of a whole country, a research group or an indi- vidual). This paper presents a ranking of ASEs which is based on webo- metric indicators. As search engines have become an essential tool for searching for information on the web many alternative search services have specialized in fi nding topic- or format-specifi c search results. By creating a ranking of these ASEs within selected categories we present an overview of the ASEs which are currently available. Through webo- metric indicators the ASEs were compared and the most popular ASEs of the respective categories determined. Keywords: Search engines, Webometric indicators Bernd Markscheff el Chair of Information and 1. Introduction Knowledge Management Technische Universität While searching for information on the web, search en- Ilmenau gines can assist the user to fi nd satisfying results. Although, P.O. Box 100565 just a few dominate the search engine market a large num- 98684 Ilmenau ber of diff erent web search services and tools exist (Maaβ Germany et al., [1]). Beside the well known universal search engines bernd.markscheff el@ like Google, Yahoo and Bing several ASEs are specialized tuilmenau.de in providing options to search for special document types, specifi c topics or time-sensitive information (Gelernter [2]; Bastian Eine Consultant for Search Engine Originally presented at the 7th International Conference on Webometrics, Optimization and Online Informetrics and Scientometrics (WIS) and 12th COLLNET Meeting, Marketing September 20–23, 2011, Istanbul Bilgi University, Istanbul, Turkey. -

Searching the Enterprise
R Foundations and Trends• in Information Retrieval Vol. 11, No. 1 (2017) 1–142 c 2017 U. Kruschwitz and C. Hull • DOI: 10.1561/1500000053 Searching the Enterprise Udo Kruschwitz Charlie Hull University of Essex, UK Flax, UK [email protected] charlie@flax.co.uk Contents 1 Introduction 2 1.1 Overview........................... 3 1.2 Examples........................... 5 1.3 PerceptionandReality . 9 1.4 RecentDevelopments . 10 1.5 Outline............................ 11 2 Plotting the Landscape 13 2.1 The Changing Face of Search . 13 2.2 DefiningEnterpriseSearch . 14 2.3 Related Search Areas and Applications . 17 2.4 SearchTechniques. 34 2.5 Contextualisation ...................... 37 2.6 ConcludingRemarks. 49 3 Enterprise Search Basics 52 3.1 StructureofData ...................... 53 3.2 CollectionGathering. 59 3.3 SearchArchitectures. 63 3.4 Information Needs and Applications . 68 3.5 SearchContext ....................... 76 ii iii 3.6 UserModelling........................ 78 3.7 Tools, Frameworks and Resources . 81 4 Evaluation 82 4.1 RelevanceandMetrics. 83 4.2 Evaluation Paradigms and Campaigns . 85 4.3 TestCollections ....................... 89 4.4 LessonsLearned ....................... 94 5 Making Enterprise Search Work 95 5.1 PuttingtheUserinControl . 96 5.2 Relevance Tuning and Support . 103 6 The Future 110 6.1 GeneralTrends........................ 110 6.2 TechnicalDevelopments. 111 6.3 Moving towards Cooperative Search . 113 6.4 SomeResearchChallenges . 114 6.5 FinalWords ......................... 117 7 Conclusion 118 Acknowledgements 120 References 121 Abstract Search has become ubiquitous but that does not mean that search has been solved. Enterprise search, which is broadly speaking the use of information retrieval technology to find information within organisa- tions, is a good example to illustrate this. -

Mining Version Histories for Detecting Code Smells
W&M ScholarWorks Arts & Sciences Articles Arts and Sciences 2015 Mining Version Histories for Detecting Code Smells Fabio Palomba Andrea De Lucia Gabriele Bavota Denys Poshyvanyk College of William and Mary Follow this and additional works at: https://scholarworks.wm.edu/aspubs Recommended Citation Palomba, F., Bavota, G., Di Penta, M., Oliveto, R., Poshyvanyk, D., & De Lucia, A. (2014). Mining version histories for detecting code smells. IEEE Transactions on Software Engineering, 41(5), 462-489. This Article is brought to you for free and open access by the Arts and Sciences at W&M ScholarWorks. It has been accepted for inclusion in Arts & Sciences Articles by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. 462 IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 41, NO. 5, MAY 2015 Mining Version Histories for Detecting Code Smells Fabio Palomba, Student Member, IEEE, Gabriele Bavota, Member, IEEE Computer Society, Massimiliano Di Penta, Rocco Oliveto, Member, IEEE Computer Society, Denys Poshyvanyk, Member, IEEE Computer Society, and Andrea De Lucia, Senior Member, IEEE Abstract—Code smells are symptoms of poor design and implementation choices that may hinder code comprehension, and possibly increase change- and fault-proneness. While most of the detection techniques just rely on structural information, many code smells are intrinsically characterized by how code elements change over time. In this paper, we propose Historical Information for Smell deTection (HIST), an approach exploiting change history information to detect instances of five different code smells, namely Divergent Change, Shotgun Surgery, Parallel Inheritance, Blob, and Feature Envy. We evaluate HIST in two empirical studies. -

Collaborative Information Access: a Conversational Search Approach
ICCBR Workshop on Reasoning from Experiences on the Web (WebCBR-09), Seattle Collaborative Information Access: A Conversational Search Approach Saurav Sahay, Anushree Venkatesh, and Ashwin Ram College of Computing Georgia Institute of Technology Atlanta, GA Abstract. Knowledge and user generated content is proliferating on the web in scientific publications, information portals and online social me- dia. This knowledge explosion has continued to outpace technological innovation in efficient information access technologies. In this paper, we describe the methods and technologies for ‘Conversational Search’ as an innovative solution to facilitate easier information access and reduce the information overload for users. Conversational Search is an interactive and collaborative information finding interaction. The participants in this interaction engage in social conversations aided with an intelligent information agent (Cobot) that provides contextually relevant search recommendations. The collaborative and conversational search activity helps users make faster and more informed search and discovery. It also helps the agent learn about conversations with interactions and social feedback to make better recommendations. Conversational search lever- agesthe social discovery process by integrating web information retrieval along with the social interactions. 1 Introduction Socially enabled online information search (social search) is a new phenomenon facilitated by recent Web technologies. This collaborative social search involves finding specific people in your network who have the knowledge you’re look- ing for or finding relevant information based on one’s social network. Social psychologists have experimentally validated that the act of social discussions have facilitated cognitive performance[1]. People in social groups can provide solutions (answers to questions)[2], pointers to databases or other people (meta- knowledge)[2][3] , validation and legitimation of ideas[2][4], can serve as mem- ory aids[5] and help with problem reformulation[2]. -

View of Siebel Mobile Siebel Mobile Products
Siebel[1] CRM Siebel Mobile Guide: Disconnected Siebel Innovation Pack 2015, Rev. D E52427-01 September 2016 Siebel Mobile Guide: Disconnected, Siebel Innovation Pack 2015, Rev. D E52427-01 Copyright © 2005, 2016 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Natural Search User Interfaces
Natural Search User Interfaces Prof. Marti Hearst UC Berkeley March/April , 2012 Book full text freely available at: http://searchuserinterfaces.com What works well in search now? Faceted Navigation 3 Real-Time Suggestions http://netflix.com http://www.imamuseum.org/ 4 Forecasting the Future First: What are the larger trends? In technology? In society? Next: Project out from these. Preferences for Preferences for Preferences for Audio / Video / Touch Social Interaction Natural Language “Natural” Interfaces Statistical Analysis of Wide adoption of social Enormous Collections Advances in media & user-generated UI Design Of Behavioral and Other Data content 6 Trend: More Natural Queries Trend: Longer, more natural queries § The research suggests people prefer to state their information need rather than use keywords. § But after first using a search engine they quickly learned that full questions resulted in failure. 8 Trend: Longer, more natural queries § The research suggests people prefer to state their information need rather than use keywords. § But after first using a search engine they quickly learned that full questions resulted in failure. § Average query length continues to increase § In 2010 vs 2009, searches of 5-8 words were up 10%, while 1-2 word searches were down. 9 Trend: Longer, more natural queries § Social Question Answering Sites: § Information worded as questions increasing available § with the questions that the audience really wants the answers to, and § written in the language the audience wants to use. § AND with