Indexing the World Wide Web: the Journey So Far Abhishek Das Google Inc., USA Ankit Jain Google Inc., USA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Metadata for Semantic and Social Applications
etadata is a key aspect of our evolving infrastructure for information management, social computing, and scientific collaboration. DC-2008M will focus on metadata challenges, solutions, and innovation in initiatives and activities underlying semantic and social applications. Metadata is part of the fabric of social computing, which includes the use of wikis, blogs, and tagging for collaboration and participation. Metadata also underlies the development of semantic applications, and the Semantic Web — the representation and integration of multimedia knowledge structures on the basis of semantic models. These two trends flow together in applications such as Wikipedia, where authors collectively create structured information that can be extracted and used to enhance access to and use of information sources. Recent discussion has focused on how existing bibliographic standards can be expressed as Semantic Metadata for Web vocabularies to facilitate the ingration of library and cultural heritage data with other types of data. Harnessing the efforts of content providers and end-users to link, tag, edit, and describe their Semantic and information in interoperable ways (”participatory metadata”) is a key step towards providing knowledge environments that are scalable, self-correcting, and evolvable. Social Applications DC-2008 will explore conceptual and practical issues in the development and deployment of semantic and social applications to meet the needs of specific communities of practice. Edited by Jane Greenberg and Wolfgang Klas DC-2008 -

Internet Economy 25 Years After .Com
THE INTERNET ECONOMY 25 YEARS AFTER .COM TRANSFORMING COMMERCE & LIFE March 2010 25Robert D. Atkinson, Stephen J. Ezell, Scott M. Andes, Daniel D. Castro, and Richard Bennett THE INTERNET ECONOMY 25 YEARS AFTER .COM TRANSFORMING COMMERCE & LIFE March 2010 Robert D. Atkinson, Stephen J. Ezell, Scott M. Andes, Daniel D. Castro, and Richard Bennett The Information Technology & Innovation Foundation I Ac KNOW L EDGEMEN T S The authors would like to thank the following individuals for providing input to the report: Monique Martineau, Lisa Mendelow, and Stephen Norton. Any errors or omissions are the authors’ alone. ABOUT THE AUTHORS Dr. Robert D. Atkinson is President of the Information Technology and Innovation Foundation. Stephen J. Ezell is a Senior Analyst at the Information Technology and Innovation Foundation. Scott M. Andes is a Research Analyst at the Information Technology and Innovation Foundation. Daniel D. Castro is a Senior Analyst at the Information Technology and Innovation Foundation. Richard Bennett is a Research Fellow at the Information Technology and Innovation Foundation. ABOUT THE INFORMATION TECHNOLOGY AND INNOVATION FOUNDATION The Information Technology and Innovation Foundation (ITIF) is a Washington, DC-based think tank at the cutting edge of designing innovation policies and exploring how advances in technology will create new economic opportunities to improve the quality of life. Non-profit, and non-partisan, we offer pragmatic ideas that break free of economic philosophies born in eras long before the first punch card computer and well before the rise of modern China and pervasive globalization. ITIF, founded in 2006, is dedicated to conceiving and promoting the new ways of thinking about technology-driven productivity, competitiveness, and globalization that the 21st century demands. -

Recommending Best Answer in a Collaborative Question Answering System
RECOMMENDING BEST ANSWER IN A COLLABORATIVE QUESTION ANSWERING SYSTEM Mrs Lin Chen Submitted in fulfilment of the requirements for the degree of Master of Information Technology (Research) School of Information Technology Faculty of Science & Technology Queensland University of Technology 2009 Recommending Best Answer in a Collaborative Question Answering System Page i Keywords Authority, Collaborative Social Network, Content Analysis, Link Analysis, Natural Language Processing, Non-Content Analysis, Online Question Answering Portal, Prestige, Question Answering System, Recommending Best Answer, Social Network Analysis, Yahoo! Answers. © 2009 Lin Chen Page i Recommending Best Answer in a Collaborative Question Answering System Page ii © 2009 Lin Chen Page ii Recommending Best Answer in a Collaborative Question Answering System Page iii Abstract The World Wide Web has become a medium for people to share information. People use Web- based collaborative tools such as question answering (QA) portals, blogs/forums, email and instant messaging to acquire information and to form online-based communities. In an online QA portal, a user asks a question and other users can provide answers based on their knowledge, with the question usually being answered by many users. It can become overwhelming and/or time/resource consuming for a user to read all of the answers provided for a given question. Thus, there exists a need for a mechanism to rank the provided answers so users can focus on only reading good quality answers. The majority of online QA systems use user feedback to rank users’ answers and the user who asked the question can decide on the best answer. Other users who didn’t participate in answering the question can also vote to determine the best answer. -

Análisis De Klout Y Peerindex
HERRAMIENtas WEB para LA MEDICIÓN DE LA INFLUENCIA digital: ANÁLISIS DE KLOUT Y PEERINDEX Javier Serrano-Puche Javier Serrano-Puche, profesor de teoría de la comunicación en la Universidad de Navarra, in- vestiga los fundamentos teóricos de la comunicación, y sobre todo del periodismo, con interés por el ámbito digital 2.0. En especial estudia las redes sociales, tanto por sus implicaciones para la expresión de la identidad personal como en la conformación de la esfera pública. Es autor de La verdad recobrada en la escritura (2011), una biografía intelectual de Leonardo Sciascia. Sobre este escritor siciliano también ha publicado numerosos ensayos en diversas revistas españolas y extranjeras. Universidad de Navarra Departamento de Comunicación Pública Edif. Biblioteca, 31080 Pamplona, España [email protected] Resumen Cada vez más es reconocida la relevancia en el entorno digital de los “líderes de opinión” o usuarios influyentes: aquellos que por medio de su actividad online (publicación de tweets y entradas en blogs, actualización de su estado en las redes sociales, recomendación de lecturas…), cumplen con la función de crear contenidos o de filtrarlos hacia personas sobre las que tienen ascendencia. Por eso han proliferado las herramientas que evalúan la influencia de una persona o marca a través de la monitorización de su uso de los medios sociales. Se analizan las dos más importantes: Klout y PeerIndex. Se explican los parámetros que constituyen la base de sus algoritmos de medición, así como sus carencias. La comprensión de cómo se ejerce y cómo puede medirse la influencia digital es una de las cuestiones más interesantes del fenómeno 2.0. -

Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Library Philosophy and Practice (e-journal) Libraries at University of Nebraska-Lincoln 2020 Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library SUNDAY JUDE ONUH National Open University of Nigeria, [email protected] OGOEGBUNAM LOVETH EKWUEME National Open University of Nigeria, [email protected] Follow this and additional works at: https://digitalcommons.unl.edu/libphilprac Part of the Library and Information Science Commons ONUH, SUNDAY JUDE and EKWUEME, OGOEGBUNAM LOVETH, "Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library" (2020). Library Philosophy and Practice (e-journal). 4650. https://digitalcommons.unl.edu/libphilprac/4650 Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library By Jude Sunday Onuh Enugu Study Centre Library National Open University of Nigeria [email protected] & Loveth Ogoegbunam Ekwueme Department of Library and Information Science National Open University of Nigeria [email protected] Abstract This study dwelt on awareness and utilization of search engines for information retrieval by students of National Open University of Nigeria (NOUN) Enugu Study centre. Descriptive survey research was adopted for the study. Two research questions were drawn from the two purposes that guided the study. The population consists of 5855 undergraduate students of NOUN Enugu Study Centre. A sample size of 293 students was used as 5% of the entire population. -

A Study on Vertical and Broad-Based Search Engines
International Journal of Latest Trends in Engineering and Technology IJLTET Special Issue- ICRACSC-2016 , pp.087-093 e-ISSN: 2278-621X A STUDY ON VERTICAL AND BROAD-BASED SEARCH ENGINES M.Swathi1 and M.Swetha2 Abstract-Vertical search engines or Domain-specific search engines[1][2] are becoming increasingly popular because they offer increased accuracy and extra features not possible with general, Broad-based search engines or Web-wide search engines. The paper focuses on the survey of domain specific search engine which is becoming more popular as compared to Web- Wide Search Engines as they are difficult to maintain and time consuming .It is also difficult to provide appropriate documents to represent the target data. We also listed various vertical search engines and Broad-based search engines. Index terms: Domain specific search, vertical search engines, broad based search engines. I. INTRODUCTION The Web has become a very rich source of information for almost any field, ranging from music to histories, from sports to movies, from science to culture, and many more. However, it has become increasingly difficult to search for desired information on the Web. Users are facing the problem of information overload , in which a search on a general-purpose search engine such as Google (www.google.com) results in thousands of hits.Because a user cannot specify a search domain (e.g. medicine, music), a search query may bring up Web pages both within and outside the desired domain. Example 1: A user searching for “cancer” may get Web pages related to the disease as well as those related to the Zodiac sign. -
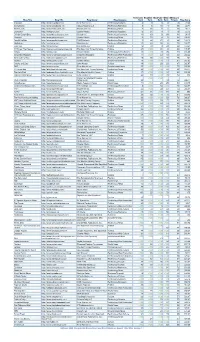
Blog Title Blog URL Blog Owner Blog Category Technorati Rank
Technorati Bloglines BlogPulse Wikio SEOmoz’s Blog Title Blog URL Blog Owner Blog Category Rank Rank Rank Rank Trifecta Blog Score Engadget http://www.engadget.com Time Warner Inc. Technology/Gadgets 4 3 6 2 78 19.23 Boing Boing http://www.boingboing.net Happy Mutants LLC Technology/Marketing 5 6 15 4 89 33.71 TechCrunch http://www.techcrunch.com TechCrunch Inc. Technology/News 2 27 2 1 76 42.11 Lifehacker http://lifehacker.com Gawker Media Technology/Gadgets 6 21 9 7 78 55.13 Official Google Blog http://googleblog.blogspot.com Google Inc. Technology/Corporate 14 10 3 38 94 69.15 Gizmodo http://www.gizmodo.com/ Gawker Media Technology/News 3 79 4 3 65 136.92 ReadWriteWeb http://www.readwriteweb.com RWW Network Technology/Marketing 9 56 21 5 64 142.19 Mashable http://mashable.com Mashable Inc. Technology/Marketing 10 65 36 6 73 160.27 Daily Kos http://dailykos.com/ Kos Media, LLC Politics 12 59 8 24 63 163.49 NYTimes: The Caucus http://thecaucus.blogs.nytimes.com The New York Times Company Politics 27 >100 31 8 93 179.57 Kotaku http://kotaku.com Gawker Media Technology/Video Games 19 >100 19 28 77 216.88 Smashing Magazine http://www.smashingmagazine.com Smashing Magazine Technology/Web Production 11 >100 40 18 60 283.33 Seth Godin's Blog http://sethgodin.typepad.com Seth Godin Technology/Marketing 15 68 >100 29 75 284 Gawker http://www.gawker.com/ Gawker Media Entertainment News 16 >100 >100 15 81 287.65 Crooks and Liars http://www.crooksandliars.com John Amato Politics 49 >100 33 22 67 305.97 TMZ http://www.tmz.com Time Warner Inc. -

Evaluation of Web-Based Search Engines Using User-Effort Measures
Evaluation of Web-Based Search Engines Using User-Effort Measures Muh-Chyun Tang and Ying Sun 4 Huntington St. School of Information, Communication and Library Studies Rutgers University, New Brunswick, NJ 08901, U.S.A. [email protected] [email protected] Abstract This paper presents a study of the applicability of three user-effort-sensitive evaluation measures —“first 20 full precision,” “search length,” and “rank correlation”—on four Web-based search engines (Google, AltaVista, Excite and Metacrawler). The authors argue that these measures are better alternatives than precision and recall in Web search situations because of their emphasis on the quality of ranking. Eight sets of search topics were collected from four Ph.D. students in four different disciplines (biochemistry, industrial engineering, economics, and urban planning). Each participant was asked to provide two topics along with the corresponding query terms. Their relevance and credibility judgment of the Web pages were then used to compare the performance of the search engines using these three measures. The results show consistency among these three ranking evaluation measures, more so between “first 20 full precision” and search length than between rank correlation and the other two measures. Possible reasons for rank correlation’s disagreement with the other two measures are discussed. Possible future research to improve these measures is also addressed. Introduction The explosive growth of information on the World Wide Web poses a challenge to traditional information retrieval (IR) research. Other than the sheer amount of information, some structural factors make searching for relevant and quality information on the Web a formidable task. -

Gender and Information Literacy: Evaluation of Gender Differences in a Student Survey of Information Sources
Gender and Information Literacy: Evaluation of Gender Differences in a Student Survey of Information Sources Arthur Taylor and Heather A. Dalal Information literacy studies have shown that college students use a va- riety of information sources to perform research and commonly choose Internet sources over traditional library sources. Studies have also shown that students do not appear to understand the information quality issues concerning Internet information sources and may lack the information literacy skills to make good choices concerning the use of these sources. No studies currently provide clear guidance on how gender might influ- ence the information literacy skills of students. Such guidance could help improve information literacy instruction. This study used a survey of college-aged students to evaluate a subset of student information literacy skills in relation to Internet information sources. Analysis of the data collected provided strong indications of gender differences in information literacy skills. Female respondents ap- peared to be more discerning than males in evaluating Internet sources. Males appeared to be more confident in the credibility and accuracy of the results returned by search engines. Evaluation of other survey responses strengthened our finding of gender differentiation in informa- tion literacy skills. ollege students today have come of age surrounded by a sea of information delivered from an array of sources available at their fingertips at any time of the day or night. Studies have shown that the most common source of information for college-aged students is the Internet. Information gathered in this environment is most likely found using a commercial search engine that returns sources of dubious quality using an unknown algorithm. -

The Scoring of America: How Secret Consumer Scores Threaten Your Privacy and Your Future
World Privacy Forum The Scoring of America: How Secret Consumer Scores Threaten Your Privacy and Your Future By Pam Dixon and Robert Gellman April 2, 2014 Brief Summary of Report This report highlights the unexpected problems that arise from new types of predictive consumer scoring, which this report terms consumer scoring. Largely unregulated either by the Fair Credit Reporting Act or the Equal Credit Opportunity Act, new consumer scores use thousands of pieces of information about consumers’ pasts to predict how they will behave in the future. Issues of secrecy, fairness of underlying factors, use of consumer information such as race and ethnicity in predictive scores, accuracy, and the uptake in both use and ubiquity of these scores are key areas of focus. The report includes a roster of the types of consumer data used in predictive consumer scores today, as well as a roster of the consumer scores such as health risk scores, consumer prominence scores, identity and fraud scores, summarized credit statistics, among others. The report reviews the history of the credit score – which was secret for decades until legislation mandated consumer access -- and urges close examination of new consumer scores for fairness and transparency in their factors, methods, and accessibility to consumers. About the Authors Pam Dixon is the founder and Executive Director of the World Privacy Forum. She is the author of eight books, hundreds of articles, and numerous privacy studies, including her landmark Medical Identity Theft study and One Way Mirror Society study. She has testified before Congress on consumer privacy issues as well as before federal agencies. -

How to Choose a Search Engine Or Directory
How to Choose a Search Engine or Directory Fields & File Types If you want to search for... Choose... Audio/Music AllTheWeb | AltaVista | Dogpile | Fazzle | FindSounds.com | Lycos Music Downloads | Lycos Multimedia Search | Singingfish Date last modified AllTheWeb Advanced Search | AltaVista Advanced Web Search | Exalead Advanced Search | Google Advanced Search | HotBot Advanced Search | Teoma Advanced Search | Yahoo Advanced Web Search Domain/Site/URL AllTheWeb Advanced Search | AltaVista Advanced Web Search | AOL Advanced Search | Google Advanced Search | Lycos Advanced Search | MSN Search Search Builder | SearchEdu.com | Teoma Advanced Search | Yahoo Advanced Web Search File Format AllTheWeb Advanced Web Search | AltaVista Advanced Web Search | AOL Advanced Search | Exalead Advanced Search | Yahoo Advanced Web Search Geographic location Exalead Advanced Search | HotBot Advanced Search | Lycos Advanced Search | MSN Search Search Builder | Teoma Advanced Search | Yahoo Advanced Web Search Images AllTheWeb | AltaVista | The Amazing Picture Machine | Ditto | Dogpile | Fazzle | Google Image Search | IceRocket | Ixquick | Mamma | Picsearch Language AllTheWeb Advanced Web Search | AOL Advanced Search | Exalead Advanced Search | Google Language Tools | HotBot Advanced Search | iBoogie Advanced Web Search | Lycos Advanced Search | MSN Search Search Builder | Teoma Advanced Search | Yahoo Advanced Web Search Multimedia & video All TheWeb | AltaVista | Dogpile | Fazzle | IceRocket | Singingfish | Yahoo Video Search Page Title/URL AOL Advanced -

A Comparison of Information Seeking Using Search Engines and Social Networks
A Comparison of Information Seeking Using Search Engines and Social Networks Meredith Ringel Morris1, Jaime Teevan1, Katrina Panovich2 1Microsoft Research, Redmond, WA, USA, 2Massachusetts Institute of Technology, Cambridge, MA, USA {merrie, teevan}@microsoft.com, [email protected] Abstract et al. 2009 or Groupization by Morris et al. 2008). Social The Web has become an important information repository; search engines can also be devised using the output of so- often it is the first source a person turns to with an informa- cial tagging systems such as delicious (delicious.com). tion need. One common way to search the Web is with a Social search also encompasses active requests for help search engine. However, it is not always easy for people to from the searcher to other people. Evans and Chi (2008) find what they are looking for with keyword search, and at describe the stages of the search process when people tend times the desired information may not be readily available to interact with others. Morris et al. (2010) surveyed Face- online. An alternative, facilitated by the rise of social media, is to pose a question to one‟s online social network. In this book and Twitter users about situations in which they used paper, we explore the pros and cons of using a social net- a status message to ask questions of their social networks. working tool to fill an information need, as compared with a A well-studied type of social searching behavior is the search engine. We describe a study in which 12 participants posting of a question to a Q&A site (e.g., Harper et al.