Unit Selection Model in Arabic Speech Synthesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Research Report on Phonetics and Phonology of Sinhala
Research Report on Phonetics and Phonology of Sinhala Asanka Wasala and Kumudu Gamage Language Technology Research Laboratory, University of Colombo School of Computing, Sri Lanka. [email protected],[email protected] Abstract phonetics and phonology for improving the naturalness and intelligibility for our Sinhala TTS system. This report examines the major characteristics of Many researches have been carried out in the linguistic Sinhala language related to Phonetics and Phonology. domain regarding Sinhala phonetics and phonology. The main topics under study are Segmental and These researches cover both aspects of segmental and Supra-segmental sounds in Spoken Sinhala. The first suprasegmental features of spoken Sinhala. Some of part presents Sinhala Phonemic Inventory, which the themes elaborated in these researches are; Sinhala describes phonemes with their associated features and sound change-rules, Sinhala Prosody, Duration and phonotactics of Sinhala. Supra-segmental features like Stress, and Syllabification. Syllabification, Stress, Pitch and Intonation, followed In the domain of Sinhala Speech Processing, a by the procedure for letter to sound conversion are very little number of researches were reported and described in the latter part. most of them were carried out by undergraduates for The research on Syllabification leads to the their final year projects. Some restricted domain identification of set of rules for syllabifying a given Sinhala TTS systems developed by undergraduates are word. The syllabication algorithm achieved an already working in a number of domains. The study of accuracy of 99.95%. Due to the phonetic nature of the such projects laid the foundation for our project. Sinhala alphabet, the letter-to-phoneme mapping was However, an extensive research was done in all- easily done, however to produce the correct aspects of Sinhala Phonetics and Phonology; in order phonetized version of a word, some modifications identify the areas to be deeply concerned in developing were needed to be done. -

Poorman's Hangul Jamo Input Method
Poorman’s Hangul Jamo Input Method pmhanguljamo.sty Kangsoo Kim 20 Sep 2021 version 0.3.6 Contents 1 Introduction 1 2 Usage 2 2.1 Loading the package .......................... 2 2.2 Commands and Environment Provided ................. 2 2.3 Setting up in your Preamble ....................... 3 3 Transliteration Rule of This Package 4 3.1 Tone Marks and Syllable Serapator ................... 4 3.2 Consonants ............................... 4 3.3 Vowels .................................. 5 3.4 Compatibility Jamos .......................... 6 4 Proper Fonts 6 5 Examples 7 5.1 Modern Hangul ............................. 7 5.2 pre-1933 Hangul ............................ 8 6 The RRK Input Method: An Alternative Way 8 6.1 Transliteration Rule of RRK ...................... 9 6.2 Example of RRK method ........................ 10 7 Further Information 11 8 Acknowledgement 11 1 Introduction 1 This LATEX package provides Hangul transliteration input method, which allows to typeset Korean Letters (Hangul) with the help of proper fonts. The name comes from “Poorman’s Hangul Jamo Input Method.” It is mainly for the people who have a system without Korean keyboard IM, but want to typeset Hangul in their document. Not only 1Hangul is the Korean alphabet to write the Korean language. In both South and North Korea, the standard writing system uses Hangul. 1 modern Hangul, but so-colled “Old Hangul” characters that uses the lost letters such as ‘Arae-A’(ㆍ), ‘Yet Ieung’(ㆁ) or ‘Pan-Sios’(ㅿ) etc. can also be typeset. X LE ATEX or LuaLATEX is required. The legacy pdfTEX is not supported. The Korean Language supporting packages such as xetexko and luatexko (in the ko.TEX bundle) or polyglossia package with Korean support are recommended, but without them typeset- ting Hangul is of no problem with this package pmhanguljamo. -

The Writing Revolution
9781405154062_1_pre.qxd 8/8/08 4:42 PM Page iii The Writing Revolution Cuneiform to the Internet Amalia E. Gnanadesikan A John Wiley & Sons, Ltd., Publication 9781405154062_1_pre.qxd 8/8/08 4:42 PM Page iv This edition first published 2009 © 2009 Amalia E. Gnanadesikan Blackwell Publishing was acquired by John Wiley & Sons in February 2007. Blackwell’s publishing program has been merged with Wiley’s global Scientific, Technical, and Medical business to form Wiley-Blackwell. Registered Office John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, United Kingdom Editorial Offices 350 Main Street, Malden, MA 02148-5020, USA 9600 Garsington Road, Oxford, OX4 2DQ, UK The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, UK For details of our global editorial offices, for customer services, and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com/wiley-blackwell. The right of Amalia E. Gnanadesikan to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher. Wiley also publishes its books in a variety of electronic formats. Some content that appears in print may not be available in electronic books. Designations used by companies to distinguish their products are often claimed as trademarks. -

Some Properties of Burmese Script H1
SEALS 23 Chulalongkorn University 2013/5/30 2013/6/22 corrected Some Properties of Burmese Script SAWADA Hideo ILCAA, Tokyo University of Foreign Studies [email protected] 0 Introduction 0.1 Indic Scripts • The group of phonogramic script systems which are descendants of the script of Asokan´ prakrit¯ inscriptions in 3cBC. (Sawada 2011: 48, originally in Japanese, slightly modified) • Indic scripts in Southeast Asia developed from the ‘extensive’ use of (Pallava-)Grantha script, i.e. the application of the script origi- nally invented for Prakrit¯ and Sanskrit to local languages. (Sawada 2008: 456, originally in Japanese) 1 Introduction 0.2 0.2 Burmese language and Burmese script Burmese language • Burmic, Burmish, Lolo-Burmese, Tibeto-Burman (Nishi 1999) ※ Burmish group consists of Burmese dialects such as Yangon- Mandalay, Dawe (Tavoyan), Rakhine (Arakan), Intha, as well as Maruic languages such as Lhaovo (Maru), Lacid (Lashi), Zaiwa (Atsi), Ngochang (Nishi 1999) Burmese script • Assumed to be the result of the application of Mon script to Burmese language • The oldest dated document in Burmese language is R¯ajakum¯ar (Myazedi) Inscriptions (AD1112). 2 Introduction 0.2 • Discrepancies between spelling and sounds of Modern Burmese due to historical sound change, observable from the following data: – Transcriptions with Chinese Characters of Miˇan-Ti`an-Guˇan-Y`ı- Yˇu 緬甸館訳語 compiled in Ming period, AD15c (Nishida 1972) – Borrowing words from Aryan languages (mainly Pali)¯ into Burmese – Borrowing words from Burmese into Shan – Phonological correspondence between Burmese and other Bur- mish languages • Thought to be the base of such scripts as Ahom, Shan and Tai-Na 3 1 Retention of vir¯ama a`s`t¸ 1.1 Aks.ara segmentation Pali.¯ cintita-m˙ attan-o (thought-acc self-gen) ‘one’s own thought’ c˘Ó½itmtÖenA (R¯ajakum¯arInscription, Pillar A, Pali¯ Face, l.19) 4 1 Retention of vir¯ama a`s`t¸ 1.1 • Aks.ara segmentation segments a sound sequence into aks.aras, i.e. -

Phonology of Lagwan (Logone-Birni Kotoko)
Ministry of Scientific Research and Innovation Phonology of Lagwan (Logone-Birni Kotoko) Joy Naomi Ruff SIL B.P. 1299, Yaoundé Cameroon 2005 1 Contents Abbreviations and transcriptions 4 Transcriptions: three levels of representation 4 Abbreviations 5 Phonology of Lagwan (Logone-Birni Kotoko) 1 Introduction 6 1.1 Population and location 6 1.2 Language names, classification and genetic affiliation 6 1.3 Dialects and variation 7 1.4 Previous research 7 1.5 Present research 7 1.6 Overview of phonology 7 2 Consonants 8 2.1 General characteristics of the consonant system 8 2.1.1 Distributional restrictions 9 2.2 Consonantal allophony 9 2.3 Distinctive consonantal features 13 2.3.1 Redundancy 14 2.3.2 Default phonetic realisation 14 2.3.2.1 The glottalic obstruents 14 2.3.2.2 The nasals 15 2.3.2.3 The zero consonant 15 2.4 Complex and contour consonants 15 2.4.1 Prenasalised obstruents 15 2.4.2 Labialised dorsal obstruents 18 2.4.2.1 Prosodic tendencies 19 2.5 Gemination 21 2.6 The voiced lateral fricative 22 2.7 Free variation 23 2.8 Loan word consonants 24 2.8.1 Pre-palatal affricates 24 2.8.1.1 The voiceless affricate [c] 24 2.8.1.2 The voiced affricate [j] 26 2.8.2 Pre-palatal fricatives 29 2.8.3 The glottal stop 31 3 Vowels 32 3.1 General characteristics of the vowel system 32 3.2 Distinctive vowel features 33 3.2.1 Redundancy 33 3.3 Phonemic vowels with limited distribution 33 3.3.1 The mid vowels |e| and |o| 34 3.3.1.1 The front vowel |e| 34 3.3.1.2 The back vowel |o| 35 2 3.3.2 The high vowels |i| and |u| 36 3.3.2.1 The front vowel -

The Music in Plain Speech and Writing
The Music in Plain Speech and Writing PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sun, 19 May 2013 11:51:46 UTC Contents CMU Pronouncing Dictionary 1 Arpabet 2 International Phonetic Alphabet 5 Phonetic transcription 26 Phonemic orthography 30 Pronunciation 35 Syllable 36 Allophone 46 Homophone 49 Rhyme 52 Half rhyme 59 Internal rhyme 60 Assonance 62 Literary consonance 64 Alliteration 65 Mnemonic 68 Phonetic algorithm 73 Metaphone 74 Soundex 77 Rhyme Genie 79 References Article Sources and Contributors 81 Image Sources, Licenses and Contributors 84 Article Licenses License 85 CMU Pronouncing Dictionary 1 CMU Pronouncing Dictionary CMU Pronouncing Dictionary Developer(s) Carnegie Mellon University Stable release 0.7a / February 18, 2008 Development status Maintained Available in English License Public Domain [1] Website Homepage The CMU Pronouncing Dictionary (also known as cmudict) is a public domain pronouncing dictionary created by Carnegie Mellon University (CMU). It defines a mapping from English words to their North American pronunciations, and is commonly used in speech processing applications such as the Festival Speech Synthesis System and the CMU Sphinx speech recognition system. The latest release is 0.7a, which contains 133,746 entries (from 123,442 baseforms). Database Format The database is distributed as a text file of the format word <two spaces> pronunciation. If there are multiple pronunciations available for a word, all subsequent entries are followed by an index in parentheses. The pronunciation is encoded using a modified form of the Arpabet system. The difference is stress marks on vowels with levels 0, 1, 2; not all entries have stress however. -

Korean Alphabet Hangul Pdf
Korean alphabet hangul pdf Continue About 63 million people in Korea, North Korea, China, Japan, Uzbekistan, Kazakhstan and Russia speak Korean. The relationship between Korean and other languages is not exactly known, although some linguists consider him a member of the Altai family of languages. Grammatically Korean is very similar to Japanese and about 70% of its vocabulary comes from Chinese. The origin of writing in Korea chinese writing has been known in Korea for over 2,000 years. It was widely used during the Chinese occupation of North Korea from 108 BC to 313 AD by the 5th century AD, Koreans began to write in classical Chinese - the earliest known example of this dates back to 414 AD. Later they developed three different systems for writing Korean with Chinese characters: Hyangchal (향찰/鄕札), Gukyeol (구결/⼝訣) and Idu (이두/吏讀). These systems were similar to those developed in Japan and probably used as models by the Japanese. The Idu system used a combination of Chinese characters along with special symbols to refer to Korean verb endings and other grammatical markers, and has been used in official and private documents for centuries. The Hyangchal system used Chinese characters to represent all sounds of the Korean language and was used mainly to write poetry. The Koreans borrowed a huge number of Chinese words, gave Korean readings and/or meanings to some Chinese characters, and invented about 150 new characters, most of which are rare or used mainly for personal or similar names. The Korean alphabet was invented in 1444 and made public in 1446 during the reign of King Sejong (b.1418-1450), the fourth king of the Joseon dynasty. -

Ki-Moon Lee, S. Robert Ramsey, a History of the Korean Language
This page intentionally left blank A History of the Korean Language A History of the Korean Language is the first book on the subject ever published in English. It traces the origin, formation, and various historical stages through which the language has passed, from Old Korean through to the present day. Each chapter begins with an account of the historical and cultural background. A comprehensive list of the literature of each period is then provided and the textual record described, along with the script or scripts used to write it. Finally, each stage of the language is analyzed, offering new details supplementing what is known about its phonology, morphology, syntax, and lexicon. The extraordinary alphabetic materials of the fifteenth and sixteenth centuries are given special attention, and are used to shed light on earlier, pre-alphabetic periods. ki-moon lee is Professor Emeritus at Seoul National University. s. robert ramsey is Professor and Chair in the Department of East Asian Languages and Cultures at the University of Maryland, College Park. Frontispiece: Korea’s seminal alphabetic work, the Hunmin cho˘ngu˘m “The Correct Sounds for the Instruction of the People” of 1446 A History of the Korean Language Ki-Moon Lee S. Robert Ramsey CAMBRIDGE UNIVERSITY PRESS Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, Sa˜o Paulo, Delhi, Dubai, Tokyo, Mexico City Cambridge University Press The Edinburgh Building, Cambridge CB2 8RU, UK Published in the United States of America by Cambridge University Press, New York www.cambridge.org Information on this title: www.cambridge.org/9780521661898 # Cambridge University Press 2011 This publication is in copyright. -

Phonetic Encoding Method for Chinese Ideograms, and Apparatus Therefor
Europaisches Patentamt European Patent Office © Publication number: 0 271 619 A1 Office europeen des brevets © EUROPEAN PATENT APPLICATION © Application number: 86309765.5 © int. CI* G06F 3/00 , B41J 3/00 © Date of filing: 15.12.86 © Date of publication of application: © Applicant: Yen, Victor Chang-ming 22.06.88 Bulletin 88/25 20 Nassau Street Princeton New Jersey(US) © Designated Contracting States: BE CH DE FR GR IT LI NL SE © Inventor: Yeh, Victor Chang-ming 20 Nassau Street Princeton New Jersey(US) © Representative: Skone James, Robert Edmund etal GILL JENNINGS & EVERY 53-64 Chancery Lane London WC2A 1HN(GB) © Phonetic encoding method for Chinese ideograms, and apparatus therefor. © A method and apparatus for data processing and word processing in the Chinese language are dis- PHnNFTir ffllMFSf Al PHABTT (PfAl- 8* « P¥X*»< t+iZ 1***, (Ptt) is de- closed. A Phonetic Chinese Language (PCL) « 8f + $ n £ £ fined in which any ideogram can be unambiguously represented by a Phonetic Chinese Word (PCW) no more than four characters in length, each word being CONSONANTS — 25 « i77*i composed of letters selected from a defined set of 12 3 4 5678 9 10 11 letters that can each be uniquely represented by a rj * * a if h 7-bit digital code. Each PCW represents one and D p m f a t n 1 g It h only one ideogram and provides the full sound and tone information required to pronounce it. Ambigu- 12 13 14 15 16 17 18 19 20 21 22 83 84 85 ities caused by homonyms and homotones are LoogH-t* ±t>B 3 + * T ¥ ill f avoided. -
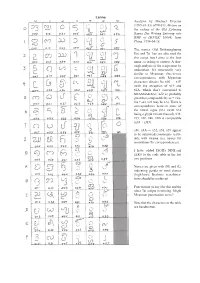
Lanna Analysis by Michael Everson
Lanna Analysis by Michael Everson (1999-01-13) of N1013, Motion on the coding of the Old Xishuang Banna Dai Writing Entering into BMP of ISO/IEC 10646, from China, 1994-04-18. The names Old Xishuangbanna Dai and Tai Lue are also used for this script, but Lanna is the best name according to experts. A thor- ough analysis of the script must be undertaken. It’s structurally very similar to Myanmar. One-to-one correspondence with Myanmar characters obtains for x00 — x1E (with the exception of x19 and x1A, which don’t correspond to MYANMAR BA); x22 is probably great tha (composable by sa + vira- ma + sa); x23 may be LA). There is correspondence between some of the vowel signs (x31 (with x32 being a glyph variant thereof), x38, x39, x3F, x40. x3B is composable (x38 + x3D). x46, x4A — x52, x58, x59 appear to be subjoined consonants realiz- able with virama (see names list annotations for correspondences). I have added DIGITs NINE and ZERO to the code table in the last two positions. Names are given with (H) and (L) indicating gender or tonal classes (high/low); Brahmic translitera- tions should be preferred. Punctuation (if any) for this and the other Tai scripts is missing. Might Myanmar punctuation serve? Note that the characters in the table are handwritten. Lanna Names list (revised by Michael Everson) from N1013, dated 1994-10. 53 LANNA COMPONENT PART OF CONSONANTS (???) 54 LANNA COMPONENT PART OF CONSONANTS (???) 00 LANNA LETTER ZERO CONSONANT (H) 55 LANNA VOWEL SIGN OI 01 LANNA LETTER I 56 LANNA VOWEL SIGN UAI 02 LANNA LETTER U 57 LANNA -

The Prehistory of a Northern Ryukyuan Dialect of Japanese
ABSTRACT SHODON:. THE PREHISTORY OF A NORTHERN RYUKYUAN DIALECT OF JAPANESE Leon Angelo Serafim Yale UnJversity 1984 The Ryukyuan dialects of Japanese are important not only in reconstructing the linguistic prehistory of the Japanese language but also for their internal history, that is, for what can be discovered about their history quite apart from what is known about the history of any other Japanese dialects. The main focus of this dissertation is on the latter question, particularly with regard to the dialect Shodon of the northern Ryukyus. The approach is internal reconstruction, utilizing the rich morphophonemics of the dialect. The reconstruction is based on alternations in noun shape due to the addition of enclitics, and on the morphophonemics of the Shodon adjective and verb subtypes. Detailed discussion of sound changes and sound-change orderings is given, and many words are reconstructed insofar as that is possible. It is hoped that this internal reconstruction using Shodon can be linked to other reconstructions in order to come up with a detailed view of the prehistory of Ryukyuan and, further, to form a link to the prehistory of the mainland Japanese dialects. Shodon: The Prehistory of a Northern Ryukyuan Dialect of Japanese A Dissertation Presented to the Faculty of the Graduate School of Yale University in Candidacy for the Degree of Doctor of Philosophy by Leon Angelo Serafim May 1984 TABLE OF CONTENTS PREFACE ••• . • • ii Chapter page I. INTRODUCTION . 1 Place of Shodon Dialect. 1 Shodon Dialect Data ••• • • • . 2 The Method of Internal Reconstruction ••••••••••• 3 Internal Reconstruction of Shodon Dialect ••••••••• 4 The Utility of an Internal Reconstruction of Shodon •••• 5 Hattori's Ryukyuan A: B Distinction ••••••••••• 6 II. -

On the "Zero Consonant" Phoneme in Modern Standard Finnish
Juha Janhunen Helsinki On the “zero consonant” phoneme in modern standard Finnish – towards a coherent paradigmatic interpretation Introduction There is a general consensus that the consonant paradigm of modern stand- ard Finnish comprises the following 13 members: the three basic unvoiced (and unaspirated) stops p t k; the corresponding (voiced) nasals m n ng; the inher- ently unvoiced continuants s h, of which h can also have voiced realisations; the voiced dental stop d; the two (voiced) liquids l r; and the two glides v j (all quoted here in their orthographical representations). In terms of places of articulation there are the three labials m p v, of which the glide v is normally pronounced as a dentilabial (labiodental); the six dentals n t s d r l, among which n d r are pro- nounced as postalveolars; the single palatal (glide) j; and the three palato-velars ng k h, of which the continuant h has mainly laryngeal, but also velar and palatal, realizations. Of the two continuants, s may also be specifi ed as a sibilant frica- tive, while h may be described as a spirant with relatively little fricative noise. The consonant system may, consequently, be presented in a matrix with four places (labial, dental, palatal, velar) and seven manners of articula- tion (nasal, voiceless stop, continuant, voiced stop, vibrant/trill, lateral, glide) (Table 1).1 The paradigmatic relationships of the continuants s h with regard to the glides v j, and of all these with regard to the segments d r l, are an issue open to several alternative interpretations (Janhunen 2007, 204–205), but there is no question as to the number of contrasts involved.